 電子發燒友App
電子發燒友App


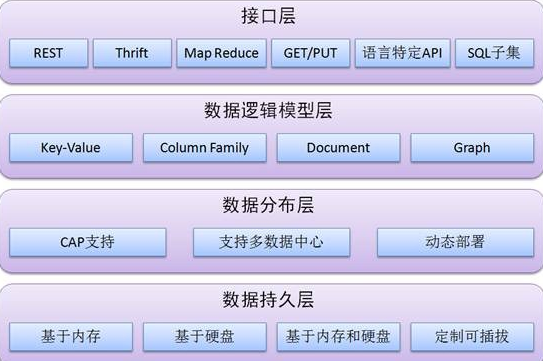
互聯網的發展催生了云計算和大數據的發展, 云計算和大數據的本質都是構建低成本,高性能高可用的分布式存儲系統,本文簡單介紹分布式存儲的一些基礎知識。
分布式存儲通過網絡連接的大量的普通服務器, 將數據分片分散在集群中的不同節點(服務器或進程)中,對外提供統一的服務。
分布式存儲一般需要具有幾個特性
可擴展:分布式存儲一般可擴展幾百甚至幾千臺服務器,并可容易的增加或減少節點, 在節點調整過程中, 分布式存儲服務可自動實現數據的遷移及負載均衡等操作。
低成本:組成分布式存儲服務的服務器可為普通服務器, 由于普通服務器故障率通常較高,因此要求存儲服務具有較好的容錯性。
高性能:分布式存儲理論上隨著節點數量的增加,對外提供的服務的性能應該成線性增長的趨勢。這是分布式存儲同非分布式存儲的一大區別之一, 一般非分布式存儲在數據量達到一定規模之后, 都會存在單點的讀寫問題,分布式存儲一般通過數據分片解決單點問題。
易用:分布式是存儲對外提供統一的接口, 用戶不需要關心數據的分片查找,副本維護等工作。
分布式存儲根據存儲類型可分為
分布式文件系統:一般存儲非結構的blob對象(文件,圖像等),比如淘寶的TFS, AWS的EBS, google的GFS等
分布式鍵值系統:存儲關系簡單的半結構數據, 只提供基于鍵值的CRUD操作, 不能做關聯查詢, 比如Redis, Tair, MongoDB等
分布式表格系統:用于存儲半結構化數據, 與鍵值系統相比, 除了提供CRUD操作外, 還支持基于某個主鍵的范圍掃描, 比如Google 的Big Table, AWS的Dynamo DB等
分布式關系數據庫:存儲關系數據, 比如Taobao的Ocean DB。
存儲系統的性能瓶頸在于隨機的讀寫操作。下表列出了各種硬件的存儲性能比:
類別消耗時間訪問L1 Cache0.5 ns訪問L2 Cache7 nsMutex加鎖/解鎖100 ns內存訪問100 ns千兆網絡發送1MB數據10 ms內存順序讀取1MB數據0.25 ms機房內網絡來回0.5 ms異地機房間網絡來回30~100 ms
SATA磁盤尋道10 ms
從SATA磁盤順序讀取1MB數據20 ms
固態SSD盤訪問延遲0.1~0.2 ms
SATA的順序讀取帶寬可以達到100MB以上, 由于磁盤的尋道時間大約為10ms, 順序讀取1MB數據的時間為:磁盤尋道時間 + 數據讀取時間, 即10ms + 1MB/100MB/s*1000=20ms。
分布式存儲系統一般需要解決幾個問題
數據分布
在分布式存儲系統中,如何將數據分片到不同的節點是首先要考慮的問題,一般分布式系統常使用的方法是Hash分布。
hash分布
哈希分布就是根據數據的某一個特征計算hash值, 并將hash值和集群中的節點做映射。從而將不同hash值的數據分布到不同的節點上。
hash分布的一個問題是一旦數據已經分布到不同的節點中, 做擴容比較困難, 比如現在數據通過hash值分布到三臺機器上, 如果要將機器擴展到五臺, 需要重新將所有的數據重新算一下hash值, 然后重新分布。因此一般擴展節點的數量是原數量的一倍,這樣只需要移動一半數據。
一致性hash
一致性hash算法從某種程度上解決了擴展過程中移動數據太多的問題, 一致行hash算法給每個節點賦予一個hash值, 這些節點按順序構成一個環,數據根據hash值落在環中的某個節點上。當需要擴容時,將新加入節點放入環中,數據遷移只需要遷移新節點相鄰的節點上的數據即可。一致性hash容易造成數據偏斜, 而且在數據復制過程中, 對相鄰節點的壓力比較大。
一般系統會引入虛擬節點或虛擬槽的解決方式:即解耦數據與節點間的關系,引入虛擬節點, 將數據映射到大量的虛擬節點上, 然后虛擬節點在在映射到實體節點上,這樣在擴容過程中,可以以虛擬節點為單位移動數據, 可從不同的實體節點上移動虛擬節點到新節點。很多存系統都采用了這種方案,如redis, Cassandra。
異常
分布式系統中,一臺服務器或者一個服務器上的不同進程被成為一個節點, 節點間通過網絡互聯, 不論是節點還是網絡都是不可靠的。分布式系統需要處理由于節點或網絡引起的各種異常。
節點異常包括節點宕機或磁盤不可用(可恢復和不可恢復),分布式系統需要可以自動監控的節點的異常, 并做相應處理:對不可恢復異常, 如果該節點值主副本節點, 則需要重新進行選主, 如果該節點是從副本節點, 則需要其他節點從主副本(或其他從副本)復制一份分片數據, 保證副本數量不變。對可恢復異常, 需要恢復節點并重構內存。
網絡異常:通過網絡進行交互, 結果可分為成功, 失敗,和未知。未知的情況可能有成功也可能是失敗, 因此需要有重試機制, 而且多次調用的結果應該冪等。
復制
由于異常的存在,為了達到高可用的目的, 一般數據會有多個副本, 多個副本鍵間的關系有:
主從副本:主從副本只有主提供寫, 從可以提供讀服務(或僅是備份的作用),主從的缺點主的單點寫瓶頸, 但是由于數據被分片了, 如果數據的摸一個分片遇到寫瓶頸, 可以通過增加集群節點的方式解決,這要求分布式存儲的擴容比較容易,一般像redis, mongodb這種系統擴容都不會成為問題, 但是像ES, 分片數量不能修改, 擴容就需要重新倒入數據。
主主副本:同一個副本的不同節點都可以是進行寫操作, Cassandara即是用這種方式實現
一致性
因為同一份數據包含多個副本,副本間的一致性是分布性存儲系統需要考慮的問題。
一致性分為強一致性,弱一致性和最終一致性。最終一致又可分為:
讀寫一致性:A寫后, A后的讀都可獲得最新結果。
會話一致性:同一個會話內寫后讀都可獲得最新結果。
單調讀:A讀取一次結果后, 后續讀取不會獲得之前版本的值。
單調寫:A的多次寫在多個副本間按照順序執行。
一般分布式存儲系統都既可以支持強一致性又可支持最總一致性。
分布式存儲系統大體遵循相同的功能模式, 但具體實現又根據自身特點各有不同。在日常系統維護過程中,了解相應的分布式系統存儲的實現機制可以快速幫助定位問題并找到正確的解決方案。
責任編輯人:CC




















 工商網監
工商網監
評論