 電子發燒友App
電子發燒友App


姿態估計
人體姿態估計:估計人的關節點坐標(回歸問題)
RGB or RGBD
圖像 or 視頻
單目 or 多視角
單人 or 多人
2D or 3D
3D姿態 or 3D形態
2D姿態估計
任務
Benchmark: MPII (2014)
代表作: CPM (CVPR 2016), Hourglass (ECCV 2016)
Benchmark: COCO (2016), CrowdPose (2018)
自底向上: OpenPose (CVPR 2017), Associative Embedding (NIPS 2017)
自頂向下: CPN (CVPR 2018), MSPN (Arxiv 2018), HRNet (CVPR 2019)
Benchmark: PoseTrack (2017)
代表作: Simple Baselines (ECCV 2018)
單人姿態估計
多人姿態估計
人體姿態跟蹤
挑戰
遮擋
復雜背景
特殊姿態
3D姿態估計
問題
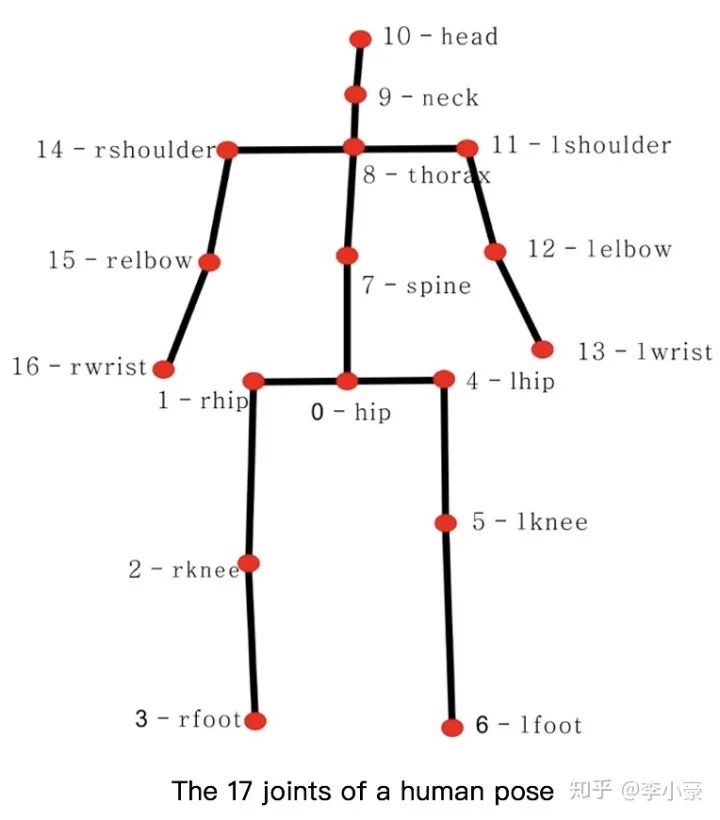
估計出關節點的三維坐標 (x, y, z) (回歸問題)
輸入: 包含人體的圖片
輸出: N×3個人體關節點
挑戰
缺少特殊姿態的數據集(如摔倒,打滾等)
由于數據集是在實驗室環境下建立的,模型的泛化能力較差
3D姿態數據集是依靠適合室內環境的動作捕捉(MOCAP)系統構建的。MOCAP系統需要帶有多個傳感器和緊身衣褲的復雜裝置,在室外環境使用是不切實際的
巨大的3D姿態空間、自遮擋
單視角2D到3D的映射中固有的深度模糊性、不適定性(一個2D骨架可以對應多個3D骨架)
缺少大型的室外數據集(主要瓶頸)
?
應用
動畫,游戲
運動捕捉系統
行為理解
姿態估計可以做為其他算法的輔助環節(行人重識別)
人體姿態估計跟人體相關的其他任務一起聯合學習(人體解析)
?
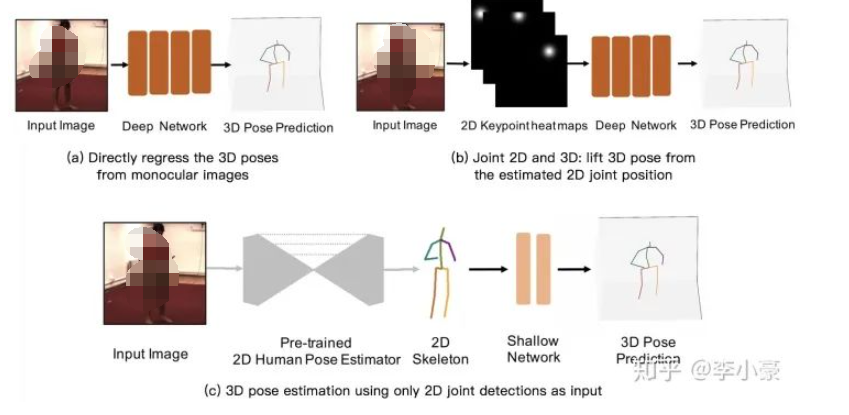
方法
3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network (ACCV 2014)
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose (CVPR 2017)
通過深度學習模型建立單目RGB圖像到3D坐標的端到端映射,但是對于單一模型來說需要學習的特征太過復雜。
聯合2D,3D共同訓練(2D信息通常以heatmap來表示)
Towards 3D Human Pose Estimation in the Wild (ICCV 2017)
3D Hand Shape and Pose Estimation from a Single RGB Image (CVPR 2019)
需要復雜的網絡架構和充足的訓練樣本。
直接用預訓練好的2D姿態網絡,將得到的2D坐標輸入到3D姿態估計網絡中(得益于2D姿態估計較為成熟)
減少了模型在2D姿態估計上的學習壓力
網絡結構簡單,輕量級
實時性,快速
訓練快,占用顯存少
缺少原始圖像輸入,可能會丟失一些空間信息
2D姿態估計的誤差會在3D估計中放大
Simple Yet Effective Baseline (ICCV 2017)
3D human pose estimation in video with temporal convolutions (CVPR 2019)
2D姿態網絡: Hourglass (ECCV 2016), CPN (CVPR 2018)
優點
缺點
因為基于檢測的模型在2D的關節點檢測中表現更好,而在3D空間下,由于非線性程度高,輸出空間大,所以基于回歸的模型比較流行。
從2D圖片直接暴力回歸得到3D坐標
先獲取2D信息,然后再“提升”到3D姿態
為什么要先進行2D估計再進行3D估計?
數據集
3D姿態估計最大、最廣泛使用的數據集
360萬張圖像,4個不同的視角 (原數據集提供的是視頻,50fps)
15個動作: directions, discussion, eating, greeting, phoning, posing, purchases, sitting, sitting down, smoking, taking photo, waiting, walking, walking dog, walking together
11 個人,但只有7個人包含3D姿態標簽
訓練: S1, S5, S6, S7, S8 (1559752張圖像)
測試: S9, S11 (550644張圖像)
備注:實際使用的時候只用了7個人的數據,總共210萬張圖像,所以我感覺應該稱為Human2.1M。而且從原數據的視頻中提取出圖片的時候,提取出的圖片數會比標簽要多,提取出來有2137070張圖像,而標簽只有2110396個。在使用這個數據集的時候將每個視頻舍棄尾部幾幀多出來的圖像使得與標簽一一對應。
Human3.6M (2014)
HumanEva (2010)
MPI-INF-3DHP (2017)
?
?
評價指標
網絡輸出的關節點坐標與ground truth的平均歐式距離(通常轉換到相機坐標)
先對網絡輸出進行剛性變換(平移,旋轉和縮放)向ground truth對齊后,再計算MPJPE
如果預測關節與ground truth之間的距離在特定閾值內,則檢測到的關節被認為是正確的
如果兩個預測的關節位置與ground truth之間的距離小于肢體長度的一半,則認為肢體被檢測到
計算機視覺:相機成像原理:世界坐標系、相機坐標系、圖像坐標系、像素坐標系之間的轉換
相機成像模型——建立過程(世界坐標系,相機坐標系,圖像坐標系,圖像像素坐標系,四者之間的關系
Mean Per Joint Position Error (MPJPE): Protocol 1,關節點坐標誤差的平均值
Procrustes analysis MPJPE (P-MPJPE): Protocol 2,基于Procrustes分析的MPJPE
Percentage of Correct Key-points (PCK),正確關鍵點的百分比
Percentage of Correct Parts (PCP),正確部件的百分比
備注:做3D的問題,需要掌握各個坐標系間的轉換,如世界坐標、相機坐標、圖像坐標等。可參考以下兩篇博文
監督方法
深度圖、點云、網格、GAN、3D投影到2D
3D投影到2D
弱監督: 不直接用標簽,而用其他信息計算Loss
半監督
自監督
全監督
視頻序列的優點
當前幀有遮擋的時候,可利用相鄰幀的完整性解決這個問題
由于單獨預測每個幀的3D姿態時,每個幀中的結果與其他幀無關,會導致輸出不連貫,帶有視頻抖動
單張圖片包含的深度信息是有限的,網絡可以從序列中挖掘到更豐富的深度信息
一張2D圖片可以對應無窮多個3D姿態,讓模型“多看”同個視角不同時間人的圖片,可以減少深度模糊性,縮小3D姿態的空間范圍
3D形態估計
問題
人體姿態重建:從圖片或視頻中重建或恢復人體姿態的3D模型
3D形態的表示
網格: 由三角形組成的多邊形網格
深度圖: 每個像素值代表的是物體到相機xy平面的距離
體素: 三維空間中的一個有大小的點,一個小方塊,相當于是三維空間中的像素
點云: ?某個坐標系下的點的數據集。點包含了豐富的信息,包括三維坐標xyz、顏色、分類值、強度值、時間等
SMPL(A Skinned Multi-Person Linear Model)
輸入 (82): Shape? ?+ Pose
?+ Pose
各個參數代表人體哪個部分?可參考“SMPL模型Shape和Pose參數”
輸出: Mesh
優點: 只需要估計少量的參數便可得到包含6890個頂點的高質量的人體3D Mesh
可從3D Mesh中回歸得到,其中? ?為預先訓練好的線性回歸器
?為預先訓練好的線性回歸器
3D Mesh: SMPL
3D Pose

可從3D Pose中使用相機內參計算得到
2D Pose

編輯:黃飛
?













 工商網監
工商網監
評論