") 關(guān)于Kirin 970的NPU的性能分析
關(guān)于Kirin 970的NPU的性能分析
去年,華為推出了業(yè)界首款集成NPU的移動芯片Kirin 970。作為新一代的旗艦,這個SoC上面的CPU集成了8個核心,其中 4 個為高性能的 ARM 公版 A73 架構(gòu),最高主頻 2.4GHz(麒麟 960 是 2.36GHz),4 個為低功耗的 ARM 公版 A53 架構(gòu),最高主頻 1.8GHz(麒麟 960 是 1.84GHz);GPU則是集成了ARM最新的Mali-G72 架構(gòu)。
另外,除了傳統(tǒng)移動手機(jī)SoC必備的通信基帶、ISP、DSP、Codec和協(xié)處理器外,Kirin 970還首次集成了專門為深度學(xué)習(xí)而定制的NPU,F(xiàn)P16 性能達(dá)到了 1.92 TFLOP。具體來看, NPU 是 CPU 的 25 倍,GPU 的 6.25 倍(25/4),能效比上,NPU 更是達(dá)到了 CPU 的 50 倍,GPU 的 6.25 倍(50/8)。這是華為面向現(xiàn)在火熱的人工智能市場扔出的一個殺手锏。
以上都是華為的一家之言,下面我們就來探討一下華為這顆芯片NPU的真正實力。首先,我們先來了解一下NPU的概念。
什么是NPU?
準(zhǔn)確來說,當(dāng)我們談到人工智能在計算領(lǐng)域的用途的時候,更多強(qiáng)調(diào)的是機(jī)器學(xué)習(xí)。
而當(dāng)我們討論人工智能在硬件層面的深入研究的時候,談?wù)摰膭t更多是針對專門的硬件模塊所進(jìn)行的卷積神經(jīng)網(wǎng)絡(luò)的優(yōu)化和執(zhí)行工作。
在解釋卷積神經(jīng)網(wǎng)絡(luò)如何工作的時候,我們從上世紀(jì)八十年代開始的工作已經(jīng)遠(yuǎn)遠(yuǎn)超出了研究工作,其根本目的是試圖模擬人腦神經(jīng)元的行為。
注意,這里的一個關(guān)鍵詞是“模擬”,雖然到目前為止并沒有任何神經(jīng)網(wǎng)絡(luò)能夠從硬件層面模仿人腦的結(jié)構(gòu)。
不過在學(xué)術(shù)領(lǐng)域,尤其是在神經(jīng)網(wǎng)絡(luò)領(lǐng)域已經(jīng)存在了很多理論。在過去的十年中,已經(jīng)開發(fā)出了一套軟件能夠在GPU的硬件層面模擬整個過程。
比如說,研究人員通過不斷的迭代和發(fā)展美國有線電視新聞網(wǎng)的模型,極大的提升了新聞的準(zhǔn)確性和效率。
當(dāng)然,GPU并不是最適合運(yùn)行人工智能的硬件,也不是唯一一個能夠進(jìn)行高度的并行運(yùn)算的處理器。
隨著人工智能的不斷發(fā)展,越來越多的公司希望在實際應(yīng)用當(dāng)中將人工智能實現(xiàn)商業(yè)化,這就要求硬件能夠提供更高的性能,更高的效率。
因此,我們也看到了更加專業(yè)的處理器的出現(xiàn),其架構(gòu)就是針對機(jī)器學(xué)習(xí)等應(yīng)用。
谷歌是第一家宣布推出此類硬件的公司,該公司在2016年推出了TPU。但是,雖然這類專業(yè)的硬件能夠在處理人工智能等工作方面在硬件和功率方面獲得更高的效率,但是也失去了靈活性。
谷歌TPU芯片和主板
在這類專門的人工智能處理器當(dāng)中,影響其工作效率的主要有兩個方面:要存在一個經(jīng)過訓(xùn)練的模型,其中主要包括模型在今后的運(yùn)行中可能涉及到的相關(guān)的數(shù)據(jù)。一般情況下,模型的訓(xùn)練是大密度的,需要經(jīng)過大批量的訓(xùn)練才能實現(xiàn)更高的精度。也就是說,在實際運(yùn)行中,有效的神經(jīng)網(wǎng)絡(luò)要比實際用到的神經(jīng)網(wǎng)絡(luò)要龐大的多。
因此,普遍存在這樣一個思路,就是模型的主體訓(xùn)練工作由更加龐大的GPU服務(wù)器或者是TPU云服務(wù)器來完成。
其次,神經(jīng)網(wǎng)絡(luò)的運(yùn)行需要一個執(zhí)行模型,通過不斷注入新的數(shù)據(jù),完成模型的演算來實現(xiàn)整個過程。一般情況下,我們將輸入數(shù)據(jù),然后通過神經(jīng)網(wǎng)絡(luò)模型得到輸出結(jié)果的模式稱之為推理。
不過實際的推理過程與模型當(dāng)中的訓(xùn)練過程對于計算的要求也存在著很大的不同。
雖然推理和訓(xùn)練都需要用到高密度的并行計算,但是推理能夠以較低精度的計算來完成,同時執(zhí)行模型部分所需要的計算性能也較低,這也就意味著推理過程能夠在更加便宜的硬件上來進(jìn)行。
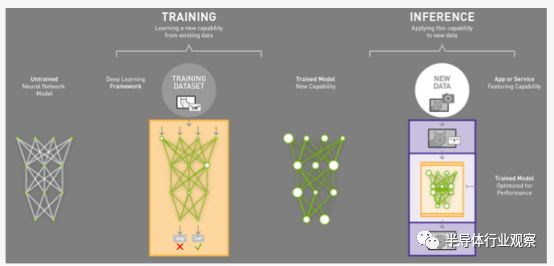
這一功能反過來引導(dǎo)整個行業(yè)走向更加注重邊緣設(shè)備(用戶設(shè)備)的方向,因為這些設(shè)備能夠提供更高的性能效率和需求更低的功耗。
也就是說,如果本地設(shè)備當(dāng)中存在一個已經(jīng)經(jīng)過訓(xùn)練的模型,就可以使用該設(shè)備來進(jìn)行推理過程,而不需要將數(shù)據(jù)上傳到云端服務(wù)器當(dāng)中來進(jìn)行數(shù)據(jù)的處理。
這一過程將會減輕可能存在的延遲,功耗和帶寬等問題,同時也避免了隱私問題,因為輸出端數(shù)據(jù)永遠(yuǎn)不會離開用戶設(shè)備。
隨著神經(jīng)網(wǎng)絡(luò)推理功能在終端設(shè)備上運(yùn)行的不斷實現(xiàn),對于不同處理器能夠?qū)崿F(xiàn)何種功能的研究以及選擇工作也在不斷深入。
CPU、GPU甚至DSP都能夠在終端設(shè)備上實現(xiàn)推理功能,但是這些處理器之間存在著巨大的效率差距。通用處理器適合絕大多數(shù)的工作,但是他們天生就不是被設(shè)計用來進(jìn)行大規(guī)模的并行計算的。GPU和DSP甚至表現(xiàn)的更好,也有巨大的提升空間。
但是,此外,我們也見到了一種新的處理加速器的出現(xiàn),比如麒麟970里面使用的NPU。
由于這類處理加速器是新近出現(xiàn)的設(shè)備,所以到目前為止,業(yè)界并沒有更出一個統(tǒng)一的命名方式。華為海思命名的是一種方式,而蘋果則是以另外一個名字命名。
不過從普世意義上來看,我們能夠?qū)⑦@些處理器統(tǒng)一稱之為神經(jīng)網(wǎng)絡(luò)IP。
為麒麟970 NPU提供IP的是一家名為寒武紀(jì)的中國IP供應(yīng)商,據(jù)了解,NPU采用的IP是經(jīng)過優(yōu)化之后的產(chǎn)物,而不是直接采用現(xiàn)有IP。同時,華為還要求Cambricon能夠與之共同發(fā)展改進(jìn)該IP,因為在實際的應(yīng)用當(dāng)中,實際情況與計算情況,有時候還是會存在著一些差距。
但是,我們需要明白的是,我們應(yīng)當(dāng)避免對神經(jīng)網(wǎng)絡(luò)的理論性能數(shù)據(jù)過多關(guān)注,因為這些數(shù)據(jù)并不一定與實際性能有關(guān),同時由于對神經(jīng)網(wǎng)絡(luò)IP了解有限,最終結(jié)果如何也未可知。
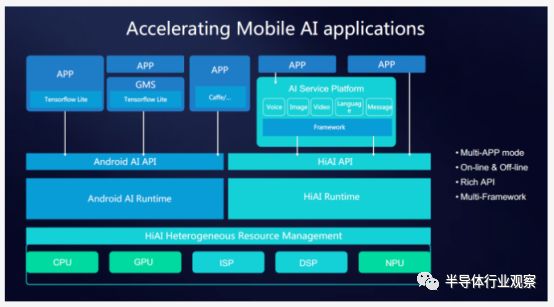
當(dāng)使用CPU以外的其他硬件設(shè)備來運(yùn)行神經(jīng)網(wǎng)絡(luò)的時候,第一個障礙就是利用適當(dāng)?shù)腁PI來訪問模塊。
傳統(tǒng)的SOC和IP供應(yīng)商已經(jīng)能夠提供專用的API和SDK來進(jìn)行使用該類硬件的神經(jīng)網(wǎng)絡(luò)的應(yīng)用開發(fā)。而海思提供的API不僅僅能夠管理CPU,也能夠用來管理GPU和NPU。雖然目前海思還沒有對外公開該API,但是據(jù)了解,海思將會在今年晚些時候與開發(fā)商一起進(jìn)行開發(fā)。
其他的廠商,諸如高通也提供了SDK來幫助程序開發(fā)人員在GPU和DSP等硬件的基礎(chǔ)上進(jìn)行神經(jīng)網(wǎng)絡(luò)的開發(fā)工作,當(dāng)然還有其他一些IP供應(yīng)商也有提供自己專門的軟件開發(fā)工具來進(jìn)行相關(guān)的開發(fā)。
但是,針對特定供應(yīng)商的API同樣存在著局限性,未來我們需要不同的供應(yīng)商能夠提供統(tǒng)一的API來進(jìn)行更加快速,便捷的開發(fā)工作。
谷歌目前正在開展這項工作,該公司計劃在安卓系統(tǒng)8.1當(dāng)中引入相關(guān)的名為NN API的模塊。
另外一個需要注意的問題是,目前很多的類似于NN API的只能夠支持一部分功能,比如只能夠支持NPU的一部分功能,如果開發(fā)人員想要在NPU的基礎(chǔ)上,充分開發(fā)和利用硬件的性能,開發(fā)者就需要有專門的API來開發(fā)這類硬件。
Kirin 970的NPU性能測試
為了完成這類開發(fā)工作,我們還需要一個基準(zhǔn)測試,來測試不同的供應(yīng)商提供的API能夠利用到NPU多少性能。
不幸的是,在現(xiàn)階段,我們還缺少類似的實現(xiàn)該基準(zhǔn)測試的方法,目前只有中國的一個廠商推出了相關(guān)的軟件:在中國比較流行的魯大師基準(zhǔn)測試軟件在最近推出了一個基于人工智能測試的框架,用來測試NPU和高通SNPE框架。
據(jù)了解,目前該基準(zhǔn)測試能夠測試三種不同的神經(jīng)網(wǎng)絡(luò),VGG16, InceptionV3和ResNet34。
這類軟件不僅能夠測試相關(guān)的處理器的性能,并給出相關(guān)的結(jié)果。同時也能夠以圖形化的方式,從平均功率,效率以及絕對性能等三個維度展示處理器的處理能力。
從這類軟件呈現(xiàn)的圖形數(shù)據(jù)我們能夠觀察到處理器的性能差異,CPU和NPU在進(jìn)行相關(guān)運(yùn)算時到底有多大的差距。
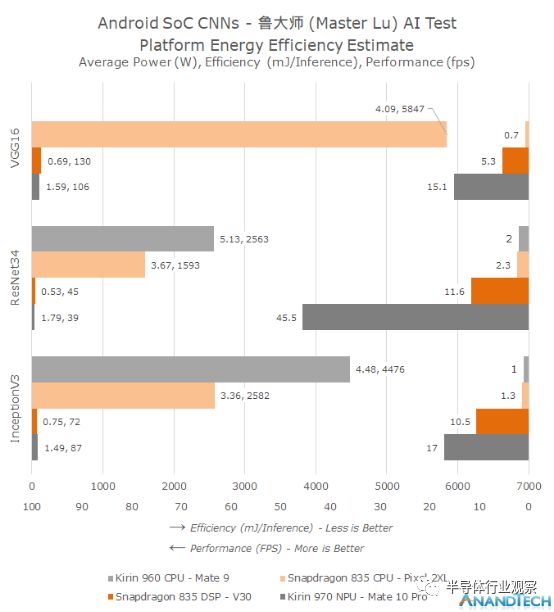
當(dāng)使用CPU來進(jìn)行運(yùn)算的時候,通常情況下CPU只能以1-2fps的速率進(jìn)行計算,而所需要的功耗也異常的高。比如驍龍835和麒麟960的CPU在運(yùn)算的時候,都需要以超過平均負(fù)載的工作負(fù)載進(jìn)行運(yùn)算。
相比較而言,高通的Hexagon DSP能夠?qū)崿F(xiàn)相對于CPU5到8倍的性能。
而華為的NPU的性能則更加明顯,相對于ResNet34,NPU能夠?qū)崿F(xiàn)4倍的性能提升。
不難發(fā)現(xiàn),不同的處理器之所以在性能方面表現(xiàn)出如此巨大的差異,是因為這些處理器的設(shè)計不同,所針對的處理器應(yīng)用場景也不同。
由于卷積神經(jīng)網(wǎng)絡(luò)在運(yùn)算的過程中需要進(jìn)行大量的并行計算,因此,像麒麟NPU這樣的專門的處理器在執(zhí)行的過程中往往能夠?qū)崿F(xiàn)更高的性能。
而在功耗方面,我們則發(fā)現(xiàn),相對于其他的處理器,NPU能夠?qū)崿F(xiàn)50倍的改進(jìn),尤其是在卷積神經(jīng)網(wǎng)絡(luò)實際的運(yùn)用當(dāng)中,這種能耗的提升更加明顯。
同時,我們也發(fā)現(xiàn),高通的DSP也能夠?qū)崿F(xiàn)類似于華為NPU同等級的功耗水平。這似乎表明,高通推出的驍龍845處理器中應(yīng)用的Hexagon 685能夠在性能方面提升3倍。
在此,我想抱怨一下谷歌的Pixel 2:由于Pixel 2缺乏對于SNPE框架的支持,因此很難從真正意義上進(jìn)行驍龍835的CPU基準(zhǔn)測試。
不過從某種意義上來說,這也是理所當(dāng)然的事情,畢竟谷歌在安卓8.1中才會引入NN API,未來谷歌將會推動安卓標(biāo)準(zhǔn)API在相關(guān)處理器方面的加速也是自然而然的。
但是,從另一方面來說,這也會限制傳統(tǒng)的手機(jī)OEM廠商開發(fā)的能力。
這一決定往往會限制今后生態(tài)系統(tǒng)的發(fā)展,這也是為什么我們沒有看到更多的手機(jī)GPU來進(jìn)行相關(guān)的卷積神經(jīng)網(wǎng)絡(luò)加速工作。
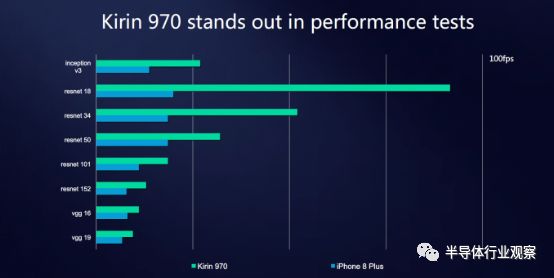
此外,雖然目前iPhone并不支持相關(guān)的基準(zhǔn)測試,但是我們也能夠從海思發(fā)布的相關(guān)數(shù)據(jù)中看到一些端倪。
從一些數(shù)字上我們能夠看到,蘋果所提供的神經(jīng)網(wǎng)絡(luò)IP雖然在性能方面超越了驍龍835處理器,但是仍然遠(yuǎn)遠(yuǎn)落后于海思的NPU。但是,我們無法單獨(dú)核實這些數(shù)字是否真的適合相關(guān)的基準(zhǔn)。
當(dāng)然,最重要的問題在于,這類處理器能夠帶來什么好處?
海思表示,一個比較明顯的例子是,美國有線電視新聞網(wǎng)通過應(yīng)用處理器來進(jìn)行降噪處理,能夠在交通繁忙的情況下,將語音識別的準(zhǔn)確度從80%提高到92%。
此外,還有在攝像頭應(yīng)用方面,Mate 10的攝像頭能夠在NPU的幫助下,通過推理,來識別不同場景,再基于場景對相機(jī)的設(shè)置進(jìn)行智能的優(yōu)化。
同時,Mate 10中所應(yīng)用的微軟翻譯程序也能夠使用NPU的離線加速翻譯功能,這些都是令我印象深刻的應(yīng)用。
而在手機(jī)內(nèi)置的圖片應(yīng)用中,也能夠智能識別圖片來進(jìn)行分類。
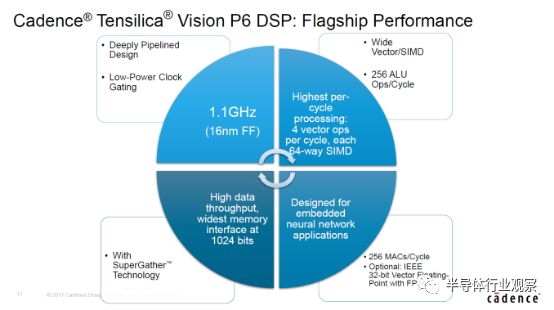
除了NPU能夠?qū)矸e神經(jīng)網(wǎng)絡(luò)進(jìn)行相應(yīng)的視覺處理之外,Cadence 的Tensilica Vision P6 DSP 和高通的Hexagon 680 DSP也能夠?qū)崿F(xiàn)相同的功能,只是目前并沒有對終端用戶開放而已。
但是,這并不表明,采用NPU的Mate 10就能夠為終端用戶帶來決定性的差異化體驗。同樣,手機(jī)中這類神經(jīng)網(wǎng)絡(luò)的應(yīng)用并沒有在汽車,安全攝像頭領(lǐng)域出現(xiàn)相同的殺手級應(yīng)用。另外,由于生態(tài)系統(tǒng)的限制性問題,我們只能夠在Mate 10見到相關(guān)的應(yīng)用,我們能否在更多的場景中見到,華為是否愿意開發(fā),與開發(fā)商一起共同開發(fā),都是值得商榷的事情,不過華為在這方面的創(chuàng)新還是值得肯定的。
正如之前所說,華為和微軟共同開發(fā)的應(yīng)用似乎是Mate 10上最吸引人的應(yīng)用,因此我們可以在此基礎(chǔ)之上進(jìn)行更多的探索。
目前來看,該應(yīng)用能夠智能識別傳統(tǒng)的外文文本,并進(jìn)行翻譯,那么在未來是否可以AR方面的應(yīng)用呢?
聯(lián)發(fā)科在CES上為我們展示了一個相關(guān)的識別的例子:使用神經(jīng)網(wǎng)絡(luò)的視頻會議編碼器能夠?qū)γ绹芯€電視新聞網(wǎng)的圖像和視頻進(jìn)行識別,并反饋給編碼器,從而提升視頻的質(zhì)量。
在未來,可以想見,越來越多的設(shè)備將會采用這類IP,開發(fā)人員也能夠更容易的開發(fā)相關(guān)應(yīng)用。
最后的思考
我在這篇文章里,并不是想強(qiáng)調(diào)麒麟970到底有多么的先進(jìn),只是希望借此機(jī)會表明,未來高端安卓智能手機(jī)處理器的競爭和發(fā)展格局將會出現(xiàn)很多令人振奮的變化。
隨著iPhone智能手機(jī)生態(tài)系統(tǒng)進(jìn)入10周年,我們也看到越來越多的垂直整合設(shè)備的出現(xiàn)。
并不是說蘋果就一定是規(guī)則的制定者,只是在未來,一個更加成熟的生態(tài)系統(tǒng)當(dāng)中,公司都需要能夠自主的把控發(fā)展路線。否則,手機(jī)廠商將很難與其他廠商區(qū)分開來,更不用說為用戶提供差異化的功能,或者與其他廠商競爭。
蘋果很早就意識到了這一點(diǎn)。而華為也是目前為止唯一一家能夠獨(dú)自設(shè)立目前的OEM廠商。
同時,還有很多準(zhǔn)獨(dú)立廠商也在努力設(shè)計自己的芯片,他們憑借從IP供應(yīng)商那里獲得的CPU和GPU等關(guān)鍵零部件來進(jìn)行設(shè)計。
根本上來說,麒麟970在CPU的性能與功率上面并沒有與驍龍835有太大的差距,其誤差只是體現(xiàn)在cortex-a73在實際應(yīng)用中的體現(xiàn)而已。
考慮到驍龍820所采用的CPU雖然與三星自主開發(fā)的CPU略有差距,但是在實際應(yīng)用中并不明顯,而且三星到目前未知也沒有計劃去全力發(fā)展和整合自主CPU,考慮到這些,華為采用ARM CPU還是很有道理的。
而高通本身在自主設(shè)計CPU和GPU方面都具有一定的自主掌控能力,并與其它廠商有著很大的差距。
想象一下,在桌面GPU上領(lǐng)先的英偉達(dá),與競爭對手相比,擁有33%的效率競爭優(yōu)勢,當(dāng)這一優(yōu)勢擴(kuò)大到75-90%的時候,這種選擇就不言而喻了。
這種情況之下,廠商可以通過使用更大的GPU來補(bǔ)償效率和性能方面的缺陷,而這些體驗,終端用戶幾乎很難感覺到。
但是,這是一種不可持續(xù)的方案,因為這種方式正在不斷蠶食廠商的毛利率。
除了CPU和GPU以及調(diào)制解調(diào)器IP之外,手機(jī)還需要更多的組件,這里就不深入探討。
比如說,在麒麟970中使用的 Cadence Tensilica Vision P6 DSP確實能夠提升相機(jī)的性能,但是也需要從軟件方面來進(jìn)行支持才可以。
NPU是一種尚處于起步階段的新興IP,麒麟970有很多競爭對手嗎?并沒有。這一功能為產(chǎn)品增加了競爭力嗎?確實有,但可能沒有想象中那么大。
軟件生態(tài)系統(tǒng)的發(fā)展確實會拖慢手機(jī)產(chǎn)業(yè)的發(fā)展,但是沒有相關(guān)硬件的支持,很多應(yīng)用只有軟件也是沒有辦法實現(xiàn)的。
華為的這一策略將來在全行業(yè)采用將是不可避免的。
海思的NPU芯片證明海思作為一家芯片設(shè)計公司也能夠設(shè)計出與高通,三星匹敵的處理器。但是,海思的發(fā)布時間并不遵循傳統(tǒng)安卓手機(jī)廠商的發(fā)布規(guī)律,因此我們預(yù)計會有新的處理出現(xiàn),在性能方面超過麒麟970。
現(xiàn)實是,華為是能夠?qū)⑿酒O(shè)計和終端產(chǎn)品整合在一起的唯一兩家OEM供應(yīng)商之一(編者按:其實三星也算一家,但是三星似乎采用高通的方案更多),也是唯一一家安卓廠商。在過去的幾年里,這家廠商已經(jīng)走過了漫長的道路,經(jīng)歷了太多的改進(jìn)。最重要的是,華為始終能夠把目標(biāo)和執(zhí)行目標(biāo)放在一起,堅定不移的朝著移動業(yè)務(wù)這一正確方向發(fā)展,這是他們成功的關(guān)鍵原因。
但對這家中國廠商來說,未來的路還是很長。
-
處理器
+關(guān)注
關(guān)注
68文章
19409瀏覽量
231193 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4781瀏覽量
101175 -
云服務(wù)器
+關(guān)注
關(guān)注
0文章
734瀏覽量
13423
發(fā)布評論請先 登錄
相關(guān)推薦
NPU是如何發(fā)展起來的?性能受哪些因素影響?
NPU支持的編程語言有哪些
NPU的工作原理解析
如何選擇合適的NPU型號
NPU的市場前景與發(fā)展趨勢
NPU在邊緣計算中的優(yōu)勢
NPU技術(shù)如何提升AI性能
什么是NPU芯片及其功能
NPU與GPU的性能對比
RK3588 技術(shù)分享 | 在Android系統(tǒng)中使用NPU實現(xiàn)Yolov5分類檢測
什么是NPU?什么場景需要配置NPU?
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析
基于RK3588的NPU案例分享!6T是真的強(qiáng)!
芯品# 物聯(lián)網(wǎng)市場性能最高的 NPU





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論