") 淺析微服務架構(gòu)中的監(jiān)控系統(tǒng)
淺析微服務架構(gòu)中的監(jiān)控系統(tǒng)
今天這篇文章我們來聊一聊一個重要模塊:「 監(jiān)控系統(tǒng) 」。
因為在微服務的架構(gòu)下,我們對服務進行了拆分,所以用戶的每次請求不再是由某一個服務獨立完成了,而是變成了多個服務一起配合完成。這種情況下,一旦請求出現(xiàn)異常,我們必須得知道是在哪個服務環(huán)節(jié)出了故障,就需要對每一個服務,以及各個指標都進行全面的監(jiān)控。
一、什么是「 監(jiān)控系統(tǒng) 」?
在微服務架構(gòu)中,監(jiān)控系統(tǒng)按照原理和作用大致可以分為三類(并非嚴格分類,僅從日常使用角度來看):
日志類(Log)
調(diào)用鏈類(Tracing)
度量類(Metrics)
下面來分別對這三種常見的監(jiān)控模式進行說明:
日志類(Log)
日志類比較常見,我們的框架代碼、系統(tǒng)環(huán)境、以及業(yè)務邏輯中一般都會產(chǎn)出一些日志,這些日志我們通常把它記錄后統(tǒng)一收集起來,方便在需要的時候進行查詢。
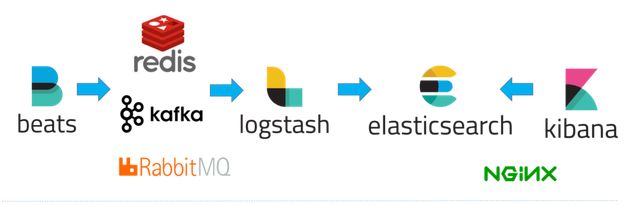
日志類記錄的信息一般是一些事件、非結(jié)構(gòu)化的一些文本內(nèi)容。日志的輸出和處理的解決方案比較多,大家熟知的有 ELK Stack 方案(Elasticseach + Logstash + Kibana),如圖:

使用Beats(可選)在每臺服務器上安裝后,作為日志客戶端收集器,然后通過Logstash進行統(tǒng)一的日志收集、解析、過濾等處理,再將數(shù)據(jù)發(fā)送給Elasticsearch中進行存儲分析,最后使用Kibana來進行數(shù)據(jù)的展示。
當然還可以升級方案為:
這些方案都比較成熟,搭建起來也比較簡單,除了用作監(jiān)控系統(tǒng)以外,還可以作為日志查詢系統(tǒng)使用,非常適用于做分析、以及問題調(diào)試使用。
調(diào)用鏈類(Tracing)
調(diào)用鏈類監(jiān)控主要是指記錄一個請求的全部流程。一個請求從開始進入,在微服務中調(diào)用不同的服務節(jié)點后,再返回給客戶端,在這個過程中通過調(diào)用鏈參數(shù)來追尋全鏈路行為。通過這個方式可以很方便的知道請求在哪個環(huán)節(jié)出了故障,系統(tǒng)的瓶頸在哪兒。
這一類的監(jiān)控一般采用 CAT 工具 來完成,一般在大中型項目較多用到,因為搭建起來有一定的成本。后面會有單獨文章來講解這個調(diào)用鏈監(jiān)控系統(tǒng)。
度量類(Metrics)
度量類主要采用時序數(shù)據(jù)庫的解決方案。它是以事件發(fā)生時間以及當前數(shù)值的角度來記錄的監(jiān)控信息,是可以聚合運算的,用于查看一些指標數(shù)據(jù)和指標趨勢。所以這類監(jiān)控主要不是用來查問題的,主要是用來看趨勢的。
Metrics一般有5種基本的度量類型:Gauges(度量)、Counters(計數(shù)器)、 Histograms(直方圖)、 Meters(TPS計算器)、Timers(計時器)。
基于時間序列數(shù)據(jù)庫的監(jiān)控系統(tǒng)是非常適合做監(jiān)控告警使用的,所以現(xiàn)在也比較流行這個方案,如果我們要搭建一套新的監(jiān)控系統(tǒng),我也建議參考這類方案進行。
因此本文接下來也會重點以時間序列數(shù)據(jù)庫的監(jiān)控系統(tǒng)為主角來描述。
二、「 監(jiān)控系統(tǒng) 」關注的對象和指標都是什么?
一般我們做「監(jiān)控系統(tǒng)」都是需要做分層式監(jiān)控的,也就是說將我們要監(jiān)控的對象進行分層,一般主要分為:
系統(tǒng)層:系統(tǒng)層主要是指CPU、磁盤、內(nèi)存、網(wǎng)絡等服務器層面的監(jiān)控,這些一般也是運維同學比較關注的對象。
應用層:應用層指的是服務角度的監(jiān)控,比如接口、框架、某個服務的健康狀態(tài)等,一般是服務開發(fā)或框架開發(fā)人員關注的對象。
用戶層:這一層主要是與用戶、與業(yè)務相關的一些監(jiān)控,屬于功能層面的,大多數(shù)是項目經(jīng)理或產(chǎn)品經(jīng)理會比較關注的對象。
知道了監(jiān)控的分層后,我們再來看一下監(jiān)控的指標一般有哪些:
延遲時間:主要是響應一個請求所消耗的延遲,比如某接口的HTTP請求平均響應時間為100ms。
請求量:是指系統(tǒng)的容量吞吐能力,例如每秒處理多少次請求(QPS)作為指標。
錯誤率:主要是用來監(jiān)控錯誤發(fā)生的比例,比如將某接口一段時間內(nèi)調(diào)用時失敗的比例作為指標。
三、基于時序數(shù)據(jù)庫的「 監(jiān)控系統(tǒng) 」有哪些?
下面介紹幾款目前業(yè)內(nèi)比較流行的基于時間序列數(shù)據(jù)庫的開源監(jiān)控方案:
Prometheus
Promethes是一款2012年開源的監(jiān)控框架,其本質(zhì)是時間序列數(shù)據(jù)庫,由Google前員工所開發(fā)。
Promethes采用拉的模式(Pull)從應用中拉取數(shù)據(jù),并還支持 Alert 模塊可以實現(xiàn)監(jiān)控預警。它的性能非常強勁,單機可以消費百萬級時間序列。
架構(gòu)如下:
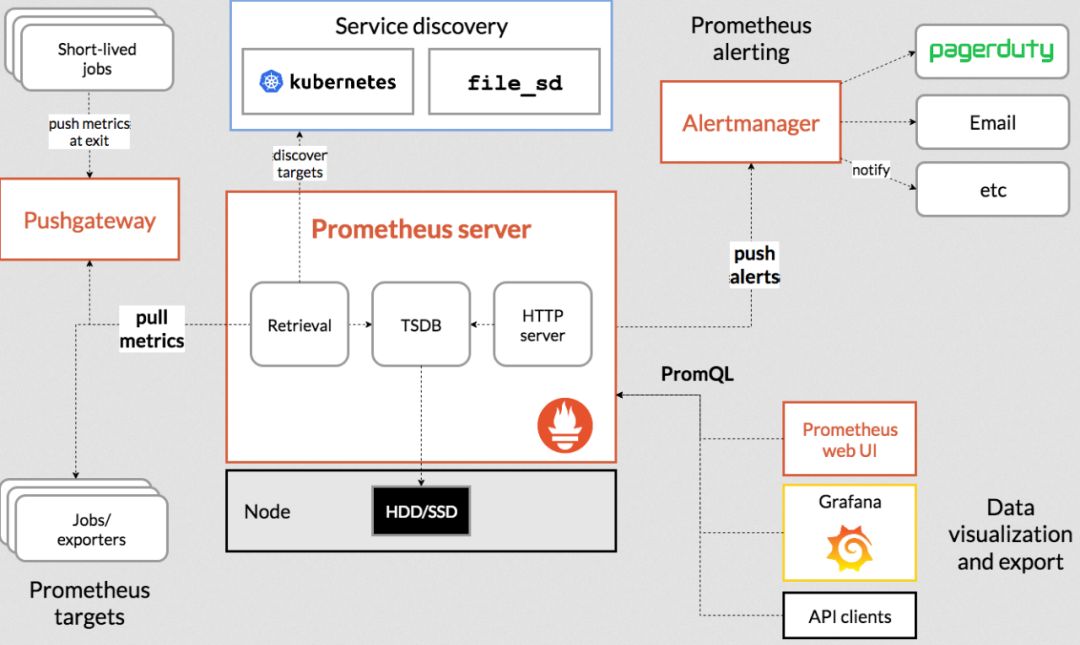
從看圖的左下角可以看到,Prometheus 可以通過在應用里進行埋點后Pull到 Prometheus Server里,如果應用不支持埋點,也可以采用exporter方式進行數(shù)據(jù)采集。
從圖的左上角可以看到,對于一些定時任務模塊,因為是周期性運行的,所以采用拉的方式無法獲取數(shù)據(jù),那么Prometheus 也提供了一種推數(shù)據(jù)的方式,但是并不是推送到Prometheus Server中,而是中間搭建一個 Pushgateway,定時任務模塊將metrics信息推送到這個Pushgateway中,然后Prometheus Server再依然采用拉的方式從Pushgateway中獲取數(shù)據(jù)。
需要拉取的數(shù)據(jù)既可以采用靜態(tài)方式配置在Prometheus Server中,也可以采用服務發(fā)現(xiàn)的方式(即圖的中間上面的Service discovery所示)。
PromQL:是Prometheus自帶的查詢語法,通過編寫PromQL語句可以查詢Prometheus里面的數(shù)據(jù)。
Alertmanager:是用于數(shù)據(jù)的預警模塊,支持通過多種方式去發(fā)送預警。
WebUI:是用來展示數(shù)據(jù)和圖形的,但是一般大多數(shù)是與Grafana結(jié)合,采用Grafana來展示。
OpenTSDB
OpenTSDB是在2010年開源的一款分布式時序數(shù)據(jù)庫,當然其主要用于監(jiān)控方案中。
OpenTSDB采用的是Hbase的分布式存儲,它獲取數(shù)據(jù)的模式與Prometheus不同,它采用的是推模式(Push)。
在展示層,OpenTSDB自帶有WebUI視圖,也可以與Grafana很好的集成,提供豐富的展示界面。
但OpenTSDB并沒有自帶預警模塊,需要自己去開發(fā)或者與第三方組件結(jié)合使用。
可以通過下圖來了解一下OpenTSDB的架構(gòu):

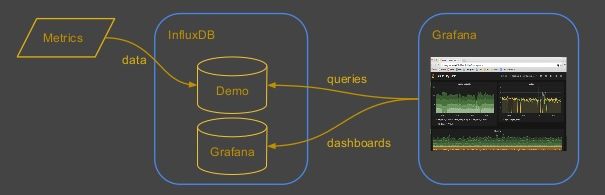
InfluxDB
InfluxDB是在2013年開源的一款時序數(shù)據(jù)庫,在這里我們主要還是用于做監(jiān)控系統(tǒng)方案。它收集數(shù)據(jù)也是采用推模式(Push)。在展示層,InfluxDB也是自帶WebUI,也可以與Grafana集成。
以上,就是對微服務架構(gòu)中「 監(jiān)控系統(tǒng)」的一些思考。
-
監(jiān)控系統(tǒng)
+關注
關注
21文章
3941瀏覽量
176863 -
服務架構(gòu)
+關注
關注
0文章
3瀏覽量
6188
原文標題:微服務架構(gòu)之「 監(jiān)控系統(tǒng) 」
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
微服務架構(gòu)和CQRS架構(gòu)基本概念介紹
微服務架構(gòu)與實踐摘要
微服務優(yōu)勢_微服務架構(gòu)的好處與不足
微服務架構(gòu)與實踐基礎篇

什么是微服務架構(gòu)_微服務架構(gòu)的優(yōu)缺點及應用
微服務架構(gòu)有哪些_微服務架構(gòu)設計模式
微服務軟件架構(gòu)應用研究綜述
微服務架構(gòu)中的服務之間如何互相調(diào)用呢?
什么是微服務架構(gòu)?
從分層架構(gòu)到微服務架構(gòu)介紹(五)
springcloud微服務架構(gòu)
docker微服務架構(gòu)實戰(zhàn)
設計微服務架構(gòu)的原則






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論