") 深度學習模型小型化處理的五種方法
深度學習模型小型化處理的五種方法
實習終于結(jié)束了,現(xiàn)把實習期間做的基于人體姿態(tài)估計的模型小型化的工作做個總結(jié)。
現(xiàn)在深度學習模型開始走向應用,因此我們需要把深度學習網(wǎng)絡和模型部署到一些硬件上,而現(xiàn)有一些模型的參數(shù)量由于過大,會導致在一些硬件上的運行速度很慢,所以我們需要對深度學習模型進行小型化處理。模型小型化旨在保證模型效果不會明顯下降的情況下降低模型的參數(shù)量,從而提高模型的運算速度。
以下是幾種模型小型化的方法:
1、修改某些卷積層的num_output
其實很多模型的參數(shù)都有冗余,有些層根本不需要很多的卷積核,所以,通過修改該參數(shù)可以降低一部分的參數(shù)量。
2、使用分離通道卷積(depthwise separable convolution)
對某些卷積層使用分離通道卷積的方法。使用分離通道卷積可以去掉一部分冗余的參數(shù)。分離通道卷積與常用卷積的不同之處在于,標準卷積操作中,每個卷積核都要對輸入的所有通道的特征進行卷積,然后結(jié)合生成一個對應的特征。分離通道卷積中,分為兩步,第一步使用分離通道卷積,每個卷積核只對一個通道進行卷積。第二步,使用1x1的標準卷積整合分離通道卷積輸出的特征。分離通道卷積時,各個通道之間的特征信息沒有交互,之后會采用一個1*1的標準卷積運算,使分離通道卷積輸出的特征的通道之間的信息有了一個交互。在tensorflow中,有對應的tf.nn.depthwise_conv2d接口可以很方便地實現(xiàn)分離通道卷積。
標準卷積和分離通道卷積的示意圖如下
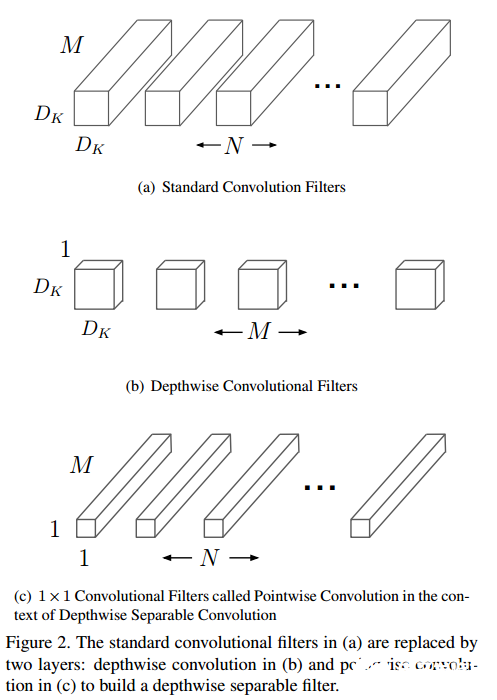
參考論文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
3、使用channel shuffle方法
channel shuffle方法是在分離通道卷積方法的基礎(chǔ)上做的改進,將分離通道卷積之后的1*1的全卷積替換為channel shuffle。
參考論文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
4、使用ThiNet方法
ThiNet方法是尋找一些對輸出特征貢獻較小的卷積核,將其裁剪掉,從而降低參數(shù)量。屬于第一種方法的延伸。
參考論文:ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression
5、改變網(wǎng)絡結(jié)構(gòu)
現(xiàn)在常見的網(wǎng)絡結(jié)構(gòu)有:以VGG為代表的單支流網(wǎng)絡結(jié)構(gòu),GoogLeNet的Inception類型的網(wǎng)絡結(jié)構(gòu),ResNet的殘差結(jié)構(gòu),還有DenseNet的結(jié)構(gòu)(類似殘差結(jié)構(gòu),把殘差結(jié)構(gòu)中特征的相加變?yōu)樘卣髌唇樱T谠?jīng)的ImageNet的比賽中,GoogLeNet取得了比VGG更好的成績,但是GoogLeNet的參數(shù)量卻比VGG小很多,這說明通過改變網(wǎng)絡結(jié)構(gòu),我們不僅可以減低模型的參數(shù)量,還可能會提升模型的效果。
前四種方法都是在原有網(wǎng)絡上進行的操作,一般不會對網(wǎng)絡結(jié)構(gòu)造成太大改變。而第五種方法則是徹底改變了網(wǎng)絡的結(jié)構(gòu)。
我們將模型的參數(shù)量降低后,如果隨機初始化,模型由于參數(shù)量較小,很難達到原有的效果,所以構(gòu)造了新的網(wǎng)絡之后還會涉及到重構(gòu)。
重構(gòu)其實是為了得到一個較好的初始化模型。我們一般去重構(gòu)網(wǎng)絡的倒數(shù)第二層的輸出特征,因為最終的結(jié)果都是在倒數(shù)第二層的輸出特征上得到的。但有時我們還會去重構(gòu)其他卷積層輸出的特征,比如一個較深的網(wǎng)絡,我們單純地去重構(gòu)倒數(shù)第二層的特征也很難得到一個較好的初始化模型,因為監(jiān)督信息(即重構(gòu)時的loss)太靠后,前面的層很難學習到,所以有時我們可以將網(wǎng)絡分為幾個部分,依次重構(gòu),先重構(gòu)前面的,然后使用重構(gòu)好的模型去重構(gòu)后面的部分。
使用ThiNet方法,每裁剪完一層之后都要做finetunign,然后再裁剪下一層。我們也可以每裁剪完一層之后去做重構(gòu),全部都裁剪完之后,做姿態(tài)估計訓練。
我們還可以重構(gòu)和姿態(tài)估計訓練一起做,使用兩個監(jiān)督信息(即重構(gòu)和姿態(tài)估計兩個loss)使模型邊重構(gòu)邊訓練,我們將其稱為mimick。
這就是我在模型小型化的工作中使用到的一些方法。但如何使用這些方法才能得到一個好的結(jié)果,這還需要親自去嘗試。
-
深度學習
+關(guān)注
關(guān)注
73文章
5513瀏覽量
121546
發(fā)布評論請先 登錄
相關(guān)推薦
深度學習模型是如何創(chuàng)建的?
什么是深度學習?使用FPGA進行深度學習的好處?
基于優(yōu)化數(shù)據(jù)處理的深度信念網(wǎng)絡模型的入侵檢測方法
模型驅(qū)動深度學習的標準流程與學習方法解析

一種小型化射頻收發(fā)前端的設計詳細教程
如何使用MATLAB實現(xiàn)深度學習的方法研究分析
大模型為什么是深度學習的未來?
深度學習的模型優(yōu)化與調(diào)試方法
人臉檢測的五種方法各有什么特征和優(yōu)缺點
深度學習模型量化方法







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論