") hadoop環(huán)境的基本概念和部署方法
hadoop環(huán)境的基本概念和部署方法
1概述
1.1目的
初步了解hadoop,初步掌握hadoop環(huán)境的部署方法。
1.2基本概念
hadoop的核心主要包含:HDFS和MapReduce
HDFS是分布式文件系統(tǒng),用于分布式存儲(chǔ)海量數(shù)據(jù)。
MapReduce是分布式數(shù)據(jù)處理模型,本質(zhì)是并行處理
2基本概念
2.1HDFS
2.1.1HDFS是什么?
HADOOP DISTRIBUTED FILE SYSTEM,簡(jiǎn)稱HDFS,是一個(gè)分布式文件系統(tǒng)。它是谷歌的GFS提出之后出現(xiàn)的另外一種文件系統(tǒng)。它有一定高度的容錯(cuò)性,而且提供了高吞吐量的數(shù)據(jù)訪問(wèn),非常適合大規(guī)模數(shù)據(jù)集上的應(yīng)用。HDFS 提供了一個(gè)高度容錯(cuò)性和高吞吐量的海量數(shù)據(jù)存儲(chǔ)解決方案。
在最初,HADOOP是作為Apache Nutch搜索引擎項(xiàng)目的基礎(chǔ)架構(gòu)而開發(fā)的,后來(lái)由于它獨(dú)有的特性,讓它成為HADOOP CORE項(xiàng)目的一部分。
2.1.2HDFS的設(shè)計(jì)思路?
是什么提供它高吞吐量的數(shù)據(jù)訪問(wèn)和適合大規(guī)模數(shù)據(jù)集的應(yīng)用的特性呢,這就要說(shuō)一下它的設(shè)計(jì)思路。
首先HDFS的設(shè)計(jì)之初就是針對(duì)超大文件的存儲(chǔ)的,小文件不會(huì)提高訪問(wèn)和存儲(chǔ)速度,反而會(huì)降低;其次它采用了最高效的訪問(wèn)模式,也就是經(jīng)常所說(shuō)的流式數(shù)據(jù)訪問(wèn),特點(diǎn)就是一次寫入多次讀取;再有就是它運(yùn)行在普通的硬件之上的,即使硬件故障,也就通過(guò)容錯(cuò)來(lái)保證數(shù)據(jù)的高可用。
2.1.3HDFS的一些概念
Block:大文件的存儲(chǔ)會(huì)被分割為多個(gè)block進(jìn)行存儲(chǔ)。默認(rèn)為64MB,每一個(gè)blok會(huì)在多個(gè)datanode上存儲(chǔ)多份副本,默認(rèn)為3份。[這些設(shè)置都能夠通過(guò)配置文件進(jìn)行更改]
Namenode:主要負(fù)責(zé)存儲(chǔ)一些metadata信息,主要包括文件目錄、block和文件對(duì)應(yīng)關(guān)系,以及block和datanote的對(duì)應(yīng)關(guān)系
Datanode:負(fù)責(zé)存儲(chǔ)數(shù)據(jù),上面我們所說(shuō)的高度的容錯(cuò)性大部分在datanode上實(shí)現(xiàn)的[還有一部分容錯(cuò)性是體現(xiàn)在namenode和secondname,還有jobtracker的容錯(cuò)等]。
2.1.4HDFS的基礎(chǔ)架構(gòu)圖
HDFS的基礎(chǔ)架構(gòu)圖
2.1.5解析HDFS帶來(lái)的好處
高吞吐量訪問(wèn):HDFS的每個(gè)block分布在不同的rack上,在用戶訪問(wèn)時(shí),HDFS會(huì)計(jì)算使用最近和訪問(wèn)量最小的服務(wù)器給用戶提供。由于block在不同的rack上都有備份,所以不再是單數(shù)據(jù)訪問(wèn),所以速度和效率是非常快的。另外HDFS可以并行從服務(wù)器集群中讀寫,增加了文件讀寫的訪問(wèn)帶寬。
高容錯(cuò)性:上面簡(jiǎn)單的介紹了一下高度容錯(cuò)。系統(tǒng)故障是不可避免的,如何做到故障之后的數(shù)據(jù)恢復(fù)和容錯(cuò)處理是至關(guān)重要的。HDFS通過(guò)多方面保證數(shù)據(jù)的可靠性,多分復(fù)制并且分布到物理位置的不同服務(wù)器上,數(shù)據(jù)校驗(yàn)功能、后臺(tái)的連續(xù)自檢數(shù)據(jù)一致性功能,都為高容錯(cuò)提供了可能。
容量擴(kuò)充:因?yàn)镠DFS的block信息存放到namenode上,文件的block分布到datanode上,當(dāng)擴(kuò)充的時(shí)候,僅僅添加datanode數(shù)量,系統(tǒng)可以在不停止服務(wù)的情況下做擴(kuò)充,不需要人工干預(yù)。
2.2MapReduce
從它名字上來(lái)看就大致可以看出個(gè)緣由,兩個(gè)動(dòng)詞Map和Reduce。
Map(展開)就是將一個(gè)任務(wù)分解成為多個(gè)任務(wù),Reduce就是將分解后多任務(wù)處理的結(jié)果匯總起來(lái),得出最后的分析結(jié)果。
2.2.1MapReduce原理
在Hadoop中,每個(gè)MapReduce任務(wù)都被初始化為一個(gè)Job,每個(gè)Job又可以分為兩種階段:map階段和reduce階段。這兩個(gè)階段分別用兩個(gè)函數(shù)表示,即map函數(shù)和reduce函數(shù)。map函數(shù)接收一個(gè)
2.2.2Map的過(guò)程
MapRunnable從input split中讀取一個(gè)個(gè)的record,然后依次調(diào)用Mapper的map函數(shù),將結(jié)果輸出。map的輸出并不是直接寫入硬盤,而是將其寫入緩存memory buffer。當(dāng)buffer中數(shù)據(jù)的到達(dá)一定的大小,一個(gè)背景線程將數(shù)據(jù)開始寫入硬盤。在寫入硬盤之前,內(nèi)存中的數(shù)據(jù)通過(guò)partitioner分成多個(gè)partition。在同一個(gè)partition中,背景線程會(huì)將數(shù)據(jù)按照key在內(nèi)存中排序。每次從內(nèi)存向硬盤flush數(shù)據(jù),都生成一個(gè)新的spill文件。
當(dāng)此task結(jié)束之前,所有的spill文件被合并為一個(gè)整的被partition的而且排好序的文件。reducer可以通過(guò)http協(xié)議請(qǐng)求map的輸出文件,tracker.http.threads可以設(shè)置http服務(wù)線程數(shù)。
2.2.3Reduce的過(guò)程
當(dāng)map task結(jié)束后,其通知TaskTracker,TaskTracker通知JobTracker。對(duì)于一個(gè)job,JobTracker知道TaskTracer和map輸出的對(duì)應(yīng)關(guān)系。reducer中一個(gè)線程周期性的向JobTracker請(qǐng)求map輸出的位置,直到其取得了所有的map輸出。reduce task需要其對(duì)應(yīng)的partition的所有的map輸出。reduce task中的copy過(guò)程即當(dāng)每個(gè)map task結(jié)束的時(shí)候就開始拷貝輸出,因?yàn)椴煌膍ap task完成時(shí)間不同。reduce task中有多個(gè)copy線程,可以并行拷貝map輸出。當(dāng)很多map輸出拷貝到reduce task后,一個(gè)背景線程將其合并為一個(gè)大的排好序的文件。當(dāng)所有的map輸出都拷貝到reduce task后,進(jìn)入sort過(guò)程,將所有的map輸出合并為大的排好序的文件。最后進(jìn)入reduce過(guò)程,調(diào)用reducer的reduce函數(shù),處理排好序的輸出的每個(gè)key,最后的結(jié)果寫入HDFS。
-
Hadoop
+關(guān)注
關(guān)注
1文章
90瀏覽量
16042 -
HDFS
+關(guān)注
關(guān)注
1文章
30瀏覽量
9641
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
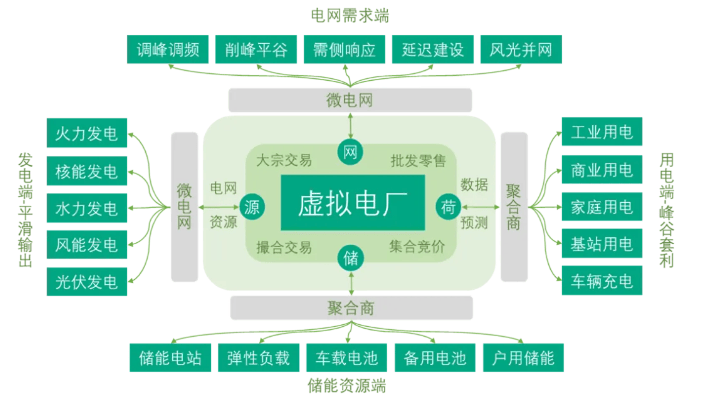
了解虛擬電廠的基本概念
地線基本概念、分類及在應(yīng)用中的設(shè)計(jì)與處理方法
Linux應(yīng)用編程的基本概念
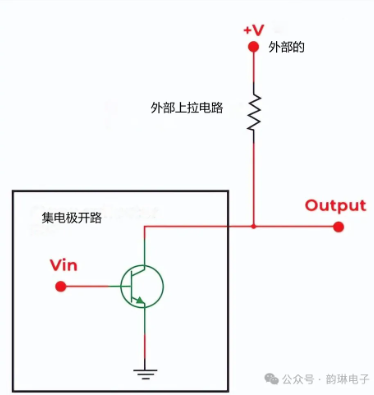
集電極開路的基本概念與原理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論