") CUDA 6中的統(tǒng)一內(nèi)存模型
CUDA 6中的統(tǒng)一內(nèi)存模型
CUDA介紹
CUDA(Compute Unified Device Architecture,統(tǒng)一計(jì)算設(shè)備架構(gòu))是由NVIDIA公司于 2006 年所推出的一種并行計(jì)算技術(shù),是該公司對(duì)于GPGPU( General-purpose computing on graphics processing units, 圖形處理單元上的通用計(jì)算 )技術(shù)的正式命名。通過(guò)此技術(shù),用戶(hù)可在GPU上進(jìn)行通用計(jì)算,而開(kāi)發(fā)人員可以使用C語(yǔ)言來(lái)為CUDA架構(gòu)編寫(xiě)程序 。相比CPU,擁有CUDA技術(shù)的GPU成本不高,但計(jì)算性能很突出。本文中提到的是2014年發(fā)布的CUDA6, CUDA6最重要的新特性就是支持統(tǒng)一內(nèi)存模型(Unified Memory)。
注:文中經(jīng)常出現(xiàn)“主機(jī)和設(shè)備”,本文的“主機(jī)”特指CPU、“設(shè)備”特指GPU。
CUDA 6中的統(tǒng)一內(nèi)存模型
NVIDIA在CUDA 6中引入了統(tǒng)一內(nèi)存模型 ( Unified Memory ),這是CUDA歷史上最重要的編程模型改進(jìn)之一。在當(dāng)今典型的PC或群集節(jié)點(diǎn)中,CPU和GPU的內(nèi)存在物理上是獨(dú)立的,并通過(guò)PCI-Express總線(xiàn)相連。在CUDA6之前, 這是程序員最需要注意的地方。CPU和GPU之間共享的數(shù)據(jù)必須在兩個(gè)內(nèi)存中都分配,并由程序直接地在兩個(gè)內(nèi)存之間來(lái)回復(fù)制。這給CUDA編程帶來(lái)了很大難度。
統(tǒng)一內(nèi)存模型創(chuàng)建了一個(gè)托管內(nèi)存池(a pool of managed memory),該托管內(nèi)存池由CPU和GPU共享,跨越了CPU與GPU之間的鴻溝。CPU和GPU都可以使用單指針訪(fǎng)問(wèn)托管內(nèi)存。關(guān)鍵是系統(tǒng)會(huì)自動(dòng)地在主機(jī)和設(shè)備之間遷移在統(tǒng)一內(nèi)存中分配的數(shù)據(jù),從而使那些看起來(lái)像CPU內(nèi)存中的代碼在CPU上運(yùn)行,而另一些看起來(lái)像GPU內(nèi)存中的代碼在GPU上運(yùn)行。
在本文中,我將向您展示統(tǒng)一內(nèi)存模型如何顯著簡(jiǎn)化GPU加速型應(yīng)用程序中的內(nèi)存管理。下圖顯示了一個(gè)非常簡(jiǎn)單的示例。兩種代碼都從磁盤(pán)加載文件,對(duì)其中的字節(jié)進(jìn)行排序,然后在釋放內(nèi)存之前使用CPU上已排序的數(shù)據(jù)。右側(cè)的代碼使用CUDA和統(tǒng)一內(nèi)存模型在GPU上運(yùn)行。和左邊代碼唯一的區(qū)別是,右邊代碼由GPU來(lái)啟動(dòng)一個(gè)內(nèi)核(并在啟動(dòng)后進(jìn)行同步),并使用新的API cudaMallocManaged() 在統(tǒng)一內(nèi)存模型中為加載的文件分配空間。
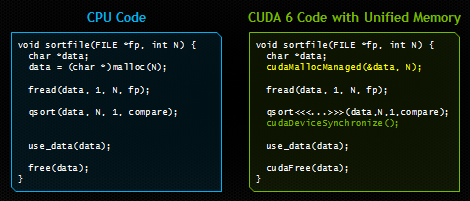
如果您曾經(jīng)編程過(guò)CUDA C / C++,那么毫無(wú)疑問(wèn),右側(cè)的代碼會(huì)為您帶來(lái)震撼。請(qǐng)注意,我們只分配了一次內(nèi)存,并且只有一個(gè)指針指向主機(jī)和設(shè)備上的可訪(fǎng)問(wèn)數(shù)據(jù)。我們可以直接地將文件的內(nèi)容讀取到已分配的內(nèi)存,然后就可以將內(nèi)存的指針傳遞給在設(shè)備上運(yùn)行的CUDA內(nèi)核。然后,在等待內(nèi)核處理完成之后,我們可以再次從CPU訪(fǎng)問(wèn)數(shù)據(jù)。CUDA運(yùn)行時(shí)隱藏了所有復(fù)雜性,自動(dòng)將數(shù)據(jù)遷移到訪(fǎng)問(wèn)它的地方。
統(tǒng)一內(nèi)存模型提供了什么
統(tǒng)一內(nèi)存模型為程序員提供了兩大捷徑
簡(jiǎn)化編程、簡(jiǎn)化內(nèi)存模型
統(tǒng)一內(nèi)存模型通過(guò)使設(shè)備內(nèi)存管理(device memory management)成為一項(xiàng)可選的優(yōu)化,而不是一項(xiàng)硬性的要求,從而降低了CUDA平臺(tái)上并行編程的門(mén)檻。借助統(tǒng)一內(nèi)存模型,程序員現(xiàn)在可以直接開(kāi)發(fā)并行的CUDA內(nèi)核,而不必?fù)?dān)心分配和復(fù)制設(shè)備內(nèi)存的細(xì)節(jié)。這將降低在CUDA平臺(tái)上編程的學(xué)習(xí)成本,也使得將現(xiàn)有代碼移植到GPU的工作變得容易。但這些好處不僅有利于初學(xué)者。我在本文后面的示例中將展示統(tǒng)一內(nèi)存模型如何使復(fù)雜的數(shù)據(jù)結(jié)構(gòu)更易于與設(shè)備代碼一起使用,以及它與C++結(jié)合時(shí)的強(qiáng)大威力。
通過(guò)數(shù)據(jù)局部性原理提高性能
通過(guò)在CPU和GPU之間按需遷移數(shù)據(jù),統(tǒng)一內(nèi)存模型可以滿(mǎn)足GPU上本地?cái)?shù)據(jù)的性能需求,同時(shí)還提供了易于使用的全局共享數(shù)據(jù)。這個(gè)功能的復(fù)雜細(xì)節(jié)被 CUDA驅(qū)動(dòng)程序和運(yùn)行時(shí)隱藏了,以確保應(yīng)用程序代碼更易于編寫(xiě)。遷移的關(guān)鍵是從每個(gè)處理器獲得全部帶寬。250 GB / s的GDDR5內(nèi)存對(duì)于保證開(kāi)普勒( Kepler )GPU的計(jì)算吞吐量至關(guān)重要。
值得注意的是, 一個(gè)經(jīng)過(guò)精心調(diào)優(yōu)的CUDA程序,即使用流(streams)和 cudaMemcpyAsync來(lái)有效地將執(zhí)行命令與數(shù)據(jù)傳輸重疊的程序,會(huì)比僅使用統(tǒng)一內(nèi)存模型的CUDA程序更好 。可以理解的是:CUDA運(yùn)行時(shí)從來(lái)沒(méi)有像程序員那樣提供何處需要數(shù)據(jù)或何時(shí)需要數(shù)據(jù)的信息!CUDA程序員仍然可以顯式地訪(fǎng)問(wèn)設(shè)備內(nèi)存分配和異步內(nèi)存拷貝,以?xún)?yōu)化數(shù)據(jù)管理和CPU-GPU并發(fā)機(jī)制 。首先,統(tǒng)一內(nèi)存模型提高了生產(chǎn)力,它為并行計(jì)算提供了更順暢的入口,同時(shí)它又不影響高級(jí)用戶(hù)的任何CUDA功能。
統(tǒng)一內(nèi)存模型 vs 統(tǒng)一虛擬尋址?
自CUDA4起,CUDA就支持統(tǒng)一虛擬尋址(UVA),并且盡管統(tǒng)一內(nèi)存模型依賴(lài)于UVA,但它們并不是一回事。UVA為 系統(tǒng)中的所有內(nèi)存提供了單個(gè)虛擬內(nèi)存地址空間,無(wú)論指針位于系統(tǒng)中的何處,無(wú)論在設(shè)備內(nèi)存(在相同或不同的GPU上)、主機(jī)內(nèi)存、或片上共享存儲(chǔ)器。UVA也允許 cudaMemcpy在不指定輸入和輸出參數(shù)確切位置的情況下使用。UVA啟用“零復(fù)制(Zero-Copy)” 內(nèi)存,“零復(fù)制”內(nèi)存是固定的主機(jī)內(nèi)存,可由設(shè)備上的代碼通過(guò)PCI-Express總線(xiàn)直接訪(fǎng)問(wèn),而無(wú)需使用 memcpy。零復(fù)制為統(tǒng)一內(nèi)存模型提供了一些便利,但是卻沒(méi)有提高性能,因?yàn)樗偸峭ㄟ^(guò)帶寬低而且延遲高的PCI-Express進(jìn)行訪(fǎng)問(wèn)。
UVA不會(huì)像統(tǒng)一內(nèi)存模型一樣自動(dòng)將數(shù)據(jù)從一個(gè)物理位置遷移到另一個(gè)物理位置。由于統(tǒng)一內(nèi)存模型能夠在主機(jī)和設(shè)備內(nèi)存之間的各級(jí)頁(yè)面自動(dòng)地遷移數(shù)據(jù),因此它需要進(jìn)行大量的工程設(shè)計(jì),因?yàn)樗枰贑UDA運(yùn)行時(shí)(runtime)、設(shè)備驅(qū)動(dòng)程序、甚至OS內(nèi)核中添加新功能。以下示例旨在讓您領(lǐng)會(huì)到這一點(diǎn)。示例:消除深層副本
統(tǒng)一內(nèi)存模型的主要優(yōu)勢(shì)在于,在訪(fǎng)問(wèn)GPU內(nèi)核中的結(jié)構(gòu)化數(shù)據(jù)時(shí),無(wú)需進(jìn)行深度復(fù)制(deep copies),從而簡(jiǎn)化了異構(gòu)計(jì)算內(nèi)存模型。如下圖所示,將包含指針的數(shù)據(jù)結(jié)構(gòu)從CPU傳遞到GPU要求進(jìn)行“深度復(fù)制”。
下面以struct dataElem為例。
struct dataElem {int prop1;int prop2;char *name;}
要在設(shè)備上使用此結(jié)構(gòu)體,我們必須復(fù)制結(jié)構(gòu)體本身及其數(shù)據(jù)成員,然后復(fù)制該結(jié)構(gòu)體指向的所有數(shù)據(jù),然后更新該結(jié)構(gòu)體。副本中的所有指針。這導(dǎo)致下面的復(fù)雜代碼,這些代碼只是將數(shù)據(jù)元素傳遞給內(nèi)核函數(shù)。
void launch(dataElem *elem) { dataElem *d_elem;char *d_name;
int namelen = strlen(elem-》name) + 1;
// Allocate storage for struct and name cudaMalloc(&d_elem, sizeof(dataElem)); cudaMalloc(&d_name, namelen);
// Copy up each piece separately, including new “name” pointer value cudaMemcpy(d_elem, elem, sizeof(dataElem), cudaMemcpyHostToDevice); cudaMemcpy(d_name, elem-》name, namelen, cudaMemcpyHostToDevice); cudaMemcpy(&(d_elem-》name), &d_name, sizeof(char*), cudaMemcpyHostToDevice);
// Finally we can launch our kernel, but CPU & GPU use different copies of “elem” Kernel《《《 。.. 》》》(d_elem);}
可以想象,在CPU和GPU代碼之間分享復(fù)雜的數(shù)據(jù)結(jié)構(gòu)所需的額外主機(jī)端代碼對(duì)生產(chǎn)率有嚴(yán)重影響。統(tǒng)一內(nèi)存模型中分配我們的“ dataElem”結(jié)構(gòu)可消除所有多余的設(shè)置代碼,這些代碼與主機(jī)代碼被相同的指針操作,留給我們的就只有內(nèi)核啟動(dòng)了。這是一個(gè)很大的進(jìn)步!
void launch(dataElem *elem) { kernel《《《 。.. 》》》(elem);}
但統(tǒng)一內(nèi)存模型不僅大幅降低了代碼復(fù)雜性。還可以做一些以前無(wú)法想象的事情。讓我們看另一個(gè)例子。
Example: CPU/GPU Shared Linked Lists
鏈表是一種非常常見(jiàn)的數(shù)據(jù)結(jié)構(gòu),但是由于它們本質(zhì)上是由指針組成的嵌套數(shù)據(jù)結(jié)構(gòu),因此在內(nèi)存空間之間傳遞它們非常復(fù)雜。如果沒(méi)有統(tǒng)一內(nèi)存模型,則無(wú)法在CPU和GPU之間分享鏈表。唯一的選擇是在零拷貝內(nèi)存(被pin住的主機(jī)內(nèi)存)中分配鏈表,這意味著GPU的訪(fǎng)問(wèn)受限于PCI-express性能。通過(guò)在統(tǒng)一內(nèi)存模型中分配鏈表數(shù)據(jù),設(shè)備代碼可以正常使用GPU上的指針,從而發(fā)揮設(shè)備內(nèi)存的全部性能。程序可以維護(hù)單鏈表,并且無(wú)論在主機(jī)或設(shè)備中都可以添加和刪除鏈表元素。
將具有復(fù)雜數(shù)據(jù)結(jié)構(gòu)的代碼移植到GPU上曾經(jīng)是一項(xiàng)艱巨的任務(wù),但是統(tǒng)一內(nèi)存模型使此操作變得非常容易。我希望統(tǒng)一內(nèi)存模型能夠?yàn)镃UDA程序員帶來(lái)巨大的生產(chǎn)力提升。
Unified Memory with C++
統(tǒng)一內(nèi)存模型確實(shí)在C++數(shù)據(jù)結(jié)構(gòu)中大放異彩。C++通過(guò)帶有拷貝構(gòu)造函數(shù)(copy constructors)的類(lèi)來(lái)簡(jiǎn)化深度復(fù)制問(wèn)題。拷貝構(gòu)造函數(shù)是一個(gè)知道如何創(chuàng)建類(lèi)所對(duì)應(yīng)對(duì)象的函數(shù),拷貝構(gòu)造函數(shù)為對(duì)象的成員分配空間并從其他對(duì)象復(fù)制值過(guò)來(lái)。C++還允許 new和 delete這倆個(gè)內(nèi)存管理運(yùn)算符被重載。這意味著我們可以創(chuàng)建一個(gè)基類(lèi),我們將其稱(chēng)為 Managed,它在重載的 new運(yùn)算符內(nèi)部使用 cudaMallocManaged(),如以下代碼所示。
class Managed {public:void *operator new(size_t len) {void *ptr; cudaMallocManaged(&ptr, len); cudaDeviceSynchronize();return ptr; }
void operator delete(void *ptr) { cudaDeviceSynchronize(); cudaFree(ptr); }};
然后,我們可以讓 String類(lèi)繼承 Managed類(lèi),并實(shí)現(xiàn)一個(gè)拷貝構(gòu)造函數(shù),該拷貝構(gòu)造函數(shù)為需要拷貝的字符串分配統(tǒng)一內(nèi)存。
// Deriving from “Managed” allows pass-by-referenceclass String : public Managed { int length; char *data;
public:// Unified memory copy constructor allows pass-by-value String (const String &s) { length = s.length; cudaMallocManaged(&data, length); memcpy(data, s.data, length); }
// 。..};
同樣,我們使我們的 dataElem類(lèi)也繼承 Managed。
// Note “managed” on this class, too.// C++ now handles our deep copiesclass dataElem : public Managed {public:int prop1;int prop2; String name;};
通過(guò)這些更改,C++的類(lèi)將在統(tǒng)一內(nèi)存中分配空間,并自動(dòng)處理深度復(fù)制。我們可以像分配任何C++的對(duì)象那樣在統(tǒng)一內(nèi)存中分配一個(gè) dataElem。
dataElem *data = new dataElem;
請(qǐng)注意,您需要確保樹(shù)中的每個(gè)類(lèi)都繼承自 Managed,否則您的內(nèi)存映射中會(huì)有一個(gè)漏洞。實(shí)際上,任何你想在CPU和GPU之間分享的內(nèi)容都應(yīng)該繼承 Managed。如果你傾向于對(duì)所有程序都簡(jiǎn)單地使用統(tǒng)一內(nèi)存模型,你可以在全局重載 new和 delete, 但這只在這種情況下有作用——你的程序中沒(méi)有僅被CPU訪(fǎng)問(wèn)的數(shù)據(jù)(即程序中的所有數(shù)據(jù)都被GPU訪(fǎng)問(wèn)),因?yàn)橹挥蠧PU數(shù)據(jù)時(shí)沒(méi)有必要遷移數(shù)據(jù)。
現(xiàn)在,我們可以選擇將對(duì)象傳遞給內(nèi)核函數(shù)了。如在C++中一樣,我們可以按值傳遞或按引用傳遞,如以下示例代碼所示。
// Pass-by-reference version__global__ void kernel_by_ref(dataElem &data) { 。.. }
// Pass-by-value version__global__ void kernel_by_val(dataElem data) { 。.. }
int main(void) { dataElem *data = new dataElem; 。..// pass data to kernel by reference kernel_by_ref《《《1,1》》》(*data);
// pass data to kernel by value -- this will create a copy kernel_by_val《《《1,1》》》(*data);}
多虧了統(tǒng)一內(nèi)存模型,深度復(fù)制、按值傳遞和按引用傳遞都可以正常工作。統(tǒng)一內(nèi)存模型為在GPU上運(yùn)行C++代碼提供了巨大幫助。
這篇文章的例子可以在Github上找到。
統(tǒng)一內(nèi)存模型的光明前景
CUDA 6中關(guān)于統(tǒng)一內(nèi)存模型的最令人興奮的事情之一就是它僅僅是個(gè)開(kāi)始。我們針對(duì)統(tǒng)一內(nèi)存模型有一個(gè)包括性能提升與特性的長(zhǎng)遠(yuǎn)規(guī)劃。我們的第一個(gè)發(fā)行版旨在使CUDA編程更容易,尤其是對(duì)于初學(xué)者而言。從CUDA 6開(kāi)始, cudaMemcpy()不再是必需的。通過(guò)使用 cudaMallocManaged(),您可以擁有一個(gè)指向數(shù)據(jù)的指針,并且可以在CPU和GPU之間共享復(fù)雜的C / C++數(shù)據(jù)結(jié)構(gòu)。這使編寫(xiě)CUDA程序變得容易得多,因?yàn)槟梢灾苯泳帉?xiě)內(nèi)核,而不是編寫(xiě)大量數(shù)據(jù)管理代碼并且要維護(hù)在主機(jī)和設(shè)備之間所有重復(fù)的數(shù)據(jù)。您仍然可以自由使用 cudaMemcpy()(特別是 cudaMemcpyAsync())來(lái)提高性能,但現(xiàn)在這不是一項(xiàng)要求,而是一項(xiàng)優(yōu)化。
CUDA的未來(lái)版本可能會(huì)通過(guò)添加數(shù)據(jù)預(yù)取和遷移提示來(lái)提高使用統(tǒng)一內(nèi)存模型的應(yīng)用程序的性能。我們還將增加對(duì)更多操作系統(tǒng)的支持。我們的下一代GPU架構(gòu)將帶來(lái)許多硬件改進(jìn),以進(jìn)一步提高性能和靈活性。
責(zé)任編輯:pj
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7145瀏覽量
89584 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3055瀏覽量
74334 -
編程
+關(guān)注
關(guān)注
88文章
3637瀏覽量
93988
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
拋棄8GB內(nèi)存,端側(cè)AI大模型加速內(nèi)存升級(jí)

芯盾時(shí)代助力中建科技統(tǒng)一身份認(rèn)證項(xiàng)目圓滿(mǎn)結(jié)項(xiàng)
芯盾時(shí)代繼續(xù)深化中建科技統(tǒng)一身份認(rèn)證平臺(tái)建設(shè)
【「大模型啟示錄」閱讀體驗(yàn)】對(duì)大模型更深入的認(rèn)知
KerasHub統(tǒng)一、全面的預(yù)訓(xùn)練模型庫(kù)
CNN, RNN, GNN和Transformer模型的統(tǒng)一表示和泛化誤差理論分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論