") 機(jī)器學(xué)習(xí)框架里不同層面的隱私保護(hù)
機(jī)器學(xué)習(xí)框架里不同層面的隱私保護(hù)
編者按:數(shù)據(jù)時代,人們從技術(shù)中獲取便利的同時,也面臨著隱私泄露的風(fēng)險。微軟倡導(dǎo)負(fù)責(zé)任的人工智能,因此機(jī)器學(xué)習(xí)中的隱私保護(hù)問題至關(guān)重要。本文介紹了目前機(jī)器學(xué)習(xí)中隱私保護(hù)領(lǐng)域的最新研究進(jìn)展,討論了機(jī)密計算、模型隱私和聯(lián)邦學(xué)習(xí)等不同層面的隱私保護(hù)方法。
作者 | 張輝帥
在大數(shù)據(jù)和人工智能的時代,人們能夠更方便高效地獲取信息。然而在獲得便利的同時,我們的行為無時無刻不在被記錄、被學(xué)習(xí)、被使用。如果在應(yīng)用中不注重隱私保護(hù),就很難阻止個人信息被用于非法目的。近年來,越來越多的人開始重視數(shù)據(jù)隱私,在選擇使用客戶端軟件(App)時更加關(guān)注隱私條款。有研究表明,對于隱私的保護(hù)可以提高用戶的使用率[1]。
此外,在法律層面,歐盟《通用數(shù)據(jù)保護(hù)條例》(GDPR)規(guī)范了企業(yè)收集、管理、刪除客戶和個人數(shù)據(jù),中國也在保護(hù)隱私方面完善了法律法規(guī)。我們時常能看到某公司因為用戶數(shù)據(jù)隱私不合規(guī)被處罰的新聞。
然而,沒有數(shù)據(jù),機(jī)器學(xué)習(xí)就如無米之炊。隨著研究的發(fā)展,機(jī)器學(xué)習(xí)的模型變得越來越強(qiáng),需要的訓(xùn)練數(shù)據(jù)也大大增加,比如,業(yè)界有些訓(xùn)練模型需要使用上百 G 的數(shù)據(jù)來訓(xùn)練數(shù)十億的參數(shù)。而在很多專業(yè)領(lǐng)域如醫(yī)療、金融防欺詐等,數(shù)據(jù)則因為隱私或者利益被分割成孤島,使得機(jī)器學(xué)習(xí)面臨著有效數(shù)據(jù)不足的問題。因此,如果不能對數(shù)據(jù)隱私提供保證,那么信息流動和機(jī)器學(xué)習(xí)也無法實現(xiàn)。
數(shù)據(jù)保護(hù)和機(jī)器學(xué)習(xí)似乎有著天然的矛盾, 因此,用戶和服務(wù)提供商都面臨的一個挑戰(zhàn)是如何在機(jī)器學(xué)習(xí)的框架里實現(xiàn)隱私保護(hù),取得隱私和效益的平衡。
隱私一詞在不同場景下指代的意義會有較大差別,在機(jī)器學(xué)習(xí)中亦是如此。接下來我們將分三節(jié)分別介紹不同層面的隱私保護(hù)(如圖1)。具體來說,第一部分陳述機(jī)密計算,討論如何實現(xiàn)機(jī)器學(xué)習(xí)中計算的機(jī)密性;第二部分陳述模型的隱私,差分隱私以及機(jī)器遺忘,討論如何減少機(jī)器學(xué)習(xí)模型對數(shù)據(jù)的泄露;第三部分陳述分布式機(jī)器學(xué)習(xí)的隱私,即聯(lián)邦學(xué)習(xí),討論在數(shù)據(jù)隔離分布式存儲,如何利用機(jī)密計算和模型隱私的技術(shù)有效地進(jìn)行隱私保護(hù)的機(jī)器學(xué)習(xí)。
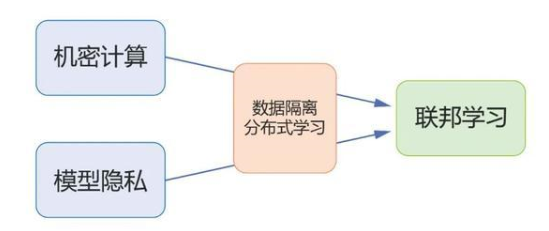
圖1:本文結(jié)構(gòu)示意圖
第一章 機(jī)密計算
(Confidential computing)
機(jī)密計算(confidential computing)是指數(shù)據(jù)的傳輸和計算過程是機(jī)密的(confidential)。當(dāng)前實現(xiàn)機(jī)密計算的方法有可信執(zhí)行環(huán)境(Trusted Executive Environment, TEE),同態(tài)加密(Homomorphic Encryption, HE)和多方安全計算(Multi-party Secure Computation, MPC)。
可信執(zhí)行環(huán)境(TEE)是處理器或虛擬系統(tǒng)上一個安全區(qū)域,可以保證在其中加載的數(shù)據(jù)和代碼的機(jī)密性和完整性。簡言之,TEE 可以被認(rèn)為是認(rèn)證用戶在云端的一塊飛地(enclave, 包括計算和存儲資源),雖然物理上在云端,但邏輯上只受認(rèn)證用戶管轄。數(shù)據(jù)和可信程序在云端加密存儲,只有在加載到 TEE 后才會解密,計算,計算結(jié)果再加密存儲到云端。云端只負(fù)責(zé)提供可信的計算環(huán)境,對其中的計算無法干預(yù)。關(guān)于 TEE,硬件或者邏輯漏洞以及可擴(kuò)展性是現(xiàn)在研究的重點。
同態(tài)加密,是一種加密方法,可以在密文上計算而不需要密鑰,而且計算結(jié)果是機(jī)密的,需要使用密鑰才能解密成明文。一般地,同態(tài)加密算法僅實現(xiàn)了同態(tài)加法和同態(tài)乘法,因此需要把計算歸約成一個數(shù)域上的加法和乘法電路。例如為了實現(xiàn)在神經(jīng)網(wǎng)絡(luò)上的同態(tài)加密計算,需要對網(wǎng)絡(luò)做一些改動使得其只包含加法乘法和多項式運算操作:把 ReLU 換成多項式激活函數(shù),運算使用定點數(shù)等,來自微軟研究院的 SEAL 項目[2]是目前比較流行的相關(guān)開源項目。但同態(tài)加密的實際應(yīng)用還面臨很大困難,由于它只能進(jìn)行加法和乘法操作,相比于明文運算增加了相當(dāng)大的計算開銷,所以現(xiàn)在的技術(shù)大約只能擴(kuò)展到 MNIST 和 CIFAR 的推斷部分[3]。
多方安全計算是參與方以各自隱私數(shù)據(jù)為輸入共同計算一個函數(shù)值。在整個過程中,各參與方除了計算結(jié)果,對他方的隱私數(shù)據(jù)沒有額外的認(rèn)知。多方安全計算能夠同時確保輸入的機(jī)密性和計算的正確性,其思想本質(zhì)是輸入數(shù)據(jù)是計算結(jié)果的一種冗余表示,有(無窮)多種輸入樣例對應(yīng)相同的計算結(jié)果,因此引入隨機(jī)數(shù)來掩蓋這種冗余性從而實現(xiàn)機(jī)密計算。多方安全計算需要設(shè)計協(xié)議來實現(xiàn)加法和乘法操作,但它的瓶頸在于通信復(fù)雜度的提升[4],如廣泛應(yīng)用的 Beaver 協(xié)議對于每個乘法操作需要一輪通信開銷。
當(dāng)前開源項目 Facebook CrypTen [5]和 Openminded PySyft [6] 用 Python 實現(xiàn)了多方安全計算的協(xié)議,可以進(jìn)行如數(shù)據(jù)分離,數(shù)據(jù)模型分離等場景下的模型訓(xùn)練和推斷。當(dāng)前的研究熱點是如何設(shè)計協(xié)議,降低通信開銷,以及如何連接應(yīng)用場景和技術(shù)實現(xiàn)。
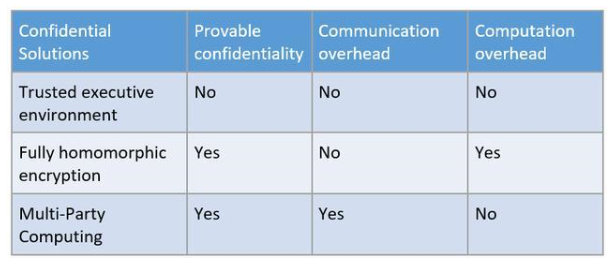
表1:機(jī)密計算技術(shù)特征
表1總結(jié)了三種機(jī)密計算技術(shù)的特征。機(jī)器學(xué)習(xí)研究者嘗試著把這些機(jī)密計算的技術(shù)和機(jī)器學(xué)習(xí)的過程結(jié)合實現(xiàn)對計算過程隱私的保護(hù),以及使用它們來降低模型差分隱私所需要的噪音[7]。
第二章 模型的隱私
(Model privacy)
機(jī)密計算可以做到在訓(xùn)練過程中保護(hù)數(shù)據(jù)的隱私。那么訓(xùn)練后的模型會造成隱私訓(xùn)練數(shù)據(jù)的泄露嗎?答案是可能的,因為機(jī)器學(xué)習(xí)的模型都會在一定程度上過擬合(泛化鴻溝),模型自身會記住(部分)訓(xùn)練數(shù)據(jù),從而導(dǎo)致發(fā)布模型會造成隱私訓(xùn)練數(shù)據(jù)的泄露。一個例子是模型反向工程(model inversion, 從模型推斷訓(xùn)練數(shù)據(jù))[8] ,如圖2就是攻擊者只用姓名和人臉識別系統(tǒng)的黑盒(blackbox)訪問恢復(fù)出的訓(xùn)練集中的數(shù)據(jù)。另一個例子是成員推斷(membership inference),它推斷某個樣本是不是在訓(xùn)練集中,較高的成員推斷成功率顯示模型對訓(xùn)練數(shù)據(jù)的隱私有泄露[9]。
圖2:從人臉識別模型通過黑盒攻擊恢復(fù)出訓(xùn)練集中的數(shù)據(jù),其中左圖為攻擊推斷結(jié)果,右圖為真實圖像[8]
差分隱私(Differential Privacy, DP) 可以衡量和控制模型對訓(xùn)練數(shù)據(jù)的泄露。它從統(tǒng)計意義上刻畫了單個數(shù)據(jù)樣本對模型的影響。一個隨機(jī)算法 M 符合 (,δ)-DP 意味著對于任何兩個相鄰的數(shù)據(jù)集 S, S‘ 和任意事件 E 滿足
P(M(S)∈E))≤e^ P(M(S’ )∈E)+δ。 (1)
實現(xiàn)算法差分隱私的一種通用做法是加噪音。加噪音會帶來模型的性能損失,差分隱私機(jī)器學(xué)習(xí)(differential private machine learning) 就是研究如何更節(jié)省地加噪音,如何在給定隱私損失的要求下,加最少的噪音取得最好的性能。微軟和中山大學(xué)在這方面的論文介紹了相關(guān)的研究工作[10]。研究人員發(fā)現(xiàn)加入的噪音和優(yōu)化算法會相互影響:噪音會讓優(yōu)化算法避開最差曲率方向,優(yōu)化算法的收縮性可以弱化之前步驟加的噪音。他們在分析中利用這種相互影響,推導(dǎo)出了一個新的基于期望曲率的理論性能界,可以顯式地看出梯度擾動比另外兩種擾動方式(目標(biāo)擾動和輸出擾動)的優(yōu)勢,并且給出了另外兩種擾動無法利用這種相互影響的原因。據(jù)此,梯度擾動是一種實現(xiàn)差分隱私機(jī)器學(xué)習(xí)的有效算法。
從2006年差分隱私被提出以來,隱私的度量也一直是這個領(lǐng)域很基礎(chǔ)的一個問題,期間提出的概念包括 -DP、(,δ)-DP、Renyi-DP、(Truncated) Concentrated DP 等。隱私度量,顧名思義是要度量一個算法的隱私損失。(,δ)-DP 可以按照公式計算出一次統(tǒng)計查詢對應(yīng)的隱私損失 (,δ)。通常一個復(fù)雜算法可以看成多次統(tǒng)計查詢的復(fù)合(composition)和采樣(sampling) ,因此分析一個復(fù)雜算法的隱私損失需要計算復(fù)合和采樣兩種操作的隱私損失。2019年[11]提出的高斯差分隱私(gaussian differential privacy)對采樣和復(fù)合都給出了一個緊估計,在隱私損失的統(tǒng)計上比之前的 moments accountant 技術(shù)更精準(zhǔn),從而在相同隱私預(yù)算下要加的噪音更小,取得的性能更好。
最近,另一個模型隱私的研究熱點是模型遺忘(machine unlearning)。如果把實現(xiàn)差分隱私看成主動設(shè)計算法使得輸出模型滿足隱私要求,那么模型遺忘是一種被動解決模型隱私的方法。它旨在機(jī)器學(xué)習(xí)模型中實現(xiàn)用戶的“被遺忘權(quán)利(the right to be forgotten)”。模型遺忘最直觀的做法是在刪除指定數(shù)據(jù)后的訓(xùn)練集上重新訓(xùn)練(retraining)這種做法的計算代價非常大,因此模型遺忘工作的主要目標(biāo)是降低計算代價,一類方法是對訓(xùn)練好的模型進(jìn)行后處理,使得模型遺忘算法的結(jié)果跟重新訓(xùn)練得到的模型是統(tǒng)計意義上近似不可區(qū)分的[12,13];另外一類方法是設(shè)計新的訓(xùn)練方法,降低重新訓(xùn)練的代價,這類方法通常將數(shù)據(jù)分成不同塊, 每塊數(shù)據(jù)單獨訓(xùn)練一個子模型, 并匯總子模型的結(jié)果,這樣刪除一個數(shù)據(jù)點只需要重新訓(xùn)練一個子模型[14,15]。
第三章 聯(lián)邦學(xué)習(xí)
(Federated learning)
聯(lián)邦學(xué)習(xí)(federated learning)的愿景是在不共享數(shù)據(jù)的情形下進(jìn)行多方聯(lián)合機(jī)器學(xué)習(xí),本質(zhì)上是一種數(shù)據(jù)訪問受限的分布式機(jī)器學(xué)習(xí)框架。
相比于經(jīng)典的分布式機(jī)器學(xué)習(xí),聯(lián)邦學(xué)習(xí)的第一層受限是數(shù)據(jù)隔離——數(shù)據(jù)在各個終端不共享,不均衡,交互通信要盡量少。微軟和 CMU 合作的論文介紹了這方面的工作[16]。研究人員分析了在數(shù)據(jù)隔離的限制下一類分布式方差縮減算法(Variance Reduced Methods, i.e.,SVRG,SARAPH,MIG)的理論性能。在最自然的分布式設(shè)置下(終端節(jié)點運算內(nèi)循環(huán),參數(shù)服務(wù)器運算外循環(huán))取得線性收斂性(強(qiáng)凸目標(biāo)函數(shù)),并且算法的時間復(fù)雜度對條件數(shù)的依賴取得目前理論上的最好結(jié)果。分布式方差縮減算法相比于分布式梯度下降,顯著降低了通信開銷并利于保護(hù)隱私。
在分析中,研究人員引入了 restricted smoothness 衡量本地目標(biāo)函數(shù)和全局目標(biāo)函數(shù)之差的平滑性,結(jié)果顯示 restricted smoothness 決定了算法的收斂性。并且當(dāng)數(shù)據(jù)不平衡,restricted smoothness 較差時,引入差異正則項,保證算法可以收斂。表2列舉了各個分布式算法的通信和計算復(fù)雜度比較(*標(biāo)識文中的算法),可以看出文中的分析對最自然的分布式方差縮減算法給出了最優(yōu)的結(jié)果。

表 2:分布式算法通信和計算復(fù)雜度比較
聯(lián)邦學(xué)習(xí)的第二層受限是隱私保護(hù)。直覺上,只共享參數(shù)更新而不共享原始數(shù)據(jù)可以在一定程度上保護(hù)原始數(shù)據(jù)的隱私。不過,論文[17]指出在深度模型中共享單個樣本的梯度可以泄露原始數(shù)據(jù)。他們提出梯度匹配(gradient matching)算法,利用給定輸入在模型上的梯度可以相當(dāng)準(zhǔn)確地恢復(fù)出原始數(shù)據(jù)的輸入和標(biāo)簽。圖3展示了梯度匹配在 MNIST、SVHN、CIFAR、LFW 數(shù)據(jù)集上恢復(fù)輸入的例子。
雖然在復(fù)合多個樣本點的梯度時,梯度匹配算法會失效,但這篇文章仍然展示了梯度對原始數(shù)據(jù)的暴露。通常,聯(lián)邦學(xué)習(xí)的算法會使用前面介紹的機(jī)密計算的工具(同態(tài)加密或多方安全計算)來實現(xiàn)可證明的隱私保護(hù)[18,19],只是這些機(jī)密計算的方法會帶來很大額外的計算和通信開銷。
圖3:攻擊者從共享的梯度中恢復(fù)出原始數(shù)據(jù),從上到下分別是 MNIST、CIFAR100、SVHN、LFW [17]
相比于同態(tài)加密完全在密文域?qū)W習(xí)和運算,是否存在一種數(shù)據(jù)弱加密方法,使得模型可以直接在其上訓(xùn)練、推斷同時還能擁有一定的隱私保證呢?最近的工作 InstaHide[20],就利用 mixup[21] 和隨機(jī)反轉(zhuǎn)對原始圖片弱加密。弱加密后的圖片視覺上看不出原始圖片的信息,但深度神經(jīng)網(wǎng)絡(luò)仍然可以直接在其上訓(xùn)練推斷,取得了相當(dāng)好的性能表現(xiàn)。此外,該工作還展示了這種弱加密算法可以抵抗多種攻擊方法。不過值得指出的是這種弱加密還沒有計算復(fù)雜性的理論,不能保證一定可以防住攻擊。
隱私保護(hù)與人們的生活息息相關(guān),在實踐和理論上也是挑戰(zhàn)和機(jī)遇并存。我們期待與更多同仁一起努力,推動隱私保護(hù)領(lǐng)域的發(fā)展。
責(zé)編AJX
-
人工智能
+關(guān)注
關(guān)注
1796文章
47674瀏覽量
240294 -
隱私保護(hù)
+關(guān)注
關(guān)注
0文章
300瀏覽量
16489 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
133087
發(fā)布評論請先 登錄
相關(guān)推薦
深度自然匿名化:隱私保護(hù)與視覺完整性并存的未來!

《具身智能機(jī)器人系統(tǒng)》第10-13章閱讀心得之具身智能機(jī)器人計算挑戰(zhàn)
隱私與安全:動態(tài)海外住宅IP如何保護(hù)你在線
Arm成功將Arm KleidiAI軟件庫集成到騰訊自研的Angel 機(jī)器學(xué)習(xí)框架
比亞迪獲得國家首批汽車隱私保護(hù)標(biāo)識
NPU與機(jī)器學(xué)習(xí)算法的關(guān)系
RISC-V如何支持不同的AI和機(jī)器學(xué)習(xí)框架和庫?
IP地址安全與隱私保護(hù)
平衡創(chuàng)新與倫理:AI時代的隱私保護(hù)和算法公平
TensorFlow與PyTorch深度學(xué)習(xí)框架的比較與選擇
藍(lán)牙模塊的安全性與隱私保護(hù)
谷歌模型框架是什么軟件?谷歌模型框架怎么用?
人工智能和機(jī)器學(xué)習(xí)的頂級開發(fā)板有哪些?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論