") 基于Python 的人工神經(jīng)網(wǎng)絡(luò)的工作原理
基于Python 的人工神經(jīng)網(wǎng)絡(luò)的工作原理
摘要: 深度學(xué)習(xí)背后的主要原因是人工智能應(yīng)該從人腦中汲取靈感。本文就用一個小例子無死角的介紹一下深度學(xué)習(xí)!
人腦模擬
深度學(xué)習(xí)背后的主要原因是人工智能應(yīng)該從人腦中汲取靈感。此觀點引出了“神經(jīng)網(wǎng)絡(luò)”這一術(shù)語。人腦中包含數(shù)十億個神經(jīng)元,它們之間有數(shù)萬個連接。很多情況下,深度學(xué)習(xí)算法和人腦相似,因為人腦和深度學(xué)習(xí)模型都擁有大量的編譯單元(神經(jīng)元),這些編譯單元(神經(jīng)元)在獨立的情況下都不太智能,但是當(dāng)他們相互作用時就會變得智能。
我認(rèn)為人們需要了解到深度學(xué)習(xí)正在使得很多幕后的事物變得更好。深度學(xué)習(xí)已經(jīng)應(yīng)用于谷歌搜索和圖像搜索,你可以通過它搜索像“擁抱”這樣的詞語以獲得相應(yīng)的圖像。-杰弗里·辛頓
神經(jīng)元
神經(jīng)網(wǎng)絡(luò)的基本構(gòu)建模塊是人工神經(jīng)元,它模仿了人類大腦的神經(jīng)元。這些神經(jīng)元是簡單、強大的計算單元,擁有加權(quán)輸入信號并且使用激活函數(shù)產(chǎn)生輸出信號。這些神經(jīng)元分布在神經(jīng)網(wǎng)絡(luò)的幾個層中。
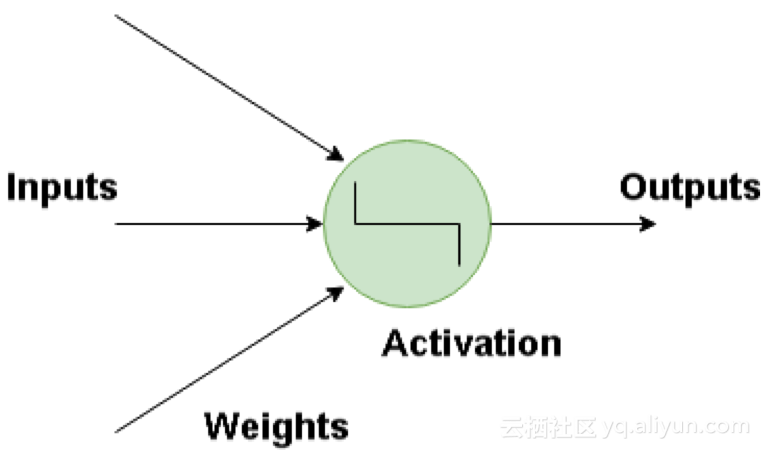
inputs 輸入 outputs 輸出 weights 權(quán)值 activation 激活
人工神經(jīng)網(wǎng)絡(luò)的工作原理是什么?
深度學(xué)習(xí)由人工神經(jīng)網(wǎng)絡(luò)構(gòu)成,該網(wǎng)絡(luò)模擬了人腦中類似的網(wǎng)絡(luò)。當(dāng)數(shù)據(jù)穿過這個人工網(wǎng)絡(luò)時,每一層都會處理這個數(shù)據(jù)的一方面,過濾掉異常值,辨認(rèn)出熟悉的實體,并產(chǎn)生最終輸出。
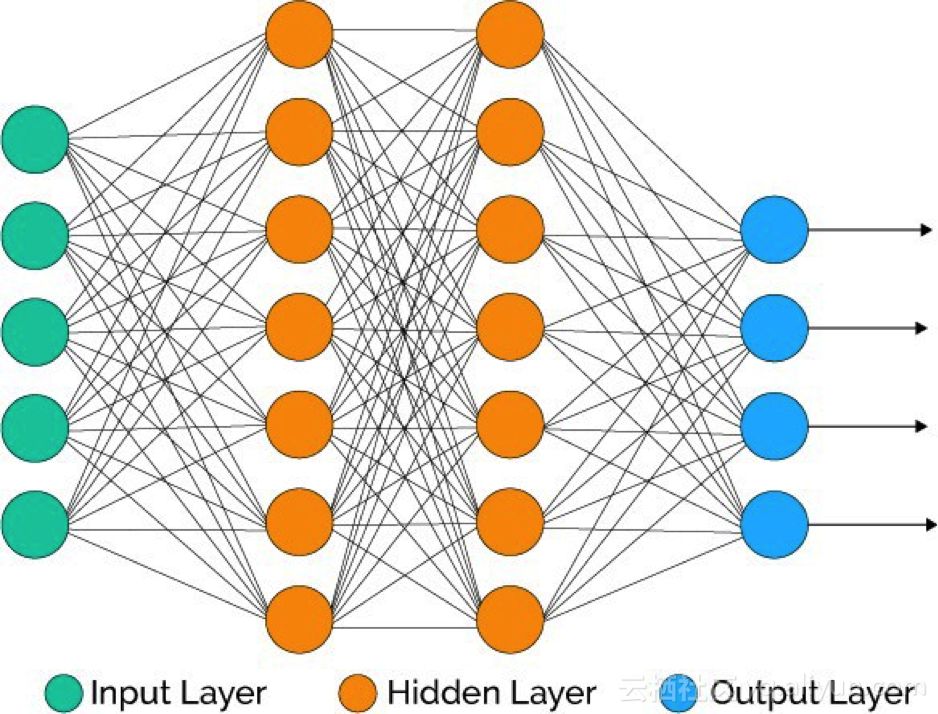
輸入層:該層由神經(jīng)元組成,這些神經(jīng)元只接收輸入信息并將它傳遞到其他層。輸入層的圖層數(shù)應(yīng)等于數(shù)據(jù)集里的屬性或要素的數(shù)量。輸出層:輸出層具有預(yù)測性,其主要取決于你所構(gòu)建的模型類型。隱含層:隱含層處于輸入層和輸出層之間,以模型類型為基礎(chǔ)。隱含層包含大量的神經(jīng)元。處于隱含層的神經(jīng)元會先轉(zhuǎn)化輸入信息,再將它們傳遞出去。隨著網(wǎng)絡(luò)受訓(xùn)練,權(quán)重得到更新,從而使其更具前瞻性。
神經(jīng)元的權(quán)重
權(quán)重是指兩個神經(jīng)元之間的連接的強度或幅度。你如果熟悉線性回歸的話,可以將輸入的權(quán)重類比為我們在回歸方程中用的系數(shù)。權(quán)重通常被初始化為小的隨機數(shù)值,比如數(shù)值0-1。
前饋深度網(wǎng)絡(luò)
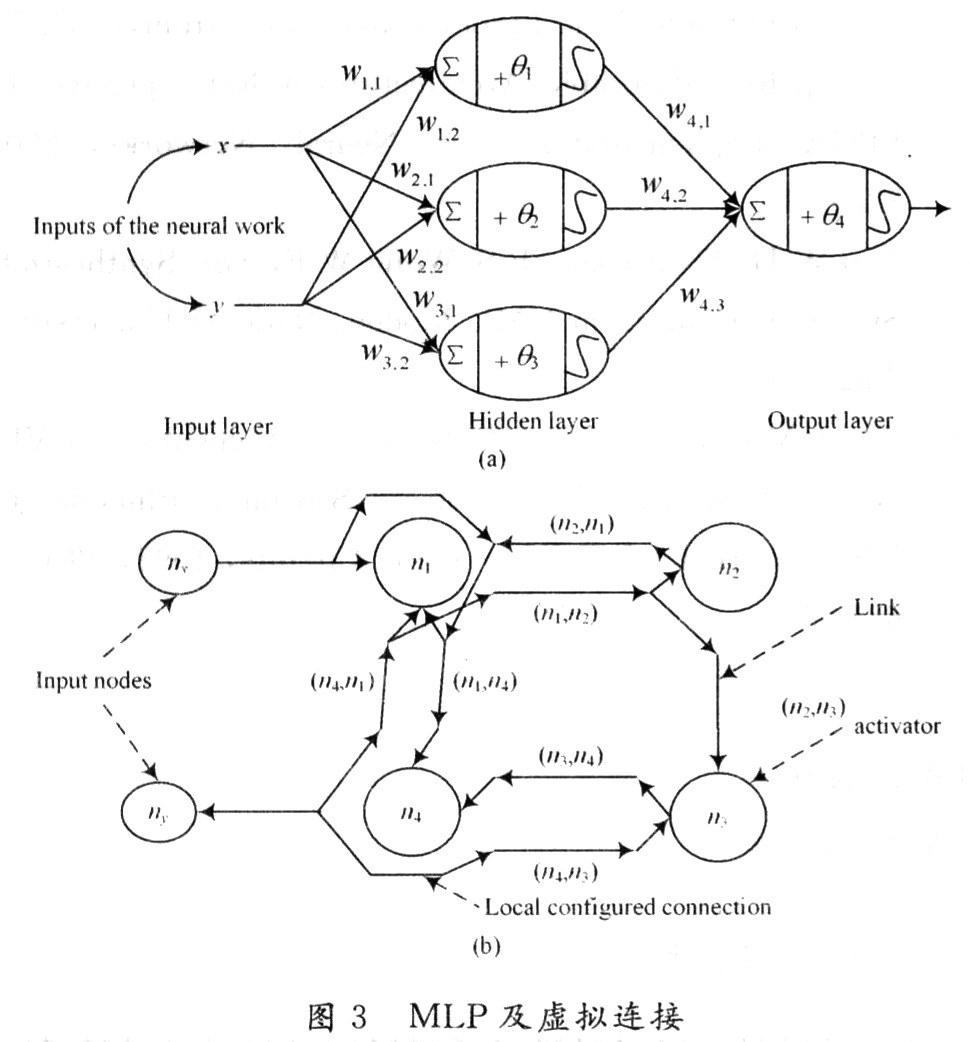
前饋監(jiān)督神經(jīng)網(wǎng)絡(luò)曾是第一個也是最成功的學(xué)習(xí)算法。該網(wǎng)絡(luò)也可被稱為深度網(wǎng)絡(luò)、多層感知機(MLP)或簡單神經(jīng)網(wǎng)絡(luò),并且闡明了具有單一隱含層的原始架構(gòu)。每個神經(jīng)元通過某個權(quán)重和另一個神經(jīng)元相關(guān)聯(lián)。
該網(wǎng)絡(luò)處理向前處理輸入信息,激活神經(jīng)元,最終產(chǎn)生輸出值。在此網(wǎng)絡(luò)中,這稱為前向傳遞。
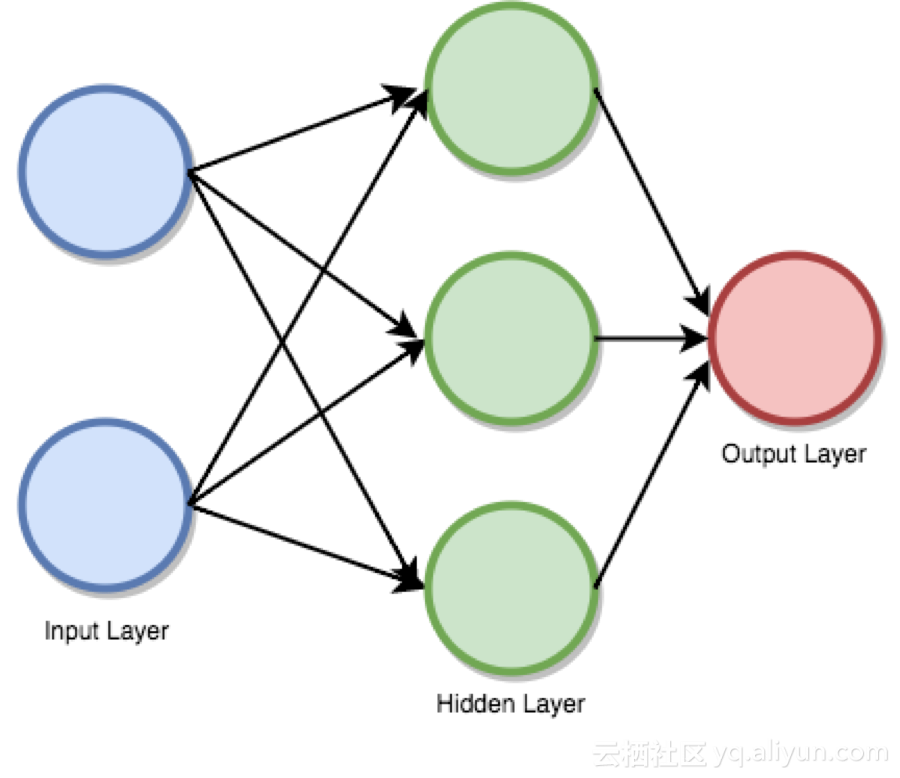
input layer 輸入層 hidden layer 輸出層 output layer 輸出層
激活函數(shù)
激活函數(shù)就是求和加權(quán)的輸入到神經(jīng)元的輸出的映射。之所以稱之為激活函數(shù)或傳遞函數(shù)是因為它控制著激活神經(jīng)元的初始值和輸出信號的強度。
用數(shù)學(xué)表示為:
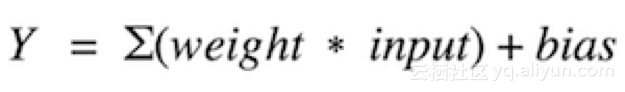
我們有許多激活函數(shù),其中使用最多的是整流線性單元函數(shù)、雙曲正切函數(shù)和solfPlus函數(shù)。
激活函數(shù)的速查表如下:
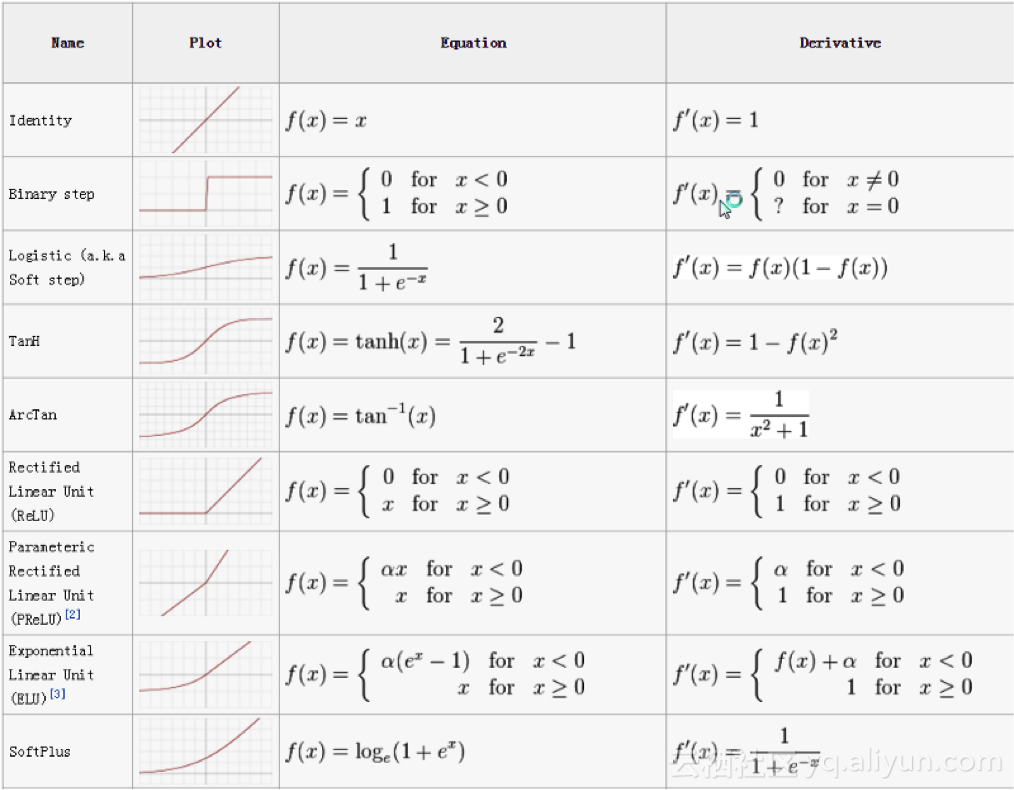
反向傳播
在網(wǎng)絡(luò)中,我們將預(yù)測值與預(yù)期輸出值相比較,并使用函數(shù)計算其誤差。然后,這個誤差會傳回這個網(wǎng)絡(luò),每次傳回一個層,權(quán)重也會根絕其導(dǎo)致的誤差值進(jìn)行更新。這個聰明的數(shù)學(xué)法是反向傳播算法。這個步驟會在訓(xùn)練數(shù)據(jù)的所有樣本中反復(fù)進(jìn)行,整個訓(xùn)練數(shù)據(jù)集的網(wǎng)絡(luò)更新一輪稱為一個時期。一個網(wǎng)絡(luò)可受訓(xùn)練數(shù)十、數(shù)百或數(shù)千個時期。
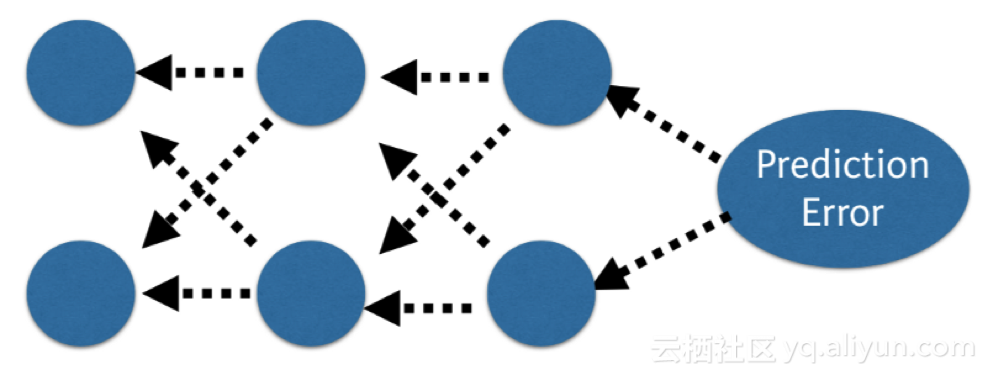
prediction error 預(yù)測誤差
代價函數(shù)和梯度下降
代價函數(shù)度量了神經(jīng)網(wǎng)絡(luò)對給定的訓(xùn)練輸入和預(yù)期輸出“有多好”。該函數(shù)可能取決于權(quán)重、偏差等屬性。
代價函數(shù)是單值的,并不是一個向量,因為它從整體上評估神經(jīng)網(wǎng)絡(luò)的性能。在運用梯度下降最優(yōu)算法時,權(quán)重在每個時期后都會得到增量式地更新。
兼容代價函數(shù)
用數(shù)學(xué)表述為差值平方和:
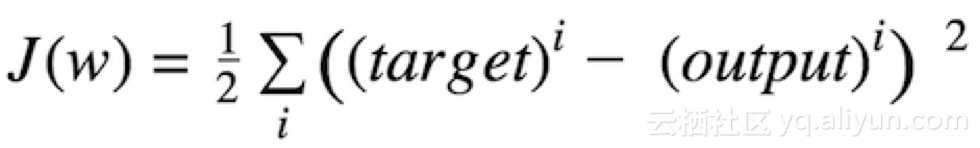
target 目標(biāo)值 output 輸出值
權(quán)重更新的大小和方向是由在代價梯度的反向上采取步驟計算出的。
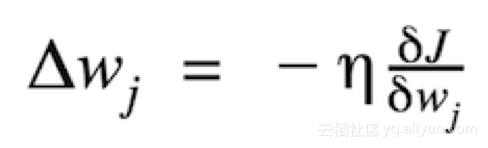
其中η 是學(xué)習(xí)率
其中Δw是包含每個權(quán)重系數(shù)w的權(quán)重更新的向量,其計算方式如下:
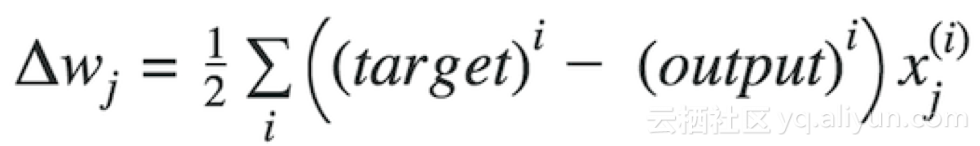
target 目標(biāo)值 output 輸出值
圖表中會考慮到單系數(shù)的代價函數(shù)
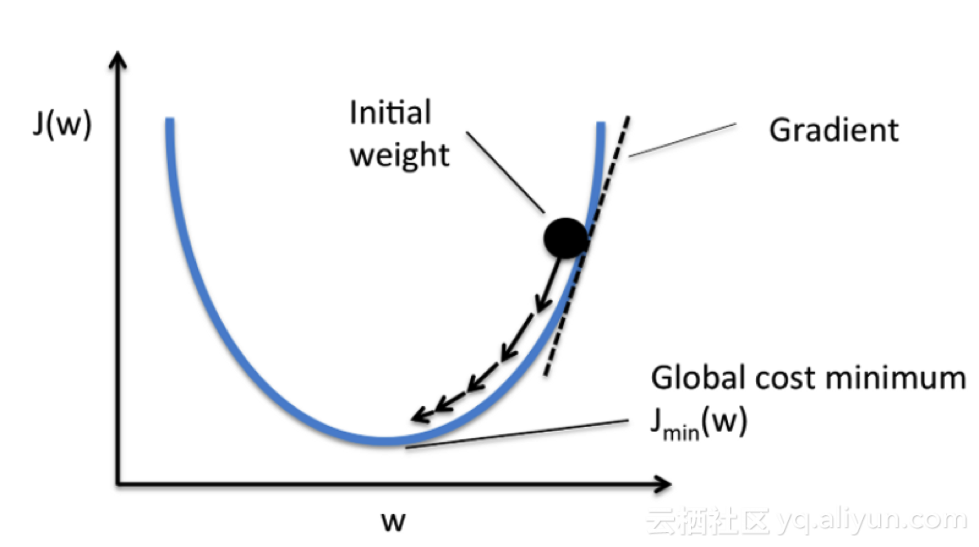
initial weight 初始權(quán)重 gradient 梯度 global cost minimum 代價極小值
在導(dǎo)數(shù)達(dá)到最小誤差值之前,我們會一直計算梯度下降,并且每個步驟都會取決于斜率(梯度)的陡度。
多層感知器(前向傳播)
這類網(wǎng)絡(luò)由多層神經(jīng)元組成,通常這些神經(jīng)元以前饋方式(向前傳播)相互連接。一層中的每個神經(jīng)元可以直接連接后續(xù)層的神經(jīng)元。在許多應(yīng)用中,這些網(wǎng)絡(luò)的單元會采用S型函數(shù)或整流線性單元(整流線性激活)函數(shù)作為激活函數(shù)。
現(xiàn)在想想看要找出處理次數(shù)這個問題,給定的賬戶和家庭成員作為輸入
要解決這個問題,首先,我們需要先創(chuàng)建一個前向傳播神經(jīng)網(wǎng)絡(luò)。我們的輸入層將是家庭成員和賬戶的數(shù)量,隱含層數(shù)為1, 輸出層將是處理次數(shù)。
將圖中輸入層到輸出層的給定權(quán)重作為輸入:家庭成員數(shù)為2、賬戶數(shù)為3。
現(xiàn)在將通過以下步驟使用前向傳播來計算隱含層(i,j)和輸出層(k)的值。
步驟:
1, 乘法-添加方法。
2, 點積(輸入*權(quán)重)。
3,一次一個數(shù)據(jù)點的前向傳播。
4, 輸出是該數(shù)據(jù)點的預(yù)測。
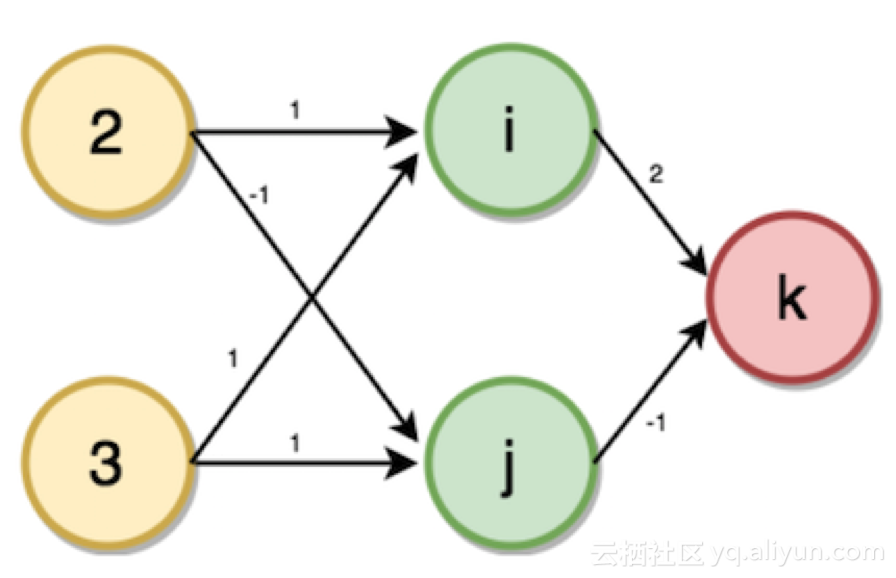
i的值將從相連接的神經(jīng)元所對應(yīng)的輸入值和權(quán)重中計算出來。
i = (2 * 1) + (3 * 1) → i = 5
同樣地,j = (2 * -1) + (3 * 1) → j = 1
K = (5 * 2) + (1 * -1) → k = 9
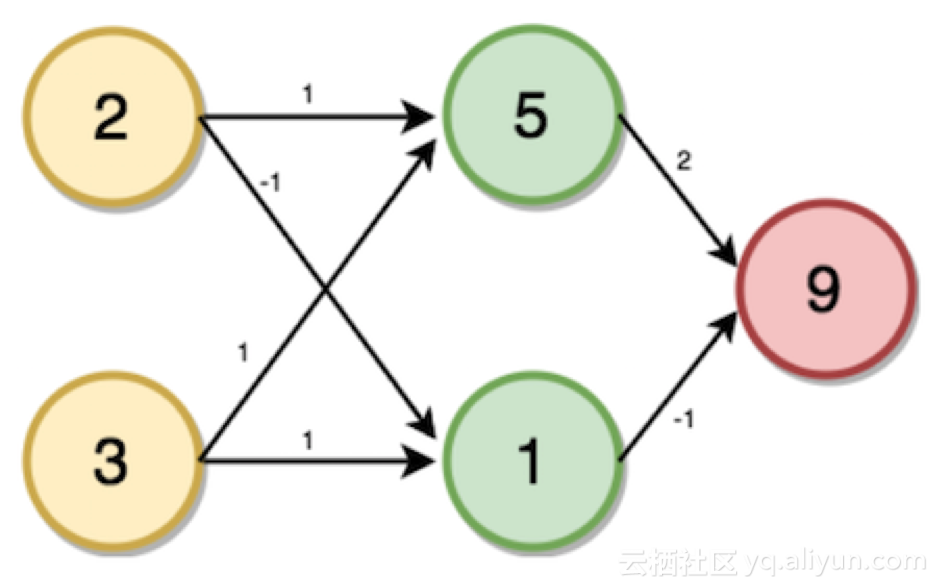
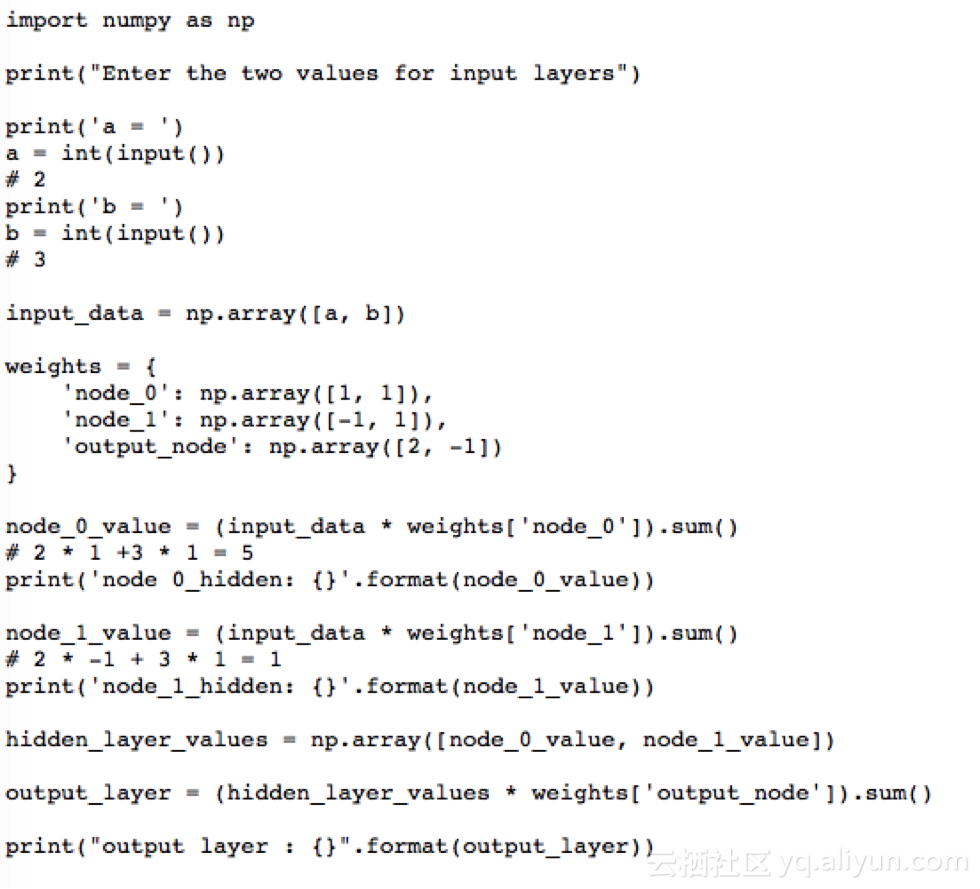

激活函數(shù)的使用
為了使神經(jīng)網(wǎng)絡(luò)達(dá)到其最大預(yù)測能力,我們需要在隱含層應(yīng)用一個激活函數(shù),以捕捉非線性。我們通過將值代入方程式的方式來在輸入層和輸出層應(yīng)用激活函數(shù)。
這里我們使用整流線性激活(ReLU):
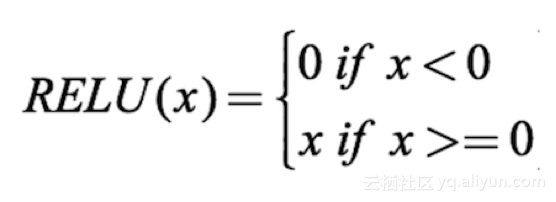


用Keras開發(fā)第一個神經(jīng)網(wǎng)絡(luò)
關(guān)于Keras:
Keras是一個高級神經(jīng)網(wǎng)絡(luò)的應(yīng)用程序編程接口,由Python編寫,能夠搭建在TensorFlow,CNTK,或Theano上。
使用PIP在設(shè)備上安裝Keras,并且運行下列指令。
在keras執(zhí)行深度學(xué)習(xí)程序的步驟
1,加載數(shù)據(jù);
2,創(chuàng)建模型;
3,編譯模型;
4,擬合模型;
5,評估模型;
開發(fā)Keras模型
全連接層用Dense表示。我們可以指定層中神經(jīng)元的數(shù)量作為第一參數(shù),指定初始化方法為第二參數(shù),即初始化參數(shù),并且用激活參數(shù)確定激活函數(shù)。既然模型已經(jīng)創(chuàng)建,我們就可以編譯它。我們在底層庫(也稱為后端)用高效數(shù)字庫編譯模型,底層庫可以用Theano或TensorFlow。目前為止,我們已經(jīng)完成了創(chuàng)建模型和編譯模型,為進(jìn)行有效計算做好了準(zhǔn)備。現(xiàn)在可以在PIMA數(shù)據(jù)上運行模型了。我們可以在模型上調(diào)用擬合函數(shù)f(),以在數(shù)據(jù)上訓(xùn)練或擬合模型。
我們先從KERAS中的程序開始,
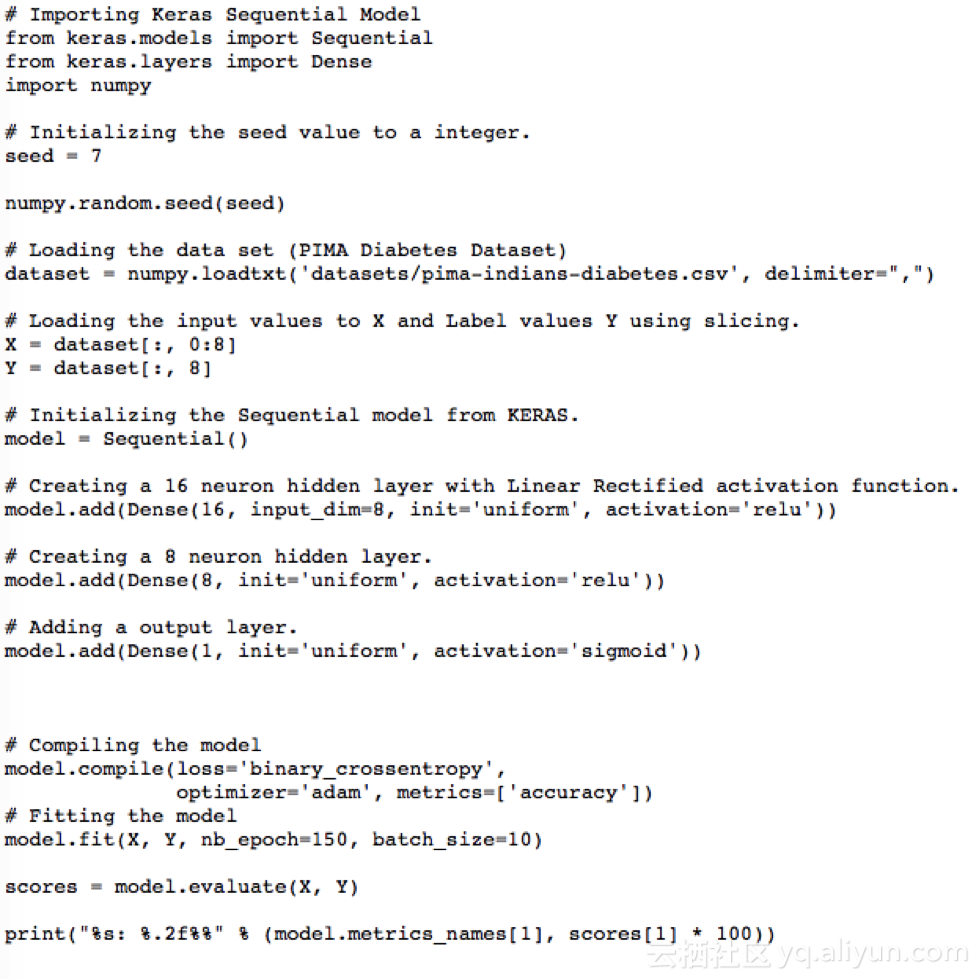
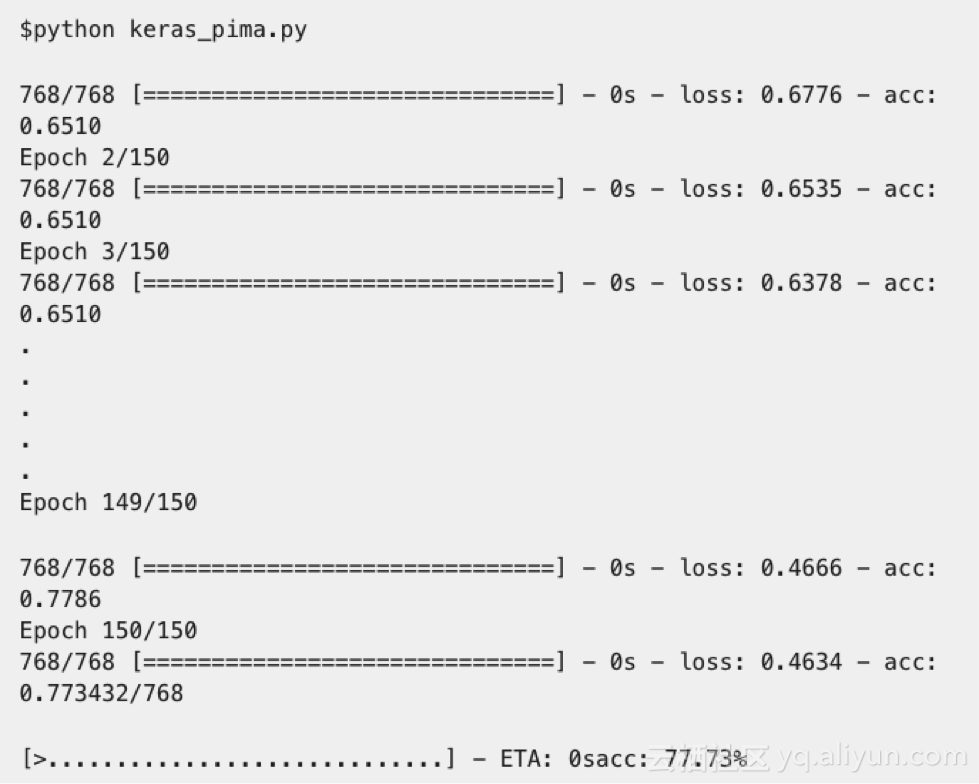
神經(jīng)網(wǎng)絡(luò)一直訓(xùn)練到150個時期,并返回精確值。
本文由北郵@愛可可-愛生活老師推薦,阿里云云棲社區(qū)組織翻譯。
作者:Vihar Kurama
譯者:荷葉。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101171
發(fā)布評論請先 登錄
相關(guān)推薦
人工神經(jīng)網(wǎng)絡(luò)原理及下載
應(yīng)用人工神經(jīng)網(wǎng)絡(luò)模擬污水生物處理
【PYNQ-Z2試用體驗】神經(jīng)網(wǎng)絡(luò)基礎(chǔ)知識
人工神經(jīng)網(wǎng)絡(luò)實現(xiàn)方法有哪些?
怎么解決人工神經(jīng)網(wǎng)絡(luò)并行數(shù)據(jù)處理的問題
嵌入式中的人工神經(jīng)網(wǎng)絡(luò)的相關(guān)資料分享
不可錯過!人工神經(jīng)網(wǎng)絡(luò)算法、PID算法、Python人工智能學(xué)習(xí)等資料包分享(附源代碼)
基于FPGA的人工神經(jīng)網(wǎng)絡(luò)實現(xiàn)方法的研究





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論