 建立決策樹的邏輯
建立決策樹的邏輯
一個小故事
zenRRan二十出頭了,到了婚配的年齡啦。又因為家是名門望族,所以一堆人搶著想來應聘配偶的職位。但是zenRRan比較挑剔,必須達到他的要求才能有機會成為他的另一半,要求為:
1. 性別女,非女性不要
于是刷刷刷走了一半人,剩下的全部為女性。
2.身高必須要在150-165cm
于是又走了一堆人,剩下的為160-165cm之間的女生。
3.性格要溫柔賢惠
聽到這些,又走了一些人,最后留下的極為最后的應聘候選人。
上述過程可以用樹來表示:
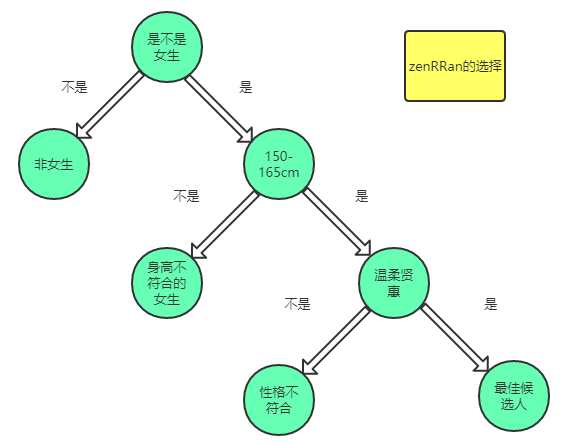
像上面的這樣的二叉樹狀決策在我們生活中很常見,而這樣的選擇方法就是決策樹。機器學習的方法就是通過平時生活中的點點滴滴經驗轉化而來的。
建立決策樹的邏輯
正如上述樹狀圖所示,我們最終會通過特征:
性別,身高,性格
得到了4種分類結果,都存在于葉子節點。
非女生,身高不符合的女生,身高符合性格不符合的女生,都符合的最佳候選人。
現在我們來回想下上面的建立決策的流程:
首先在一群給定數據(應聘者)中,我們先通過一個特征(性別)來進行二分類。當然選取這個特征也是根據實際情況而定的,比如zenRRan選取第一個條件為性別的原因是,來的男的太多了,比例占的有點大,所以先給他分成類放到一邊,剩下的更加好分類而已。
然后,對葉子節點(那些還想繼續分類的節點們)繼續進行上述的流程。
那么怎么選取特征作為當前的分類依據呢?有兩種方法:
信息熵和基尼系數。
信息熵
熵這個概念想必大家都不陌生,熵用來表示數據的確定性程度。研究一個詞,就要從他的來源說起,熵,來自熱動力學,表示原子或者一個事物的穩定程度,溫度越高,原子越活躍,越不穩定;反而溫度越低,就越穩定,越保持不動。所以慢慢的這個概念被用到各個方向,也就有了新的定義詞匯,但是它的本意沒變,就是穩定程度大小的表示。
那么在決策樹里面,我們用的是一種熵,信息熵,來表示類別的穩定程度。
公式為:
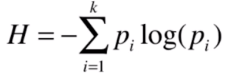
注:p為一個類的占比
什么意思呢?具體用數字表示下:
比如一個分類結果由三個類組成,占比為1/3 1/31/3,那么它們的信息熵為:
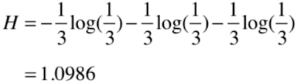
如果占比為1/10 2/10 7/10,那么它的信息熵為:
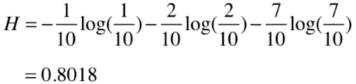
那再舉一個極端情況,也就是我們想要得到的類,只包含一種情況,其他的比例為0,那么比如占比情況為:1 0 0,那么它的信息熵為:
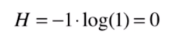
我們會發現一個分類結果里,里面的類別比例越是接近,信息熵也就越大,反之越是趨向于一個值,越是小,會達到0。
如果將所有的情況考慮在內的話,就能繪成一個圖(為了好畫,以該分好的類別里有兩種事物為例):
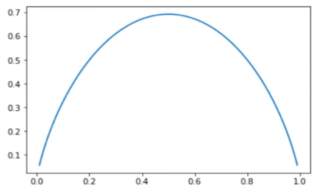
我們會發現,當占比為0.5的時候,也就是另一個事物的占比也是0.5的時候信息熵最高,當傾向于一個事物的時候,信息熵最小,無限接近并達到0。
為什么都占比一樣的時候信息熵最大呢?也就是說最不穩定呢?因為當每個事物都占比一樣的時候,一個小事物進來,不清楚它到底屬于哪一類;如果只有一類事物或者一類事物居多數,那么也就比較明確該屬于哪類,也就穩定,確定了。
那么怎么用呢?
我們通過計算機分類,因為有很多種分類情況,不是每一次分類都是直接將同一類分到一個類別里,而是將該分好的兩個類的信息熵總和最小為依據,不斷地通過暴力尋找最佳選擇。然后遞歸進行對分好類的數據進行再分類。
基尼系數
基尼系數和信息熵在這里具有同樣的性質。先看看它的公式:
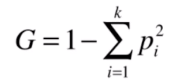
公式看不出什么特色之處,就繼續用數字展示下:
比如依然是三分類,類別占比為1/3 1/3 1/3,基尼系數為:
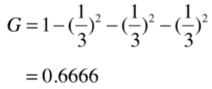
類別占比為1/10 2/10 7/10,基尼系數為:
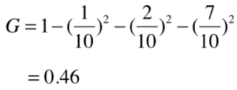
如果是極端情況下占比為1 0 0,那么基尼系數為;
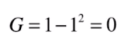
我們根據公式其實就能看出來,平方的函數為凸函數,而該公式在都相等的時候值最大。
代碼實現
再重說下流程:
通過對每個特征進行嘗試分類,記錄當前分類最小的信息熵(或基尼系數)的特征為當前分類結果。
選取一些點,初始化數據:
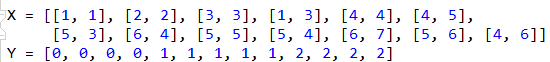
X為二維平面的數據點,Y為類別。
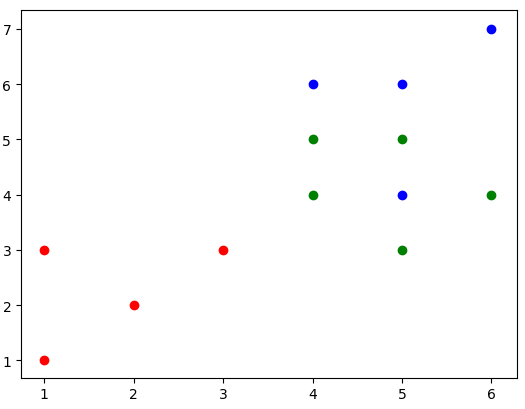
數據點分布情況:
信息熵函數:

基尼系數函數:

二者使用一個即可。
下面是一個分類核心的流程:
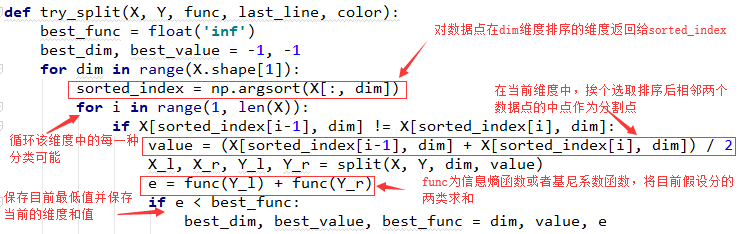
文字描述為:
對數據點的特征0維進行嘗試分類,先按照0維數據排序,然后取每相鄰的中點值,然后以0維該值分界線,處于分界線兩側的數據分別求信息熵(或基尼系數),如果比之前的小,這就保存該值和當前維度。然后選取第1維進行相同操作,最終的最小信息熵(或基尼系數)最小對應的值為本次分類的結果。
但是這個僅僅是一層分類,如果還子節點還有要分類的數據,繼續上述操作即可。
分類代碼:

分類效果流程圖:
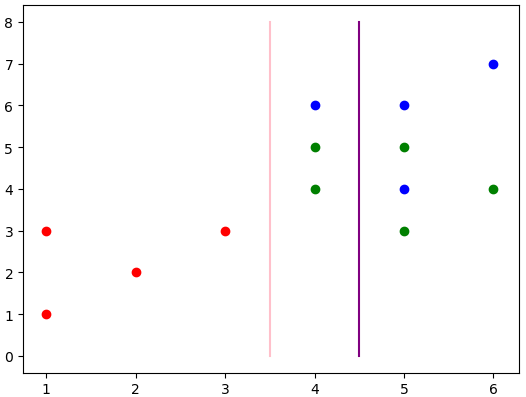
決策樹第一層分類結果為:
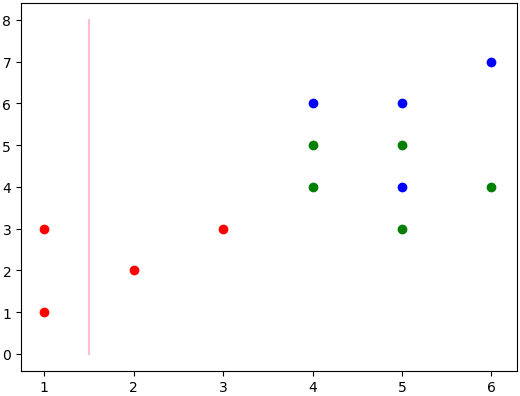
當前線為最佳值,1維的數據就是分過的,但是沒有當前的值好,也就沒顯示。
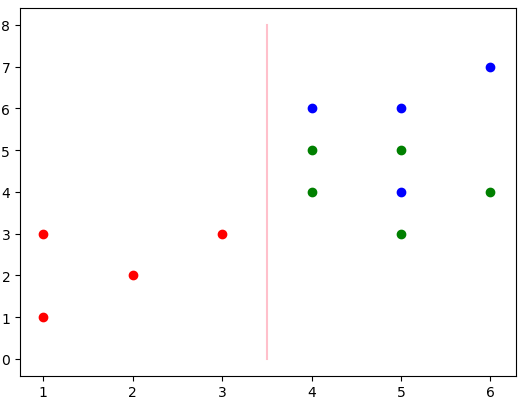
現在已經分出了兩類,左邊的紅色和右邊的綠色+藍色。那么還要對上述的右邊進行分類,獲取該數據,并且繼續進行分類,分類流程圖為:
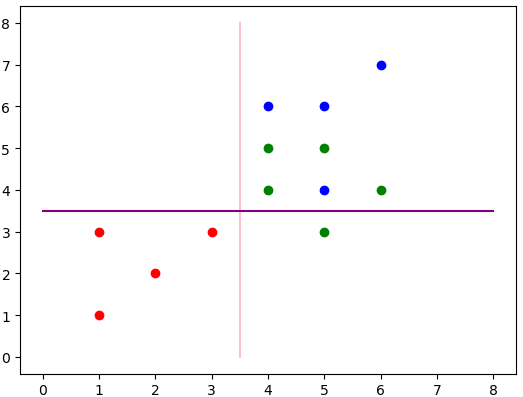
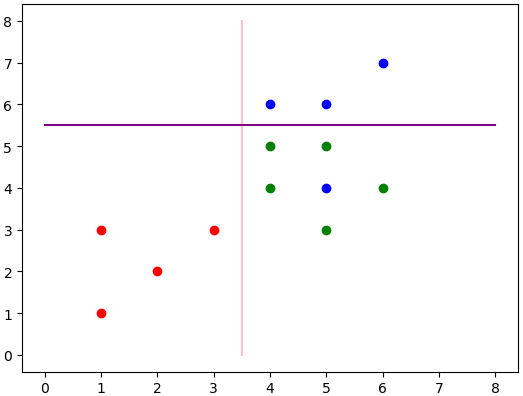
最終得出的分類結果為上述兩條線。其中粉色為第一層分類,紫色為第二層分類。
批判性思維看決策樹
看到上述的分類結果,其實你心里也想到了決策樹的缺點了,就是分類總是橫平豎直的,不能是曲線。
比如
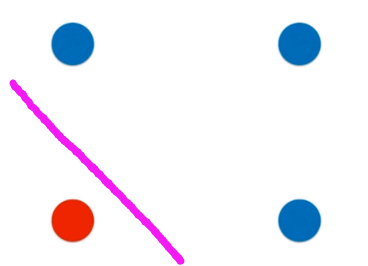
該四個數據的分類最佳理想條件下應該為上述紫色線條,但是決策樹的結果為;
如果存在數據在:
明明應該屬于藍色點的,但是被劃分到紅色點里。
所以可以看出,決策樹對數據的要求是是苛刻的。
另一個問題是,決策樹的學習問題,從上述代碼實現過程能夠看出來,可以說是暴力求解了。
責任編輯:lq
-
二叉樹
+關注
關注
0文章
74瀏覽量
12376 -
機器學習
+關注
關注
66文章
8441瀏覽量
133093 -
決策樹
+關注
關注
3文章
96瀏覽量
13587
原文標題:【機器學習】決策樹的理論與實踐
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
宇樹科技在物聯網方面
xgboost超參數調優技巧 xgboost在圖像分類中的應用
xgboost的并行計算原理
嵌入式學習-飛凌嵌入式ElfBoard ELF 1板卡-初識設備樹之設備樹組成和結構
飛凌嵌入式ElfBoard ELF 1板卡-初識設備樹之設備樹組成和結構
邏輯異或和邏輯或的比較分析
簡單認識邏輯電路的用途
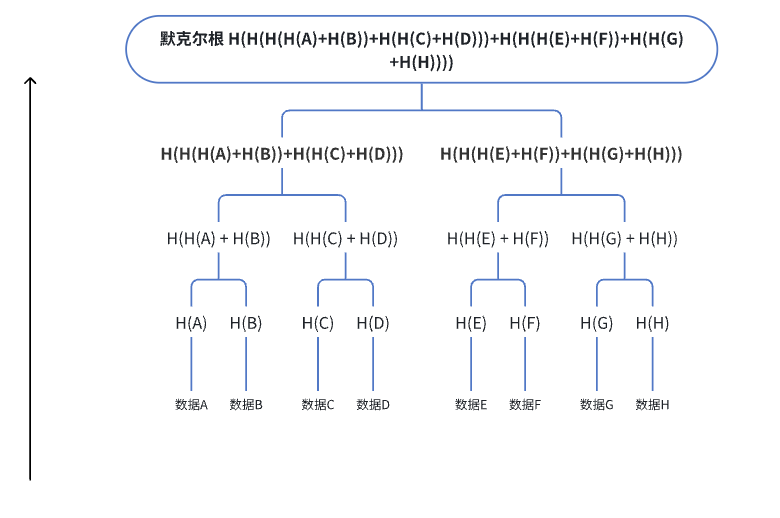
什么是默克爾樹(Merkle Tree)?如何計算默克爾根?
數字邏輯怎么把邏輯圖畫成電路圖
數字系統的核心:邏輯門電路

機器學習算法原理詳解
原理圖設計里兩顆重要的樹(國產EDA)
崔東樹:進口車增量助力消費增長,年內潛力巨大
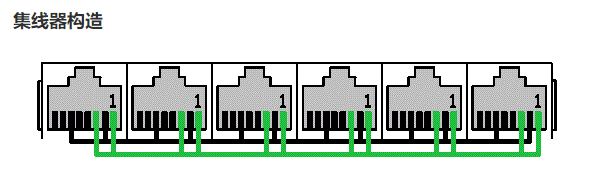
集線器是什么?集線器內部構造
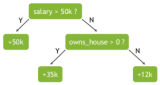
什么是隨機森林?隨機森林的工作原理





 工商網監
工商網監
評論