 一文解析人臉識別算法的廣泛分類及構建塊
一文解析人臉識別算法的廣泛分類及構建塊
作者:Akshat Agarwal,Ipshita Biswas
自遠古以來,人臉一直是最直接的識別標準。因此,看到它成為最方便的生物識別技術就不足為奇了。與其他生物識別方法(例如語音,指紋,手形,掌紋)不同,分析面部不需要與所討論的對象進行積極配合。面部識別可以通過照片,視頻或實時捕獲來完成。
人臉識別是一個廣泛的術語,用于識別或驗證照片和視頻中的人物。該方法包括檢測,對準,特征提取和識別。
盡管存在一些實際挑戰,面部識別仍在醫療,執法,鐵路預訂,安全,家庭自動化和辦公室等各個領域得到廣泛使用。
在這篇文章中,您將發現以下內容:
什么是面部識別?
人臉識別算法的廣泛分類
面部識別系統的各個階段
面部識別構建塊概述
看一下人臉識別SDK
什么是面部識別?
面部識別是一種生物識別技術,該軟件使用深度學習算法來分析個人的面部特征并存儲數據。然后,該軟件將照片,視頻或實時捕獲的各種面孔與數據庫存儲的面孔進行比較,并驗證身份。通常,該軟件可以識別一個人的臉上大約80個不同的節點。節點用作定義個人面部變量的端點。這些變量包括–嘴唇的形狀,眼睛,鼻子的長度和寬度以及眼窩的深度。
與其他生物識別技術相比,面部識別的普及是由于這樣的事實,即它通常趨于更準確且侵入性最小。
面部識別算法的分類面部識別是一種識別已經在數據庫中注冊的面部的技術。面部識別系統廣泛地涉及兩個任務-驗證和識別。
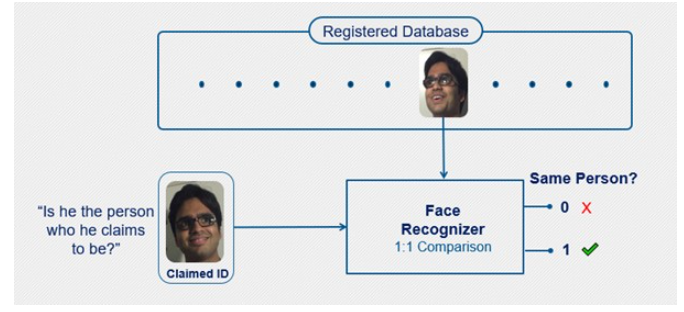
圖1:人臉驗證
驗證旨在回答以下問題:“他是他聲稱的那個人嗎?”當某人聲稱自己是特定人時,驗證系統會在數據庫中找到其個人資料。它將人的臉與數據庫中顯示的個人資料中的臉進行比較,以檢查它們是否匹配。這是一個1對1的匹配系統,因為該系統必須將個人的臉部與鏈接的個人資料中已經存在的特定臉部進行匹配。因此,驗證比識別更快,更準確。
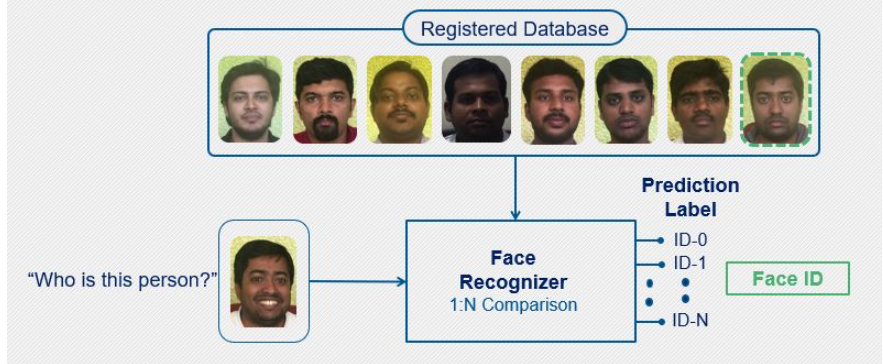
圖2:人臉識別
在人臉識別中,系統嘗試對照其數據庫中存在的所有人臉來檢查輸入人臉。這是一對一的匹配系統。
面部識別系統的各個階段
讓我們談談面部識別系統的兩個階段:注冊和識別。
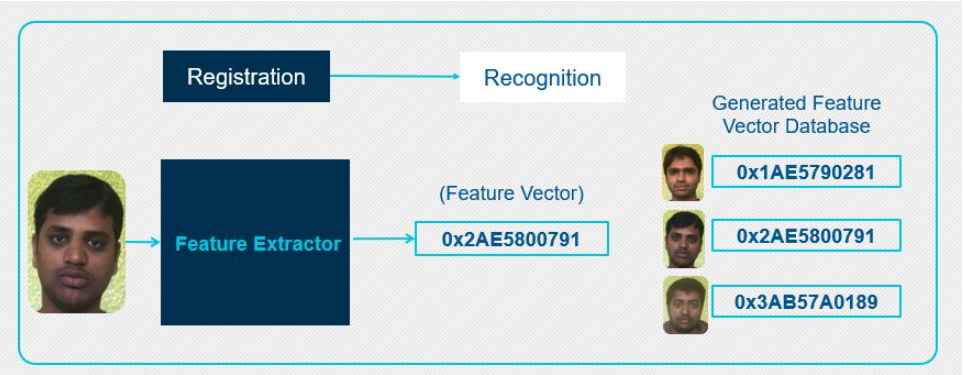
圖3:面部識別階段I
在第一階段或注冊階段,將注冊一組已知的面孔。然后,特征提取器為每個注冊人臉生成唯一的特征向量。基于每個臉部的獨特臉部特征來生成特征向量。提取的特征向量(對于每個人臉都是唯一的)成為已注冊數據庫的一部分,可用于將來參考。
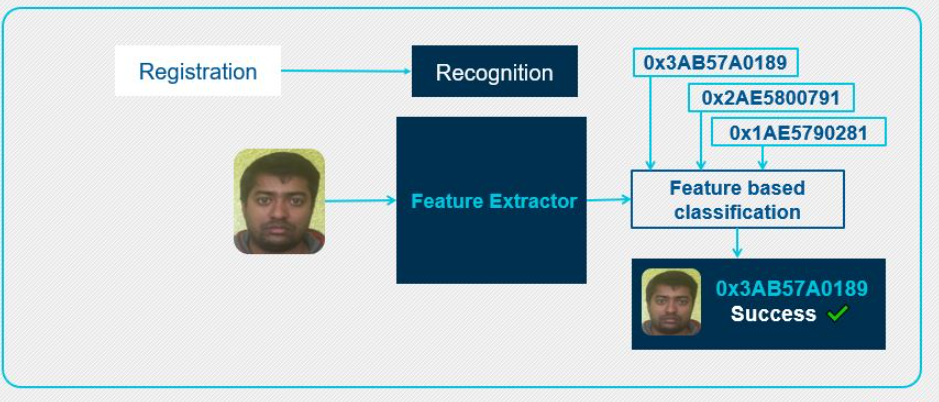
圖4:面部識別階段II
在識別階段,將輸入圖像提供給特征提取器以執行面部識別。在此,特征提取器也生成對于輸入面部圖像唯一的特征向量。然后將該特征向量與數據庫中已經可用的特征向量進行比較。“基于特征的分類”塊比較輸入人臉的人臉特征與數據庫的已注冊人臉之間的距離。當注冊的面部滿足匹配標準時,基于特征的分類將返回在數據庫中找到的匹配面部ID。
面部識別系統的組成部分
面部識別系統的主要組件是:面部檢測,界標檢測,生動度檢測,面部識別模塊(面部識別,面部識別/面部驗證)。
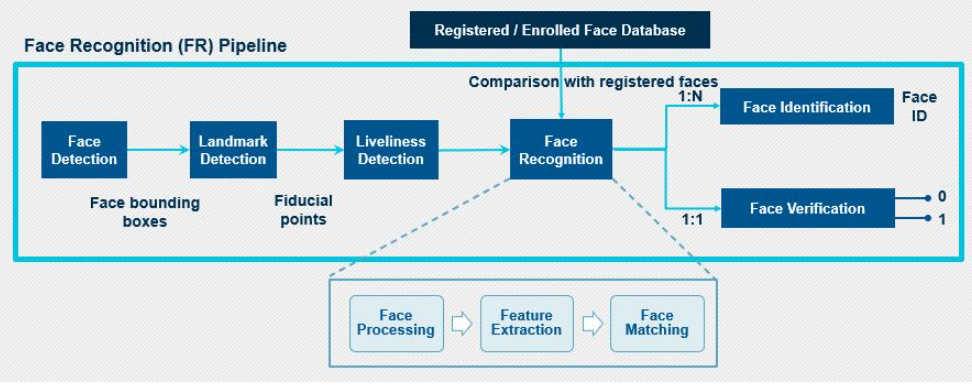
圖5:面部識別模塊
首先,來自視頻流的圖像或幀被發送到面部檢測模塊,在此從輸入圖像中檢測面部。作為輸出,它將發送檢測到的面部的邊界框坐標。這里要注意的是,即使人臉檢測器定位了圖像的人臉并為每個人臉創建了邊框,它也不能保證人臉的正確對齊,并且人臉綁定框會發生抖動。因此,需要面部預處理階段以獲得有效的面部向量。該階段有助于提高系統的面部檢測能力。
人臉預處理在界標檢測塊中完成,界標檢測塊可識別參考點在眼睛,鼻子,嘴唇,下巴,下巴等人臉上的位置(也稱為基準界標點)。然后,將這些檢測到的臉部界標補償為臉部的空間變化。這是通過識別面部的幾何結構并基于各種轉換(例如平移縮放旋轉)獲得規范的對齊方式來完成的。這將輸出具有標準化規范坐標的人臉緊邊界框。
在將對齊的臉部發送到臉部識別模塊之前,必須檢查臉部欺騙,以確保臉部是從圖像或視頻的實時供稿中獲取的,并且不是為了獲得未授權訪問而被欺騙的臉部。活力檢測器執行此檢查。
然后將圖像發送到下一個塊,即人臉識別塊。在成功完成人臉識別之前,此塊執行一系列處理任務。第一步是人臉處理,這是處理輸入人臉內類內變化所必需的。這是必不可少的步驟,因為我們不希望面部識別器模塊因輸入面部圖像中存在的姿勢,表情,照度變化和遮擋等變化而分散注意力。解決輸入面中的類內差異之后,下一個重要的處理步驟是特征提取。上面已經討論了特征提取器的功能。
面部識別模塊的最后一步是面部匹配步驟,在該步驟中,將在最后一步中獲得的特征向量與數據庫中注冊的面部向量進行比較。在該步驟中,計算相似度,并生成相似度分數,根據需要將該相似度分數進一步用于面部識別或面部驗證。
面部識別SDK示例
圖6:面部識別SDK的第一步
我們將使用PathPartner的可授權面部識別SDK軟件解決方案來展示如何實現準確的面部檢測和面部識別系統。該SDK包含機器學習和計算機視覺算法,可讓您執行六個關鍵的人臉識別任務。
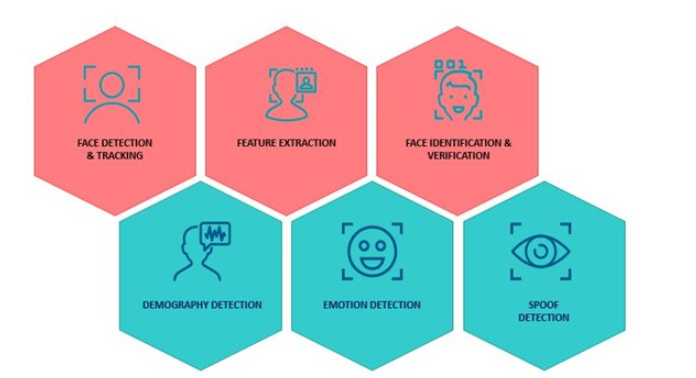
圖7:使用SDK執行的六個面部識別任務
SDK有兩種變體:
低復雜度型號,型號大小低至10MB,適合內存和處理能力低的終端設備。
高復雜度變量,模型大小為90MB,適用于全方位服務的邊緣設備。
該算法在德州儀器(TI),高通(Qualcomm),英特爾(Intel),ARM(ARM),恩智浦(NXP)等一系列嵌入式平臺上進行了優化,并且可以在云服務器平臺上進一步工作。
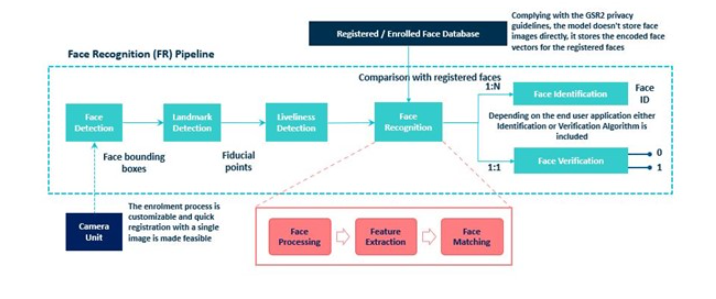
圖8:SDK的構建塊
開發基于CNN的面部識別系統
與基于非CNN的方法相比,基于CNN的方法更為可取,以便減少應對諸如遮擋和不同照明條件等挑戰的精力。識別過程包括以下步驟:
數據采集
公開可用的數據集并未涵蓋對面部識別至關重要的所有評估參數。因此,這需要在許多標準和內部數據集上進行詳細的基準測試,這些數據集涵蓋可用于人臉分析的各種變化。此SDK支持以下變體:姿勢,照明,表情,遮擋,性別,背景,種族,年齡,眼睛,外觀。
深度學習模型設計
模型的復雜性取決于最終用戶的應用程序。該SDK在駕駛員監控系統(DMS)和智能考勤系統中實現。
駕駛員監控系統:為了評估駕駛員的機敏性和實時關注,需要邊緣計算。因此,需要魯棒的,低復雜度的系統。在這里,機器學習模型用于面部檢測和界標回歸,而淺層和深層CNN模型用于估計和分類。
培訓和優化
這些模塊在最初準備的數據集中進行了預訓練。該解決方案已在各種開源數據集(例如FDDB,LFW和定制的內部開發數據集)上進行了測試。
克服各種挑戰
照明變化–為了克服由于照明條件變化而引起的問題,采用了兩種方法。一種是使用基于甘特圖的方法將RGB轉換為類似NIR的圖像。另一個正在使用RGB數據訓練模型,并在輸入端使用NIR圖像對其進行微調。
姿勢和表情變化–如果可以從非正面視圖獲得面部圖像,則必須從一個或多個可用圖像中獲得面部圖像的規范視圖。這是通過基于界標點估計相對于頭部角度的姿勢變化,然后使用傾斜,拉伸,鏡像和其他操作來獲得前額路線來實現的。這使得面部識別系統能夠輸出姿勢不變的表示,并顯著提高面部識別的準確性。為了克服由于表情差異而產生的影響,在預處理階段執行面部對齊。
遮擋–目前,SDK正在接受訓練以檢測蒙面。在這種情況下,模型被訓練為僅處理眼睛和額頭周圍的數據;但是,當系統中注冊的人數有限時,這種方法在不受控制的環境(如辦公室設置)中可獲得最佳結果。
外觀變化–發型,老化和使用化妝品的差異會導致個人外觀的重大差異。因此,在很大程度上降低了面部識別精度。為了解決此問題,SDK使用了對外觀變化具有魯棒性的表示和匹配方案。
圖9:即使沒有胡須也可以識別出的臉;PathPartner的面部識別模型可用于從汽車應用程序(例如DMS)到零售應用程序(可能包括客戶情感估計)的各個行業。
結論
如今,面部識別被認為是所有生物特征測量中最自然的。深度學習已成為大多數正在開發的面部識別算法的核心組成部分。面部識別算法正在呈指數級增長。根據NIST最近的一份報告,在過去的五年(2013-2018年)中,識別準確性取得了巨大的進步,超過了2010-2013年期間所取得的進步。
盡管存在一些實際挑戰,但是面部識別技術已廣泛應用于零售,汽車,銀行,醫療保健,市場營銷等各個行業。面部識別算法除了提高識別人的準確性外,還擴展了其在檢測面部表情和行為方面的范圍。
編輯:hfy
-
生物識別
+關注
關注
3文章
1210瀏覽量
52622
發布評論請先 登錄
相關推薦
校園人臉識別閘機通道的應用

如何提升人臉門禁一體機的識別準確率?







 工商網監
工商網監
評論