") 一篇非常新的介紹PyTorch內(nèi)部機(jī)制的文章
一篇非常新的介紹PyTorch內(nèi)部機(jī)制的文章
譯者序:這篇博文是一篇非常新的介紹PyTorch內(nèi)部機(jī)制的文章,作者Edward Z Yang來(lái)自于Stanford大學(xué),是PyTorch的核心開(kāi)發(fā)者之一。文章中介紹了如何閱讀PyTorch源碼和擴(kuò)展PyTorch的技巧。目前講PyTorch底層的文章不多,故將其翻譯出來(lái),才疏學(xué)淺,如有疏漏,歡迎留言討論。 原文鏈接:http://blog.ezyang.com/2019/05/pytorch-internals/ 翻譯努力追求通俗、易懂,有些熟知的名詞沒(méi)有進(jìn)行翻譯比如(Tensor, 張量) 部分專(zhuān)有名詞翻譯對(duì)照表如下 英文 譯文
| autograde | 自動(dòng)微分 |
| tensor | 張量(翻譯保持了tensor) |
| layout | 布局(主要講的是數(shù)據(jù)在內(nèi)存中的分布) |
| device | 設(shè)備(比如CPU或者GPU) |
| dtype | 數(shù)據(jù)類(lèi)型(比如 float, int) |
| kernels | 實(shí)現(xiàn)某個(gè)操作的具體代碼(翻譯保持了kernels) |
| operation | 操作(比如加,矩陣相乘) |
| operator | 操作符 |
| metadata | 元數(shù)據(jù) |
| stride | 步長(zhǎng) |
| dimension | 維度 |
| view | 視圖 |
| offset | 偏移量 |
| storage | 存儲(chǔ) |
| dispatch | 分派 |
| wrap | 封裝 |
| unwrap | 解封裝(翻譯保持了unwrap) |
這篇博文是一篇長(zhǎng)論文形式的關(guān)于PyTorch內(nèi)部機(jī)制的演講材料,我于2019年5月14日在PyTorch紐約見(jiàn)面會(huì)中進(jìn)行了這場(chǎng)演講。
Intros

大家好!我今天帶來(lái)的是關(guān)于PyTorch內(nèi)部機(jī)制的演講

這個(gè)演講的受眾是那些已經(jīng)用過(guò)PyTorch,問(wèn)過(guò)自己"如果我能給PyTorch做些貢獻(xiàn)豈不美哉"但是又被PyTorch龐大的C++代碼嚇退的人。實(shí)話(huà)說(shuō):有時(shí)候PyTorch的代碼庫(kù)確實(shí)又多又雜。這個(gè)演講的目的是給你提供一張導(dǎo)向圖:告訴你PyTorch這個(gè)"支持自動(dòng)微分的tensor庫(kù)"的基本結(jié)構(gòu),給你介紹一些能夠幫助你在PyTorch代碼庫(kù)中暢游的工具和小技巧。我假設(shè)你之前寫(xiě)過(guò)一些PyTorch代碼,但是不需要你對(duì)如何實(shí)現(xiàn)一個(gè)機(jī)器學(xué)習(xí)庫(kù)有過(guò)深入的理解。

這個(gè)演講分為兩個(gè)部分:在第一部分,我將會(huì)向你介紹tensor庫(kù)的基本概念。我將會(huì)從你所熟知的tensor數(shù)據(jù)類(lèi)型談起,并且詳細(xì)討論這個(gè)數(shù)據(jù)類(lèi)型提供了什么,作為幫助你理解它是如何實(shí)現(xiàn)的指引。如果你是一個(gè)PyTorch的重度用戶(hù),大部分內(nèi)容都是你所熟知的。我們也將會(huì)討論擴(kuò)展PyTorch的"三要素":布局(layout),設(shè)備(device)和數(shù)據(jù)類(lèi)型(dtype),這三個(gè)要素指導(dǎo)著我們選擇哪種方式擴(kuò)展Tensor類(lèi)。
在紐約的現(xiàn)場(chǎng)演講中,我跳過(guò)了關(guān)于自動(dòng)微分(autograde)的部分,不過(guò)我在這個(gè)博文中簡(jiǎn)要的討論了它們。 第二部分包含了PyTorch源碼的細(xì)節(jié)。我會(huì)告訴你如何在復(fù)雜autograd的代碼中找到邏輯,哪些代碼是重要的,哪些代碼是老舊的,以及所有PyTorch提供的易用工具來(lái)幫助你編寫(xiě)kernels。
Concepts
Tensor/Storage/Strides
Tensor 是PyTorch的核心數(shù)據(jù)結(jié)構(gòu)。你可能對(duì)tensor的概念已經(jīng)相當(dāng)了解了:它是包含若干個(gè)標(biāo)量(標(biāo)量可以是各種數(shù)據(jù)類(lèi)型如浮點(diǎn)型、整形等)的n-維的數(shù)據(jù)結(jié)構(gòu)。我們可以認(rèn)為tensor包含了數(shù)據(jù)和元數(shù)據(jù)(metadata),元數(shù)據(jù)用來(lái)描述tensor的大小、其包含內(nèi)部數(shù)據(jù)的類(lèi)型、存儲(chǔ)的位置(CPU內(nèi)存或是CUDA顯存?)
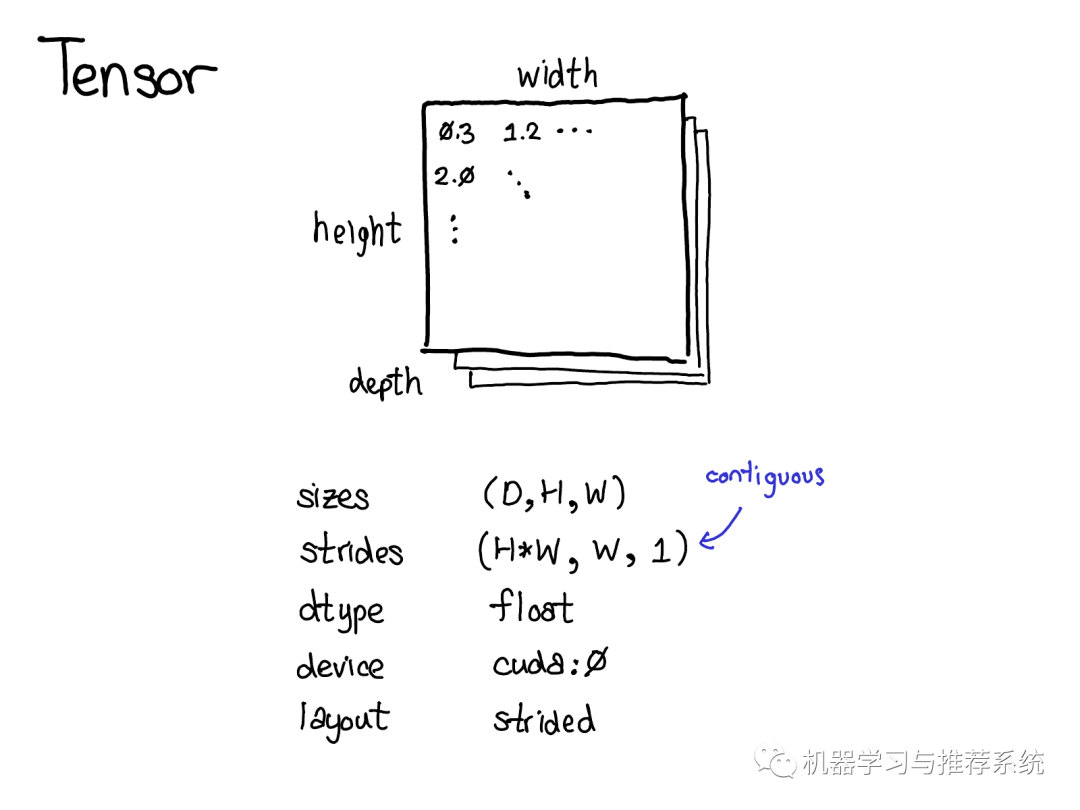
也有一些你可能不太熟悉的元數(shù)據(jù):步長(zhǎng)(the stride),步長(zhǎng)實(shí)際上是PyTorch的一個(gè)亮點(diǎn),所以值得花點(diǎn)時(shí)間好好討論一下它。
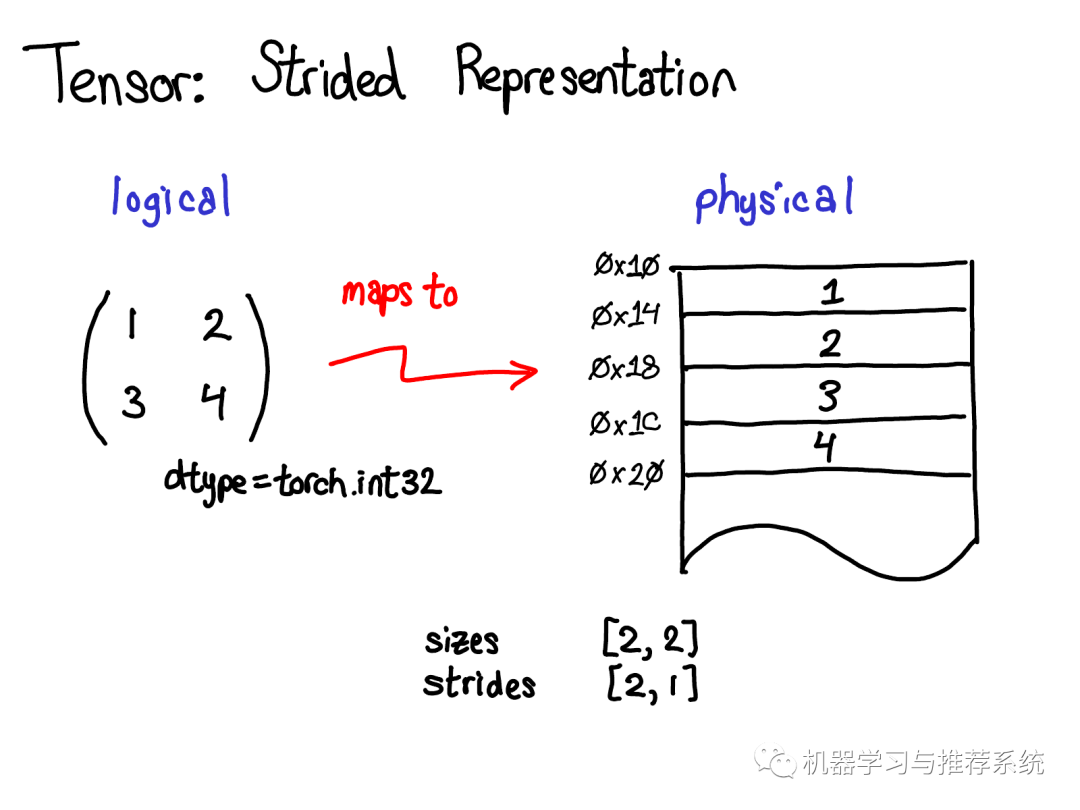
Tensor是一個(gè)數(shù)學(xué)概念。當(dāng)用計(jì)算機(jī)表示數(shù)學(xué)概念的時(shí)候,通常我們需要定義一種物理存儲(chǔ)方式。最常見(jiàn)的表示方式是將Tensor中的每個(gè)元素按照次序連續(xù)的在內(nèi)存中鋪開(kāi)(這是術(shù)語(yǔ)contiguous的來(lái)歷),將每一行寫(xiě)到相應(yīng)內(nèi)存位置里。如上圖所示,假設(shè)tensor包含的是32位的整數(shù),因此每個(gè)整數(shù)占據(jù)一塊物理內(nèi)存,每個(gè)整數(shù)的地址都和上下相鄰整數(shù)相差4個(gè)字節(jié)。為了記住tensor的實(shí)際維度,我們需要將tensor的維度大小記錄在額外的元數(shù)據(jù)中。 那么,步長(zhǎng)在物理表示中的作用是什么呢?
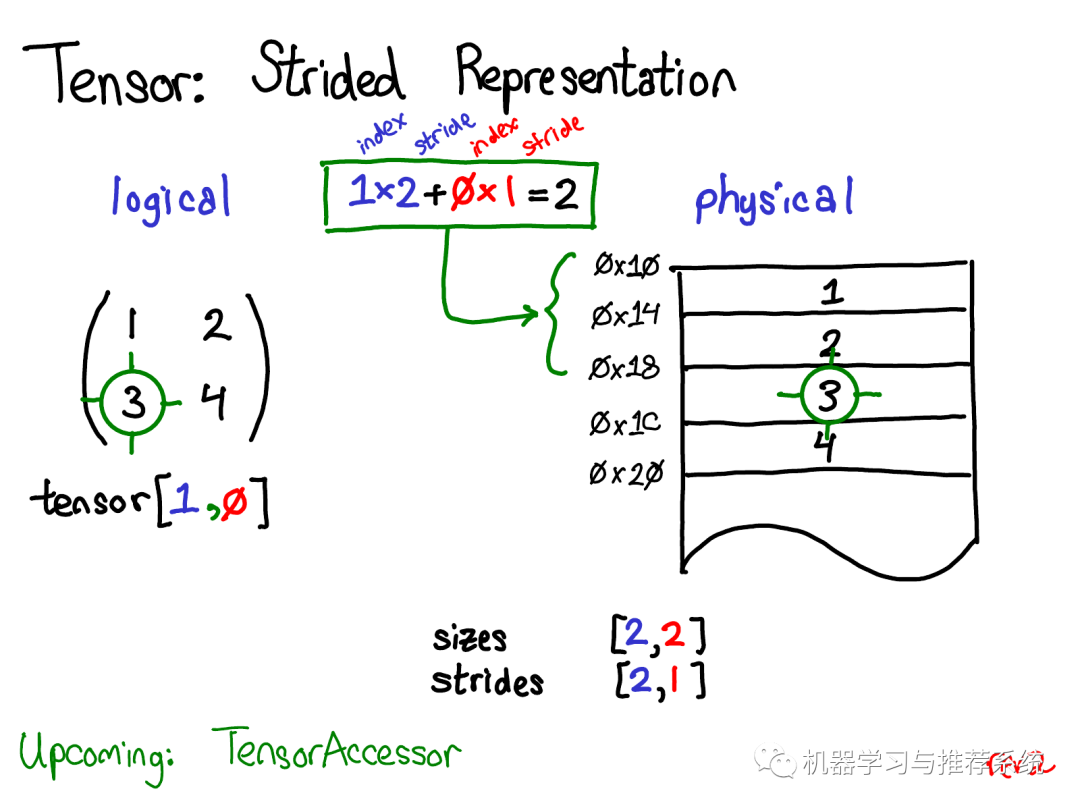
假設(shè)我想要訪(fǎng)問(wèn)位于tensor [1, 0]位置處的元素,如何將這個(gè)邏輯地址轉(zhuǎn)化到物理內(nèi)存的地址上呢?步長(zhǎng)就是用來(lái)解決這樣的問(wèn)題:當(dāng)我們根據(jù)下標(biāo)索引查找tensor中的任意元素時(shí),將某維度的下標(biāo)索引和對(duì)應(yīng)的步長(zhǎng)相乘,然后將所有維度乘積相加就可以了。在上圖中我將第一維(行)標(biāo)為藍(lán)色,第二維(列)標(biāo)為紅色,因此你能夠在計(jì)算中方便的觀(guān)察下標(biāo)和步長(zhǎng)的對(duì)應(yīng)關(guān)系。
求和返回了一個(gè)0維的標(biāo)量2,而內(nèi)存中地址偏移量為2的位置正好儲(chǔ)存了元素3。 (在后面的演講中,我會(huì)討論TensorAccessor,一個(gè)方便的類(lèi)來(lái)處理下標(biāo)到地址的計(jì)算。當(dāng)你使用TensorAccessor而不是原始的指針的時(shí)候,這個(gè)類(lèi)能隱藏底層細(xì)節(jié),自動(dòng)幫助你完成這樣的計(jì)算) 步長(zhǎng)是實(shí)現(xiàn)PyTorch視圖(view)的根基。例如,假設(shè)我們想要提取上述tensor的第二行:
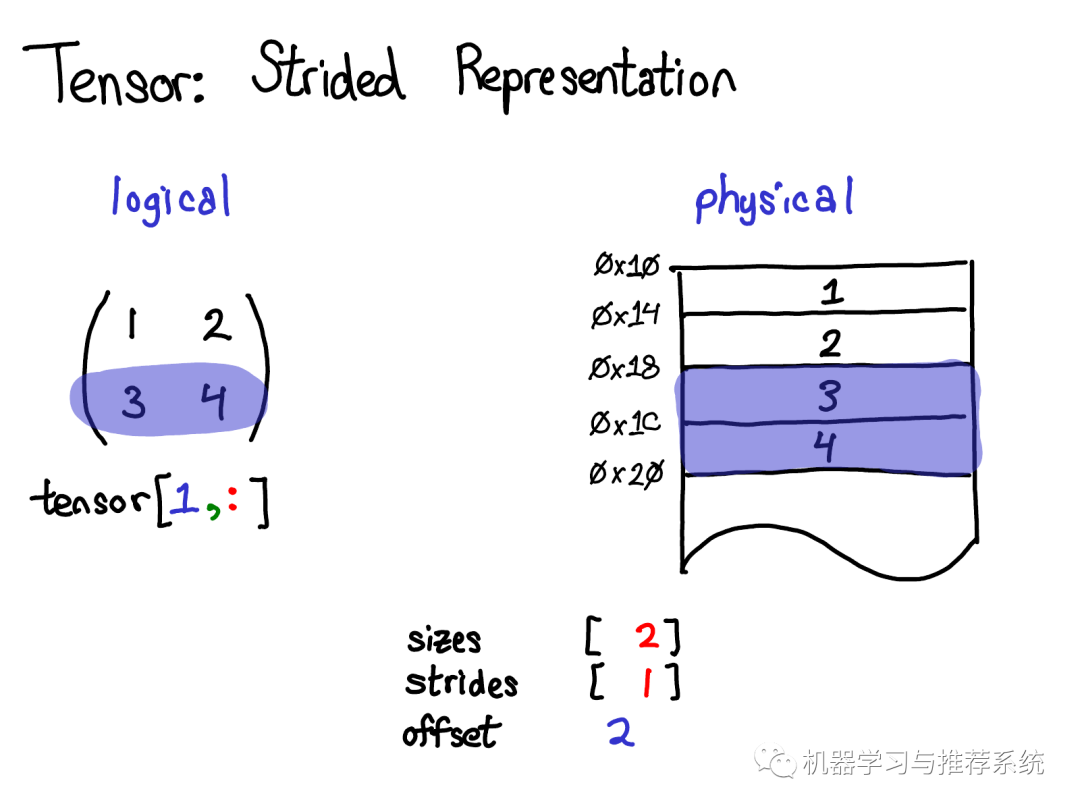
使用高級(jí)索引技巧,我只需要寫(xiě)成tensor[1, :] 來(lái)獲取這一行。重要的事情是:這樣做沒(méi)有創(chuàng)建一個(gè)新的tensor;相反,它只返回了原tensor底層數(shù)據(jù)的另一個(gè)視圖。這意味著如果我編輯了這個(gè)視圖中的數(shù)據(jù),變化也會(huì)反應(yīng)到原tensor上。在這個(gè)例子中,不難看出視圖是怎么做的:3和4存儲(chǔ)在連續(xù)的內(nèi)存中,我們所要做的是記錄一個(gè)偏移量(offset),用來(lái)表示新的視圖的數(shù)據(jù)開(kāi)始于原tensor數(shù)據(jù)自頂向下的第二個(gè)。(每一個(gè)tensor都會(huì)記錄一個(gè)偏移量,但是大多數(shù)時(shí)候他們都是0,我在圖片中忽略了這樣的例子)
來(lái)自于演講的問(wèn)題:如果我給一個(gè)tensor生成了一個(gè)視圖,我怎樣釋放掉原tensor的內(nèi)存? 回答:你必須要復(fù)制一份這個(gè)視圖,以切斷和原tensor物理內(nèi)存的關(guān)系。除此之外,別無(wú)選擇。順便提一下,如果你之前寫(xiě)過(guò)Java,拿到一個(gè)字符串的子字符串有相似的問(wèn)題,因?yàn)槟J(rèn)情況下不會(huì)產(chǎn)生數(shù)據(jù)的復(fù)制,因此子字符串關(guān)聯(lián)著(可能非常大的)原字符串。這個(gè)問(wèn)題在Java 7u6被修復(fù)了。
一個(gè)更有趣的例子是假設(shè)我想要拿第一列的數(shù)據(jù):
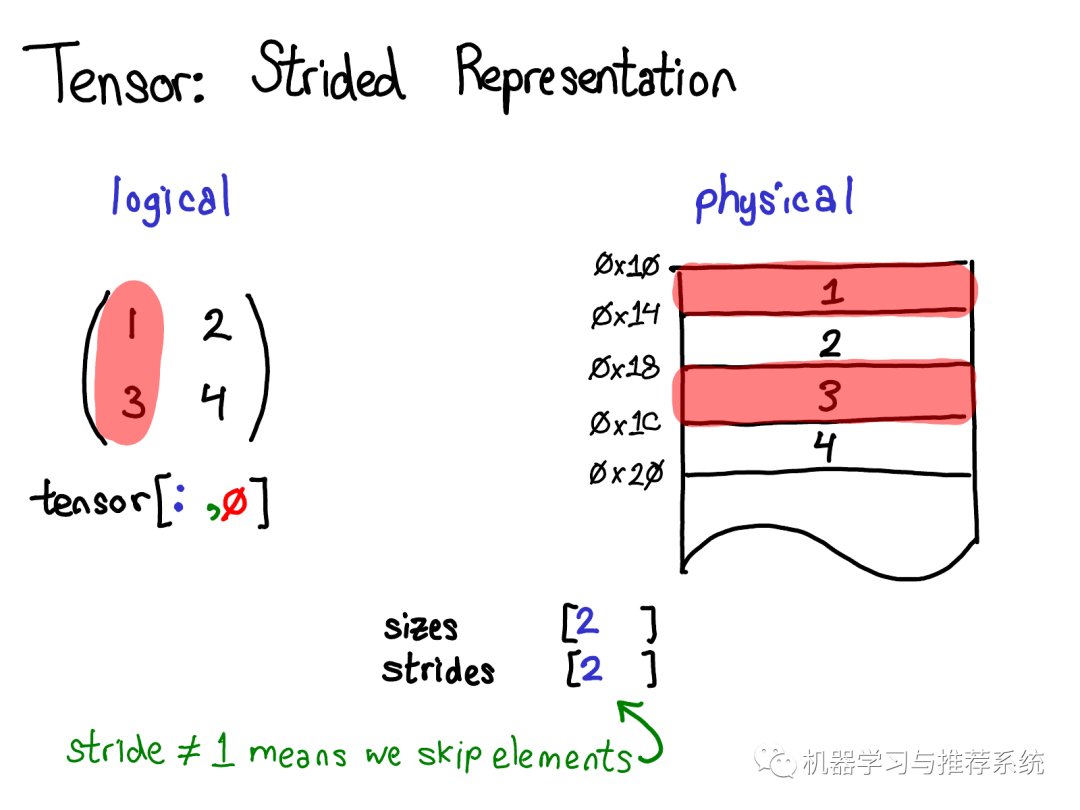
物理內(nèi)存中處于第一列的元素是不連續(xù)的:每個(gè)元素之間都隔著一個(gè)元素。這里步長(zhǎng)就有用武之地了:我們將步長(zhǎng)指定為2,表示在當(dāng)前元素和下一個(gè)你想訪(fǎng)問(wèn)的元素之間, 你需要跳躍2個(gè)元素(跳過(guò)1個(gè)元素)。 步長(zhǎng)表示法能夠表示所有tensor上有趣的視圖,如果你想要進(jìn)行一些嘗試,見(jiàn)步長(zhǎng)可視化。 讓我們退一步想想如何實(shí)現(xiàn)這種機(jī)制(畢竟,這是一個(gè)關(guān)于內(nèi)部機(jī)制的演講)。要取得tensor上的視圖,我們得對(duì)tensor的的邏輯概念和tensor底層的物理數(shù)據(jù)(稱(chēng)為存儲(chǔ) storage)進(jìn)行解耦:
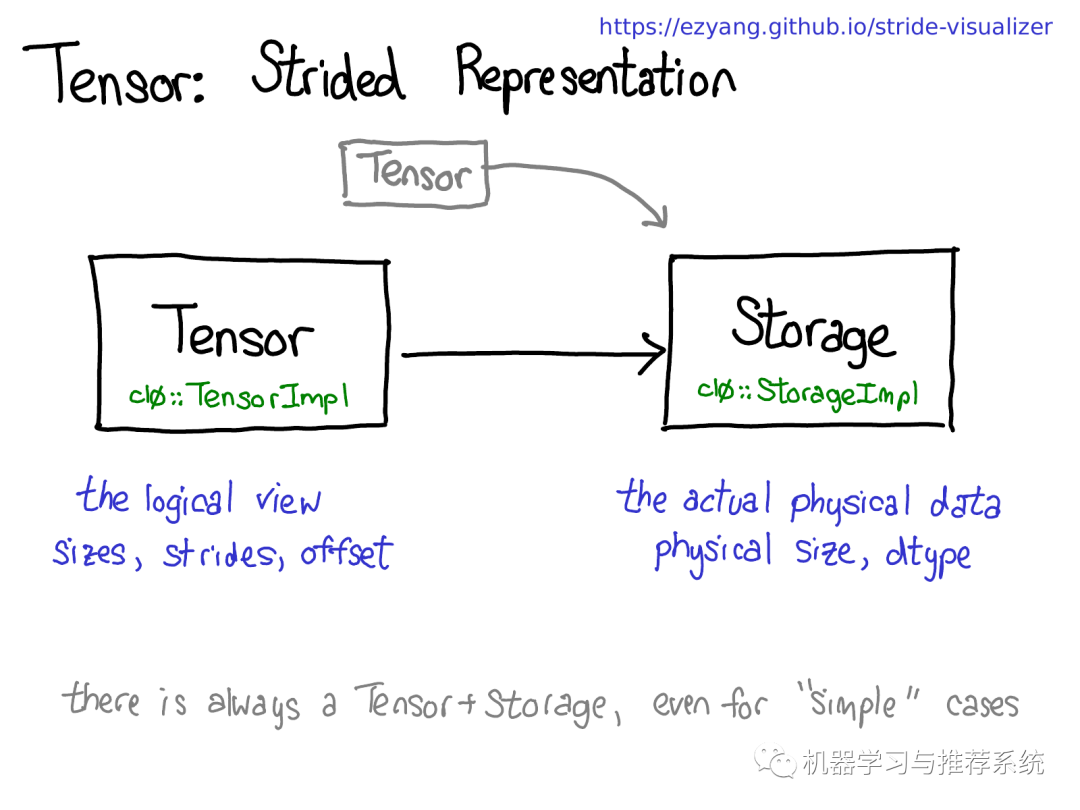
一個(gè)存儲(chǔ)可能對(duì)應(yīng)多個(gè)tensor。存儲(chǔ)定義了tensor的數(shù)據(jù)類(lèi)型和物理大小,而每個(gè)tensor記錄了自己的大小(size),步長(zhǎng)(stride)和偏移(offset),這些元素定義了該tensor如何對(duì)存儲(chǔ)進(jìn)行邏輯解釋。 值得注意的是即使對(duì)于一些不需要用到存儲(chǔ)的"簡(jiǎn)單"的情況(例如,通過(guò)torch.zeros(2,2)分配一個(gè)內(nèi)存連續(xù)的tensor),總是存在著Tensor-Storage對(duì)。
順便提一下,我們也對(duì)改進(jìn)這樣的模型很感興趣。相比于有一個(gè)獨(dú)立的存儲(chǔ),只基于現(xiàn)有tensor定義一個(gè)視圖。這有一點(diǎn)點(diǎn)復(fù)雜,但是優(yōu)點(diǎn)是可以更加直接的表示連續(xù)tensor,而不需要tensor到存儲(chǔ)的轉(zhuǎn)化。這樣的變化將會(huì)使PyTorch的內(nèi)部表示更加像Numpy。
我們對(duì)于tensor的數(shù)據(jù)布局(data layout)做了相當(dāng)多的討論,(有人會(huì)說(shuō),如果你能夠?qū)?shù)據(jù)底層表示搞清楚,剩下的一切就順理成章了)。但是我覺(jué)得還是有必要簡(jiǎn)要的探討一下tensor上的操作(operations)是如何實(shí)現(xiàn)的。抽象來(lái)說(shuō),當(dāng)你調(diào)用torch.mm的時(shí)候,會(huì)產(chǎn)生兩種分派(dispatch):
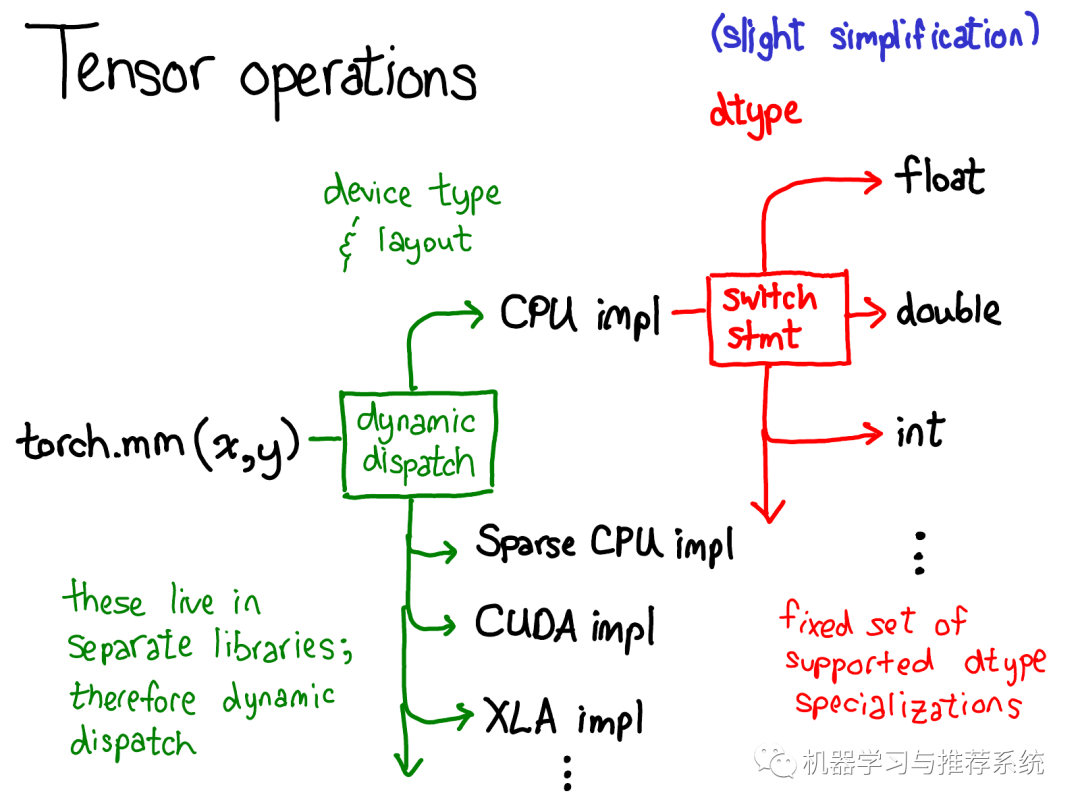
第一種分派基于設(shè)備類(lèi)型(device type)和tensor的布局(layout of a tensor),例如這個(gè)tensor是CPU tensor還是CUDA tensor;或者,這個(gè)tensor是基于步長(zhǎng)的(strided) tensor 還是稀疏tensor。這是一種動(dòng)態(tài)分派的過(guò)程:使用一個(gè)虛函數(shù)調(diào)用實(shí)現(xiàn)(虛函數(shù)的細(xì)節(jié)將在教程的后半部分詳述)。這種動(dòng)態(tài)分派是必要的因?yàn)轱@然CPU和GPU實(shí)現(xiàn)矩陣乘法的方式不同。
這種分派是動(dòng)態(tài)的因?yàn)閷?duì)應(yīng)的kernels(理解為具體的實(shí)現(xiàn)代碼)可能存在于不同的庫(kù)中(e.g. libcaffe2.so 或 libcaffe2_gpu.so),如果你想要訪(fǎng)問(wèn)一個(gè)沒(méi)有直接依賴(lài)的庫(kù),你就得動(dòng)態(tài)的分派你的函數(shù)調(diào)用到這些庫(kù)中。 第二種分派基于tensor的數(shù)據(jù)類(lèi)型(dtype)。這種依賴(lài)可以通過(guò)簡(jiǎn)單的switch語(yǔ)句解決。稍稍思考,這種分派也是有必要的:CPU 代碼(或者GPU代碼)實(shí)現(xiàn)float類(lèi)型矩陣乘法和int類(lèi)型矩陣乘法也會(huì)有差異,因此每種數(shù)據(jù)類(lèi)型(dtype)都需要不同的kernels。 如果你想要理解operators在PyTorch中是如何調(diào)用的,上面這張圖也許最應(yīng)該被記住。當(dāng)講解代碼的時(shí)候我們會(huì)再回到這張圖。
Layout/Device/Dtype

既然我們一直在討論Tensor,我還想花點(diǎn)時(shí)間討論下tensor擴(kuò)展(extension)。畢竟,日常生活中遇到的tensor大部分都并不是稠密的浮點(diǎn)數(shù)tensor。很多有趣的擴(kuò)展包括XLA tensors,quantized tensors,或者M(jìn)KL-DNN tensors。作為一個(gè)tensor library我們需要考慮如何融合各種類(lèi)型的tensors。
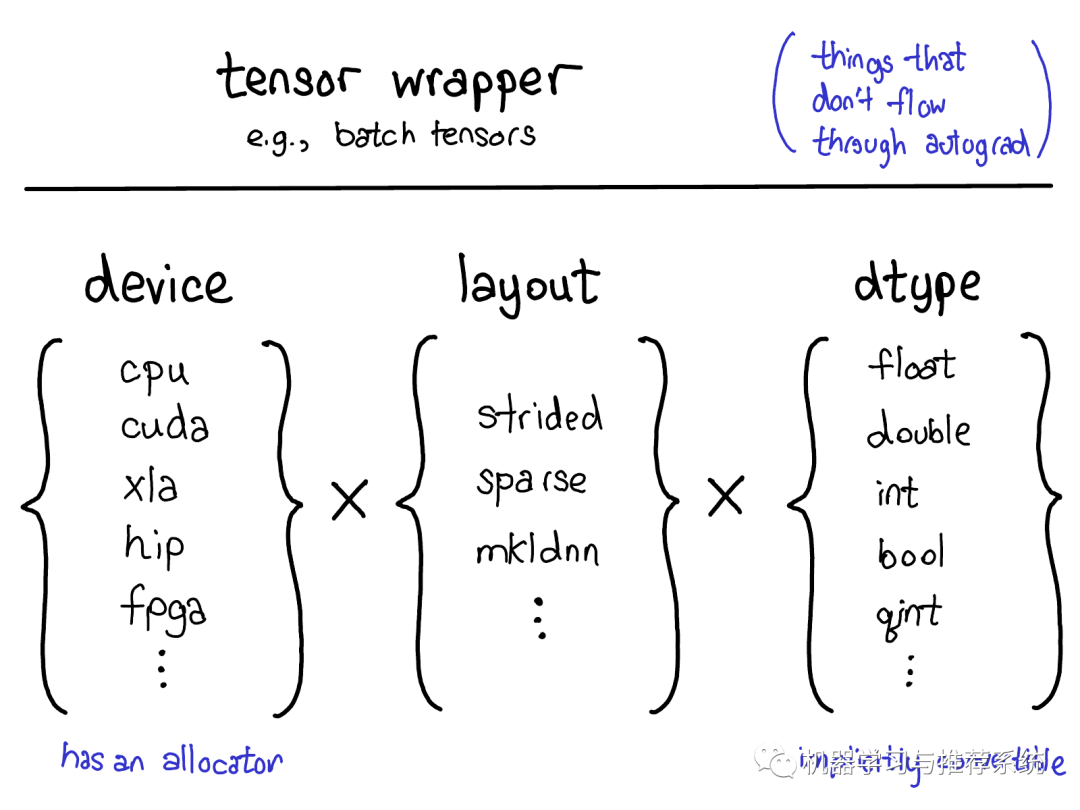
目前來(lái)說(shuō)PyTorch的擴(kuò)展模型提供了4種擴(kuò)展方法。首先,能夠唯一確定Tensor類(lèi)型的"三要素"是:
設(shè)備類(lèi)型(The device) 設(shè)備類(lèi)型描述了tensor的到底存儲(chǔ)在哪里,比如在CPU內(nèi)存上還是在NVIDIA GPU顯存上,在AMD GPU(hip)上還是在TPU(xla)上。不同設(shè)備的特征是它們有自己的存儲(chǔ)分配器(allocator),不同設(shè)備的分配器不能混用。
內(nèi)存布局(The layout) 描述了我們?nèi)绾谓忉屵@些物理內(nèi)存。常見(jiàn)的布局是基于步長(zhǎng)的tensor(strided tensor)。稀疏tensor有不同的內(nèi)存布局,通常包含一對(duì)tensors,一個(gè)用來(lái)存儲(chǔ)索引,一個(gè)用來(lái)存儲(chǔ)數(shù)據(jù);MKL-DNN tensors 可能有更加不尋常的布局,比如塊布局(blocked layout),這種布局難以被簡(jiǎn)單的步長(zhǎng)(strides)表達(dá)。
數(shù)據(jù)類(lèi)型(The dtype) 數(shù)據(jù)類(lèi)型描述tensor中的每個(gè)元素如何被存儲(chǔ)的,他們可能是浮點(diǎn)型或者整形,或者量子整形。
如何你想要增加一種PyTorch tensor類(lèi)型(順便說(shuō)下,請(qǐng)聯(lián)系我們?nèi)绻阏娴南胍鲞@個(gè)!這個(gè)目前來(lái)說(shuō)不是那么容易的事情),你應(yīng)該想想你要擴(kuò)展上面提到的哪一個(gè)決定張量類(lèi)型的因素("三要素")。目前為止,并不是所有的組合都有對(duì)應(yīng)的kernel(比如FPGA上稀疏量子張量的計(jì)算就沒(méi)有現(xiàn)成的kernel),但是原則上來(lái)說(shuō)大部分的組合都可能是道理的,因此至少在一定程度上我們支持它們。
還有一種方法可以用來(lái)擴(kuò)展Tensor,即寫(xiě)一個(gè)tensor的wrapper類(lèi),實(shí)現(xiàn)你自己的對(duì)象類(lèi)型(object type)。聽(tīng)起來(lái)很顯然,但是很多人卻在該用wrapper擴(kuò)展的時(shí)候卻選擇了擴(kuò)展上述三種要素。wrapper類(lèi)擴(kuò)展的一個(gè)非常好的優(yōu)點(diǎn)是開(kāi)發(fā)非常簡(jiǎn)單。 什么時(shí)候我們應(yīng)該寫(xiě)一個(gè)tensor wrapper或者擴(kuò)展PyTorch tensor?一個(gè)至關(guān)重要的測(cè)試是在反向自動(dòng)求導(dǎo)的過(guò)程中你是否需要傳遞該tensor。
例如通過(guò)這樣的測(cè)試,我們就可以知道應(yīng)該通過(guò)擴(kuò)展PyTorch的方式實(shí)現(xiàn)稀疏tensor,而不是建立一個(gè)包含索引tensor和值tensor的Python對(duì)象(wrapper方式):因?yàn)楫?dāng)在一個(gè)包含Embedding的網(wǎng)絡(luò)上做優(yōu)化的時(shí)候,我們希望生成的梯度也是稀疏的。
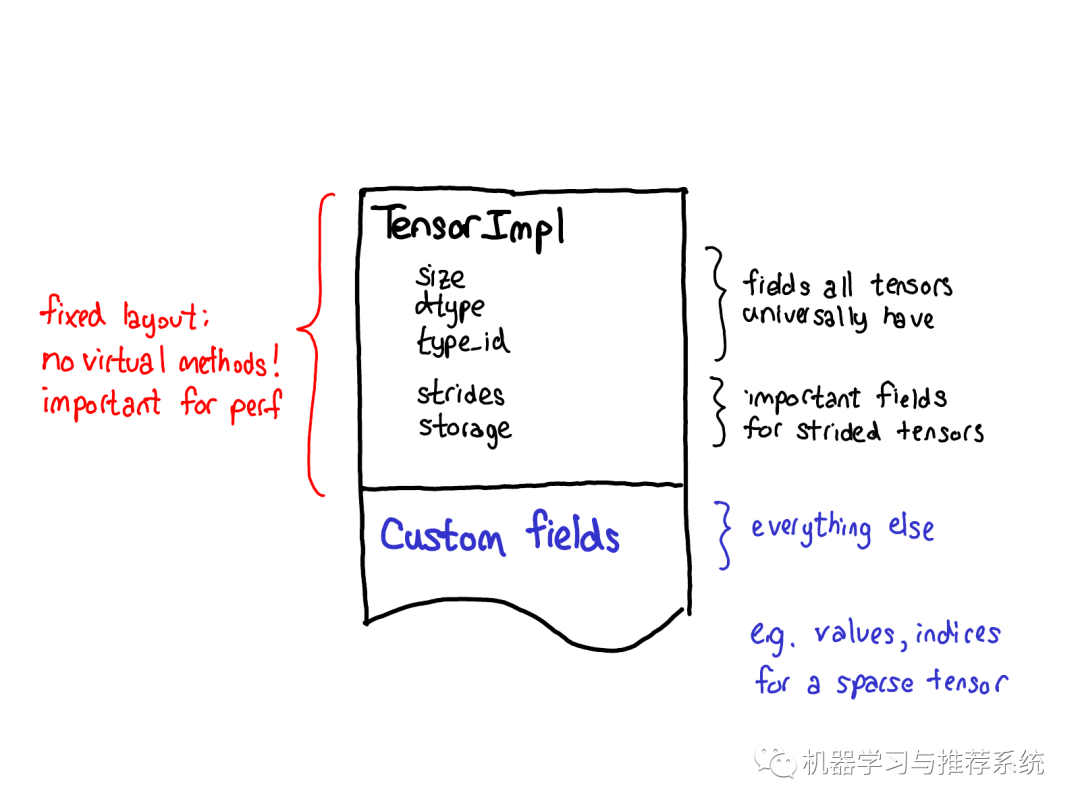
我們關(guān)于tensor擴(kuò)展的哲學(xué)也對(duì)tensor自身的數(shù)據(jù)布局產(chǎn)生著一定的影響。我們始終希望tensor結(jié)構(gòu)能有個(gè)固定的布局:我們不希望一些基礎(chǔ)的operator(這些operator經(jīng)常被調(diào)用),如size of tensor需要一個(gè)虛分派 (virtual dispatches)。因此當(dāng)你觀(guān)察Tensor實(shí)際的布局的時(shí)候(定義在 TensorImpl 結(jié)構(gòu)體中),一些被我們認(rèn)為是所有類(lèi)型tensor都會(huì)有的字段定義在前面,隨后跟著一些strided tensors特有的字段(我們也認(rèn)為它們很重要),最后才是特定類(lèi)型tensor的獨(dú)有字段,比如稀疏tensor的索引和值。
Autograd
上面講述的都是tensor相關(guān)的東西,不過(guò)如果Pytorch僅僅提供了Tensor,那么它不過(guò)是numpy的一個(gè)克隆。PyTorch 發(fā)布時(shí)一個(gè)區(qū)別性的特征是提供了自動(dòng)微分機(jī)制(現(xiàn)在我們有了其他很酷的特性包括TorchScript;但是當(dāng)時(shí),自動(dòng)微分是僅有的區(qū)別點(diǎn)) 自動(dòng)微分到底做了什么呢?自動(dòng)微分是訓(xùn)練神經(jīng)網(wǎng)絡(luò)的一種機(jī)制:

…下面這張圖補(bǔ)充了計(jì)算loss的gradients所需要的代碼:

請(qǐng)花一點(diǎn)時(shí)間學(xué)習(xí)上面這張圖。有一些東西需要展開(kāi)來(lái)講;下面列出了哪些東西值得關(guān)注:
首先請(qǐng)忽略掉那些紅色和藍(lán)色的代碼。PyTorch實(shí)現(xiàn)了reverse-mode automatic differentiation (反向模式自動(dòng)微分),意味著我們通過(guò)反向遍歷計(jì)算圖的方式計(jì)算出梯度。注意看變量名:我們?cè)诩t色代碼區(qū)域的最下面計(jì)算了loss;然后,在藍(lán)色代碼區(qū)域首先我們計(jì)算了grad_loss。loss 由 next_h2計(jì)算而來(lái),因此我們計(jì)算grad_next_h2。嚴(yán)格來(lái)講,這些以grad_開(kāi)頭的變量其實(shí)并不是gradients;他們實(shí)際上是Jacobian矩陣左乘了一個(gè)向量,但是在PyTorch中我們就叫它們grad,大部分人都能理解其中的差異。
即使代碼結(jié)構(gòu)相同,代碼的行為也是不同的:前向(forwards)的每一行被一個(gè)微分計(jì)算代替,表示對(duì)這個(gè)前向操作的求導(dǎo)。例如,tanh操作符變成了tanh_backward操作符(如上圖最左邊的綠線(xiàn)所關(guān)聯(lián)的兩行所示)。前向和后向計(jì)算的輸入和輸出顛倒過(guò)來(lái):如果前向操作生成了next_h2,那么后向操作取grad_next_h2作為輸入。
概述之,自動(dòng)微分做了下圖所示的計(jì)算,不過(guò)實(shí)質(zhì)上沒(méi)有生成執(zhí)行這些計(jì)算所需的代碼。PyTorch 自動(dòng)微分不會(huì)做代碼到代碼的轉(zhuǎn)換工作(即使PyTorch JIT確實(shí)知道如何做符號(hào)微分(symbolic differentiation))。
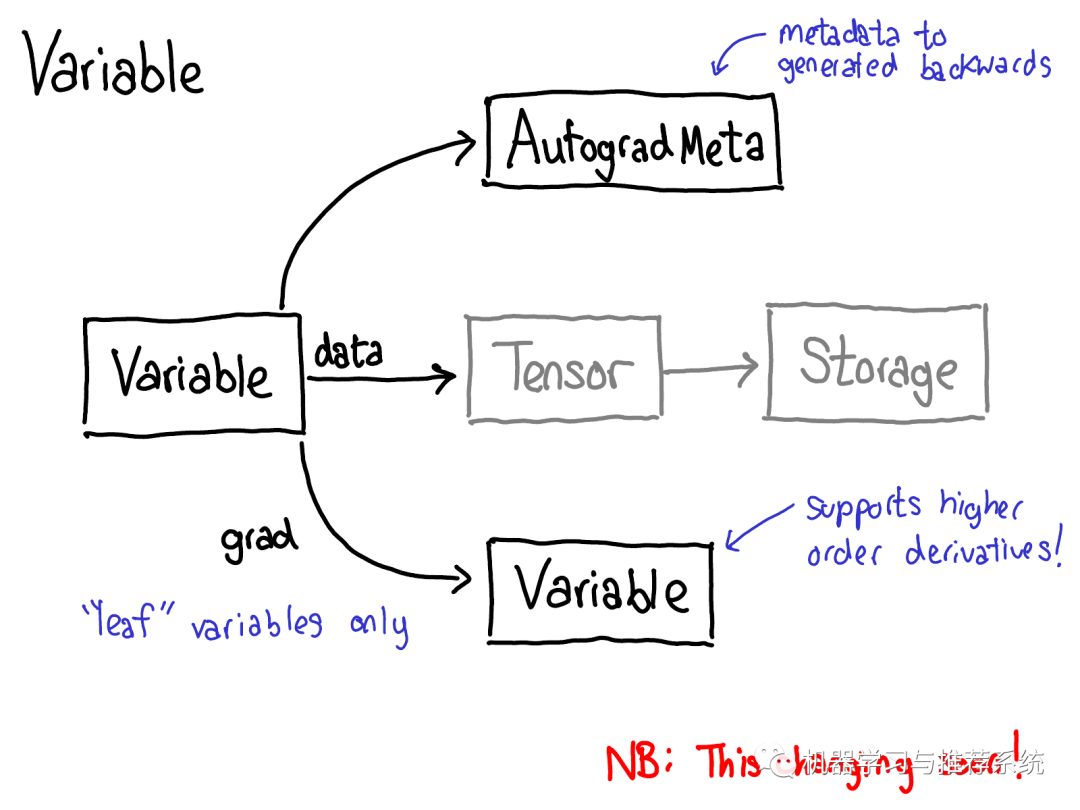
為了實(shí)現(xiàn)這個(gè),當(dāng)我們?cè)趖ensor上調(diào)用各種operations的時(shí)候,一些元數(shù)據(jù)(metadata)也需要被記錄下來(lái)。讓我們調(diào)整一下tensor數(shù)據(jù)結(jié)構(gòu)的示意圖:現(xiàn)在不僅僅單單一個(gè)tensor指向storage,我們會(huì)有一個(gè)封裝著這個(gè)tensor和更多信息(自動(dòng)微分元信息(AutogradeMeta))的變量(variable)。這個(gè)變量所包含的信息是用戶(hù)調(diào)用loss.backward()執(zhí)行自動(dòng)微分所必備的。 順便我們也更新下分派的圖:
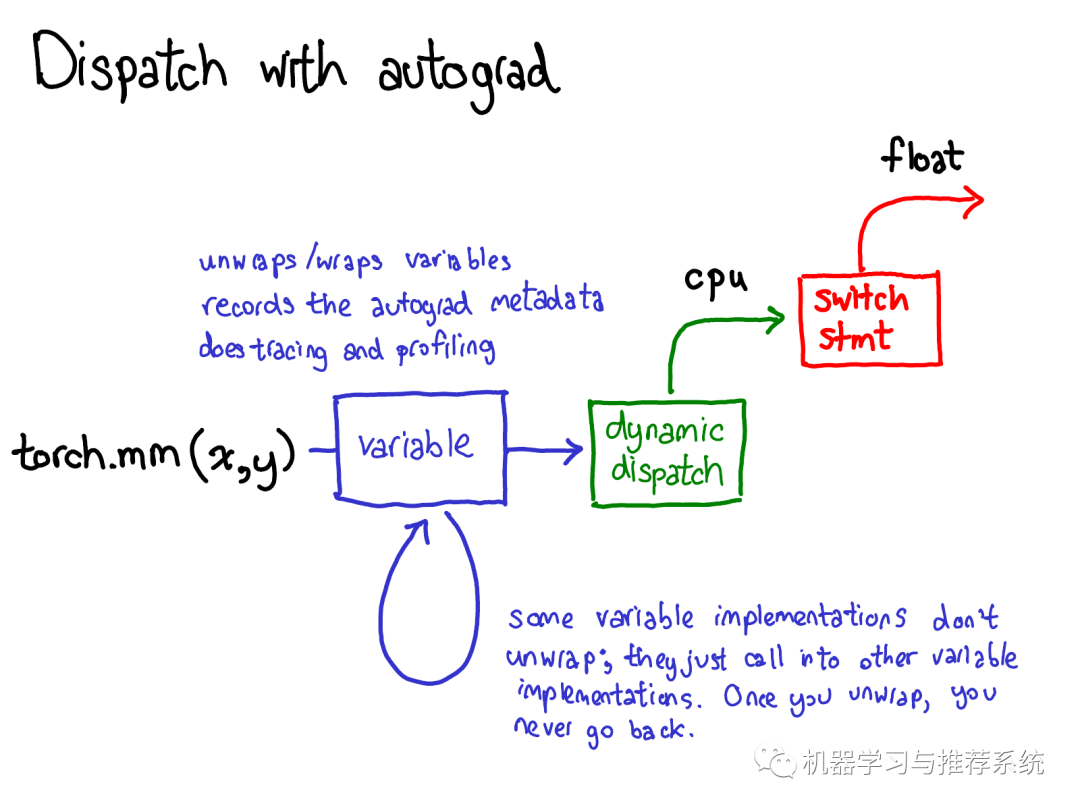
在將計(jì)算分派到CPU或者CUDA的具體實(shí)現(xiàn)之前,變量也要進(jìn)行分派,這個(gè)分派的目的是取出變量?jī)?nèi)部封裝的分派函數(shù)的具體實(shí)現(xiàn)(上圖中綠色部分),然后再將結(jié)果封裝到變量里并且為反向計(jì)算記錄下必要的自動(dòng)微分元信息。 當(dāng)然也有其他的實(shí)現(xiàn)沒(méi)有unwrap操作;他們僅僅調(diào)用其他的變量實(shí)現(xiàn)。你可能會(huì)花很多時(shí)間在變量的調(diào)用棧中跳轉(zhuǎn)。然后,一旦某個(gè)變量unwrap并進(jìn)入了非變量的tensor域,變量調(diào)用棧就結(jié)束了,你不會(huì)再回到變量域,除非函數(shù)調(diào)用結(jié)束并且返回。
Mechanics
到此我們已經(jīng)討論了足夠的概念了,現(xiàn)在來(lái)看看具體的代碼實(shí)現(xiàn)。

PyTorch的源碼包含許多文件目錄,CONTRIBUTING 文件里給這些目錄做了詳細(xì)的解釋?zhuān)贿^(guò)實(shí)話(huà)說(shuō),你只需要關(guān)注4個(gè)目錄:
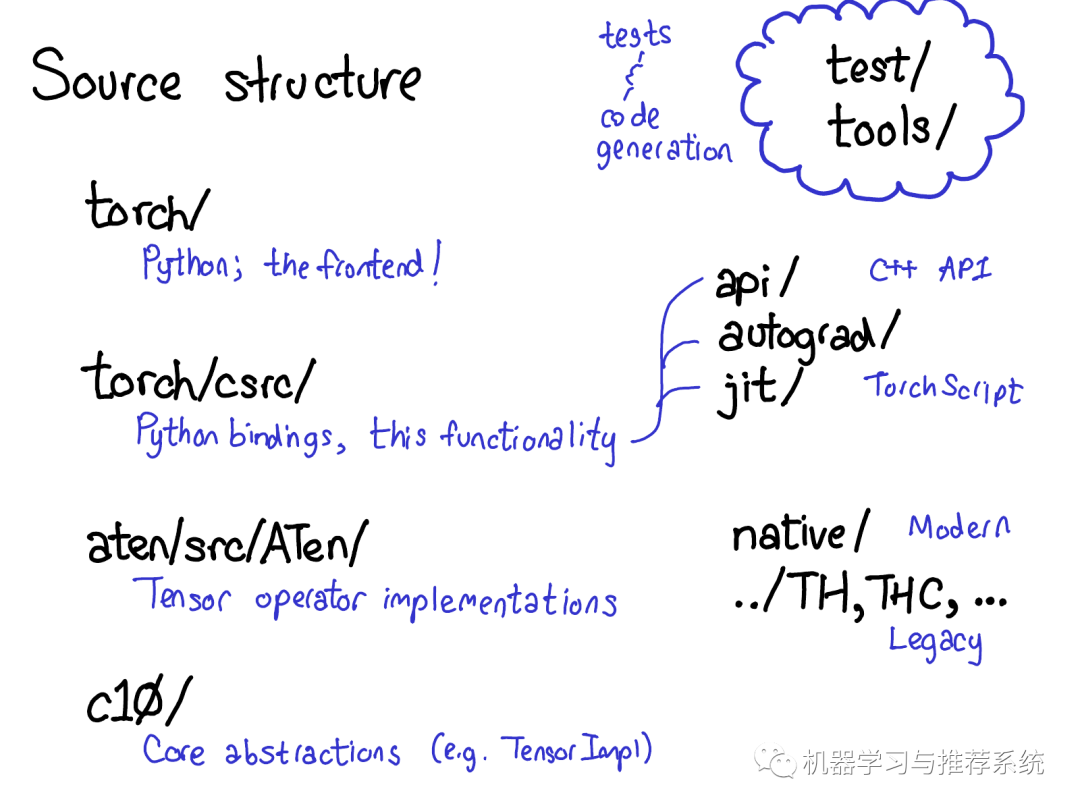
首先,torch/包含了你最熟悉的部分:你在代碼中引入并使用的Python 模塊(modules),這里都是Python代碼,容易修改起來(lái)做各種小實(shí)驗(yàn),然后,暗藏在這些表層代碼的下面是:
torch/csrc/,這部分C++代碼實(shí)現(xiàn)了所謂的PyTorch前端(the frontend of PyTorch)。具體來(lái)說(shuō),這一部分主要橋接了Python邏輯的C++的實(shí)現(xiàn),和一些PyTorch中非常重要的部分,比如自動(dòng)微分引擎(autograd engine)和JIT編譯器(JIT compiler)。
aten/,是"A Tensor Library"的縮寫(xiě),是一個(gè)C++庫(kù)實(shí)現(xiàn)了Tensor的各種operations。如果你需要查找一些實(shí)現(xiàn)kernels的代碼,很大幾率上他們?cè)赼ten/文件夾里。ATen 內(nèi)對(duì)operators的實(shí)現(xiàn)分成兩類(lèi),一種是現(xiàn)代的C++實(shí)現(xiàn)版本,另一種是老舊的C實(shí)現(xiàn)版本,我們不提倡你花太多的時(shí)間在C實(shí)現(xiàn)的版本上。
c10/ ,是一個(gè)來(lái)自于Caffe2 和 A”Ten“的雙關(guān)語(yǔ)(Caffe 10),其中包含了PyTorch的核心抽象,Tensor和Storage數(shù)據(jù)結(jié)構(gòu)的實(shí)際實(shí)現(xiàn)部分。
有如此多的地方看源碼,我們也許應(yīng)該精簡(jiǎn)一下目錄結(jié)構(gòu),但目前就是這樣。如果你做一些和operators相關(guān)的工作,你將花大部分時(shí)間在aten上。
Operator call stack
下面我們來(lái)看看實(shí)踐中這些分離的代碼分別用在那些地方:

(譯注:下面這一部分需要對(duì)C++的機(jī)制有相當(dāng)?shù)牧私猓热缣摵瘮?shù)調(diào)用等等,我添加了一些自己的理解,盡力翻譯得易懂一些,但是不保證完全正確,原文鏈接供參考) 當(dāng)你調(diào)用一個(gè)函數(shù)比如torch.add的時(shí)候,會(huì)發(fā)生哪些事情?如果你記得我們之前討論過(guò)的分派機(jī)制,你的腦海中會(huì)浮現(xiàn)一個(gè)基本的流程:
我們將會(huì)從Python 代碼轉(zhuǎn)到 C++代碼(通過(guò)解析Python調(diào)用的參數(shù)) (譯注:解析調(diào)用參數(shù)下面代碼中有例子)
處理變量分派(VariableType到Type),順便說(shuō)一下,這里的Type和程序語(yǔ)言類(lèi)型沒(méi)有關(guān)系,只是在分派中我們這么叫它) (譯注:這一部分博文中沒(méi)有討論,下面作者也澄清了這是個(gè)疏忽,所以忽略就好了)
處理 設(shè)備類(lèi)型/布局 分派(Type) (譯注:這一部分討論)
找到實(shí)際上的kernel,可能是一個(gè)現(xiàn)代的函數(shù)(modern native funciton),可能是一個(gè)老舊的函數(shù)(legacy TH funciton, TH 后面會(huì)解釋) (譯注:現(xiàn)代的函數(shù)指C++代碼,老舊的多指C代碼,后面有詳細(xì)討論。)
每一個(gè)步驟具體對(duì)應(yīng)到一些代碼。讓我們剖析這一部分代碼:

上面的C++代碼展示了分派具體怎樣實(shí)現(xiàn)的,我們以一個(gè)C實(shí)現(xiàn)的Python function為例子 (譯注:即下面的THPVariable_add, 以TH開(kāi)頭的大都是C代碼,后文會(huì)介紹),這種實(shí)現(xiàn)在Python代碼中我們會(huì)通過(guò)類(lèi)似這樣語(yǔ)句調(diào)用: torch._C.VariableFunctions.add.THPVariable_add。 要強(qiáng)調(diào)的是上面這段代碼是自動(dòng)生成的。你不會(huì)在GitHub repository中搜索到它們,因此你必須得從源碼構(gòu)建PyTorch才能查看到它們。另一個(gè)重要的事實(shí)是,你不需要深入地了解這段代碼干了什么;簡(jiǎn)單的掃一遍代碼并且對(duì)大概的思路有個(gè)了解就足夠了。
如上圖,我用藍(lán)色標(biāo)注了一些最重要的部分:如你所見(jiàn),PythonArgParser class 用來(lái)從Python (譯注:Python add方法)的 args和kwargs中生成C++ parser對(duì)象,(譯注:通過(guò)parser對(duì)象的parse方法可以得到一個(gè)r對(duì)象,r里封裝了左操作數(shù)r.tensor(0),操作符r.scalar(1)和右操作數(shù)r.tensor(1),見(jiàn)上面的代碼) 然后我們調(diào)用dispatch_add函數(shù)(上圖紅色所示),它釋放了Python的全局解釋器鎖(global interpreter lock) 然后調(diào)用一個(gè)一般方法作用到C++ tensor self上(譯注:self tensor是C++ Tensor類(lèi)的對(duì)象,C++ Tensor類(lèi)見(jiàn)下面這張圖)。當(dāng)這個(gè)方法返回時(shí),我們重新將Tensor封裝回Python object。 (到此為止,ppt上有個(gè)疏漏:我應(yīng)該向你展示關(guān)于Variable dispatch的代碼。目前還沒(méi)修復(fù)這個(gè)部分。你可以想象奇妙的魔法發(fā)生后,我們到了...)

當(dāng)我們調(diào)用C++ Tensor類(lèi)的add方法時(shí)候,虛分派還未發(fā)生。然而,一個(gè)內(nèi)聯(lián)(inline)函數(shù)會(huì)在"Type"對(duì)象上調(diào)用一個(gè)虛函數(shù)(譯注:Type對(duì)象指代碼中的type()返回的對(duì)象,虛函數(shù)指add方法)。這個(gè)方法才是真正的虛函數(shù)(這就是為什么我之前說(shuō)Type是一個(gè)媒介,作用是引出虛調(diào)用)。在這個(gè)例子里,這個(gè)虛函數(shù)調(diào)用被分派到TypeDefault的類(lèi)的add實(shí)現(xiàn)上,原因是我們提供了一個(gè)add的實(shí)現(xiàn),這種實(shí)現(xiàn)在任何一種設(shè)備類(lèi)型上(包括CPU和CUDA)都一致(譯注:所以叫TypeDefault);假如我們對(duì)不同的設(shè)備有具體的實(shí)現(xiàn),可能會(huì)調(diào)用類(lèi)似于CPUFloatType::add這樣的函數(shù),意味著虛函數(shù)add最后將實(shí)際的add操作分派到的CPU上浮點(diǎn)數(shù)相加的具體kernel代碼上。
根據(jù)預(yù)期,這個(gè)PPT很快將會(huì)過(guò)時(shí)了,Roy Li正在做一些替代Type分派的工作,這些工作將會(huì)使PyTorch對(duì)于移動(dòng)設(shè)備支持的更好。
值得一提的是,所有的代碼,直到對(duì)于具體kernel的調(diào)用,都是自動(dòng)生成的。
這里有點(diǎn)繞,所以一旦你對(duì)執(zhí)行流程的大方向有一定的了解,我建議你直接跳到kernels的部分。
Tools for writing kernels

PyTorch為kernels編寫(xiě)者提供了許多實(shí)用的工具。在這一節(jié)里,我們將會(huì)簡(jiǎn)要了解他們之中的一部分。但是首先,一個(gè)kernel包含哪些東西?

我們通常上認(rèn)為一個(gè)kernel包含如下部分:
首先,我們?yōu)閗ernel寫(xiě)了一些元數(shù)據(jù)(metadata),這些元數(shù)據(jù)驅(qū)動(dòng)了代碼生成,讓你不用寫(xiě)一行代碼就可以在Python中調(diào)用kernel。
一旦你訪(fǎng)問(wèn)了kernel,意味著你經(jīng)過(guò)了設(shè)備類(lèi)型/布局類(lèi)型的虛函數(shù)分派流程。首先你要寫(xiě)的一點(diǎn)是錯(cuò)誤檢測(cè)(error checking),以保證輸入tensors有正確的維度。(錯(cuò)誤檢測(cè)非常重要!千萬(wàn)別跳過(guò)它們!)
然后,一般我們會(huì)給輸出tensor分配空間,以將結(jié)果寫(xiě)入進(jìn)去
接下來(lái)是編寫(xiě)合適的kernel。到這里,你應(yīng)該做數(shù)據(jù)類(lèi)型分派(第二種分派類(lèi)型dtype),以跳轉(zhuǎn)到一個(gè)為特定數(shù)據(jù)類(lèi)型編寫(xiě)的kernel上。(通常你不用太早做這個(gè),因?yàn)榭赡軙?huì)產(chǎn)生一些重復(fù)的代碼,比如說(shuō)一些邏輯在任何case上都適用)
許多高效的kernel需要一定程度上的并行,因此你需要利用多核(multi-CPU)系統(tǒng)。(CUDA kernels 暗含著并行的邏輯,因?yàn)樗?a target="_blank">編程模型是建立在大量的并行體系上的)
最后,你需要訪(fǎng)問(wèn)數(shù)據(jù)并做希望做的計(jì)算!
在接下來(lái)的PPT里,我會(huì)帶你了解PyTorch提供的一些工具幫助你實(shí)現(xiàn)上述步驟。

為了充分利用PyTorch帶來(lái)的代碼生成機(jī)制,你需要為operator寫(xiě)一個(gè)schema。這個(gè)schema需要給定你定義函數(shù)的簽名(signature),并且控制是否我們生成Tensor方法(比如 t.add())以及命名空間函數(shù)(比如at::add())。你也需要在schema中指明當(dāng)一個(gè)設(shè)備/布局的組合給定的時(shí)候,operator的哪一種實(shí)現(xiàn)需要被調(diào)用。具體格式細(xì)節(jié)查看README in native

你也可能要在 derivatives.yaml 定義operation的求導(dǎo)操作。

錯(cuò)誤檢測(cè)既能通過(guò)底層API也能通過(guò)高層API來(lái)實(shí)現(xiàn)。底層API如宏(macro):TORCH_CHECK,輸入一個(gè)boolean表達(dá)式,跟著一個(gè)字符串,如果根據(jù)Boolean表達(dá)式判斷結(jié)果為false,這個(gè)宏就會(huì)輸出字符串。這個(gè)宏比較好的地方是你能將字符串和非字符串?dāng)?shù)據(jù)混合起來(lái)輸出,所有的變量都通過(guò)他們實(shí)現(xiàn)的<<操作符格式化,PyTorch中大多數(shù)重要的數(shù)據(jù)類(lèi)型都預(yù)定義了<<操作符。
(譯注:這是C++中字符格式輸出的方式,即通過(guò)重載<<操作符) 高層API能夠幫你避免寫(xiě)重復(fù)的錯(cuò)誤提示。它的工作方式是首先你將每個(gè)Tensor封裝進(jìn)TensorArg中,TensorArg包含這個(gè)Tensor的來(lái)源信息(比如,通過(guò)它的參數(shù)名)。然后它提供了一系列封裝好的函數(shù)來(lái)做各種屬性的檢測(cè);比如,checkDim()用來(lái)檢測(cè)是否tensor的維度是一個(gè)固定的數(shù)。如果它不是,這個(gè)函數(shù)會(huì)基于TensorArg中的元數(shù)據(jù)提供一個(gè)可讀性好的錯(cuò)誤提示。

Pytorch中編寫(xiě)operator的另一件值得注意的事情是,通常對(duì)一個(gè)operator,你需要編寫(xiě)三種版本:abs_out這個(gè)版本把輸出存儲(chǔ)在(out= 這個(gè)關(guān)鍵字參數(shù)中),abs_這個(gè)版本會(huì)就地修改輸入,abs這個(gè)是常規(guī)版本(返回輸出,輸入不變)。 在大多數(shù)情況下,我們實(shí)現(xiàn)的是abs_out版本,然后通過(guò)封裝的方式實(shí)現(xiàn)abs和abs_,但是也有給每個(gè)函數(shù)實(shí)現(xiàn)一個(gè)單獨(dú)版本的時(shí)候。

為了做數(shù)據(jù)類(lèi)型分派(dtype dispatch),你應(yīng)當(dāng)使用AT_DISPATCH_ALL_TYPES宏。這個(gè)宏的輸入?yún)?shù)是Tensor的type,和一個(gè)可以分派各種的type類(lèi)型的lambda表達(dá)式,通常情況下,這個(gè)lambda表達(dá)式會(huì)調(diào)用一個(gè)模板幫助函數(shù)(templated helper function,譯注:也是C++中的概念,C++泛型會(huì)討論到模板函數(shù))。 這個(gè)宏不僅"做分派工作",它也決定了你的kernel將會(huì)支持哪些數(shù)據(jù)類(lèi)型。嚴(yán)格來(lái)說(shuō),這個(gè)宏有幾個(gè)不同的版本,這些版本可以讓你選擇處理哪些特定的dtype子集。大多數(shù)情況下,你會(huì)使用AT_DISPATCH_ALL_TYPES,但是一定要留心當(dāng)你只想要分派到特定類(lèi)型的場(chǎng)景。關(guān)于在特定場(chǎng)景如何選擇宏詳見(jiàn)Dispatch.h

在CPU上, 你經(jīng)常想要并行化你的代碼。在之前,OpenMP 原語(yǔ)(pragmas) 經(jīng)常被用來(lái)做并行化的工作。

在我們需要訪(fǎng)問(wèn)數(shù)據(jù)的時(shí)候,PyTorch提供了不少選擇。
如果你僅僅想拿到存儲(chǔ)在特定位置的數(shù)值,你應(yīng)該使用TensorAccessor。tensor accessor類(lèi)似于tensor,但是它將維度(dimensionality)和數(shù)據(jù)類(lèi)型(dtype)硬編碼(hard codes)成了模板參數(shù)(template parameters 譯注:代碼里的x.accessor
Tensor accessors能夠正確的處理步長(zhǎng)(stride),因此當(dāng)你做些原始指針(raw pointer)訪(fǎng)問(wèn)的時(shí)候你應(yīng)當(dāng)盡量用它們 (不幸的是,一些老舊的代碼并沒(méi)有這樣)。PyTorch里還有一個(gè)PackedTensorAccessor類(lèi),被用來(lái)在CUDA加載過(guò)程中傳輸accessor,因此你能夠在CUDA kernel 內(nèi)訪(fǎng)問(wèn)accessors。(小提示:TensorAccessor默認(rèn)是64-bit索引的,在CUDA中要比32-bit索引要慢很多)
如果你編寫(xiě)的operator需要做一些規(guī)律性的數(shù)據(jù)訪(fǎng)問(wèn),比如,點(diǎn)乘操作,強(qiáng)烈建議你用高層API比如TensorIterator。這個(gè)幫助類(lèi)自動(dòng)幫你處理了廣播(broadcasting)和類(lèi)型提升(type promotion),非常方便。(譯注:廣播和類(lèi)型提升可以參考numpy相關(guān)的描述)
為了在CPU上執(zhí)行得盡量快,也許你需要使用向量化的CPU指令(vectorized CPU instructions)來(lái)編寫(xiě)kernel。我們也提供了工具!Vec256 類(lèi)表示一個(gè)向量,并提供了一系列的方法以對(duì)其向量化的操作(vectorized operations)。幫助函數(shù)比如binary_kernel_vec 讓你更加容易得運(yùn)行向量化的操作,以處理原始的CPU指令不容易處理的向量化的場(chǎng)景。同時(shí),這個(gè)類(lèi)還負(fù)責(zé)針對(duì)不同的指令集編譯不同的kernel,然后在運(yùn)行時(shí)對(duì)你CPU所支持的指令集做測(cè)試,以使用最合適的kernel。
Legacy code

PyTorch 中的許多kernel仍然由古老的TH類(lèi)型的代碼實(shí)現(xiàn)(順便說(shuō)一下,TH代表TorcH。縮寫(xiě)固然很好,但是太常見(jiàn)了,如果你看到了TH,就把它當(dāng)做老舊的就好了)。下面詳細(xì)解釋下什么是老舊的TH類(lèi)型:
它由C代碼編寫(xiě),沒(méi)有(或者極少)用到C++
它是由手動(dòng)引用計(jì)數(shù)的(當(dāng)不再使用某個(gè)tensor的時(shí)候,通過(guò)手工調(diào)用THTensor_free方法來(lái)減少引用計(jì)數(shù))
它存在于 generic/文件夾中,意味著我們需要通過(guò)定義不同的#define scalar_t來(lái)多次編譯。
這些代碼是很"瘋狂"的,我們也不愿意維護(hù)它們,所以請(qǐng)不要再向里面添加?xùn)|西了。你可以做的更有意義的事情是,如果你喜歡編程但是不熟悉關(guān)于kernel的編寫(xiě),你可以嘗試著移植這些TH函數(shù)到ATen里面去。
Workflow efficiency

作為總結(jié),我想要討論一些關(guān)于高效擴(kuò)展PyTorch的技巧。如果說(shuō)龐大的PyTorch C++代碼庫(kù)是第一道阻止很多人貢獻(xiàn)代碼到PyTorch的門(mén)檻,那么工作效率就是第二道門(mén)檻。如果你試著用寫(xiě)Python的習(xí)慣編寫(xiě)C++代碼,你將會(huì)花費(fèi)大量的時(shí)間,因?yàn)橹匦戮幾gPyTorch太耗時(shí)了,你需要無(wú)盡的時(shí)間來(lái)驗(yàn)證你的改動(dòng)是否奏效。 如何高效的改動(dòng)PyTorch可能需要另一場(chǎng)專(zhuān)門(mén)的talk,但是這個(gè)PPT總結(jié)了一些常見(jiàn)的"誤區(qū)":
如果你編輯了一個(gè)頭文件,尤其是那種包含許多源文件(尤其是包含了CUDA文件),那么你可能會(huì)需要一個(gè)非常長(zhǎng)時(shí)間的重新編譯。為了避免這個(gè),盡量保持只修改cpp文件,盡量少修改頭文件!
我們的CI(譯注:應(yīng)該指一個(gè)云端的已配置好的環(huán)境,見(jiàn)鏈接)是一個(gè)非常好的,不需要任何配置的環(huán)境來(lái)測(cè)試你的修改是否會(huì)奏效。但是在你得到結(jié)果之前估計(jì)需要1到2小時(shí)。如果你的修改需要大量的實(shí)驗(yàn)驗(yàn)證,把時(shí)間花在設(shè)置一個(gè)本地開(kāi)發(fā)環(huán)境上吧。同樣,如果你遇到了一個(gè)特別難以debug的問(wèn)題,在本地環(huán)境中測(cè)試它。你可以下載并且使用我們的Docker鏡像 download and run the Docker images locally
如何貢獻(xiàn)的文檔詳述了如何設(shè)置ccache,我們強(qiáng)烈推薦這個(gè),因?yàn)楹芏嗲闆r下它會(huì)在你修改頭文件時(shí)幫助你節(jié)省重新編譯的時(shí)間。它也能幫助你避免一些我們編譯系統(tǒng)的bugs,比如重新編譯了一些不該重新編譯的文件。
我們有大量的C++代碼,推薦你在一個(gè)有著充足CPU和RAM資源的服務(wù)器上編譯。強(qiáng)烈不建議你用自己的筆記本編譯CUDA,編譯CUDA是特特特特別慢的,筆記本不具備快速編譯的能力。
Conclusions
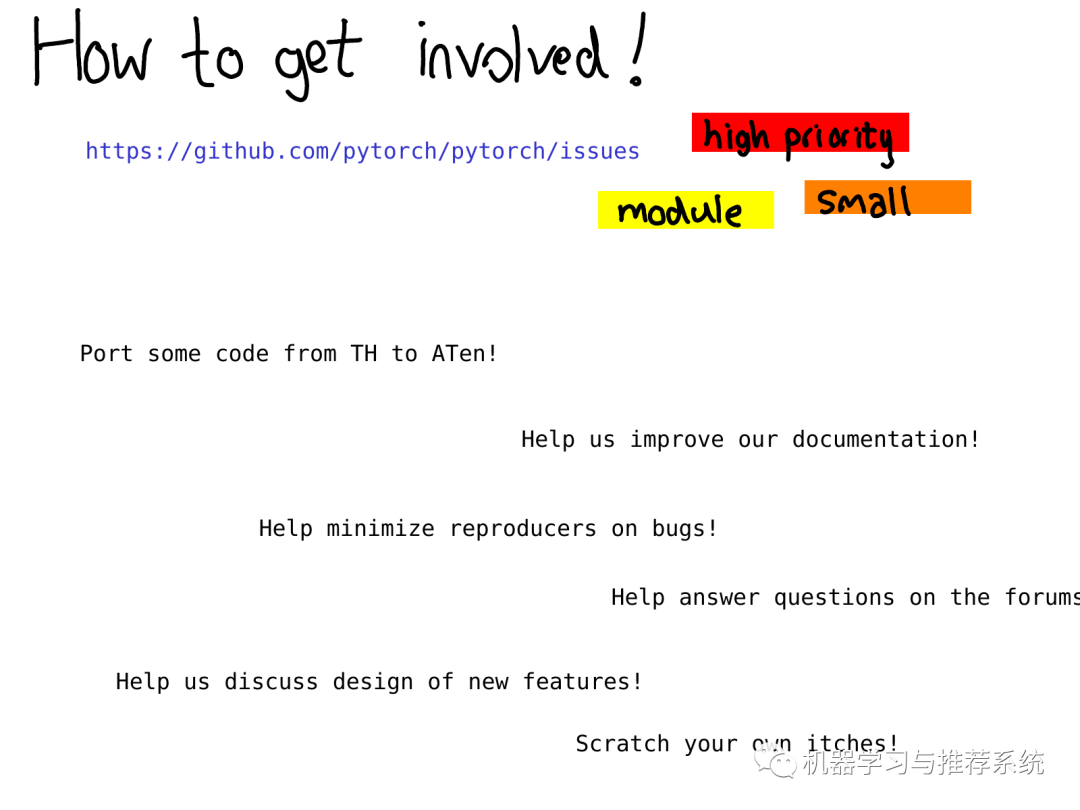
總之這份教程帶你快速掃過(guò)PyTorch內(nèi)部機(jī)制!許多東西沒(méi)有被討論到,但是希望以上的描述和解釋能夠幫助你對(duì)代碼的大體結(jié)構(gòu)有個(gè)初步的了解。 看完這份教程后你需要去哪里獲得更詳細(xì)的資源?你能夠做哪種類(lèi)型的貢獻(xiàn)?一個(gè)比較好的起點(diǎn)是我們的問(wèn)題追蹤器(issue tracker)。在今年早些時(shí)候,我們開(kāi)始對(duì)問(wèn)題進(jìn)行標(biāo)注,一個(gè)標(biāo)注過(guò)的問(wèn)題意味著至少有一個(gè)PyTorch開(kāi)發(fā)者注意到了它并且做了初始的任務(wù)評(píng)估。
通過(guò)這些標(biāo)注你能夠知道我們認(rèn)為哪些問(wèn)題是high priority的,或者你可以查詢(xún)屬于特定模塊的問(wèn)題,例如 autograd ,或者你可以查詢(xún)一些我們認(rèn)為不是那么重要的小問(wèn)題(警告:我們有時(shí)也會(huì)判斷失誤) 即使你不想立刻開(kāi)始編程,也有很多有意義的工作比如改善文檔(我喜歡合并文檔的pull請(qǐng)求,它們實(shí)在是太好了),幫助我們復(fù)現(xiàn)其他用戶(hù)報(bào)告的bug,幫助我們討論問(wèn)題追蹤中的RFCs(request for comment,請(qǐng)求給出詳細(xì)注釋)。
責(zé)任編輯:xj
原文標(biāo)題:一文搞懂 PyTorch 內(nèi)部機(jī)制
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
源碼
+關(guān)注
關(guān)注
8文章
652瀏覽量
29458 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13366
原文標(biāo)題:一文搞懂 PyTorch 內(nèi)部機(jī)制
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
利用Arm Kleidi技術(shù)實(shí)現(xiàn)PyTorch優(yōu)化

PyTorch 2.5.1: Bugs修復(fù)版發(fā)布

PyTorch 數(shù)據(jù)加載與處理方法
如何使用 PyTorch 進(jìn)行強(qiáng)化學(xué)習(xí)
pytorch怎么在pycharm中運(yùn)行
pycharm如何調(diào)用pytorch
pytorch環(huán)境搭建詳細(xì)步驟
pytorch和python的關(guān)系是什么
pytorch如何訓(xùn)練自己的數(shù)據(jù)
PyTorch的介紹與使用案例
tensorflow和pytorch哪個(gè)更簡(jiǎn)單?
tensorflow和pytorch哪個(gè)好
如何使用PyTorch建立網(wǎng)絡(luò)模型
使用PyTorch構(gòu)建神經(jīng)網(wǎng)絡(luò)
PyTorch中激活函數(shù)的全面概覽





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論