 騰訊云虛擬化開源團隊為內核引入全新虛擬文件系統
騰訊云虛擬化開源團隊為內核引入全新虛擬文件系統
Linux內存管理概述
我們知道linux系統內核的主要工作之一是管理系統中安裝的物理內存,系統中內存是以page頁為單位進行分配,每個page頁的大小是4K,如果我們需要申請使用內存則內核的分配流程是這樣的,首先內核會為元數據分配內存存儲空間,然后才分配實際的物理內存頁,再分配對應的虛擬地址空間和更新頁表。
好奇的同學肯定想問,元數據是什么,為什么我申請內存還要分配元數據,元數據有什么用呢?
其實為了管理內存頁的使用情況,內核設計者采用了page structure(頁面結構)的數據結構,也就是我們所說的元數據來跟蹤內存,該數據結構以數組的形式保存在內存中,并且以physical frame number(物理頁框號)為索引來做快速訪問 (見圖1) 。
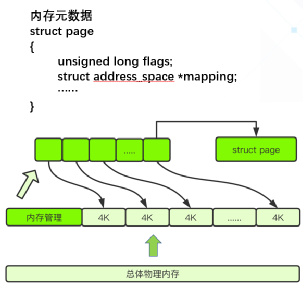
(圖1)
元數據存儲著各種內存信息,比如使用大頁復合頁的信息,slub分配器的信息等等,以便告訴內核該如何使用每個頁面,以及跟蹤頁面在各個映射列表上的位置,或將其連接到后端的存儲等等。所以在內核的內存管理中頁面元數據的重要性不言而喻,目前在64位系統上這個數據結構占用64個字節,而由于通常的頁面大小為4KB,比如一臺安裝了4GB內存的普通電腦上就有1048576個普通頁,這意味著差不多需要64MB大小的內存來存儲內存元數據來用于管理內存普通頁。
似乎看起來并沒有占用很多內存,但是在某些應用場景下面可就不同了哦,現今的云服務中普遍安裝了海量內存來支持各種業務的運行,尤其是AI和機器學習等場景下面,比如圖2中,如果服務器主機有768g的內存,則其中能真正被業務使用的只有753g,有大約10多個g的物理內存就被內存元數據所占用了,假如我們可以精簡這部分內存,再將其回收利用起來,則云服務提供商就可以提供更多的云主機給自己的客戶,從而增加每臺服務器能帶來的收入,降低了總體擁有成本,也就是我們常說的TCO,有那么多好處肯定是要付諸實施咯,但是我們要如何正確并且巧妙地處理這個問題而不影響系統的穩定性呢?
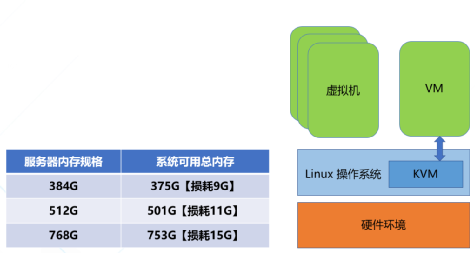
(圖2)
Direct Memory Management File System(直接內存管理文件系統)
有的小伙伴會說好像現有的內核接口就可以解決類似問題呀,比如我可以mmap系統中的/dev/mem,將線性地址描述的物理內存直接映射到進程的地址空間內,不但可以直接訪問這部分內存也繞過了內核繁復的內存管理機制,豈不是很方便。但其實這里有很大的局限性,首先對于/dev/mem的訪問需要root權限的加持,這就增加了內核被攻擊的風險,其次mmap映射出來的是一整塊連續的內存,在使用的過程中如何進行碎片化的管理和回收,都會相應需要用戶態程序增加大量的代碼復雜度和額外的開銷。 為了既能更好地提高內存利用率,又不影響已有的用戶態業務代碼邏輯,騰訊云虛擬化開源團隊獨辟蹊徑,為內核引入了全新的虛擬文件系統 - Direct Memory Management File System(直接內存管理文件系統)(見圖3),該文件系統可以支持頁面離散化映射用來避免內存碎片,同時全新設計了高效的remap (重映射)機制用來處理內存硬件故障(MCE)的情況,并且對KVM、VFIO和內存子系統交互所用到的接口都進行了優化,用來加速虛擬機機EPT頁表和IOMMU頁表的建立,在避免了內存元數據的額外開銷的情況下還增加了虛擬機的性能提升的空間。
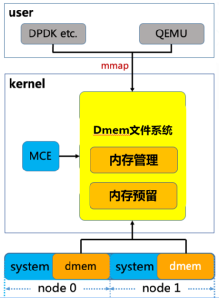
(圖3)
從內存管理上來看,dmemfs在服務器系統啟動引導的時候就將指定數量的內存預先保留在系統中的各個NUMA節點上,這部分內存沒有被系統內存管理機制接管,也就不需要消耗額外的內存來存儲元數據。 我們知道內核的內存信息全部來自e820表, 這部分e820信息只提供了內存的區間描述和類型,無法提供NUMA節點信息, 所以必須在memblock初始化之后, 內核buddy伙伴系統初始化之前做好內存預留 (見圖4), 而這時memblock可能已經有分配出去的空間, 以及BIOS會預留等等原因, 導致同一個節點存在不連續的內存塊,因此dmemfs引入了全新的kernel parameter “dmem=”,并將其指定為early param。 內核在解析完參數之后會將得到的信息全部存放在全局結構體dmem_param,其中包含著我們需要預留的memory的大小和起始地址等,隨后在內核初始化到在ACPI處理和paging_ini()之間,我們插入dmem的預留處理函數memblock_reserve(),將dmem內存從memblock中扣除,形成dmem內存池。而存留在memblock中的系統內存則會被paging_init()構建對應的內存元數據并納入buddy子系統。(見圖4)
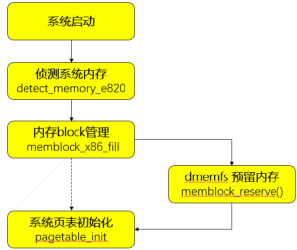
(圖4)
預留下來的內存由稱為dmem_pool的內存池結構體來管理,第一層拓撲為dmem numa node,用來描述dmem在各個numa 節點上的分布情況以實現了numa親和性,第二層拓撲是在dmem numa node的基礎上再實現一個dmem region鏈表,以描述當前節點下每段連續的dmem內存區間(見圖5)。每個region中以page作為分配的最小顆粒度,都關聯到一個local bitmap來維護和管理每個dmem 頁面的狀態,在掛載dmemfs文件系統時為每個 region申請并關聯 bitmap, 并且指定頁面大小的粒度, 比如4K, 2M或1G,從而方便在服務器集群中部署使用
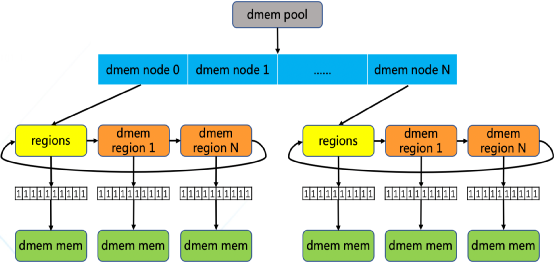
(圖5)
簡單的來說在掛載了dmemfs文件系統之后,就可以使用如下的qemu參數將dmemfs所管理的物理內存傳遞給虛擬機直接使用。
而在虛擬機啟動之后,對內存的讀寫會發生缺頁異常,而內核的缺頁處理機制會將請求發送給dmemfs,dmemfs就會將預留內存按照所需頁面的大小補充到EPT表中從而幫助虛擬機建立好GVA->HPA的映射關系。 為了滿足實際生產環境,dmemfs還必須支持對MCE的處理。MCE, 即Machine Check ERROR, 是一種用來報告系統錯誤的硬件方式。當觸發了MCE時, 在Linux內核流程中會檢查這個物理頁面是否屬于dmem管理, 我們在基于每個連續內存塊的dmem region內引入了一個error_bitmap, 這是以物理頁面為單位的, 來記錄當前系統中發生過mce的頁。同時通過多個手段, 保證分配內存使用的bitmap和這個mce error_bitmap保持同步, 從而后續的分配請求會跳過這些錯誤頁面(見圖6)。 然后在內存管理部分引入一個 mce通知鏈, 通過注冊相應的處理函數, 在觸發mce時可以通知使用者進行相應的處理。 而在dmem文件系統層面, 我們則通過inode鏈表來追蹤文件系統的inode,當文件系統收到通知以后, 會遍歷這個鏈表來判斷并得到錯誤頁面所屬的inode,再遍歷inode關聯的vma紅黑樹, 最終得到使用這些錯誤頁的相關進程進行相應的處理。
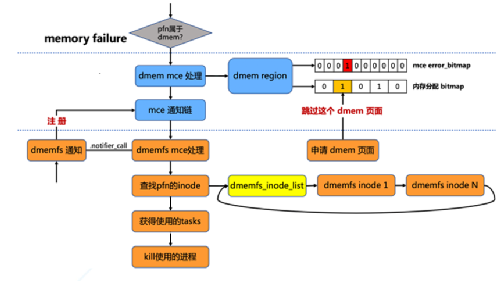
(圖6)
在使用了dmemfs之后,由于消除了冗余的內存元數據結構,內存的額外消耗有了顯著地下降,從圖7的實驗數據中可以看到,內存規格384GB的服務器中, 內存消耗從9GB降到2GB, 消耗降低了77.8%,而內存規格越大, 使用內存全售賣方案對內存資源的消耗占比越小, 從而可以將更多內存回收再利用起來, 降低了服務器平臺成本。
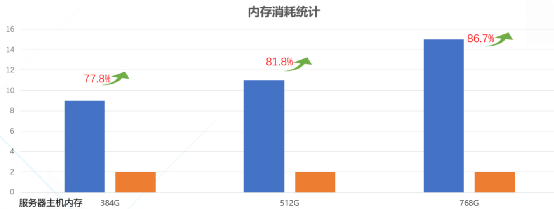
(圖 7)
原文標題:內存管理的另辟蹊徑 - 騰訊云虛擬化開源團隊為內核引入全新虛擬文件系統(dmemfs)
文章出處:【微信公眾號:Linuxer】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
內核
+關注
關注
3文章
1382瀏覽量
40425 -
內存
+關注
關注
8文章
3055瀏覽量
74332 -
騰訊云
+關注
關注
0文章
216瀏覽量
16841
原文標題:內存管理的另辟蹊徑 - 騰訊云虛擬化開源團隊為內核引入全新虛擬文件系統(dmemfs)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
騰訊云內核團隊修復Linux關鍵Bug
Jtti:Linux中虛擬文件系統和容器化的關系
虛擬化數據恢復—UFS2文件系統數據恢復案例
云計算中的虛擬化技術應用
嵌入式學習-飛凌嵌入式ElfBoard ELF 1板卡-應用編程示例控制LED燈之sysfs文件系統
飛凌嵌入式ElfBoard ELF 1板卡-應用編程示例控制LED燈之sysfs文件系統
飛凌嵌入式ElfBoard ELF 1板卡-Linux C接口編程入門之文件I/O
Linux根文件系統的掛載過程
什么是虛擬機?什么是虛擬化?
虛擬機數據恢復—KVM虛擬機被誤刪除的數據恢復案例
linux--sysfs文件系統

服務器數據恢復—KVM虛擬機raw格式磁盤文件數據恢復案例
虛擬機數據恢復—EXT4文件系統下KVM虛擬機數據恢復案例





 工商網監
工商網監
評論