") 解析Transformer中的位置編碼 -- ICLR 2021
解析Transformer中的位置編碼 -- ICLR 2021
引言
Transformer是近年來非常流行的處理序列到序列問題的架構(gòu),其self-attention機制允許了長距離的詞直接聯(lián)系,可以使模型更容易學(xué)習(xí)序列的長距離依賴。由于其優(yōu)良的可并行性以及可觀的表現(xiàn)提升,讓它在NLP領(lǐng)域中大受歡迎,BERT和GPT系列均基于Transformer實現(xiàn)。鑒于Transformer在NLP問題上的優(yōu)異表現(xiàn),也有越來越多人將其引入到了CV領(lǐng)域。
和RNN、CNN等模型不同,對于Transformer來說,位置編碼的加入是必要的,因為單純的self-attention機制無法捕捉輸入的順序,即無法區(qū)分不同位置的詞。為此我們大體有兩個方式:(1)將位置信息融入到輸入中,這構(gòu)成了絕對位置編碼的一般做法;(2)將位置信息融入self-attention結(jié)構(gòu)中,這構(gòu)成了相對位置編碼的一般做法。
本次Fudan DISC實驗室將分享ICLR 2021中關(guān)于Transformer和其位置編碼的3篇論文,介紹研究人員從不同角度和場景下對Transformer和其位置編碼的研究。
文章概覽
重新思考語言預(yù)訓(xùn)練中的位置編碼
Rethinking the Positional Encoding in Language Pre-training
論文地址: https://openreview.net/forum?id=09-528y2Fgf
本文針對BERT提出了一種新的位置編碼方法—Transformer with Untied Positional Encoding(TUPE),它通過兩種方法改進了現(xiàn)有的方法,即解開單詞和位置之間的相關(guān)性,以及解開序列位置上的[CLS]。大量實驗表明,TUPE具有較好的性能。
DEBERTA:帶有解耦注意力的解碼增強BERT
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
論文地址: https://openreview.net/forum?id=XPZIaotutsD
本文提出了兩種改進BERT預(yù)訓(xùn)練的方法:第一種方法是分散注意機制,該機制使用兩個向量分別對每個單詞的內(nèi)容和位置進行編碼來表示每個單詞,并使用分散矩陣計算單詞之間在內(nèi)容和相對位置上的注意力權(quán)重;第二個方法是一個增強的掩碼解碼器,它取代了輸出的Softmax層來預(yù)測用于MLM預(yù)訓(xùn)練的掩碼令牌。使用這兩種技術(shù),新的預(yù)訓(xùn)練語言模型DeBERTa在許多下游NLP任務(wù)上表現(xiàn)都優(yōu)于RoBERTa和BERT。
把圖片當(dāng)作16乘16的詞:用于大規(guī)模圖像識別的Transformer
An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale
論文地址: https://openreview.net/forum?id=YicbFdNTTy
本文提出在視覺任務(wù)中的Transformer—Vision Transformer(ViT)。圖像對卷積神經(jīng)網(wǎng)絡(luò)的依賴不是必要的,并且將純transformer直接應(yīng)用于圖像patch序列可以很好地執(zhí)行圖像分類任務(wù)。本文的實驗表明,當(dāng)對大量數(shù)據(jù)進行預(yù)訓(xùn)練并將其傳輸?shù)街械却笮』蜉^小的圖像識別基準時,與最先進的卷積網(wǎng)絡(luò)相比,ViT可獲得出色的結(jié)果,同時訓(xùn)練所需的計算資源也大大減少。
論文細節(jié)
1

動機
因為 Transformer 在結(jié)構(gòu)上不能識別來自不同位置的 token,一般需要用 positional embedding 來輔助。最簡單的做法就是在 input token embedding 上直接加 positional embedding (NSP loss現(xiàn)在基本不用,所以這里不再考慮 segment embedding)。然后在 Transformer 的 self-attention 里,會把 input 用三個矩陣映射到不同的空間,Q,K,V,接著把 Q 和 K 做點積,過 softmax ,得到 attention 的 weight 。因此,在第一層 Transformer 的 QK 點積 ,我們可以得到:
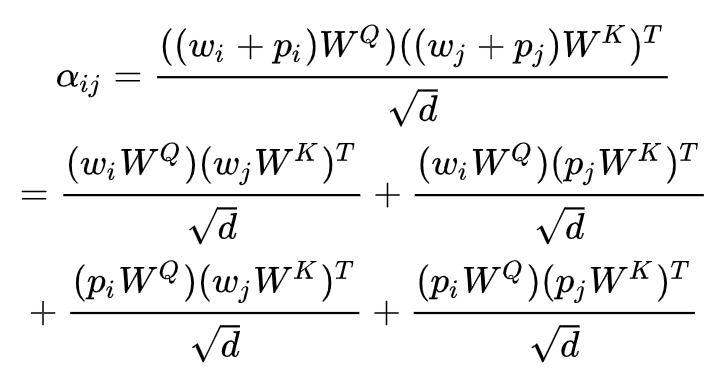
其中 是self attention matrix在進行softmax之前第i行第j列的元素,代表第i個token對第j個token的注意力大小, 是 token embedding,是position embedding,、是映射Q和K所用的矩陣。作者認為代表token和position的交叉的中間兩項沒有給self attention做出貢獻,為了驗證該想法,作者對展開后的四項進行了可視化,如Figure 2所示,可以看到中間兩項看起來很均勻,說明position 和 token 之間確實沒有太強的關(guān)聯(lián)。

同時,作者認為 token 和 position 用了相同的矩陣做 QKV 的變換。但 position 和 token 所包含的信息不一樣,共享矩陣也不合理。
方法
為了解決上述問題,作者將self attention做了如下改動:
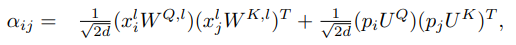
其中,、是把 positional embedding 映射到 Q 和 K 所用的矩陣,分母中的根號 2d 是為了保持量綱。簡單來說,作者去掉了 position 和 token 之間的交叉,同時用了不同的變換矩陣。需要注意的是,在多層的 Transformer 模型里,比如BERT,上面式子的第二項在不同層之間是共享的。因此,這里僅需要算一次,幾乎沒有引入額外的計算代價。
作者還提出,在上述的公式中,可以再添加一個與相對位置相關(guān)的偏置項,即
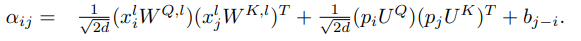
作者在文中使用了T5文章中提出的相對位置編碼。
另外,作者還特殊處理了 [CLS] token 的 position,使其不會因 positional locality 而忽略了整個句子的信息。具體來說,在的第二項,即與位置相關(guān)的注意力計算中,作者將[CLS] 對其他token的注意力以及其他token對[CLS]的注意力額外引入了兩個參數(shù),這兩個參數(shù)與位置信息無關(guān),是一個可學(xué)習(xí)的標量,這樣就完成了和[CLS]相關(guān)注意力的計算。
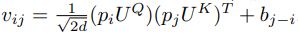
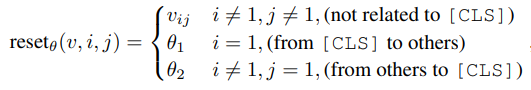
模型整體的架構(gòu)如下
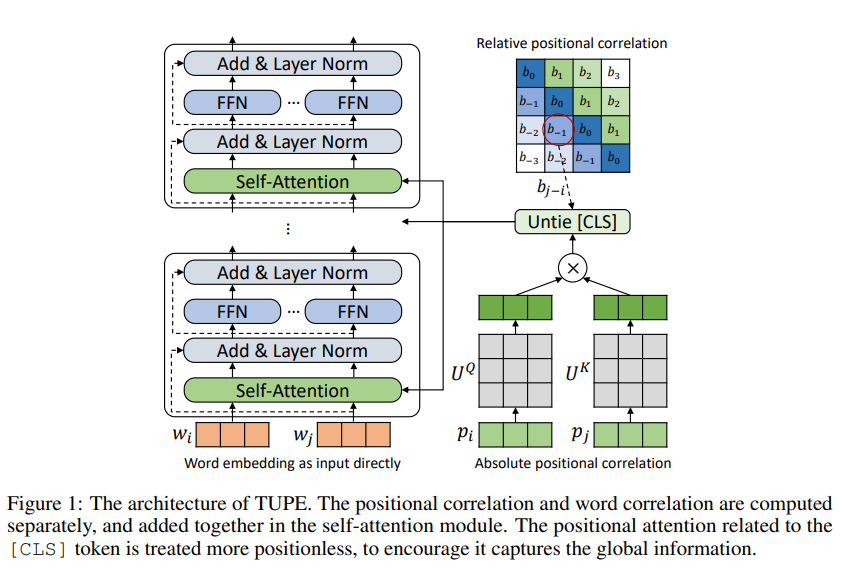
實驗
作者首先使用TUPE模型以類似BERT的方式進行預(yù)訓(xùn)練,然后在GLUE數(shù)據(jù)集下進行微調(diào)。其中-A代表僅使用了絕對位置編碼,-R代表在絕對位置編碼的基礎(chǔ)上增加了相對位置編碼(即偏置項)。mid表示訓(xùn)練了300k步的中間結(jié)果,tie-cls代表移除對[CLS]的特殊處理,d代表為詞和位置使用不同的投影矩陣。
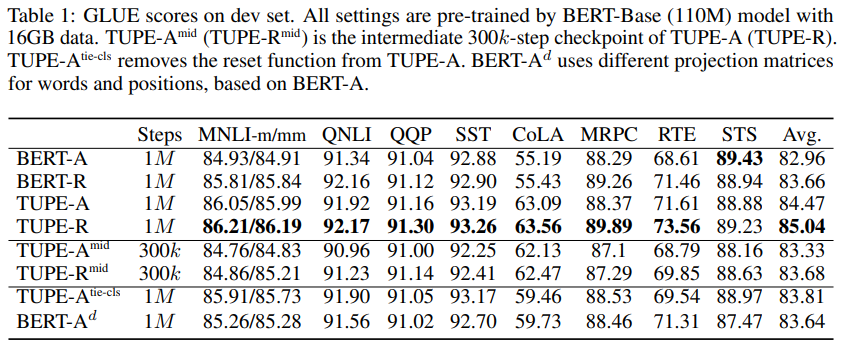
結(jié)果表明,添加相對位置信息對下游任務(wù)效果有一定提升;TUPE模型的效果持續(xù)優(yōu)于BERT模型的效果;TUPE僅訓(xùn)練300k-step(30%)的結(jié)果已經(jīng)可以和BERT等模型的效果相比較;對[CLS] token的特殊處理和使用不同的投影矩陣均可以增加模型性能。
分析
作者最后對TUPE和BERT的預(yù)訓(xùn)練過程進行了分析,結(jié)果表明,TUPE不僅最后比 baseline 要好,并且可以在 30% (300k-step) 的時候,就達到 baseline 在 1000k-step 時的效果。
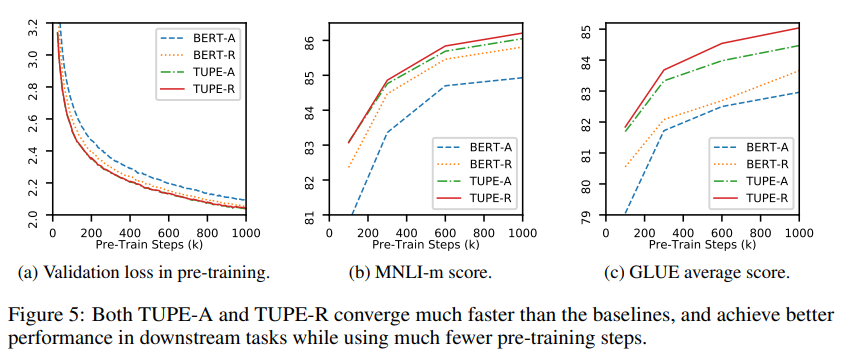
最后作者還對TUPE學(xué)習(xí)到的多個head得到的注意力矩陣進行了可視化,作者發(fā)現(xiàn),不同的head捕捉到了不同的注意力模式,作者還對下圖中的幾種進行了命名,如 attending globally; attending locally; attending broadly; attending to the previous positions; attending to the next positions 等。

2

動機
和上一篇文章類似,文章也是對self attention的結(jié)構(gòu)進行了重構(gòu),與上篇文章不同的是,文章直接從相對位置出發(fā),認為在一個序列中的第i個token可以用兩個向量對其進行表示,分別是 和 ,分別代表了該token的內(nèi)容信息和相對第j個token的相對位置信息。那么第i個token和第j個token的注意力計算可以拆解為如下公式:
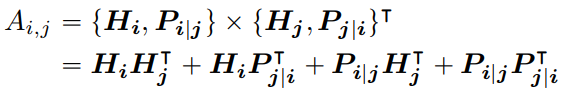
那么注意力可以解耦成四個部分,分別是內(nèi)容和內(nèi)容、內(nèi)容和位置、位置和內(nèi)容、位置與位置。作者認為第四項相對位置和相對位置的交叉無法給注意力提供有效信息,可以舍棄,因此作者提出了解耦注意力機制。
同時,作者認為現(xiàn)有的預(yù)訓(xùn)練、微調(diào)模式存在一些GAP,首先它們的任務(wù)不同,預(yù)訓(xùn)練階段是直接預(yù)測被MASK掉的token,微調(diào)階段是拿句子表示再添加額外的網(wǎng)絡(luò)層去完成下游任務(wù),為了彌補這種GAP,作者提出了解碼增強的BERT。
方法
為了解決上述問題,作者將self attention做了如下改動:
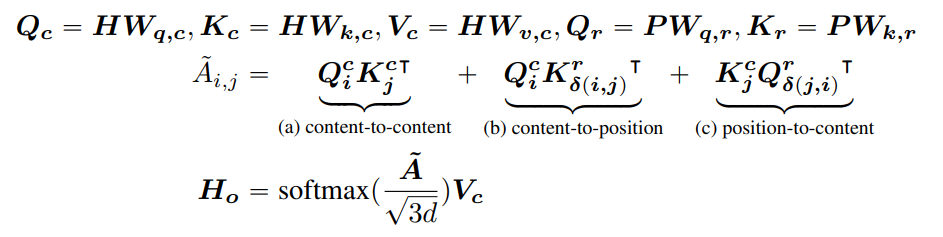
在解耦注意力中,作者拋棄了位置與位置部分,并且認為內(nèi)容和位置的投影矩陣是異質(zhì)的,因此引入了新參數(shù) 和 ,其中 P是跨所有層共享的相對位置嵌入向量。其中 函數(shù)的定義如下:
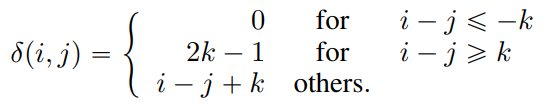
該函數(shù)定義了token之間的相對距離,計算token之間的注意力機制的時候,將通過該公式計算token和token之間的相對距離矩陣,則相對位置向量則可以通過事先定義的embedding層取出。作者還提出了一種計算解耦注意力的高效算法,可以有效地減小空間復(fù)雜度。
上述的注意力計算中中僅包含了相對位置信息,作者認為只有相對位置也不好,最好能把絕對位置信息也加進去,作者給了兩張?zhí)砑拥姆绞健5谝环N方式是在輸入的時候,把絕對位置信息添加到輸入的token embedding中;第二種方式是在最后一兩層再添加到前面那些層輸出的隱向量中。
考慮到BERT等預(yù)訓(xùn)練模型在預(yù)訓(xùn)練和微調(diào)時不一樣,預(yù)訓(xùn)練的時候,bert的輸出經(jīng)過softmax后,直接給出概率。微調(diào)的時候,bert的輸出會經(jīng)過一些與任務(wù)相關(guān)的decoder。作者將掩碼語言模型(MLM)視為任何微調(diào)任務(wù),并添加一個任務(wù)特定解碼器,該解碼器被實現(xiàn)為兩層 Transformer 解碼器和 Softmax 輸出層,用于預(yù)訓(xùn)練。所以作者這里將預(yù)訓(xùn)練和微調(diào)的模型盡可能相近,模型共有13層,前11層稱為encoder,后2層參數(shù)共享,稱為decoder,然后微調(diào)的時候,前12層保留,然后和bert一樣進行各類任務(wù)的微調(diào)。
實驗
作者按照 BERT 的設(shè)置預(yù)訓(xùn)練DeBERTa,和BERT不同的是,作者使用了 BPE 詞匯表。對于訓(xùn)練數(shù)據(jù),作者使用 了 Wikipedia(English Wikipedia dump;12GB)、BookCorpus(6GB)、OPENWEBTEXT(public Reddit content;38GB)和 STORIES(CommonCrawl 的子集;31GB)。重復(fù)數(shù)據(jù)消除后的總數(shù)據(jù)大小約為 78GB。我們使用 6 臺 DGX-2 機器和 96 個 V100 GPU 來訓(xùn)練模型。單個模型訓(xùn)練,batch size 設(shè)置為 2K,1M 的 steps,大約需要 20 天的時間。
作者將預(yù)訓(xùn)練好的模型在GLUE數(shù)據(jù)集上進行微調(diào),表 1 顯示,與 BERT 和 RoBERTa 相比,DeBERTa 在所有任務(wù)中始終表現(xiàn)得更好。同時,DeBERTa 在八項任務(wù)中有六項優(yōu)于 XLNet。特別是,MRPC(1.7% 超過 XLNet,1.6% 超過 RoBERTa)、RTE(2.2% 超過 XLNet,1.5% 超過 RoBERTa)和 CoLA(0.5% 超過 XLNet,1.5% 超過 RoBERTa)的改進非常顯著。
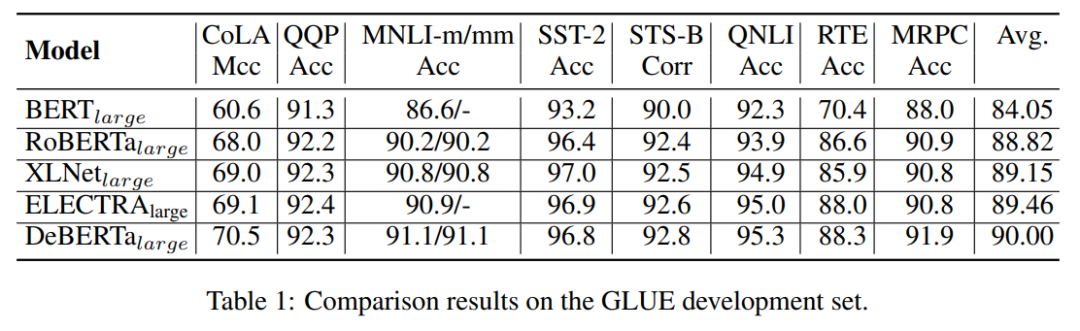
作者還使用了其他數(shù)據(jù)集來評估 DeBERTa,分別是(1)問答:SQuAD v1.1、SQuAD v2.0、RACE、ReCoRD 和 SWAG;(2)自然語言推理:MNLI;(3)NER:CoNLL-2003。為了進行比較,他們還將 Megatron 分為三種不同的模型尺寸:Megatron 336M、Megatron 1.3B 和 Megatron 3.9B,它們使用與 RoBERTa 相同的數(shù)據(jù)集進行訓(xùn)練。與之前的 SOTA 模型(包括 BERT、RoBERTa、XLNet 和 Megatron336M)相比,DeBERTa 在這 7 項任務(wù)中的表現(xiàn)始終更優(yōu)。盡管 Megatron1.3B 是 DeBERTa 的 3 倍大,DeBERTa 在四個基準中的三個方面仍然可以超過 Megatron1.3B。結(jié)果表明,在不同的下游任務(wù)中,DeBERTa 算法都具有較好的性能。
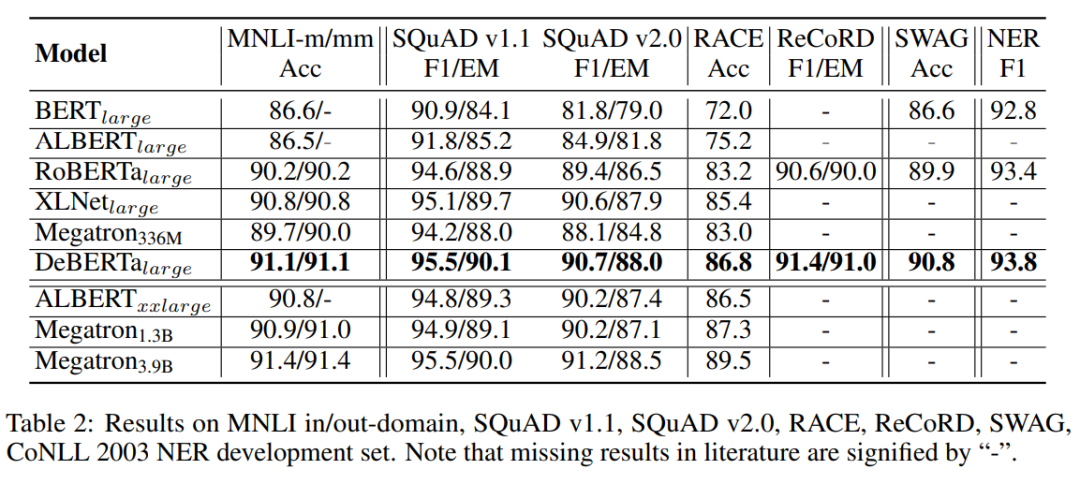
作者還對DeBERTa進行了消融實驗,-EMD 是沒有增強解碼器的DeBERTa模型。C2P 是沒有內(nèi)容-位置項的DeBERTa模型。P2C 是沒有位置-內(nèi)容項的DeBERTa模型。作者發(fā)現(xiàn)刪除 DeBERTa 中的任何一個組件都會導(dǎo)致所有基準測試的性能下降。
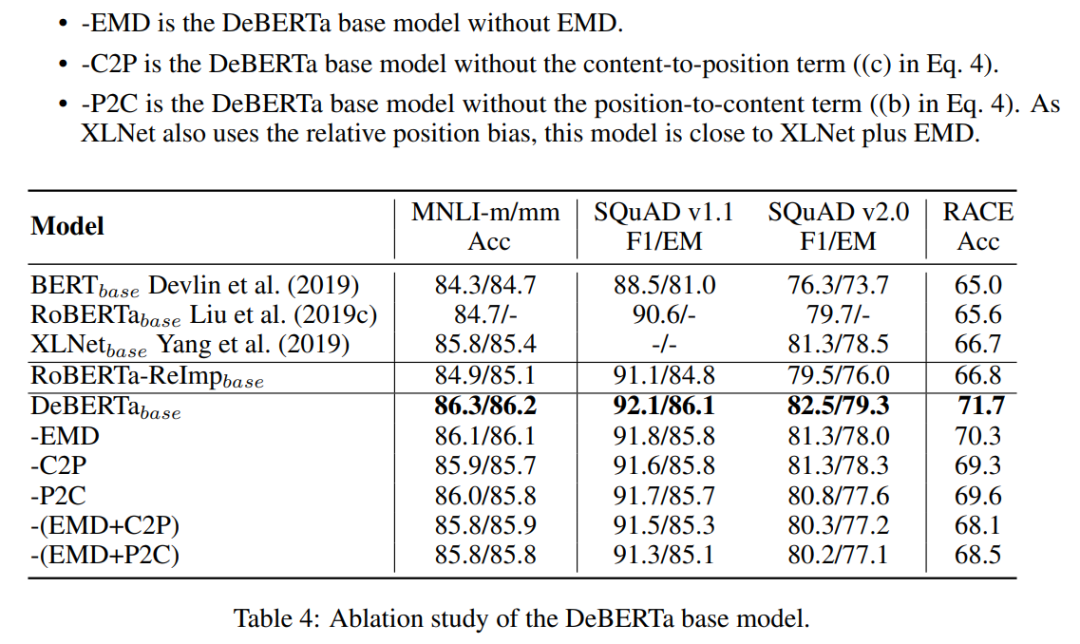
最后作者還研究了注意力機制模式和預(yù)訓(xùn)練模型的有效性。結(jié)果表明,在預(yù)訓(xùn)練的訓(xùn)練過程中,DeBERTa 的表現(xiàn)一直優(yōu)于 RoBERTa-ReImp,并且收斂速度更快。
3

動機
本篇文章跟位置編碼的關(guān)系不是特別大,但文章將Transformer在圖像識別領(lǐng)域中完全代替了卷積神經(jīng)網(wǎng)絡(luò)。近年來,Transformer已經(jīng)成了NLP領(lǐng)域的標準配置,但是CV領(lǐng)域還是CNN(如ResNet, DenseNet等)占據(jù)了絕大多數(shù)的SOTA結(jié)果。最近CV界也有很多文章將transformer遷移到CV領(lǐng)域,雖然已經(jīng)有很多工作用self-attention完全替代CNN,且在理論上效率比較高,但是它們用了特殊的attention機制,無法從硬件層面加速,所以目前CV領(lǐng)域的SOTA結(jié)果還是被CNN架構(gòu)所占據(jù)。文章不同于以往工作的地方,就是盡可能地將NLP領(lǐng)域的transformer不作修改地搬到CV領(lǐng)域來。
方法
NLP處理的語言數(shù)據(jù)是序列化的,而CV中處理的圖像數(shù)據(jù)是三維的(長、寬和channels)。所以需要一個方式將圖像這種三維數(shù)據(jù)轉(zhuǎn)化為序列化的數(shù)據(jù)。文章中,圖像被切割成一個個patch,這些patch按照一定的順序排列,就成了序列化的數(shù)據(jù)。作者首先將圖像分割成一個個patch,然后將每個patch reshape成一個向量,得到所謂的flattened patch。
作者對上述過程得到的flattened patches向量做了Linear Projection,這些經(jīng)過線性映射后的向量被稱為 patch embedding(類似word embedding),一個255乘255像素的圖片,每隔16乘16個像素進行分割,則這些圖片可以被當(dāng)做16乘以16的詞拼在一起。作者也為這些patch添加了位置信息,因為按照特定順序的patch是需要具備位置信息的,作者采取了常見的絕對位置編碼,給每個位置的patch學(xué)習(xí)一個位置編碼向量。
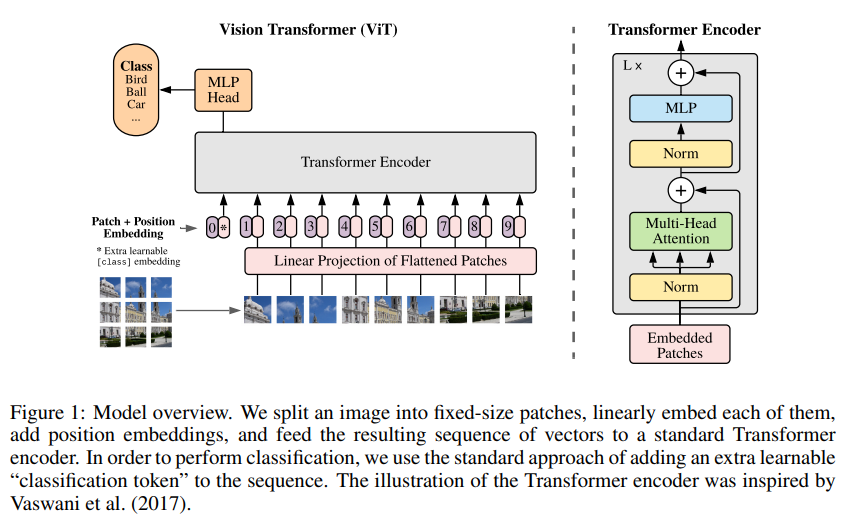
為了給圖像進行分類,作者也借鑒BERT在第一個patch前添加了[CLS] patch,該patch經(jīng)過Transformer后的hidden vector被用于對圖形進行分類的特征。
文中還提出了一個比較有趣的解決方案,將transformer和CNN結(jié)合,即將ResNet的中間層的feature map作為transformer的輸入。和之前所說的將圖片分成patch然后reshape成sequence不同的是,在這種方案中,作者直接將ResNet某一層的feature map reshape成sequence,再通過Linear Projection變?yōu)門ransformer輸入的維度,然后直接輸入進Transformer中。
到下游任務(wù)微調(diào)時,如果圖像的分辨率增大時(即圖像的長和寬增大時),如果保持patch大小不變,得到的patch個數(shù)將增加,即序列長度將增加。但是由于在預(yù)訓(xùn)練的時候,position embedding的個數(shù)和pretrain時分割得到的patch個數(shù)相同。因此超出部分的positioin embedding在模型中是未定義或者無意義的。為了解決這個問題,文章中提出用2D插值的方法,基于原圖中的位置信息,將pretrain中的position embedding插值成更多個,這樣有利于位置編碼在面對更高分辨率圖片微調(diào)時可以更好地收斂。
實驗
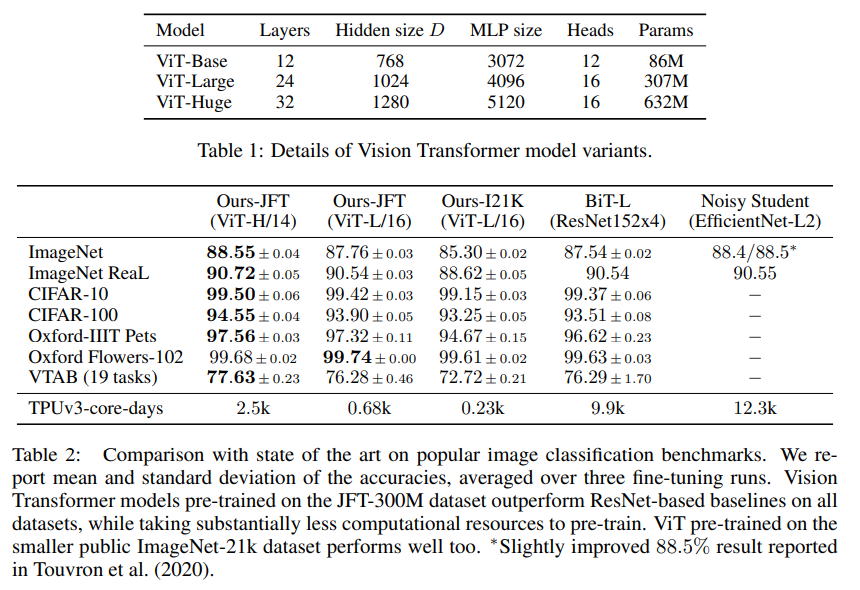
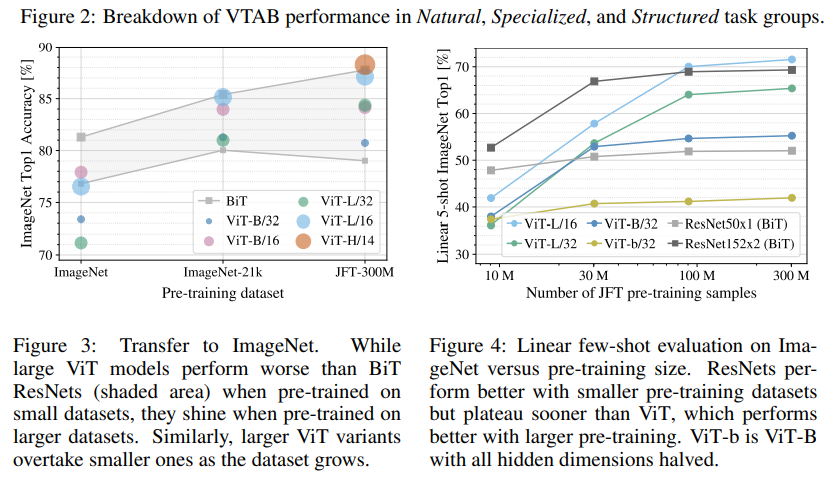
作者使用提出的模型,即VIT,做了大量實驗。實驗的范式遵循預(yù)訓(xùn)練-微調(diào)模型,現(xiàn)在某個數(shù)據(jù)集下使用大量有標簽的圖片進行預(yù)訓(xùn)練,然后再在某個數(shù)據(jù)集下進行微調(diào)。下表中最上面一行指的是預(yù)訓(xùn)練用的數(shù)據(jù)集,最左邊一列指的是微調(diào)使用的數(shù)據(jù)集。ViT-H/14指的是,使用了ViiT-Huge模型的設(shè)置,并且patch的size是14乘14的。Noisy Student是ImageN上的SOTA,BiT是其余任務(wù)上的SOTA。
可以看到,在JFT數(shù)據(jù)集上預(yù)訓(xùn)練的ViT-L/16性能比BiT-L(也是在JFT上進行預(yù)訓(xùn)練)更好。模型更大一點的ViT-H/14性能進一步提升,尤其是在更具挑戰(zhàn)性的任務(wù)上,如ImageNet、CIFAR-100和VTAB,且所需的計算資源依舊遠小于之前SOTA。在I21K上預(yù)訓(xùn)練得到的ViT-L/16性能也非常不錯,需要的計算資源更少,在8TPU上訓(xùn)練30天即可。
作者進一步使用可視化的結(jié)果分析了使用不同預(yù)訓(xùn)練數(shù)據(jù)集和不同復(fù)雜度模型的情況下,下游任務(wù)的表現(xiàn)。作者發(fā)現(xiàn),在預(yù)訓(xùn)練數(shù)據(jù)集比較小的情況下,大模型(ViT-L)性能還是不如小模型(ViT-B);當(dāng)預(yù)訓(xùn)練數(shù)據(jù)集比較大的情況,大模型效果會更好。作者得出的結(jié)論是,在小數(shù)據(jù)集上,卷積的歸納偏置是是非常有用的,但在大數(shù)據(jù)集上,直接學(xué)relevant pattern就夠了,這里的relevant pattern應(yīng)該指的是patch和patch之間的相關(guān)模式。
總結(jié)
此次 Fudan DISC 解讀的三篇論文圍繞Transformer以及位置編碼展開。對于序列來講,位置編碼的影響十分重要,詞和句子的位置信息對語義的影響是巨大的,如何在Transformer模型中有效地融合位置信息是十分重要的。
編輯:jq
-
編碼
+關(guān)注
關(guān)注
6文章
957瀏覽量
54951 -
CV
+關(guān)注
關(guān)注
0文章
53瀏覽量
16906 -
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
367瀏覽量
11914
原文標題:【Transformer】Transformer 中的位置編碼 -- ICLR 2021
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
拉線式絕對值編碼器:精準測量與位置反饋的可靠解決方案

編碼器邏輯功能解析與實現(xiàn)
編碼器七種常見故障解析
編碼器在機器人技術(shù)中的應(yīng)用 編碼器在傳感器系統(tǒng)中的作用
磁編碼器與位置控制系統(tǒng)的結(jié)合應(yīng)用
磁編碼器工作原理解析 磁編碼器與光編碼器的比較
電機控制系統(tǒng)中的編碼器概述與作用
AGV輪轂電機中的編碼器

旋轉(zhuǎn)編碼器在PLC中怎么編程
編碼器在自動化系統(tǒng)中的應(yīng)用
絕對值編碼器的工作原理及其在電機控制中的應(yīng)用

視覺Transformer基本原理及目標檢測應(yīng)用
脈沖編碼器位置未確定如何解除,脈沖編碼器位置怎么調(diào)
編碼器原點設(shè)定方法 | 編碼器原點丟失怎樣找回
編碼器零點位置怎么看 | 編碼器零位怎樣確定






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論