") 如何理解泛化是深度學(xué)習(xí)領(lǐng)域尚未解決的基礎(chǔ)問題
如何理解泛化是深度學(xué)習(xí)領(lǐng)域尚未解決的基礎(chǔ)問題
如何理解泛化是深度學(xué)習(xí)領(lǐng)域尚未解決的基礎(chǔ)問題之一。為什么使用有限訓(xùn)練數(shù)據(jù)集優(yōu)化模型能使模型在預(yù)留測試集上取得良好表現(xiàn)?這一問題距今已有 50 多年的豐富歷史,并在機(jī)器學(xué)習(xí)中得到廣泛研究。如今有許多數(shù)學(xué)工具可以用來幫助研究人員了解某些模型的泛化能力。但遺憾的是,現(xiàn)有的大多數(shù)理論都無法應(yīng)用到現(xiàn)代深度網(wǎng)絡(luò)中,這些理論在現(xiàn)實(shí)環(huán)境中顯得既空泛又不可預(yù)測。而理論和實(shí)踐之間的差距 在過度參數(shù)化模型中尤為巨大,這類模型在理論上能夠擬合訓(xùn)練集,但在實(shí)踐中卻不能做到。
豐富歷史
數(shù)學(xué)工具
過度參數(shù)化
在《Deep Bootstrap 框架:擁有出色的在線學(xué)習(xí)能力即是擁有出色的泛化能力》(The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers)(收錄于 ICLR 2021)這篇論文中,我們提出了一個(gè)解決此問題的新框架,該框架能夠?qū)⒎夯c在線優(yōu)化領(lǐng)域聯(lián)系起來。在通常情況下,模型會(huì)在有限的樣本集上進(jìn)行訓(xùn)練,而這些樣本會(huì)在多個(gè)訓(xùn)練周期中被重復(fù)使用。但就在線優(yōu)化而言,模型可以訪問無限的樣本流,并且可以在處理樣本流的同時(shí)進(jìn)行迭代更新。在這項(xiàng)研究中,我們發(fā)現(xiàn),能使用無限數(shù)據(jù)快速訓(xùn)練的模型,它們在有限數(shù)據(jù)上同樣具有良好的泛化表現(xiàn)。二者之間的這種關(guān)聯(lián)為設(shè)計(jì)實(shí)踐提供了新思路,同時(shí)也為從理論角度理解泛化找到了方向。
《Deep Bootstrap 框架:擁有出色的在線學(xué)習(xí)能力即是擁有出色的泛化能力》
Deep Bootstrap 框架
Deep Bootstrap 框架的主要思路是將訓(xùn)練數(shù)據(jù)有限的現(xiàn)實(shí)情況與數(shù)據(jù)無限的“理想情況”進(jìn)行比較。它們的定義如下:
現(xiàn)實(shí)情況(N、T):使用來自一個(gè)分布的 N 個(gè)訓(xùn)練樣本訓(xùn)練模型;在 T 個(gè)小批量隨機(jī)梯度下降 (SGD) 步驟中,照常在多個(gè)訓(xùn)練周期中重復(fù)使用這 N 個(gè)樣本。這相當(dāng)于針對經(jīng)驗(yàn)損失(訓(xùn)練數(shù)據(jù)的損失)運(yùn)行 SGD 算法,這是監(jiān)督學(xué)習(xí)中的標(biāo)準(zhǔn)訓(xùn)練程序。
理想情況(T):在 T 個(gè)步驟中訓(xùn)練同一個(gè)模型,但在每個(gè) SGD 步驟中使用來自分布的新樣本。也就是說,我們運(yùn)行相同的訓(xùn)練代碼(相同的優(yōu)化器、學(xué)習(xí)速率、批次大小等),但在每個(gè)訓(xùn)練周期中采用全新的訓(xùn)練樣本集,而不是重復(fù)使用相同的樣本。理想情況下,對于一個(gè)幾乎達(dá)到無限的“訓(xùn)練集”而言,其訓(xùn)練誤差和測試誤差之間相差無幾。
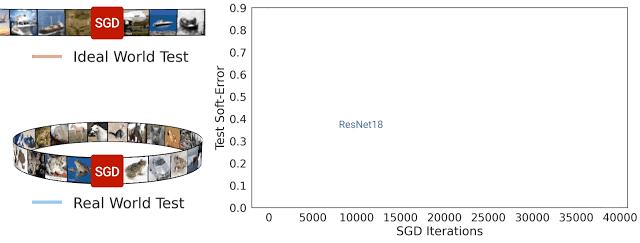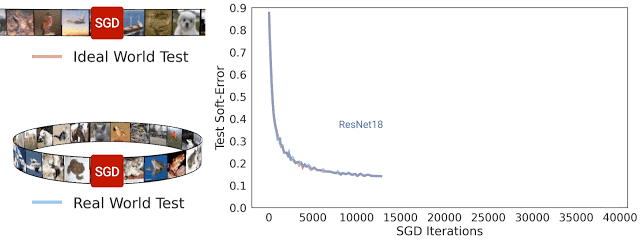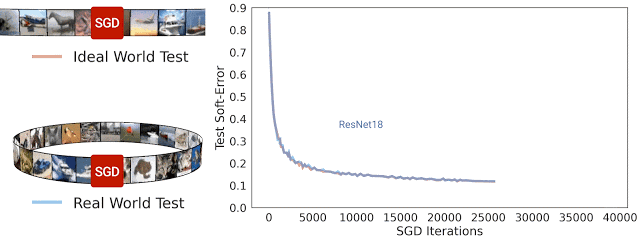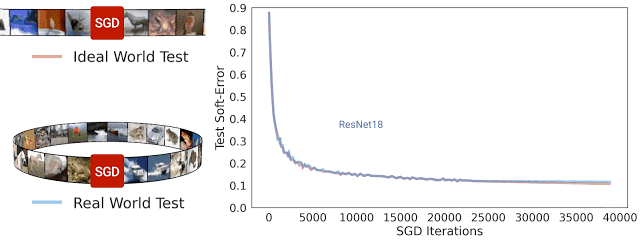
在 SGD 迭代期間 ResNet-18 架構(gòu)理想情況及現(xiàn)實(shí)情況的測試軟誤差。可以看到,兩種誤差非常相近
一般而言,我們認(rèn)為現(xiàn)實(shí)情況和理想情況不會(huì)有任何關(guān)聯(lián),因?yàn)樵诂F(xiàn)實(shí)世界中用于模型處理的來自分布的示例數(shù)量是有限的,而在理想世界中模型處理的示例數(shù)量是無限的。但在實(shí)踐中,我們發(fā)現(xiàn)現(xiàn)實(shí)情況模型和理想情況模型之間的測試誤差非常相近。
為了將此觀察結(jié)果量化,我們通過創(chuàng)建一個(gè)名為 CIFAR-5m 的數(shù)據(jù)集模擬了一種理想情況。我們使用 CIFAR-10 訓(xùn)練了一個(gè)生成模型,然后利用該模型生成約六百萬個(gè)圖像。選擇生成這么多圖像的目的是為了使此數(shù)據(jù)集對于模型而言具有“近乎無限性”,從而避免模型重復(fù)采樣相同的數(shù)據(jù)。也就是說,在理想情況下,模型面對的是一組全新的樣本。
CIFAR-5m
生成模型
下圖給出了幾種模型的測試誤差,對比了它們在現(xiàn)實(shí)情況(如重復(fù)使用數(shù)據(jù))和理想情況(使用“全新”數(shù)據(jù))中使用 CIFAR-5m 數(shù)據(jù)訓(xùn)練的表現(xiàn)。藍(lán)色實(shí)線展示了 ResNet 模型在現(xiàn)實(shí)情況下使用標(biāo)準(zhǔn) CIFAR-10 超參數(shù)針對 50000 個(gè)樣本訓(xùn)練 100 個(gè)周期的表現(xiàn)。藍(lán)色虛線展示了同樣的模型在理想情況下使用五百萬個(gè)樣本一次性訓(xùn)練完畢的表現(xiàn)。出人意料的是,現(xiàn)實(shí)情況和理想情況下的測試誤差非常接近,在某種程度上模型并不會(huì)受到樣本是重復(fù)使用還是全新的影響。
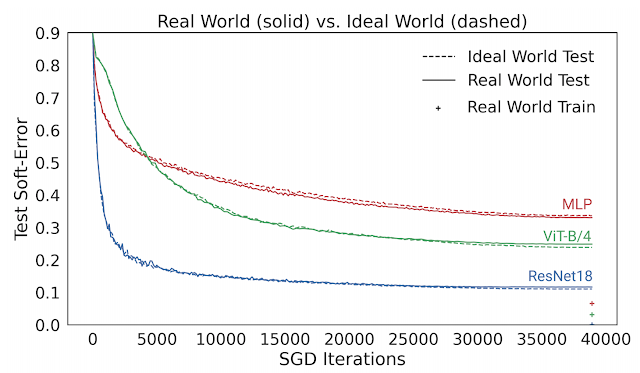
現(xiàn)實(shí)情況下的模型使用 50000 個(gè)樣本訓(xùn)練 100 個(gè)周期,理想情況下的模型使用五百萬個(gè)樣本訓(xùn)練一個(gè)周期。圖中的線展示了測試誤差以及 SGD 步驟的執(zhí)行次數(shù)
這個(gè)結(jié)果也適用于其他架構(gòu),如多層感知架構(gòu)(紅線)、視覺 Transformer(綠線),以及許多其他架構(gòu)、優(yōu)化器、數(shù)據(jù)分布和樣本大小設(shè)置。從這些實(shí)驗(yàn)中,我們得出了一個(gè)關(guān)于泛化的新觀點(diǎn),即能使用無限數(shù)據(jù)快速優(yōu)化的模型,同樣能使用有限數(shù)據(jù)進(jìn)行良好的泛化。例如,ResNet 模型使用有限數(shù)據(jù)進(jìn)行泛化的能力要優(yōu)于 MLP 模型,其原因在于 ResNet 模型使用無限數(shù)據(jù)進(jìn)行優(yōu)化的速度更快。
多層感知
基于優(yōu)化行為理解泛化
我們從中得出一個(gè)重要的觀察結(jié)果,即直到現(xiàn)實(shí)情況開始收斂前,現(xiàn)實(shí)情況和理想情況下的模型在所有時(shí)刻的測試誤差都非常接近(訓(xùn)練誤差 《 1%)。因此,我們可以通過研究模型在理想情況下的行為來理解它們在現(xiàn)實(shí)情況下的表現(xiàn)。
也就是說,模型的泛化可以通過研究其在兩種框架下的優(yōu)化表現(xiàn)來理解:
1. 在線優(yōu)化:其用于在理想情況下觀察測試誤差的減小速度
2. 離線優(yōu)化:其用于在現(xiàn)實(shí)情況下觀察訓(xùn)練誤差的收斂速度
因此,研究泛化時(shí),我們可以相應(yīng)地研究上述兩個(gè)方面,它們僅涉及優(yōu)化問題,因此在概念上較為簡單。通過這項(xiàng)觀察,我們發(fā)現(xiàn)出色的模型和訓(xùn)練程序均符合兩個(gè)條件:(1) 能在理想情況下快速優(yōu)化;(2) 在現(xiàn)實(shí)情況下的優(yōu)化速度較慢。
所有深度學(xué)習(xí)設(shè)計(jì)方案都能通過了解它們在這兩方面的表現(xiàn)來進(jìn)行評估。例如,一些改進(jìn),比如卷積、殘差連接和預(yù)訓(xùn)練等,其主要作用是加速理想情況的優(yōu)化,而另一些改進(jìn),比如正則化和數(shù)據(jù)增強(qiáng)等,其主要作用則是減慢現(xiàn)實(shí)情況的優(yōu)化。
應(yīng)用 Deep Bootstrap 框架
研究人員可以使用 Deep Bootstrap 框架來研究和指導(dǎo)深度學(xué)習(xí)設(shè)計(jì)方案。它所依循的原則是:每當(dāng)我們做出影響現(xiàn)實(shí)情況泛化能力的更改時(shí)(架構(gòu)、學(xué)習(xí)速率等),我們都應(yīng)考慮它對以下兩方面帶來的影響:(1) 理想情況的測試誤差優(yōu)化(越快越好)以及 (2) 現(xiàn)實(shí)情況的訓(xùn)練誤差優(yōu)化(越慢越好)。
例如, 預(yù)訓(xùn)練在實(shí)踐中通常用于促進(jìn)小數(shù)據(jù)體系中的模型泛化。然而,人們對預(yù)訓(xùn)練發(fā)生作用的機(jī)理知之甚少。我們可以使用 Deep Bootstrap 框架,通過觀察預(yù)訓(xùn)練對上述兩方面形成的影響研究這個(gè)問題。我們發(fā)現(xiàn),預(yù)訓(xùn)練的主要作用是促進(jìn)理想情況的優(yōu)化 (1),即使網(wǎng)絡(luò)能夠“快速學(xué)習(xí)”在線優(yōu)化。預(yù)訓(xùn)練模型泛化能力的增強(qiáng)幾乎總能帶來其在理想情況下優(yōu)化能力的提高。下圖比較了使用 CIFAR-10 訓(xùn)練的視覺 Transformers (ViT) 在 ImageNet 上從零開始訓(xùn)練和預(yù)訓(xùn)練之間的差別。
ImageNet
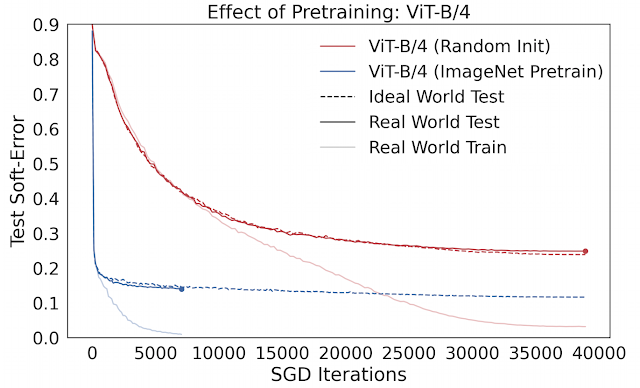
預(yù)訓(xùn)練的作用:經(jīng)過預(yù)訓(xùn)練的 ViT 在理想情況下的優(yōu)化速度更快
我們還可以使用此框架研究數(shù)據(jù)增強(qiáng)。在理想情況下的數(shù)據(jù)增強(qiáng)相當(dāng)于對每個(gè)新樣本進(jìn)行一次增強(qiáng),而不是對同一個(gè)樣本進(jìn)行多次增強(qiáng)。此框架意味著好的數(shù)據(jù)增強(qiáng)均符合兩個(gè)條件:(1) 不會(huì)嚴(yán)重?fù)p害理想情況的優(yōu)化(即增強(qiáng)樣本的分布不會(huì)過于“失范”),(2) 抑制現(xiàn)實(shí)情況的優(yōu)化速度(以使現(xiàn)實(shí)世界花更多時(shí)間擬合其訓(xùn)練集)。
數(shù)據(jù)增強(qiáng)的主要作用通過第二條:延長現(xiàn)實(shí)情況的優(yōu)化時(shí)間來實(shí)現(xiàn)。關(guān)于第一條,一些激進(jìn)的數(shù)據(jù)增強(qiáng) (混合/剪切) 可能會(huì)對理想情況造成不良影響,但這種影響與第二條相比不值一提。
結(jié)語
Deep Bootstrap 框架為理解深度學(xué)習(xí)的泛化和經(jīng)驗(yàn)現(xiàn)象提供了一個(gè)新角度。我們非常期待能夠在未來看到它被用于理解深度學(xué)習(xí)的其他方面。尤為有趣的是,泛化可以通過純粹的優(yōu)化方面的考量來描述, 這在理論上和許多主流方法相悖。至關(guān)重要的是,我們需同時(shí)考慮在線優(yōu)化和離線優(yōu)化,單獨(dú)考慮二者中的任何一個(gè)都是不夠的,它們共同決定了泛化能力。
主流方法
Deep Bootstrap 框架還揭曉了為什么深度學(xué)習(xí)對于許多設(shè)計(jì)方案都異常穩(wěn)健,原因是許多中架構(gòu)、損失函數(shù)、優(yōu)化器、標(biāo)準(zhǔn)化和激活函數(shù)都具有良好的泛化能力。這個(gè)框架揭示了一個(gè)普適定律:基本上任何具有良好在線優(yōu)化表現(xiàn)的設(shè)計(jì)方案,其都能在離線狀態(tài)下有良好的泛化表現(xiàn)。
最后,現(xiàn)代神經(jīng)網(wǎng)絡(luò)既可能過參數(shù)化(如使用小型數(shù)據(jù)任務(wù)訓(xùn)練的大型網(wǎng)絡(luò)),也可能欠參數(shù)化(如 OpenAI GPT-3、Google T5 或 Facebook ResNeXt WSL)。而 Deep Bootstrap 框架表明,在線優(yōu)化是在這兩種模式中取得成功的關(guān)鍵因素。
致謝
感謝我們的合著者 Behnam Neyshabur 對論文的巨大貢獻(xiàn)以及對于博文的寶貴反饋。感謝 Boaz Barak、Chenyang Yuan 和 Chiyuan Zhang 對于博文及論文的有益評論。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5516瀏覽量
121556
原文標(biāo)題:透過新視角理解深度學(xué)習(xí)中的泛化
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
NPU在深度學(xué)習(xí)中的應(yīng)用
深度學(xué)習(xí)模型的魯棒性優(yōu)化
GPU深度學(xué)習(xí)應(yīng)用案例
AI大模型與深度學(xué)習(xí)的關(guān)系
FPGA做深度學(xué)習(xí)能走多遠(yuǎn)?
如何理解機(jī)器學(xué)習(xí)中的訓(xùn)練集、驗(yàn)證集和測試集
深度學(xué)習(xí)模型中的過擬合與正則化
深度學(xué)習(xí)中的時(shí)間序列分類方法
深度學(xué)習(xí)中的無監(jiān)督學(xué)習(xí)方法綜述
深度學(xué)習(xí)在視覺檢測中的應(yīng)用
深度學(xué)習(xí)與nlp的區(qū)別在哪
人工智能深度學(xué)習(xí)的五大模型及其應(yīng)用領(lǐng)域
深度學(xué)習(xí)在計(jì)算機(jī)視覺領(lǐng)域的應(yīng)用
深度解析深度學(xué)習(xí)下的語義SLAM

為什么深度學(xué)習(xí)的效果更好?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論