 當機器人遇見強化學習,會碰出怎樣的火花?
當機器人遇見強化學習,會碰出怎樣的火花?
當機器人遇見強化學習,會碰出怎樣的火花?
一名叫 Cassie 的機器人,給出了生動演繹。
最近,24 歲的中國南昌小伙李鐘毓和其所在團隊,用強化學習教 Cassie 走路 ,目前它已學會蹲伏走路和載重走路等。
相關論文以 《雙足機器人魯棒參數化運動控制的強化學習》(Reinforcement Learning for Robust Parameterized Locomotion Control of Bipedal Robots)為題,已被機器人國際學術頂會 ICRA 收錄。
通過強化學習,它能自己走路,并能進行自我恢復。在現實世界中,通過反復試驗來訓練大型機器人會很危險,為解決這些問題,李鐘毓所在小組使用了兩個不同的仿真環境。
研究中,一個虛擬版本的 Cassie,通過與環境交互產生的大量數據,來學習穩定的步態。
習得的步態控制器,被轉移到名為 SimMechanics 的第二個仿真環境中進行驗證,該環境有更高的準確性,可用以模擬現實世界的物理過程,但是會減慢仿真運行速度。
而通過使用在仿真環境中學習的步態控制器,Cassie 能非常平穩地行走,且無需進行任何額外微調。它不僅能像人類一樣前后左右地走,還能蹲著走,也能承受意料之外的負載,更能從強行推動造成的失穩狀態中恢復過來。
比如,在測試期間,Cassie 損壞了它右腿的兩個電機,但它仍能調整其步行策略、并進行適應。
機器人如何更魯棒?答案是強化學習
Cassie 是李鐘毓所在的 Hybrid Robotics Group 實驗室、從美國 Agility Robotics 公司買來的,它大概有一米多高,內部擁有十個電機,以及二十個自由度。
據他介紹,Cassie 于 2017 年首次開始出售,他從 2019 年開始接觸,目前已經研究兩年有余。
買來后,其主要用于測試和驗證不同算法,如控制算法和導航控制算法等。在李鐘毓這里,Cassie 更像是一個研究平臺。
事實上,足式機器人的核心正是控制算法。研究中,李鐘毓主要使用 Python 進行編程,主體代碼由其所在小組搭建,剩余一部分基于其他學者的開源代碼。
由于是二足機器人,算法控制上會更難。而該研究的創新點在于,用強化學習的方法,得到控制二足機器人步態的算法,相比傳統基于模型的算法,性能可得到顯著提升。
由此帶來的魯棒性也比較強,怎么推它都不會倒,即便在幾乎快要摔倒的情況下,也能快速恢復穩定狀態,這也是業內首次展示出二足機器人如此穩定的性能。
在強化學習之前,傳統基于模型的方法,需要很多時間和技巧給機器人做建模,尤其對于二足機器人而言,一旦其自身性質和周圍環境發生改變,比如電機壞了、地面摩擦力有變化,模型很有可能就會失效。
其次,對于雙足式的機器人系統,其非線性非常高,并且由于是高自由度的混合系統,每一次踏步都會受到地面沖擊力,因此很難獲得精確模型。
而要想做一個實時控制算法,就要使用相對完整的動力學模型。但是,即便具備好的模型,部署在非常高自由度的非線性系統上,也很難做到較快的實時計算。
因此,使用傳統方法時,很多學者都會做出權衡取舍,比如往往用簡化模型來做控制算法。
這樣做出的算法有兩個缺點:一是無法完整利用動力學模型,無法充分發揮機器人系統的靈敏性;二是基于模型的算法,一旦超過其穩定區域,算法就會輕易崩潰。
而強化學習的優點在于,通過相對完整的機器人動力系統,Cassie 在仿真環境反復嘗試后,就能獲得大量和環境交互的數據,從而學會用穩定步態行走。
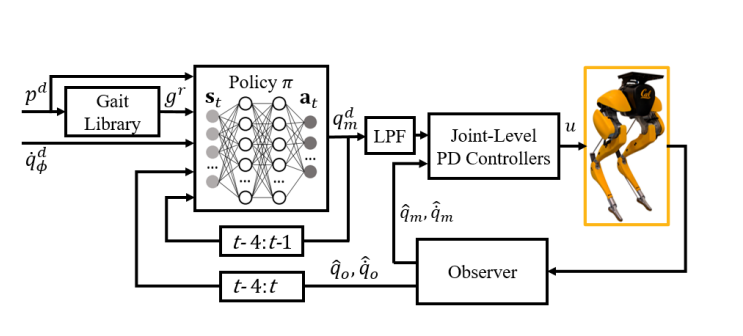
圖 | 本次研究的核心:基于強化學習的步態控制器(來源:受訪者)
如上圖所示,這是本次研究提出的基于學習的步行控制器,控制器的輸入包括所期望的步態參數、期望的轉彎偏航速度、由期望的步態參數解碼的參考步態、一段時間內的觀察到的機器人狀態以及控制器的輸出。
另據悉,控制器可輸出十個電機的期望位置,通過低通濾波器(LPF)后,可被發送到各個關節處的 PD 控制器產生期望的電機力矩。
兩大創新,讓 Cassie 可模仿各種步態
李鐘毓告訴 DeepTech,該研究主要有兩大創新點。
第一個創新點,在于采用了步態庫,里面有各種各樣不同的步行速度和步行高度的步態,比如有 1 米每秒的前進速度、0.3 米每秒的側向行走速度、和 0.7 米的步行高度下的步態。這樣就能在步態庫中各取所需,從而讓機器人模仿不同的參考步態,同時還能追蹤參考步態的速度和步行高度。
通過步態庫,在訓練中使用神經網絡所代表的控制器,就能控制不同的步行速度和步行高度,比如往前或者往后。此外,不同步態之間還可實現來回切換。
此外,步態庫還能提供更多參考動作,Cassie 在仿真學習時,就能見到各種步態,同時還能學會在各種動作下保持平衡。
如下圖所示,Cassie 滑了一跤,幾乎差點摔倒,但在用安全繩把自己拉起來后,它能迅速恢復穩定步態,這個能力是前所未有的,而且李鐘毓也并未就該能力,專門訓練過它。
也就是說,這是 Cassie 通過在訓練中模仿各種步態,并讓自己從不同步態的過渡中“自摸學會”的能力,這在大部分基于模型控制算法的機器人身上很難實現。
試想一下,如果機器人自己倒在地上,沒有人扶它,無論對它自己還是對周圍人都非常危險。
第二個創新點在于,結合了機器人的歷史輸入和輸出,從而實現對 Cassie 和其所在環境的在線系統辨識。
這樣,控制器就能讓 Cassie 適應不同的環境, 比如不同地面的摩擦力。
測試中,Cassie 的兩個電機壞了,但它仍能快速適應系統變化。再比如,把不同重物放在 Cassie 身上,即便拉著后面的安全架,它也能迅速適應這種變化。
據悉,該研究由李鐘毓所在的、由 Prof. Koushil Sreenath 帶領的課題組,和伯克利大學 Prof. Sergey Levine、以及 Prof. Pieter Abbeel 兩個課題組合作。
李鐘毓所在的小組,專注于機器人和控制算法領域,其他兩個小組則是強化學習方面的專家。此外,該工作的成功也離不開團隊成員程旭欣、Xue Bin Peng、Glen Berseth 的共同努力。
可應用于災后搜救和快遞 “最后一公里”
相比其他機器人,Cassie 有更大的運動空間,因為人類社會的環境,主要圍繞人類需求而建造。而二足控制算法,能讓 Cassie 在人類環境中更好地運動比如爬樓梯,這也是輪式機器人無法實現的。
具體應用中,當發生地震時,Cassie 能在塌房中做救援工作;或者在 “最后一公里” 的快遞中,在此之前先用快遞車運送到固定地方,但因為收件人一般在室內,這時 Cassie 就能替代快遞小哥,把快遞當面送給用戶。
此外,Cassie 這類二足機器人,形態上和人類相似,人類也更傾向于和它們做更好的交互,比如可以給其設計富有感情的動作,冷冰冰的機器也能變得更有溫度。
李鐘毓之前的論文 《動畫Cassie:一個可讀的動力學機器人角色》(Animated Cassie:A Dynamic Relatable Robotic Character), 首次用動畫軟件給 Cassie 設計了富有表情的動作,并使用基于模型的軌跡優化的算法,設計出來的動作能讓 Cassie 在現實世界中復現出來,上述論文也入選了 IROS 2020 最佳娛樂應用論文。
據悉,這也是首次在二足機器人上做這種嘗試,Cassie 也因此能用肢體語言表達感情和人交互。
未來,李鐘毓會就 Cassie 的算法技術做以局部開源,相關研究方法已經以論文形式發表,以推動足式機器人的進步。
看好中國機器人發展態勢,博士畢業后或將回國發展
談及研究中難忘的事情,李鐘毓表示,當時仿真訓練做了很久都“顆粒無收”,不過此前也沒有學者能一次就做成功。
仿真訓練模型,非常難以部署到真實世界中。畢竟真實環境和仿真環境的差異非常大。為此,他折騰很久都沒有眉目,導師也勸他再做不出來就要換方向。
但他秉持 “不是有希望才堅持,而是堅持才有希望” 的想法,首次把訓練得到的控制器部署在 Cassie 就取得了成功。
實驗成功后,他激動得給導師發了一條短信,導師知道后也非常振奮。這等于無需進行算法調參,開發好就能直接部署到機器人上。
李鐘毓生于 1996 年,來自江西南昌,本科就讀于浙江大學竺可楨學院,學習機械電子工程,大四時申請到去卡內基梅隆大學(CMU)機器人研究所做科研實習。
在那里,他專門在機器人 Ballbot 的開發,該機器人能在一個球上保持平衡,并能帶領盲人避開障礙物,這也為他后續工作夯實了基礎。
由于表現優秀,本科畢業后,CMU 的導師把其推薦到伯克利大學機械系控制和機器人方向直博。
今年他在讀博二,雖然畢業去向還未明朗,但他認為回國是很好的選擇。因為他認為,中國現在有非常成熟的機器人平臺,兩足機器人也有著很好的發展空間。
原文標題:24歲浙大畢業生研發兩足機器人,已學會蹲伏走路和載重走路,應用于“最后一公里快遞”和災后搜救 | 專訪
文章出處:【微信公眾號:DeepTech深科技】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
機器人
+關注
關注
211文章
28641瀏覽量
208413 -
強化學習
+關注
關注
4文章
268瀏覽量
11301
原文標題:24歲浙大畢業生研發兩足機器人,已學會蹲伏走路和載重走路,應用于“最后一公里快遞”和災后搜救 | 專訪
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】1.全書概覽與第一章學習
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
名單公布!【書籍評測活動NO.51】具身智能機器人系統 | 了解AI的下一個浪潮!
使用機器學習和NVIDIA Jetson邊緣AI和機器人平臺打造機器人導盲犬
如何使用 PyTorch 進行強化學習
“0元購”智元靈犀X1機器人,軟硬件全套圖紙和代碼全公開!資料免費下載!
Al大模型機器人
逐際動力攜手英偉達Isaac平臺, 助力通用機器人研發
通過強化學習策略進行特征選擇






 工商網監
工商網監
評論