") 一文讓你了解知識圖譜多跳問答
一文讓你了解知識圖譜多跳問答
一、簡介
1. 什么是問答?
問答 (Question Answering) 是自然語言處理 (Natural Language Processing) 的一個重要研究領(lǐng)域。在該領(lǐng)域中,研究者們旨在構(gòu)建出這樣一種系統(tǒng):它可以針對人類以「自然語言形式」提出的問題自動地給出答案。
問答這一領(lǐng)域的研究成果已經(jīng)早已普及我們每個人的生活。例如,當(dāng)你清晨起床詢問你的智能語音助手 “今天天氣怎么樣”時,你會得到類似這樣的回答:“今天是晴天,溫度 15-22 攝氏度”。
與傳統(tǒng)的信息檢索以及數(shù)據(jù)庫檢索不同的是,問答這一領(lǐng)域旨在研究那些以「自然語言形式」給出的問題,而非結(jié)構(gòu)化的查詢語言,這更符合日常生活中的應(yīng)用場景。但自然語言的模糊性也為問題的準(zhǔn)確理解帶來了很大困難。
同時,問答的數(shù)據(jù)源可能是多種多樣的。在不同的場景下,結(jié)構(gòu)化的知識圖譜以及無結(jié)構(gòu)的文本均有可能是潛在的數(shù)據(jù)源。因此,針對不同的數(shù)據(jù)源研究相應(yīng)的推理算法也是當(dāng)前問答領(lǐng)域的熱門方向之一。
因此,總結(jié)一下,構(gòu)建一個高質(zhì)量問答系統(tǒng)的關(guān)鍵點在于:
準(zhǔn)確的問題理解技術(shù)
針對不同的數(shù)據(jù)源設(shè)計合適的推理算法
本文將重點針對以「知識圖譜」為主要數(shù)據(jù)源的問答場景(知識圖譜問答)進(jìn)行介紹。首先,我們回顧一下知識圖譜的相關(guān)概念與定義。
2. 什么是知識圖譜 ?
知識圖譜 (Knowledge Graph) 是一種以「多關(guān)系有向圖」形式存儲人類「知識」的數(shù)據(jù)結(jié)構(gòu)。知識圖譜中的每個節(jié)點表示一個實體,兩個節(jié)點之間的有向邊表示它們之間的關(guān)系。例如,《姚明》 是一個實體,《上海》 也是一個實體,它們之間的關(guān)系是 《出生于》。這樣的一個三元組 《姚明,出生于,上海》 表示一個事實 (Fact)。
同樣作為問答的數(shù)據(jù)源,與無結(jié)構(gòu)的文本數(shù)據(jù)相比,結(jié)構(gòu)化的知識圖譜以一種更加清晰、準(zhǔn)確的方式表示人類知識,從而為高質(zhì)量的問答系統(tǒng)的構(gòu)建帶來了前所未有的發(fā)展機(jī)遇。
3. 什么是知識圖譜問答?
知識圖譜問答 (Question Answering over Knowledge Graphs),顧名思義,指的是使用知識圖譜作為主要數(shù)據(jù)源的問答場景。對于給定的問題,我們基于知識圖譜進(jìn)行推理從而得到答案。這一技術(shù)已經(jīng)被業(yè)界廣泛地使用于相關(guān)智能搜索與推薦業(yè)務(wù)中,其中最著名的當(dāng)屬谷歌的搜索引擎業(yè)務(wù)。
例如,對于這樣一個比較簡單的問題 “姚明的出生地是哪里?”,谷歌通過知識圖譜中 《姚明,出生于,上海》 這個三元組得到答案是 《上海》 這一實體。
圖 1:谷歌搜索引擎基于知識圖譜對于簡單問題的回答
對于更加復(fù)雜的一些問題,如 “成龍的父親的出生地是哪里?”,谷歌依然可以通過知識圖譜中的多個三元組 《成龍,父親,房道龍 (Charles Chan)》,《房道龍,出生地,和縣》 得到答案是實體 《和縣》。
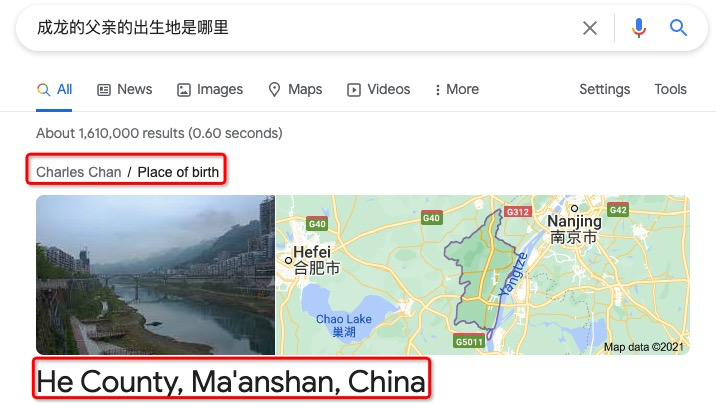
圖 2:谷歌搜索引擎基于知識圖譜對于復(fù)雜問題的回答
接下來,為了更好地介紹知識圖譜問答領(lǐng)域的發(fā)展,我們需要先明確幾個基本概念:
「主題實體」:主題實體指的是出現(xiàn)在問題中的實體。例如,對于問題 “姚明的出生地是哪里?”,我們通過 “姚明” 這一字符串判斷主題實體是 《姚明》 ,它也是后續(xù)推理流程中的推理起點。理論上一個問題中的主題實體不限個數(shù),但在后面介紹的知識圖譜多跳問答領(lǐng)域中,一般假設(shè)一個問題中只存在一個主題實體。
「答案實體」:理論上問題的答案未必是一個實體,例如 ”中國在北京奧運會獲得的金牌有多少枚?“ 的答案是一個數(shù)字。但在后面介紹的知識圖譜多跳問答領(lǐng)域中,一般假設(shè)問題的答案是知識圖譜中的一個實體,即答案實體。
二、知識圖譜問答的發(fā)展簡史
接下來,本文將從兩個維度簡要介紹知識圖譜問答的發(fā)展歷史。
一方面,按照所研究的問題 (Question) 的難易程度,知識圖譜問答領(lǐng)域的發(fā)展可分為兩個階段:早期的 「Simple QA」 以及當(dāng)前主流的 「Complex QA」。
另一方面,按照建模方式的不同,知識圖譜問答領(lǐng)域的工作可分為兩個流派:「語義解析」 (Semantic Parsing) 與 「信息檢索」 (Information Retrieval)。
1. 問題難度:Simple QA & Complex QA
(1)。 Simple QA在知識圖譜問答領(lǐng)域發(fā)展的早期,研究者們主要針對 Simple QA 這種較為簡單的場景開展研究 [1, 2, 3]。Simple QA 研究的是那些「可以使用單個三元組推理出答案」的問題,這些問題也被稱為 Simple Questions 。
例如,對于 “姚明的出生地是哪里?” 這一問題,我們可以通過知識圖譜中的單個三元組 《姚明,出生于,上海》 得到答案是 《上海》 這個實體。
(2)。 Complex QA經(jīng)過一段時間的研究,Simple QA 場景中已經(jīng)發(fā)展出了許多成熟且實用的方法。因此,研究者們轉(zhuǎn)而研究更為復(fù)雜的問題 (Complex Questions)。這些問題更契合實際應(yīng)用中的復(fù)雜場景,而這一研究方向也被稱為 Complex QA [4, 5]。
簡單地說,Complex Questions 是 Simple Questions 的補(bǔ)集,即「無法使用單個三元組」回答的問題。在實際的研究中,研究者們主要關(guān)注以下類型的問題:
「帶約束的問題」:例如:”誰是第一屆溫網(wǎng)男單冠軍?“。該問題中的 “第一屆” 表示一種對答案實體的約束。
「多跳問題」:例如:”成龍主演電影的導(dǎo)演是哪些人?“。該問題需要使用多個三元組所形成的多跳推理路徑才能夠回答。例如:通過這些三元組 《成龍,主演,新警察故事》, 《新警察故事,導(dǎo)演,陳木勝》,我們推理出 《陳木勝》 是一個正確答案。
本文之后將主要結(jié)合多跳問題這一研究場景(知識圖譜多跳問答)進(jìn)行詳細(xì)介紹。
2. 建模方式:Semantic Parsing & Information Retrieval
(1)。 Semantic Parsing語義解析 (Semantic Parsing) 類方法旨在將問題解析為可執(zhí)行的圖數(shù)據(jù)庫「查詢語句」 (如 SPARQL),然后通過執(zhí)行該語句找到答案。
對于 Simple Questions,語義解析類方法旨在將問題解析為一個頭實體 與一個關(guān)系 ,即 (h, r, ?) 的形式。例如,對于 “姚明的出生地是哪里?” 這一問題,可以解析出頭實體 《姚明》 與關(guān)系 《出生地》,并得到偽查詢語句 《姚明,出生地,?》。隨后通過執(zhí)行該查詢語句得到答案 《上海》。
對于 Complex Questions,語義解析類方法將它們解析為一種 查詢圖 (Query Graph) [4]。例如,對于 ”成龍第一部主演的電影的導(dǎo)演是誰?“ 這一復(fù)雜問題,我們可以將其解析為以下查詢圖。
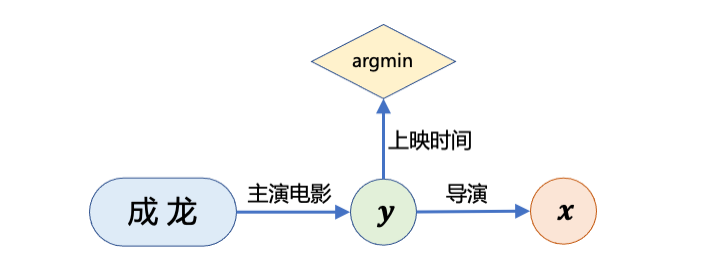
圖 3:語義解析類方法示意圖
當(dāng)我們執(zhí)行這張查詢圖所表示的查詢語句時,我們首先找到成龍主演的所有電影 ,再通過 argmin 這一約束從中篩選出上映時間最早的電影。對于這部篩選出來的電影,我們進(jìn)一步查詢出它的導(dǎo)演是 ,并作為答案返回。
(2)。 Information Retrieval信息檢索 (Information Retrieval) 類方法 [5] 旨在從問題與候選答案中提取出它們的特征,并基于這些特征設(shè)計相應(yīng)的打分函數(shù)以衡量 ”問題-候選答案“ 的語義相關(guān)性,最終得分最高的候選答案被作為預(yù)測答案輸出。下圖給出了信息檢索類模型的處理流程。
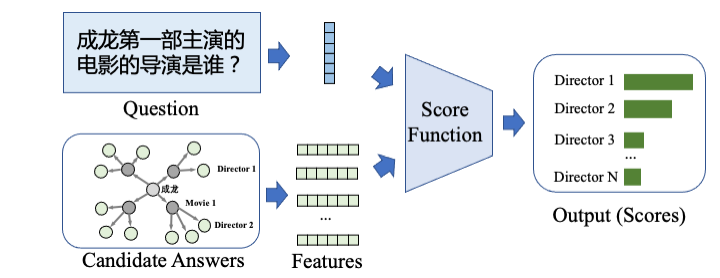
圖 4:信息檢索類方法示意圖
三、知識圖譜多跳問答
本節(jié)將結(jié)合一些重點工作對 「知識圖譜多跳問答」 這一方向進(jìn)行介紹。從問題的難易程度這一視角來看,多跳問答屬于 Complex QA 這一領(lǐng)域;從模型的流派這一視角來看,多跳問答這一方向中的模型的主流是信息檢索這一流派,因此我們接下來也將重點結(jié)合這一流派進(jìn)行介紹。
通俗來說,多跳問題 (Multi-hop Questions) 指的是那些需要知識圖譜 「多跳推理」 才能回答的問題。例如,若要回答 ”成龍主演電影的導(dǎo)演是哪些人?“ 這一問題,則需要多個三元組所形成的多跳推理路徑 《成龍,主演,新警察故事》, 《新警察故事,導(dǎo)演,陳木勝》 才能夠回答。
這種類型的問題在實際應(yīng)用中十分普遍,但想要構(gòu)建出一個高準(zhǔn)確率的知識圖譜多跳問答系統(tǒng)卻并非易事。下圖展示了一個谷歌搜索中的 Bad Case。
我們嘗試在谷歌搜索中輸入以下問題 ”姚明的妻子的父親的出生地是哪里?“。對于該問題,正確的推理路徑為 妻子父親出生地。但是,谷歌卻錯誤地將問題解析成了以下推理路徑 父親妻子出生地。由于姚明的母親(父親的妻子)是方鳳娣 (Fang Fengdi),谷歌將她的出生地作為答案返回。由此可見,知識圖譜多跳問答是一個極具挑戰(zhàn)性的任務(wù)。
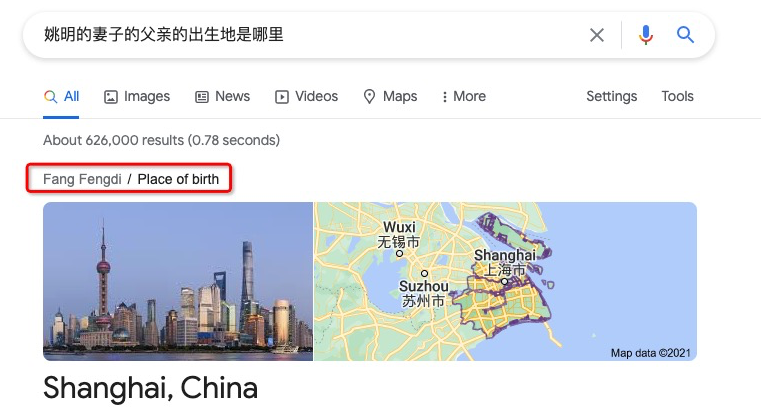
圖 5:谷歌搜索引擎對于復(fù)雜問題的錯誤回答案例
接下來,我們將結(jié)合近年的幾個重要工作對知識圖譜多跳問答這一領(lǐng)域的發(fā)展進(jìn)行介紹。在開篇的簡介中,我們提到高質(zhì)量問答系統(tǒng)的構(gòu)建包含兩個關(guān)鍵點:問題理解與推理算法。知識圖譜多跳問答也不例外。接下來要介紹的幾篇工作也正是圍繞這兩個關(guān)鍵點展開。
(1)。 VRN:端到端的問題理解
知識圖譜問答中,問題理解的首要目標(biāo)就是識別問題中的主題實體 (Topic Entity)。在之前的例子中,如 “姚明的出生地是哪里?”,我們通過 “姚明” 這一字符串判斷主題實體是 《姚明》 ,它也是后續(xù)推理流程中的推理起點。
之前的一些工作 [6] 通過文本匹配的方式來識別主題實體,但在實際應(yīng)用場景中這種方式易受噪聲(自然語言的模糊性和錯別字)影響。在這些情況下,如果我們將知識圖譜問答分為主題實體識別與知識推理這兩個獨立的階段,那么在主題實體識別這一階段產(chǎn)生的錯誤往往會傳遞到知識推理這一階段,從而對最終預(yù)測結(jié)果產(chǎn)生嚴(yán)重的影響。
為了解決這一問題,VRN [5] 提出了一個端到端 (end-to-end) 的框架。它將主題實體識別與知識推理這兩個模塊以端到端的方式融合起來,從而訓(xùn)練過程中的 loss 會直接反饋到主題實體識別模塊,有助于更準(zhǔn)確地在噪聲環(huán)境中識別出正確的主題實體。
為了實現(xiàn) ”端到端“ 這一目標(biāo),VRN 進(jìn)行了以下概率建模。對于給定的問題 ,它的正確答案是實體 的概率表示為 。問題 中的主題實體是實體 的概率表示為 。給定主題實體是 的情況下,問題 的答案是 的概率表示為。從而得到,
其中 表示的是實體識別這一流程, 表示的是知識推理這一流程。本質(zhì)上,VRN 是將主題實體 建模為隱變量,然后以全概率公式的形式表示 。
接下來介紹的三個工作主要圍繞推理算法進(jìn)行研究。更具體地,這些工作主要針對知識圖譜「鏈接缺失」 (incomplete) 這一真實場景下的推理算法進(jìn)行研究。
(2)。 GraftNet: 基于多源數(shù)據(jù)的問答
真實應(yīng)用場景下的知識圖譜往往是存在鏈接缺失問題的,即一部分正確的三元組(事實)沒有被包含進(jìn)知識圖譜中。而這些缺失的三元組可能對于準(zhǔn)確地回答給定的問題至關(guān)重要。
為了解決這一問題,GraftNet [7] 采取了以下措施:
使用無結(jié)構(gòu)的文本數(shù)據(jù)作為結(jié)構(gòu)化的知識圖譜數(shù)據(jù)的補(bǔ)充;
提出了一個圖神經(jīng)網(wǎng)絡(luò)模型 (GNN),它可以在文本與知識圖譜組成的混合類型數(shù)據(jù)上進(jìn)行推理并得到答案。
對于無結(jié)構(gòu)的文本數(shù)據(jù),GraftNet 將每個文檔 (document) 看做一個節(jié)點,并融入知識圖譜結(jié)構(gòu)中:如果該文檔中包含某個實體 ,那么就在這個文檔與實體 之間建立連接。下圖展示了一個直觀的例子。
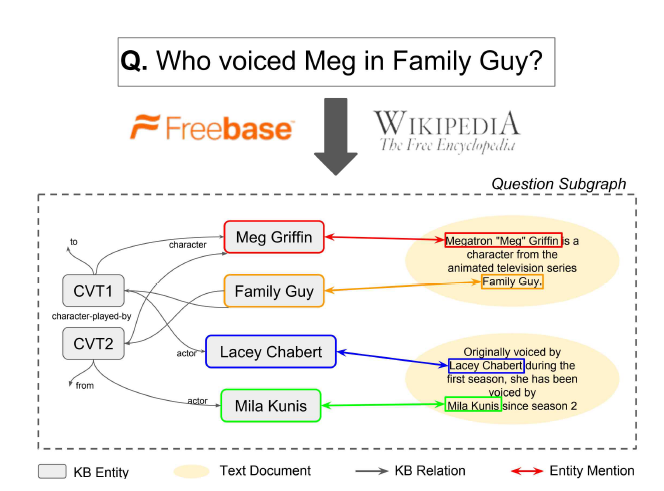
圖 6:GraftNet 多源數(shù)據(jù)融合示意圖 [7]
基于這種由知識圖譜與文檔數(shù)據(jù)組成的圖結(jié)構(gòu),GraftNet 設(shè)計了一個 GNN 用于推理,大致流程如下:
對給定的問題 (假定主題實體 已知),使用 Personalized PageRank (PPR) 算法提取出以 為中心的子圖。最終的候選答案實體便被限定在該子圖中,這個子圖中實體的集合也就是候選答案集合。
使用多層 GNN 迭代更新實體、文檔的表示,使得圖中的每個節(jié)點可以感知到多跳鄰居的信息。最終基于更新后的實體表示計算每個候選實體的得分。詳細(xì)內(nèi)容請見原文 [7]。
至于為什么要裁剪出子圖,這是由于實際應(yīng)用中知識圖譜的實體數(shù)量過于龐大,如果將實體全集作為候選答案實體集,則會大大增加從中尋找正確答案的難度。因此,提前對實體進(jìn)行篩選,只保留一小部分與問題相關(guān)的實體作為候選答案是一個明智的選擇。
(3)。 PullNet: 動態(tài)子圖拓展
雖然 GraftNet 取得了不錯的效果,但該方法依然存在著一些問題。例如,GraftNet 為了減小候選答案實體集合的大小,使用 PPR 算法提取出以主題實體為中心的子圖。但這些子圖往往過大,而且有時并沒有將正確答案囊括進(jìn)來 [8]。
為了解決這一問題,PullNet [8] 提出了一種動態(tài)的子圖拓展方法。具體地,該算法將子圖初始化為主題實體 ,隨后迭代地將與問題相關(guān)程度高的鄰居實體拓展進(jìn)子圖,并同時使用 GNN 更新子圖中節(jié)點的表示。
圖7展示了 PullNet 相比 GraftNet 在子圖提取上的優(yōu)勢,其中x-軸表示提取出的子圖大小(子圖中的實體數(shù)量),y-軸表示正確答案實體的召回率,即正確答案被包含在子圖中的百分比,PageRank-Nibble 表示 GraftNet 所使用的子圖提取方法。以左圖 MetaQA (3-hop) 數(shù)據(jù)集為例,GraftNet 如果想要達(dá)到 0.9 左右的召回率,則需要將子圖中的實體數(shù)量增大至 500 左右,而 PullNet 只需要動態(tài)地拓展出實體數(shù)量大小為 65 左右的子圖,便可以輕松達(dá)到 0.983 的召回率。
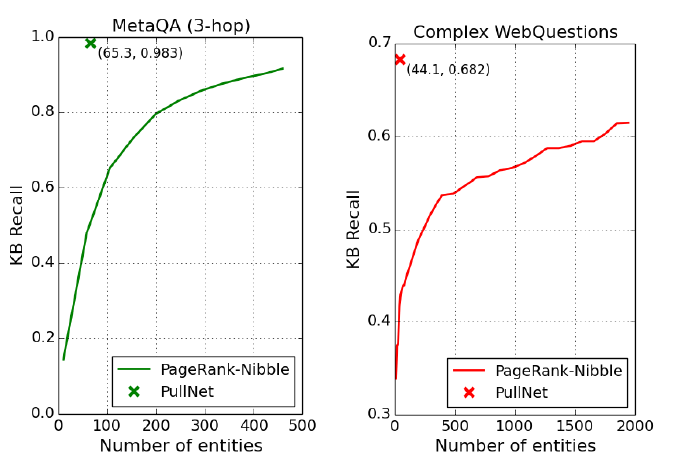
圖 7:正確答案實體召回率 (y-軸) 與子圖大小 (x-軸)關(guān)系示意圖 [8]
(4)。 EmbedKGQA: 基于鏈接預(yù)測思路的問答方法
與 GraftNet 以及 PullNet 使用 GNN 進(jìn)行推理思路不同的是,EmbedKGQA [9] 借鑒了知識圖譜鏈接預(yù)測 (Link Prediction) 的思路以實現(xiàn)在鏈接缺失的知識圖譜上的推理。
知識圖譜鏈接預(yù)測指的是給定一個三元組中的頭實體(或尾實體)與關(guān)系,對尾實體(或頭實體)進(jìn)行預(yù)測的任務(wù),即 (h, r, ?) 或 (?, r, t)。給定一個問題 ,EmbedKGQA [9] 將該問題中的主題實體 看做頭實體,將問題 看做一個關(guān)系,要預(yù)測的尾實體則是該問題的答案。也就是說,EmbedKGQA 將多跳問答建模成 。
這樣的思路雖然簡單,但也行之有效。總的來說,在知識圖譜鏈接缺失的場景下,GraftNet 與 PullNet 從數(shù)據(jù)的角度出發(fā),采取了使用文本數(shù)據(jù) ”補(bǔ)全“ 知識圖譜的思路,同時針對這種混合類型數(shù)據(jù)設(shè)計專門的推理算法。EmbedKGQA 則是從模型的角度出發(fā),直接借鑒了鏈接預(yù)測這種比較成熟的建模思路。
四、總結(jié)
構(gòu)建高質(zhì)量問答系統(tǒng)的關(guān)鍵在于「準(zhǔn)確的問題理解」與「針對相應(yīng)的數(shù)據(jù)源設(shè)計合適的推理算法」。從問題理解的角度,知識圖多跳問答近期工作主要關(guān)注于如何準(zhǔn)確地識別問題中的實體。從推理算法的角度,近期的工作主要關(guān)注:1) 如何降低候選實體集合大小,同時減小對正確答案召回率的影響;2): 如何在鏈接缺失的知識圖譜上進(jìn)行推理。
Reference
[1] Berant, Jonathan et al. “Semantic Parsing on Freebase from Question-Answer Pairs.” EMNLP (2013)。
[2] Yih, Wen-tau et al. “Semantic Parsing for Single-Relation Question Answering.” ACL (2014)。
[3] Bordes, Antoine et al. “Large-scale Simple Question Answering with Memory Networks.” ArXiv abs/1506.02075 (2015)
[4] Yih, Wen-tau et al. “Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base.” ACL (2015)。
[5] Zhang, Yuyu et al. “Variational Reasoning for Question Answering with Knowledge Graph.” AAAI (2018)。
[6] Miller, Alexander H. et al. “Key-Value Memory Networks for Directly Reading Documents.” EMNLP (2016)。
[7] Sun, Haitian et al. “Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text.” EMNLP (2018)。
[8] Sun, Haitian et al. “PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text.” EMNLP (2019)。
[9] Saxena, Apoorv et al. “Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings.” ACL (2020)。
作者簡介:蔡健宇,2019年畢業(yè)于東南大學(xué),獲得工學(xué)學(xué)士學(xué)位。現(xiàn)于中國科學(xué)技術(shù)大學(xué)電子工程與信息科學(xué)系的 MIRA Lab 實驗室攻讀研究生,師從王杰教授。研究興趣包括知識表示與知識推理。
編輯:jq
-
谷歌
+關(guān)注
關(guān)注
27文章
6196瀏覽量
106020 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13401 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7742
原文標(biāo)題:一文帶你入門知識圖譜多跳問答
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于華為云 Flexus 云服務(wù)器 X 搭建部署——AI 知識庫問答系統(tǒng)(使用 1panel 面板安裝)

利智方:驅(qū)動企業(yè)知識管理與AI創(chuàng)新加速的平臺
傳音旗下人工智能項目榮獲2024年“上海產(chǎn)學(xué)研合作優(yōu)秀項目獎”一等獎

傳音旗下小語種AI技術(shù)榮獲2024年“上海產(chǎn)學(xué)研合作優(yōu)秀項目獎”一等獎

三星自主研發(fā)知識圖譜技術(shù),強(qiáng)化Galaxy AI用戶體驗與數(shù)據(jù)安全
總有一個是你會遇到的S參數(shù)問題的問答

一文讓你了解PCB六層板布局
三星電子將收購英國知識圖譜技術(shù)初創(chuàng)企業(yè)
知識圖譜與大模型之間的關(guān)系
訊飛星火大模型V3.5春季升級,多領(lǐng)域知識問答超越GPT-4 Turbo?
信雅達(dá)大模型智能問答產(chǎn)品發(fā)布 運營知識助手“小雅”上線
利用知識圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動的RAG系統(tǒng)(下)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論