") 超詳細EMNLP2020 因果推斷
超詳細EMNLP2020 因果推斷
引言
X,Y之間的因果性被定義為操作X,會使得Y發(fā)生改變。在很多領(lǐng)域如藥物效果預(yù)測、推薦算法有效性,因果性都有著重要作用。然而現(xiàn)實數(shù)據(jù)中,變量之間還會存在其他的相關(guān)關(guān)系(confounding)。如何從觀察獲得的數(shù)據(jù)中發(fā)現(xiàn)不同因素之間的因果關(guān)系則是統(tǒng)計學(xué)、機器學(xué)習(xí)和人工智能領(lǐng)域具有挑戰(zhàn)性的重要研究問題---統(tǒng)計推斷。
本次Fudan DISC實驗室將分享EMNLP 2020中有關(guān)因果推斷的3篇論文,介紹在不同任務(wù)下因果推斷方法的應(yīng)用。
文章概覽
基于因果推理的邏輯相關(guān)多任務(wù)學(xué)習(xí)研究
Exploring Logically Dependent Multi-task Learning with Causal Inference
論文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.173
該篇文章從因果推理的角度出發(fā),使用mediation assumption對邏輯依賴的MTL進行了研究。具體模型使用label transfer利用之前的低級邏輯依賴的任務(wù)label,以及Gumbel sampling方法來處理級聯(lián)錯誤。
腳本知識的因果推理
Causal Inference of Script Knowledge
論文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.612
該篇文章從概念和實踐的角度論證了純粹基于相關(guān)性的方法對于腳本知識歸納是不夠的,并提出了一種基于事件干預(yù)評估因果效應(yīng)的腳本歸納方法。
使用因果關(guān)系消除偏見的法院意見生成
De-Biased Court’s View Generation with Causality
論文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.56
本文提出了一種新的基于注意力和反事實的自然語言生成方法(AC-NLG),該方法由一個注意力編碼器和一對反事實譯碼器組成。注意力編碼器利用原告的索賠和事實描述來學(xué)習(xí)索賠感知的編碼表示。反事實譯碼器被用來消除數(shù)據(jù)中的混淆偏差,并與協(xié)同的判決預(yù)測模型結(jié)合來生成法院意見。
論文細節(jié)
1

論文動機
以往的研究表明,分層多任務(wù)學(xué)習(xí)(MTL)可以通過堆疊編碼器和輸出形式的民主MTL來利用任務(wù)依賴性。然而,在邏輯相關(guān)的任務(wù)中,堆疊編碼器只考慮特征表示的依賴性,而忽略了標(biāo)簽的依賴性。MLT的三種結(jié)構(gòu)如下圖所示
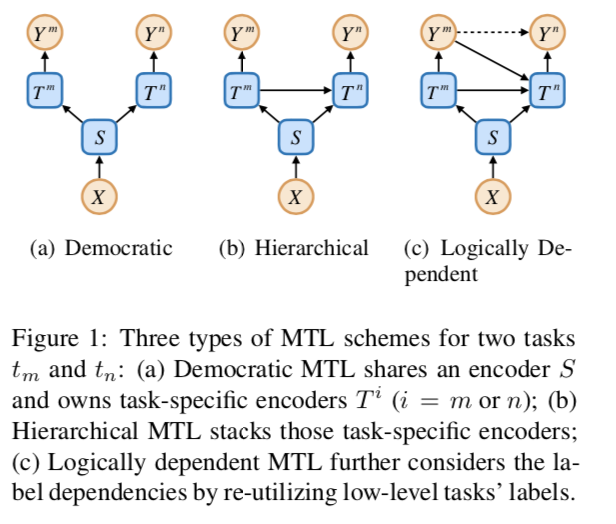
從因果關(guān)系的角度來看,前兩個方案假設(shè)ym和yn是條件獨立的,而第三個方案假設(shè)ym對yn有因果關(guān)系。在這篇文章中,作者認為因果關(guān)系對于邏輯相關(guān)的任務(wù)是重要的,并提出了一種稱為標(biāo)簽轉(zhuǎn)移(label transfer,LT)的機制,使得一個任務(wù)可以利用其所有較低級別任務(wù)的標(biāo)簽。
當(dāng)使用前任務(wù)的標(biāo)簽時,會引入訓(xùn)練和測試的分歧問題。也就是說該策略在訓(xùn)練中使用低水平任務(wù)的標(biāo)注標(biāo)簽,在測試中則需要使用預(yù)測的標(biāo)簽,這樣會導(dǎo)致任務(wù)之間的級聯(lián)錯誤。本文使用Gumbel抽樣(GS)來解決這個問題。具體來說,模型從每個任務(wù)的預(yù)測概率分布中抽取一個標(biāo)簽,并將其提供給更高級別的任務(wù)。抽樣可以看作是一個反事實推理過程,可以估計不同任務(wù)標(biāo)簽之間的因果關(guān)系。如果因果效應(yīng)存在,反向傳播的梯度將懲罰錯誤的預(yù)測。
方法
1. Basic Causal Assumptions
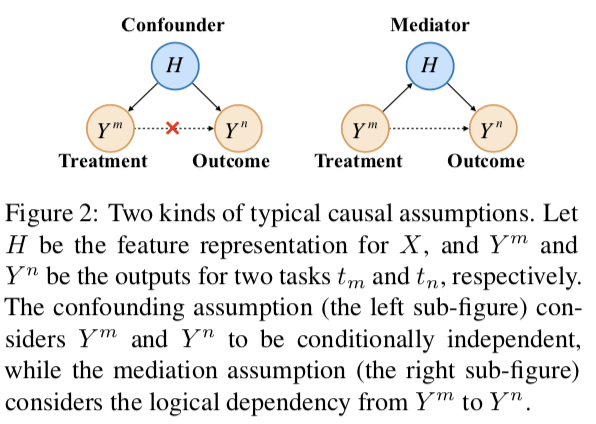
如上圖MTL有兩種可能的因果假設(shè):confounding 和 mediation。confounding假設(shè)是,Ym和Yn是條件獨立的,僅由H決定。然而,對于邏輯相關(guān)的任務(wù),文章使用mediation假設(shè),即Ym對Yn有因果關(guān)系。具體來說,此假設(shè)包括Ym和Yn之間的兩條因果路徑。通過媒體H(實線),稱為間接效應(yīng)。另一個直接鏈接Ym到Y(jié)n(虛線),稱為直接效果。一條是通過metiator H(實線)把Ym和Yn聯(lián)系起來的,稱為間接效應(yīng)。另一個直接連接Ym到Y(jié)n(虛線),稱為直接效應(yīng)。
2. Full Causal Graphs
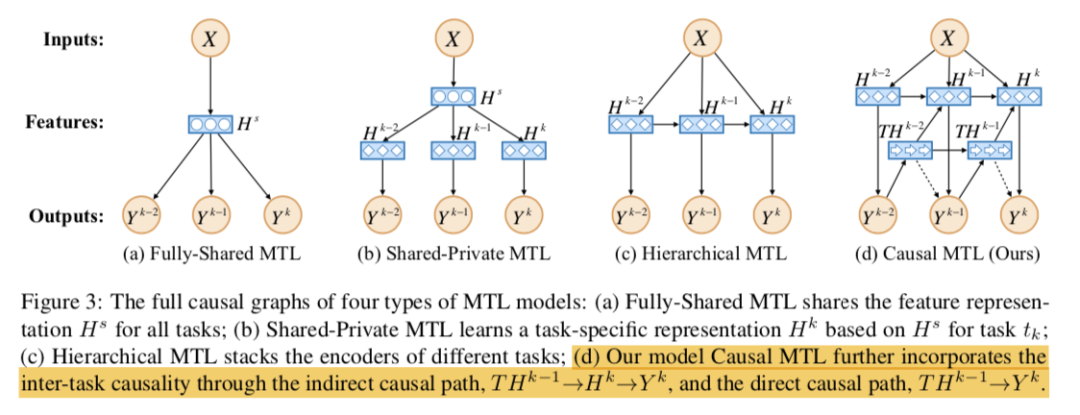
CMTL通過兩條路徑將任務(wù)間因果性結(jié)合起來。它首先創(chuàng)建一個中間變量傳達之前所有任務(wù)的標(biāo)簽信息。然后該模型考慮了路徑→→的間接因果效應(yīng),還包括路徑→的直接因果效應(yīng)。
3. Model Details
完整模型結(jié)構(gòu)下圖所示。
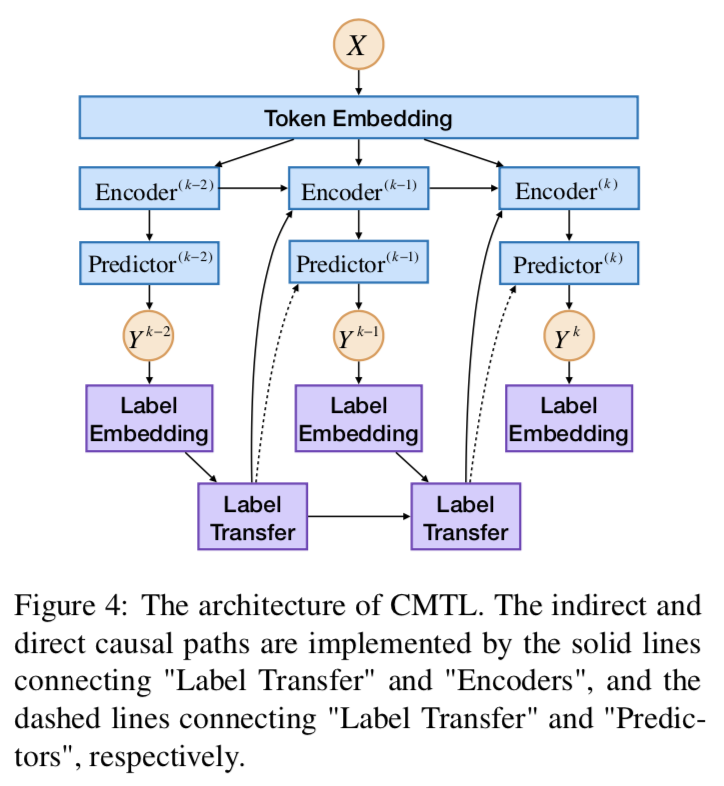
Label Transfer LT使用RNN-LSTM的結(jié)構(gòu)來編碼:
**Encoders ** 然后將被送入編碼器。如圖所示,Encoder^(k) 的輸入包括三個部分:詞嵌入、轉(zhuǎn)移標(biāo)簽和k-1層的輸出。輸出可表示為:
¥4f對于JERE和ABSA任務(wù)編碼器使用Bi-LSTM。對于LJP任務(wù),先使用CNN編碼句子,隨后使用LSTM編碼標(biāo)簽嵌入。
Gumbel Sampling GS使用重參數(shù)技巧來估計多項抽樣:
其中g(shù)符合Gumbel(0,1),是溫度參數(shù)。在訓(xùn)練過程中將使用來代替標(biāo)注標(biāo)簽。這樣低水平的任務(wù)將有一定的概率抽樣一個反事實的值,如果因果關(guān)系確實存在,會從高水平的任務(wù)得到反饋。
4. 因果解釋
估計任務(wù)tm的標(biāo)簽對任務(wù)tn的標(biāo)簽的因果效應(yīng):
除了估計標(biāo)簽的因果效應(yīng)外,還可以檢驗X中n-grams元素的影響。對原始序列進行干預(yù),得到另一個文本序列,其中n-gram 被屏蔽。由于n-gram可能非常稀疏,因此僅對單個因果效應(yīng)進行了估計:
實驗結(jié)果
1. 主要結(jié)果
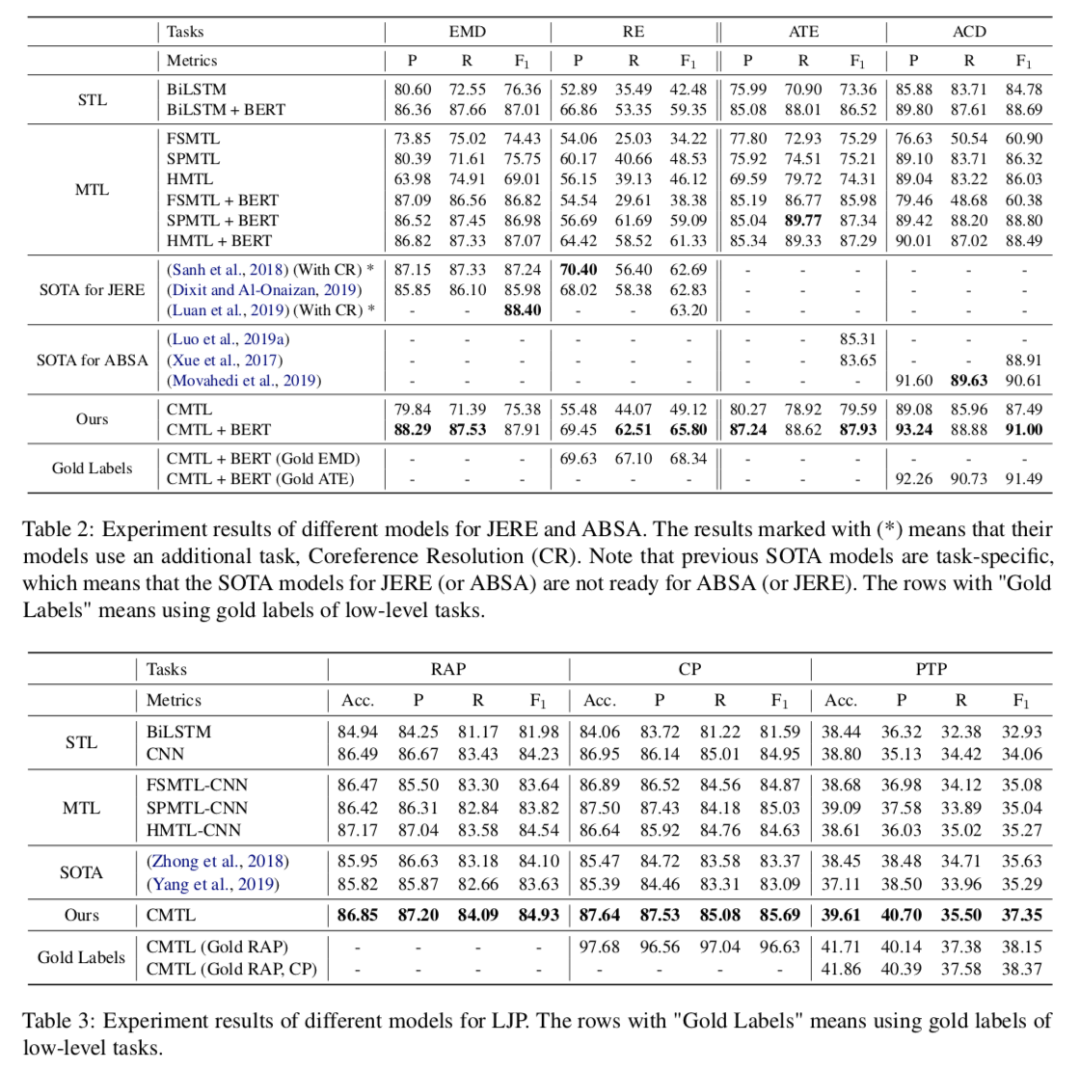
在三個任務(wù)上模型都有所提升。
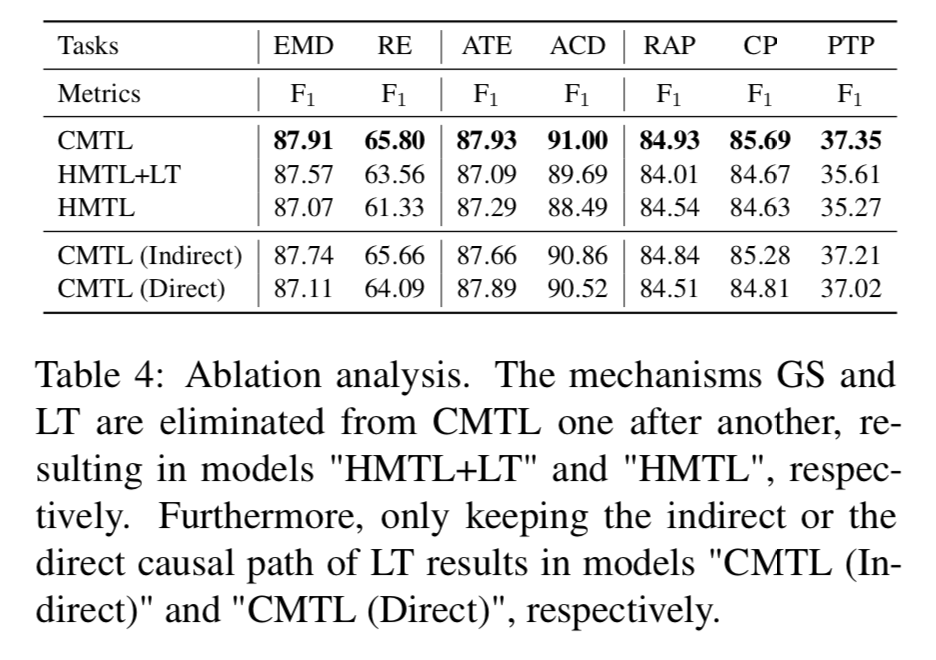
如圖所示,GS和LT對模型都是有影響的,特別是對于高水平的任務(wù)。例如,消除GS導(dǎo)致RE的F1得分下降2.24分,消除這兩種機制導(dǎo)致顯著下降4.47分。此外,文章保留了CMTL的間接因果路徑或直接因果路徑,分別記為CMTL(間接)和CMTL(直接)模型。兩種相關(guān)模型的性能都略差于CMTL。
2. 案例分析

3. 因果效應(yīng)估計
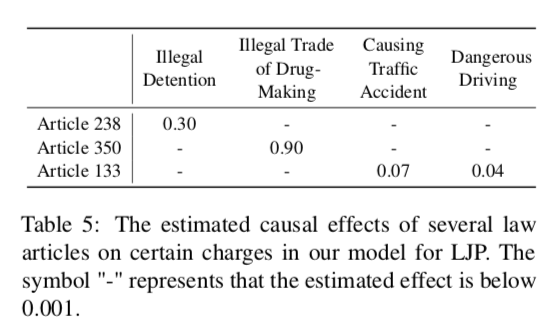
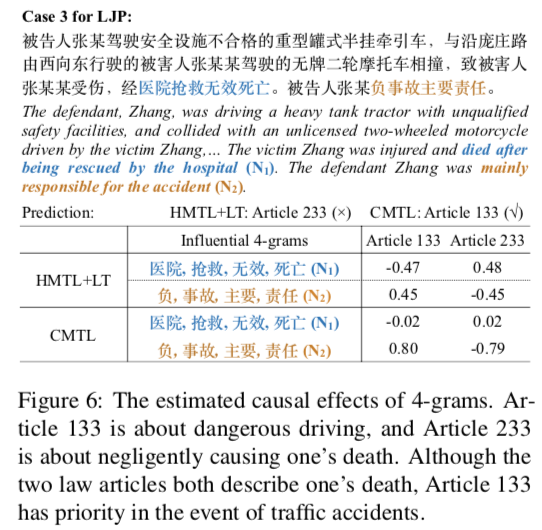
2

論文動機
長期以來典型事件序列所定義的日常情景的常識性知識,一直被認為在文本理解和理解中起著重要作用。通過數(shù)據(jù)驅(qū)動的方法從文本語料庫中學(xué)習(xí)這樣的知識需要確定定量度量標(biāo)準。雖然觀察到的事件之間存在相關(guān)性,但相關(guān)性并不是決定事件是否形成有意義腳本的唯一因素。這篇文章則提出基于因果關(guān)系的方法,用于提取腳本知識。
方法
Step 1: Define a Causal Model
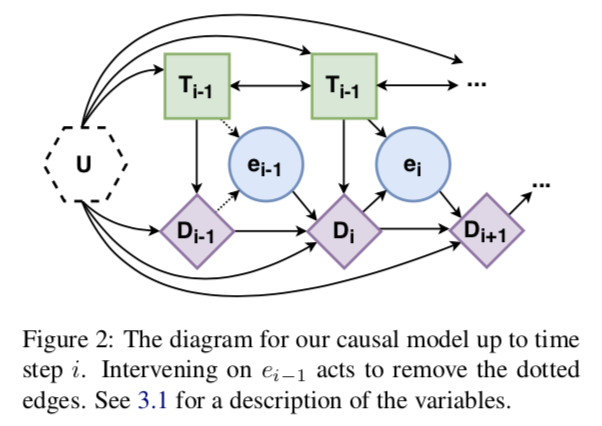
世界,U:生成數(shù)據(jù)的起點是真實世界,由未測量的變量U顯式表示。這個變量是不可知的,通常是不可測量的:我們不知道它是如何分布的,甚至不知道它是什么類型的變量。這個變量由圖2中的六邊形節(jié)點表示。
Text,T:下一種類型的變量是文本。將文本分割成塊T1,…,TN,其中N是文本中事件數(shù)。因此,變量Ti是與文本中提到的第i個事件相對應(yīng)的文本塊。
事件推斷,e:讀取一段文本,并推斷文本中提到的事件類型。這個類型在模型中由變量 表示,其中E是一組可能的原子事件類型。文本直接因果影響推斷的時間類型,所以文本有指向事件的單向箭頭。
語篇表征,D:變量ei表示Ti中部分語義內(nèi)容的高層次抽象。而文本中發(fā)生過事件以及它們之間的因果關(guān)系是人類閱讀時的核心部分,這種信息會顯著影響讀者基于事件的推理。因此,引入一個話語表征變量,它本身就是兩個子變量和的組合。
Step 2: Establishing Identifiability
由后門準則知道:
使用蒙特卡洛估計上述期望。
Step 3: Estimation
通過機器學(xué)習(xí)方法上述中的
Extracting Script Knowledge
令,則腳本相容分數(shù)(因果分數(shù))為。
實驗結(jié)果
使用人工分別對事件對和事件鏈評分的結(jié)果如下:
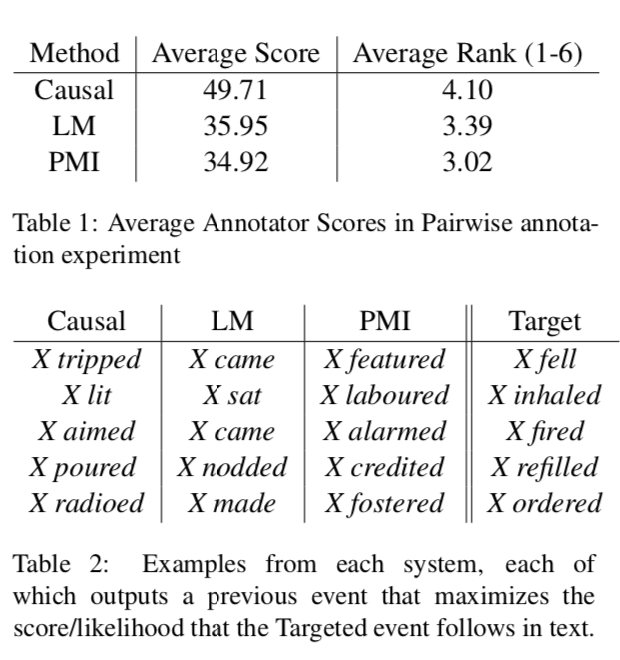
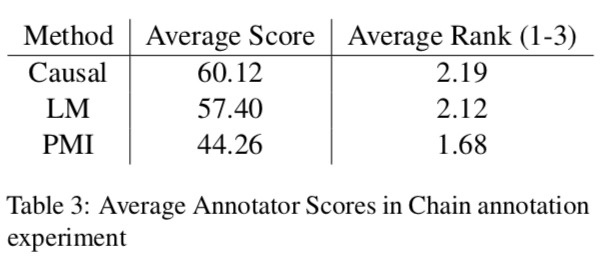
結(jié)果表明因果模型的分數(shù)更高。
3

論文動機
法院意見生成是法律人工智能的一項新穎而重要的任務(wù),旨在提高判決預(yù)測結(jié)果的可解釋性,實現(xiàn)法律文書的自動生成。雖然先前的文本到文本的自然語言生成(NLG)方法可以用來解決這個問題,但是他們都忽略了數(shù)據(jù)生成機制中的混淆偏差,這樣會限制模型的性能,影響學(xué)習(xí)結(jié)果。主要挑戰(zhàn)有:1. 民事法律制度中的“無訴不審”原則,使得判決需要回應(yīng)原告的索賠;2. 民事案件中判決的不平衡,由于原告只會在有很大把握的前提下提起訴訟,也就導(dǎo)致大部分的判決都是支持的,這樣就形成了數(shù)據(jù)分布不均。
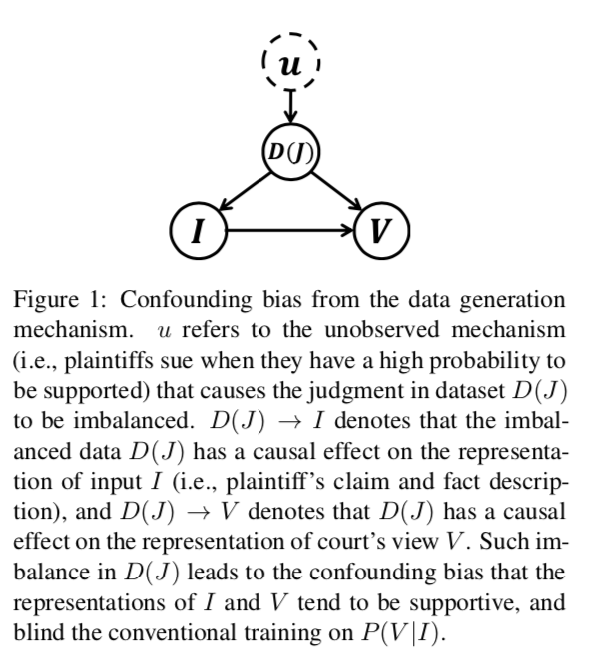
如上因果圖角度看,判決的不平衡揭示了數(shù)據(jù)生成機制導(dǎo)致的混淆偏見。這種不平衡的數(shù)據(jù)將導(dǎo)致輸入(索賠和公認事實)和輸出(法院觀點)的學(xué)習(xí)表示傾向于支持,導(dǎo)致輸入和輸出之間的混淆偏差,并影響傳統(tǒng)NLG模型的訓(xùn)練。
針對這些問題,文章提出了一種基于注意力和反事實的自然語言生成(AC-NLG)方法,通過聯(lián)合優(yōu)化一個索賠感知編碼器、一對反事實解碼器來生成判決分辨性法院意見和一個協(xié)同判決預(yù)測模型。
方法
Backdoor Adjustment
對于一般的生成任務(wù),我們需要計算:如果 ,則 退化為 , 將會忽略 時的表示。后門調(diào)整是因果推理中的一個消除混淆的技術(shù)。后門調(diào)整對進行操作,將后驗概率從被動觀察提升到主動干預(yù)。后門調(diào)整通過計算介入后驗P(V | do(I))和控制混雜因子來解決混雜偏差:。后門調(diào)整切斷了和之間的依賴。
Backdoor In Implementation
實現(xiàn)過程中,使用一對反事實解碼器估計,使用判據(jù)預(yù)測模型估計。
Model Architecture
Claim-aware Encoder:原告的權(quán)利要求c和事實描述f是句子形式。因此,編碼器首先將單詞轉(zhuǎn)換為嵌入詞。然后將嵌入序列反饋給Bi-LSTM,產(chǎn)生兩個隱藏狀態(tài)序列hc、hf,分別對應(yīng)于原告的請求和事實描述。之后,我們使用Claim-aware attention來融合hc和hf。對于hf中的每個隱藏狀態(tài),是其對的注意權(quán)重,注意分布計算如下:
隨后產(chǎn)生新的事實描述表示:
經(jīng)過Bi-LSTM層,得到最終表是。
Judgment Predictor:使用全連接層由h生成判決的概率預(yù)測:
Counterfactual Decoder:為了消除數(shù)據(jù)偏差的影響,使用一對反事實解碼器,其中包含兩個解碼器,一個用于支持的情況,另一個用于不支持的情況。這兩種譯碼器的結(jié)構(gòu)相同,但目的是產(chǎn)生不同判決的法院觀點。運用了注意機制:在每個步驟t,給定編碼器的輸出和解碼狀態(tài),注意力分布的計算方法與相同,但參數(shù)不同。上下文向量是h的加權(quán)和:
。上下文向量與解碼狀態(tài)相連接并送到線性層以產(chǎn)生詞匯分布:
實驗結(jié)果
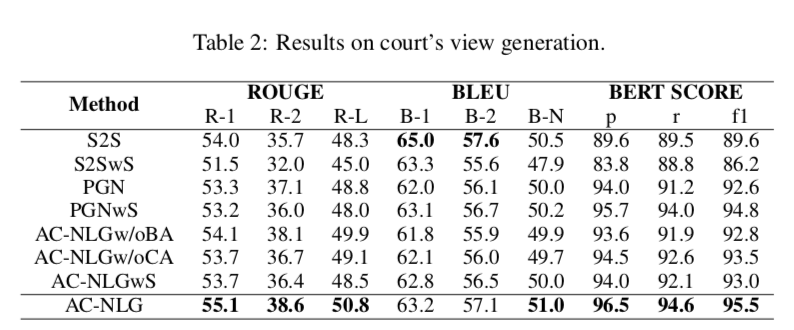
上圖顯示了法院意見生成的一些評估指標(biāo):ROUGE, BLEU, 和 BERT SCORE分數(shù)。可以得出:
(1)S2S傾向于重復(fù)單詞,這使得其BLEU得分較高,而BERT得分較低
(2) 過采樣策略對模型沒有好處,因此,它不能解決混淆偏差
(3) 與基準相比,AC-NLG具有索賠感知編碼器和后門反事實解碼器,在法庭視圖生成方面取得了更好的性能
(4) AC NLGw/oCA和AC-NLG之間的性能差距證明了索賠感知編碼器的有效性,AC NLGw/oBA和AC-NLG之間的差距說明了反事實解碼器的優(yōu)越性。
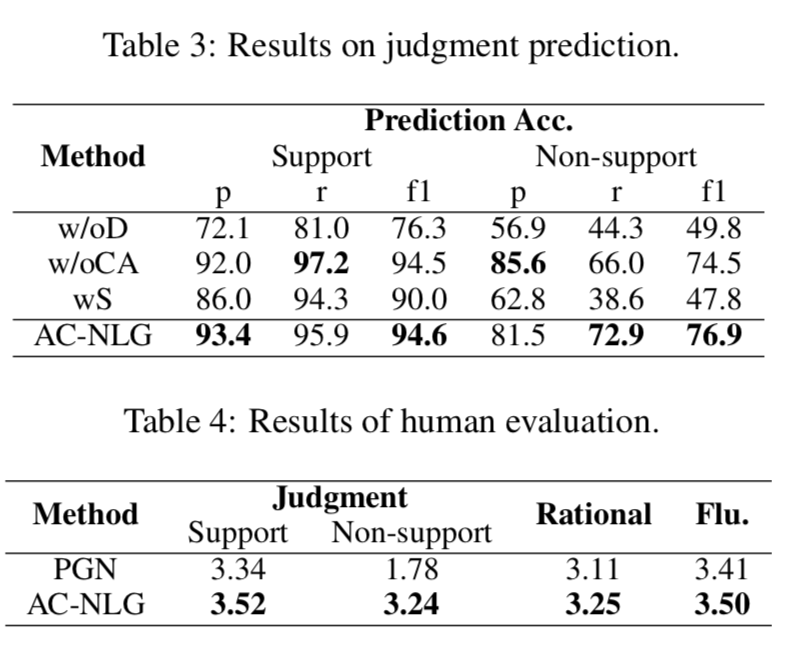
上圖顯示了判決預(yù)測準確率以及人類評估結(jié)果:
判據(jù)預(yù)測結(jié)果:
(1) 模型中反事實譯碼器可以顯著地消除混淆偏差,從而在不支持的情況下獲得顯著的改進,例如將f1從49.8%提高到76.9%
(2) 提出的索賠感知編碼器是為提高生成質(zhì)量而設(shè)計的,對判決預(yù)測的影響有限。
(3) 過采樣并不能給模型帶來任何改進。
人類評估結(jié)果:
(1) 由于數(shù)據(jù)中的混雜偏差,PGN中的判決生成在無支持案例中的表現(xiàn)較差,支持案例和無支持案例之間的表現(xiàn)差距很大(1.56)
(2) 通過使用后門反事實解碼器,AC-NLG大大提高了判決生成的性能,特別是對于不支持的情況,并且在支持和不支持的情況之間實現(xiàn)了較小的性能差距(只有0.28)
(3) AC-NLG使用了一個支持索賠的編碼器,在理性和流暢性方面也取得了更好的性能

上圖展示了不同模型產(chǎn)生的法院觀點。
總結(jié)
此次 Fudan DISC 解讀的三篇論文圍繞因果推斷的應(yīng)用。對于多任務(wù)學(xué)習(xí),可以考慮任務(wù)標(biāo)簽之間的因果性。對于抽取任務(wù),可以考慮使用因果性評估來篩選想要的抽取內(nèi)容。對于數(shù)據(jù)集有偏差的文本生成任務(wù),因果推斷可以幫助消除混淆偏差。
編輯:jq
-
編碼器
+關(guān)注
關(guān)注
45文章
3669瀏覽量
135247 -
譯碼器
+關(guān)注
關(guān)注
4文章
312瀏覽量
50466 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13401
原文標(biāo)題:EMNLP2020 因果推斷
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
超詳細!FMU生成器用戶手冊來啦~

超六類線用幾類水晶頭好
一種基于因果路徑的層次圖卷積注意力網(wǎng)絡(luò)

鑒源實驗室·測試設(shè)計方法-因果圖
經(jīng)緯恒潤功能安全AI 智能體論文成功入選EMNLP 2024!

6a類網(wǎng)線是超6嗎

第19.1 章-星瞳科技 OpenMV視覺循跡功能 超詳細OpenMV與STM32單片機通信

當(dāng)系統(tǒng)鬧脾氣:用「因果推斷」哄穩(wěn)技術(shù)的心





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論