 C語言中Linux字節對齊的問題
C語言中Linux字節對齊的問題
最近作者在做一個項目,遇到一個問題,運行于ARM上的threadx在與DSP通信采用消息隊列的方式傳遞消息(最終實現原理是中斷+共享內存的方式),在實際操作過程中發現threadx總是crash,于是經過排查,是因為傳遞消息的結構體沒有考慮字節對齊的問題。
隨手整理一下C語言中字節對齊的問題與大家一起分享。
一、概念
對齊跟數據在內存中的位置有關。如果一個變量的內存地址正好位于它長度的整數倍,他就被稱做自然對齊。比如在32位cpu下,假設一個整型變量的地址為0x00000004,那它就是自然對齊的。
首先了解什么位、字節、字
| 位 | bit | 1個二進制位稱為1個bit |
| 字節 | Byte | 8個二進制位稱為1個Byte |
| 字 | word | 電腦用來一次性處理事務的一個固定長度 |
| 名稱 | 英文名 | 含義 |
|---|
字長
一個字的位數,現代電腦的字長通常為16,32, 64位。(一般N位系統的字長是N/8字節。)
不同的CPU一次可以處理的數據位數是不同的,32位CPU可以一次處理32位數據,64位CPU可以一次處理64位數據,這里的位,指的就是字長。
而所謂的字長,我們有時會稱為字(word)。在16位的CPU中,一個字剛好為兩個字節,而32位CPU中,一個字是四個字節。若以字為單位,向上還有雙字(兩個字),四字(四個字)。
二、對齊規則
對于標準數據類型,它的地址只要是它的長度的整數倍就行了,而非標準數據類型按下面的原則對齊:數組 :按照基本數據類型對齊,第一個對齊了后面的自然也就對齊了。聯合 :按其包含的長度最大的數據類型對齊。結構體:結構體中每個數據類型都要對齊。
三、如何限制定字節對齊位數?
1. 缺省
在缺省情況下,C編譯器為每一個變量或是數據單元按其自然對界條件分配空間。一般地,可以通過下面的方法來改變缺省的對界條件:
2. #pragma pack(n)
· 使用偽指令#pragma pack (n),C編譯器將按照n個字節對齊。· 使用偽指令#pragma pack (),取消自定義字節對齊方式。
#pragma pack(n) 用來設定變量以n字節對齊方式。n字節對齊就是說變量存放的起始地址的偏移量有兩種情況:
如果n大于等于該變量所占用的字節數,那么偏移量必須滿足默認的對齊方式
如果n小于該變量的類型所占用的字節數,那么偏移量為n的倍數,不用滿足默認的對齊方式。
結構的總大小也有一個約束條件,如果n大于等于所有成員變量類型所占用的字節數,那么結構的總大小必須為占用空間最大的變量占用的空間數的倍數;否則必須是n的倍數。
3. __attribute
另外,還有如下的一種方式:· __attribute((aligned (n))),讓所作用的結構成員對齊在n字節自然邊界上。如果結構中有成員的長度大于n,則按照最大成員的長度來對齊。·attribute((packed)),取消結構在編譯過程中的優化對齊,按照實際占用字節數進行對齊。
3. 匯編.align
匯編代碼通常用.align來制定字節對齊的位數。
.align:用來指定數據的對齊方式,格式如下:
.align[absexpr1,absexpr2]
以某種對齊方式,在未使用的存儲區域填充值. 第一個值表示對齊方式,4, 8,16或 32. 第二個表達式值表示填充的值。
四、為什么要對齊?
操作系統并非一個字節一個字節訪問內存,而是按2,4,8這樣的字長來訪問。因此,當CPU從存儲器讀數據到寄存器,IO的數據長度通常是字長。如32位系統訪問粒度是4字節(bytes), 64位系統的是8字節。當被訪問的數據長度為n字節且該數據地址為n字節對齊時,那么操作系統就可以高效地一次定位到數據,無需多次讀取,處理對齊運算等額外操作。數據結構應該盡可能地在自然邊界上對齊。如果訪問未對齊的內存,CPU需要做兩次內存訪問。
字節對齊可能帶來的隱患:
代碼中關于對齊的隱患,很多是隱式的。比如在強制類型轉換的時候。例如:
unsignedinti=0x12345678; unsignedchar*p=NULL; unsignedshort*p1=NULL; p=&i; *p=0x00; p1=(unsignedshort*)(p+1); *p1=0x0000;
最后兩句代碼,從奇數邊界去訪問unsignedshort型變量,顯然不符合對齊的規定。在x86上,類似的操作只會影響效率,但是在MIPS或者sparc上,可能就是一個error,因為它們要求必須字節對齊.
五、舉例
例1:os基本數據類型占用的字節數
首先查看操作系統的位數
在64位操作系統下查看基本數據類型占用的字節數:
#include
例2:結構體占用的內存大小--默認規則
考慮下面的結構體占用的位數
structyikou_s { doubled; charc; inti; }yikou_t;
執行結果
sizeof(yikou_t)=16
在內容中各變量位置關系如下:
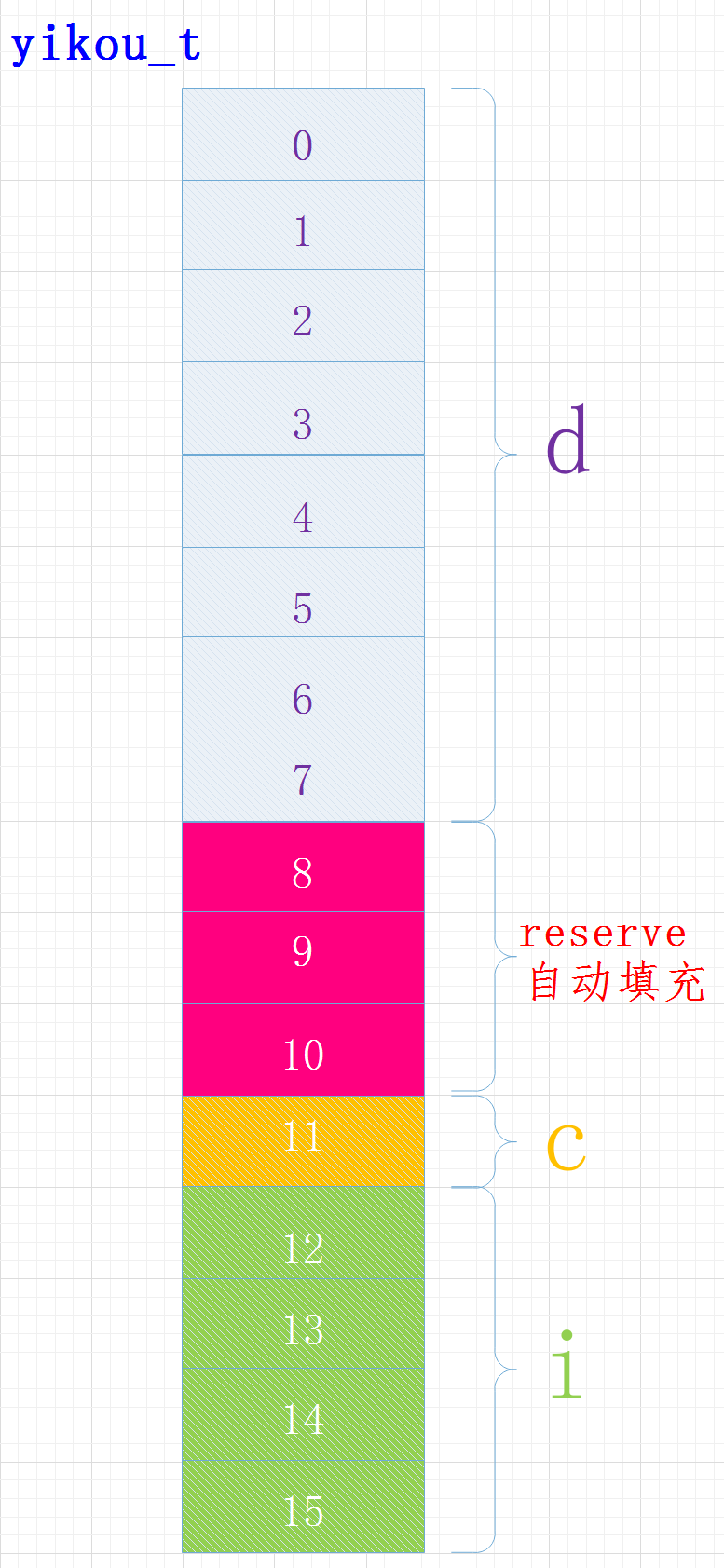
其中成員C的位置還受字節序的影響,有的可能在位置8
編譯器給我們進行了內存對齊,各成員變量存放的起始地址相對于結構的起始地址的偏移量必須為該變量類型所占用的字節數的倍數, 且結構的大小為該結構中占用最大空間的類型所占用的字節數的倍數。
對于偏移量:變量type n起始地址相對于結構體起始地址的偏移量必須為sizeof(type(n))的倍數結構體大小:必須為成員最大類型字節的倍數
char:偏移量必須為sizeof(char)即1的倍數 int:偏移量必須為sizeof(int)即4的倍數 float:偏移量必須為sizeof(float)即4的倍數 double:偏移量必須為sizeof(double)即8的倍數
例3:調整結構體大小
我們將結構體中變量的位置做以下調整:
structyikou_s { charc; doubled; inti; }yikou_t;
執行結果
sizeof(yikou_t)=24
各變量在內存中布局如下:
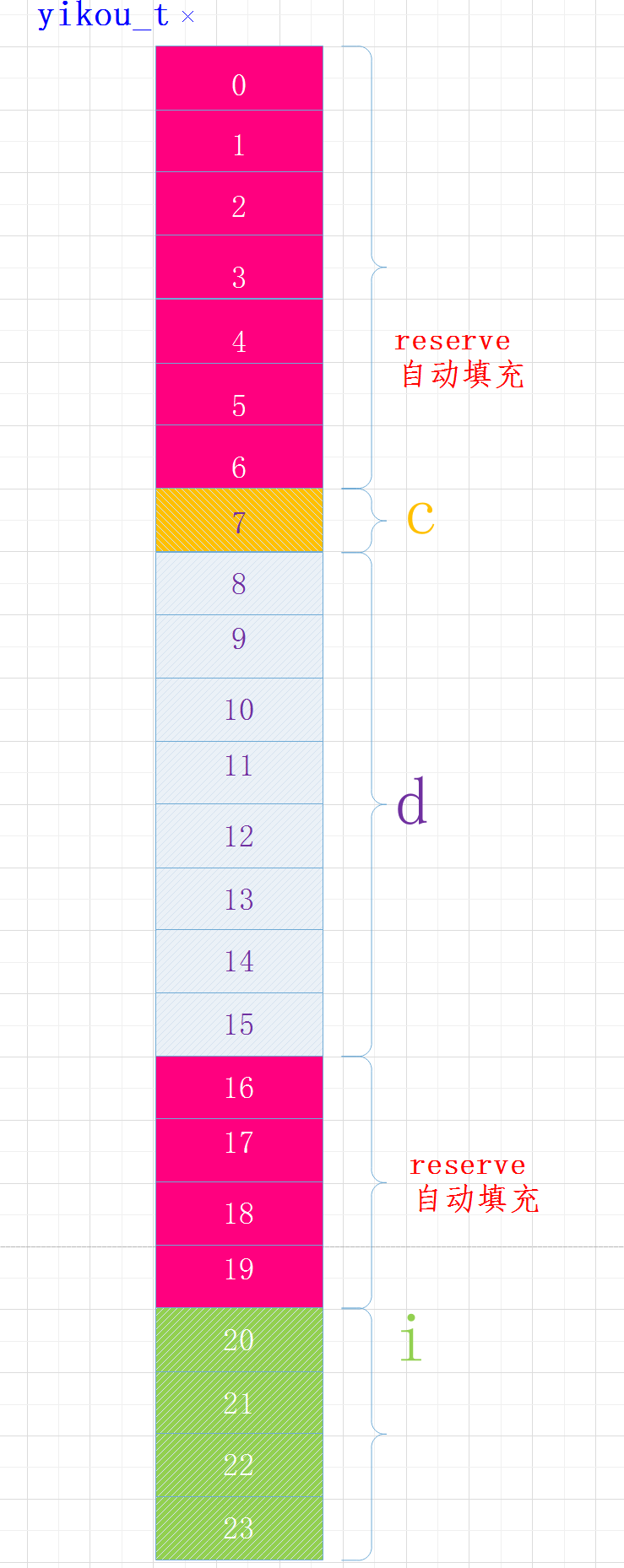
當結構體中有嵌套符合成員時,復合成員相對于結構體首地址偏移量是復合成員最寬基本類型大小的整數倍。
例4:#pragma pack(4)
#pragmapack(4) structyikou_s { charc; doubled; inti; }yikou_t;sizeof(yikou_t)=16
例5:#pragma pack(8)
#pragmapack(8) structyikou_s { charc; doubled; inti; }yikou_t;sizeof(yikou_t)=24
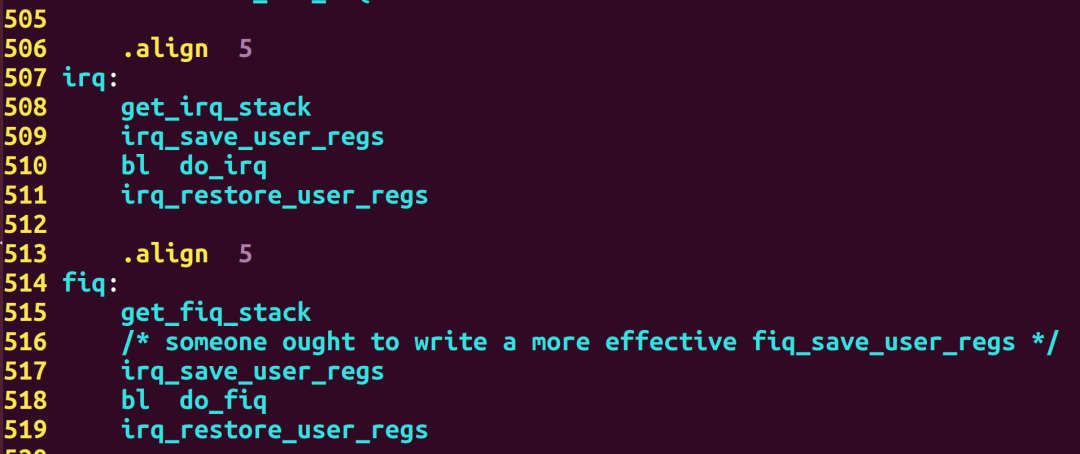
例6:匯編代碼
舉例:以下是截取的uboot代碼中異常向量irq、fiq的入口位置代碼:
六、匯總實力
有手懶的同學,直接貼一個完整的例子給你們:
#include
責任編輯:haq
-
Linux
+關注
關注
87文章
11345瀏覽量
210383 -
C語言
+關注
關注
180文章
7614瀏覽量
137702 -
字節
+關注
關注
0文章
41瀏覽量
13803
原文標題:Linux字節對齊的那些事
文章出處:【微信號:A1411464185,微信公眾號:multisim】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

C語言中申請的堆內存能不能自動釋放
C語言中的socket編程基礎
c語言中從左到右結合怎么看
求助,關于STM32H7的Cache無效化操作32字節對齊問題求解
C語言基礎-為什么要使用C?

C語言中的typedef的應用
C語言#define的應用
C語言中的位域典型的實例







 工商網監
工商網監
評論