 機器學習模型的可解釋性算法詳解
機器學習模型的可解釋性算法詳解
本文介紹目前常見的幾種可以提高機器學習模型的可解釋性的技術,包括它們的相對優點和缺點。我們將其分為下面幾種:
1. Partial Dependence Plot (PDP);
2. Individual Conditional Expectation (ICE)
3. Permuted Feature Importance
4. Global Surrogate
5. Local Surrogate (LIME)
6. Shapley Value (SHAP)
六大可解釋性技術
01. Partial Dependence Plot (PDP)
PDP是十幾年之前發明的,它可以顯示一個或兩個特征對機器學習模型的預測結果的邊際效應。它可以幫助研究人員確定當大量特征調整時,模型預測會發生什么樣的變化。
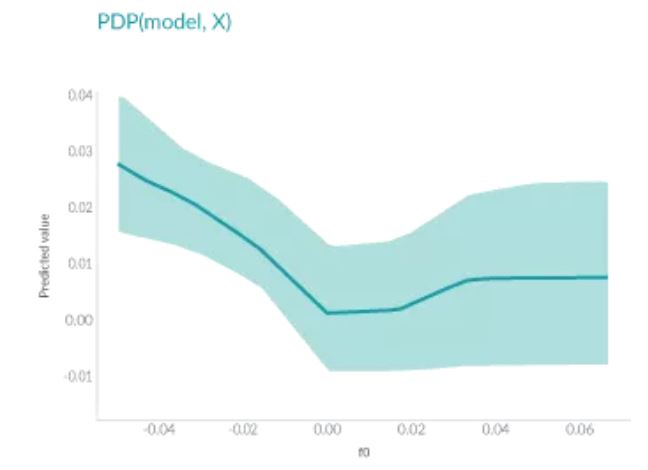
上面圖中,軸表示特征的值,軸表示預測值。陰影區域中的實線顯示了平均預測如何隨著值的變化而變化。PDP能很直觀地顯示平均邊際效應,因此可能會隱藏異質效應。
例如,一個特征可能與一半數據的預測正相關,與另一半數據負相關。那么PDP圖將只是一條水平線。
02. Individual Conditional Expectation (ICE)
ICE和PDP非常相似,但和PDP不同之處在于,PDP繪制的是平均情況,但是ICE會顯示每個實例的情況。ICE可以幫助我們解釋一個特定的特征改變時,模型的預測會怎么變化。
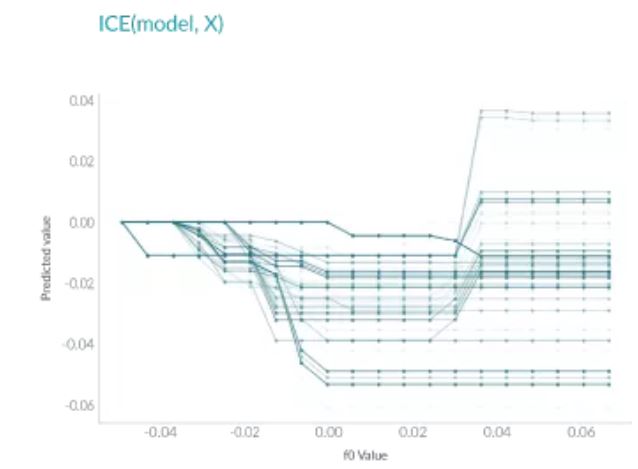
如上圖所示,與PDP不同,ICE曲線可以揭示異質關系。但其最大的問題在于:它不能像PDP那樣容易看到平均效果,所以可以考慮將二者結合起來一起使用。
03. Permuted Feature Importance
Permuted Feature Importance的特征重要性是通過特征值打亂后模型預測誤差的變化得到的。換句話說,Permuted Feature Importance有助于定義模型中的特征對最終預測做出貢獻的大小。
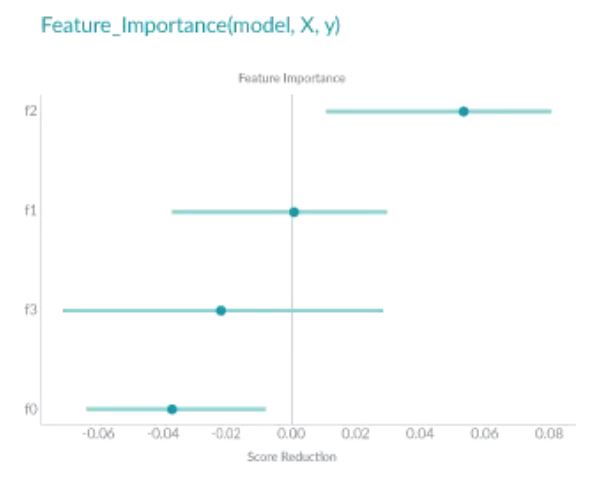
如上圖所示,特征f2在特征的最上面,對模型的誤差影響是最大的,f1在shuffle之后對模型卻幾乎沒什么影響,生息的特征則對于模型是負面的貢獻。
04. Global Surrogate
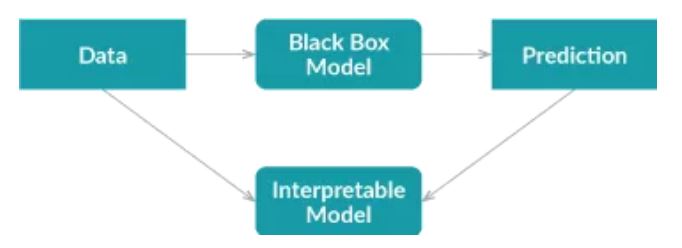
Global Surrogate方法采用不同的方法。它通過訓練一個可解釋的模型來近似黑盒模型的預測。
首先,我們使用經過訓練的黑盒模型對數據集進行預測;
然后我們在該數據集和預測上訓練可解釋的模型。
訓練好的可解釋模型可以近似原始模型,我們需要做的就是解釋該模型。
注:代理模型可以是任何可解釋的模型:線性模型、決策樹、人類定義的規則等。
使用可解釋的模型來近似黑盒模型會引入額外的誤差,但額外的誤差可以通過R平方來衡量。
由于代理模型僅根據黑盒模型的預測而不是真實結果進行訓練,因此全局代理模型只能解釋黑盒模型,而不能解釋數據。
05. Local Surrogate (LIME)
LIME(Local Interpretable Model-agnostic Explanations)和global surrogate是不同的,因為它不嘗試解釋整個模型。相反,它訓練可解釋的模型來近似單個預測。LIME試圖了解當我們擾亂數據樣本時預測是如何變化的。
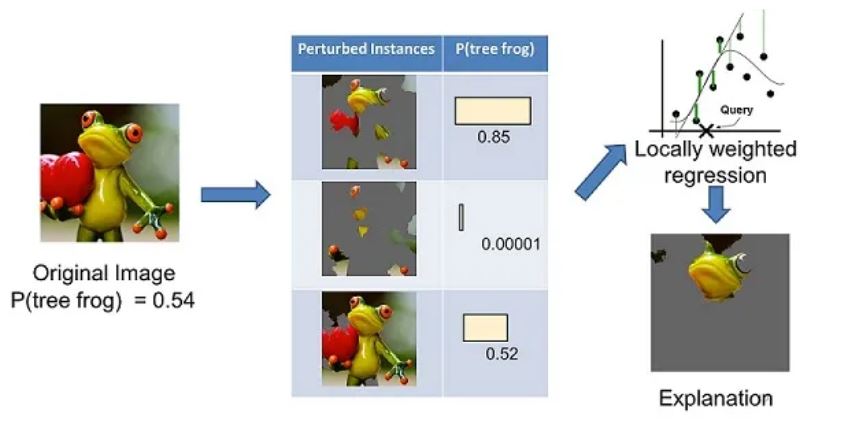
上面左邊的圖像被分成可解釋的部分。然后,LIME 通過“關閉”一些可解釋的組件(在這種情況下,使它們變灰)來生成擾動實例的數據集。對于每個擾動實例,可以使用經過訓練的模型來獲取圖像中存在樹蛙的概率,然后在該數據集上學習局部加權線性模型。最后,使用具有最高正向權重的成分來作為解釋。
06. Shapley Value (SHAP)
Shapley Value的概念來自博弈論。我們可以通過假設實例的每個特征值是游戲中的“玩家”來解釋預測。每個玩家的貢獻是通過在其余玩家的所有子集中添加和刪除玩家來衡量的。一名球員的Shapley Value是其所有貢獻的加權總和。Shapley 值是可加的,局部準確的。如果將所有特征的Shapley值加起來,再加上基值,即預測平均值,您將得到準確的預測值。這是許多其他方法所沒有的功能。
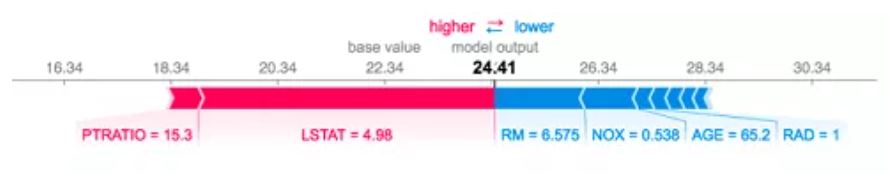
該圖顯示了每個特征的Shapley值,表示將模型結果從基礎值推到最終預測的貢獻。紅色表示正面貢獻,藍色表示負面貢獻。
小結
機器學習模型的可解釋性是機器學習中一個非常活躍而且重要的研究領域。本文中我們介紹了6種常用的用于理解機器學習模型的算法。大家可以依據自己的實踐場景進行使用。
參考文獻
https://www.twosigma.com/articles/interpretability-methods-in-machine-le...
【免責聲明】本文轉載自:Datawhale,轉載此文目的在于傳播相關技術知識,版權歸原作者所有,如涉及侵權,請聯系小編刪除(聯系郵箱:service@eetrend.com )。
審核編輯:符乾江
-
PDP
+關注
關注
0文章
53瀏覽量
36256 -
機器學習
+關注
關注
66文章
8438瀏覽量
133084
發布評論請先 登錄
相關推薦
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
NPU與機器學習算法的關系
一種基于因果路徑的層次圖卷積注意力網絡

魯棒性在機器學習中的重要性
常見AI大模型的比較與選擇指南
AI大模型與深度學習的關系
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
Al大模型機器人
機器學習算法原理詳解

【大規模語言模型:從理論到實踐】- 閱讀體驗
【大語言模型:原理與工程實踐】核心技術綜述
Meta發布SceneScript視覺模型,高效構建室內3D模型
AI算法在礦山智能化中的應用全解析





 工商網監
工商網監
評論