 如何使用框架訓練網絡加速深度學習推理
如何使用框架訓練網絡加速深度學習推理
從 TensorRT 7.0 開始, Universal Framework Format( UFF )被棄用。在本文中,您將學習如何使用新的 TensorFlow -ONNX- TensorRT 工作流部署經過 TensorFlow 培訓的深度學習模型。圖 1 顯示了 TensorRT 的高級工作流。

圖 1 。 TensorRT 是一種推理加速器。
首先,使用任何框架訓練網絡。網絡訓練后,批量大小和精度是固定的(精度為 FP32 、 FP16 或 INT8 )。訓練好的模型被傳遞給 TensorRT 優化器,優化器輸出一個優化的運行時(也稱為計劃)。。 plan 文件是 TensorRT 引擎的序列化文件格式。計劃文件需要反序列化才能使用 TensorRT 運行時運行推斷。
要優化在 TensorFlow 中實現的模型,只需將模型轉換為 ONNX 格式,并使用 TensorRT 中的 ONNX 解析器解析模型并構建 TensorRT 引擎。圖 2 顯示了高級 ONNX 工作流。

圖 2 。 ONNX 工作流。
在本文中,我們將討論如何使用 ONNX 工作流創建一個 TensorRT 引擎,以及如何從 TensorRT 引擎運行推理。更具體地說,我們演示了從 Keras 或 TensorFlow 中的模型到 ONNX 的端到端推理,以及使用 ResNet-50 、語義分段和 U-Net 網絡的 TensorRT 引擎。最后,我們將解釋如何在其他網絡上使用此工作流。
下載 TensorFlow -onnx- TensorRT 后 – 代碼 tar 。 gz 文件,您還應該從 Cityscapes dataset scripts repo 下載 labels.py ,并將其與其他腳本放在同一個文件夾中。
ONNX 概述
ONNX 是機器學習和深度學習模型的開放格式。它允許您將不同框架(如 TensorFlow 、 PyTorch 、 MATLAB 、 Caffe 和 Keras )的深度學習和機器學習模型轉換為單一格式。
它定義了一組通用的運算符、深入學習的通用構建塊集和通用文件格式。它提供計算圖的定義以及內置運算符。可能有一個或多個輸入或輸出的 ONNX 節點列表形成一個無環圖。
ResNet ONNX 工作流示例
在這個例子中,我們展示了如何在兩個不同的網絡上使用 ONNX 工作流并創建一個 TensorRT 引擎。第一個網絡是 ResNet-50 。
工作流包括以下步驟:
將 TensorFlow / Keras 模型轉換為。 pb 文件。
將。 pb 文件轉換為 ONNX 格式。
創建 TensorRT 引擎。
從 TensorRT 引擎運行推斷。
將模型轉換為。 pb
第一步是將模型轉換為。 pb 文件。以下代碼示例將 ResNet-50 模型轉換為。 pb 文件:
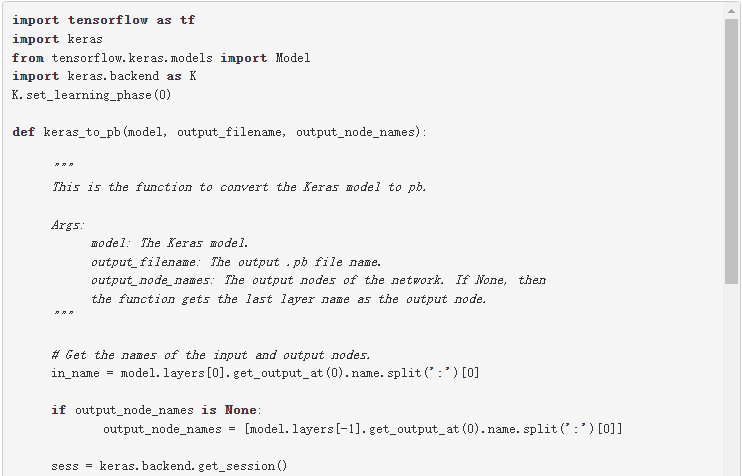

除了 Keras ,您還可以從以下位置下載 ResNet-50 :
深度學習示例 GitHub 存儲庫:提供最新的深度學習示例網絡。您還可以看到 ResNet-50 分支,它包含一個腳本和方法來訓練 ResNet-50v1 。 5 模型。
NVIDIA NGC 型號 :它有預訓練模型的檢查點列表。例如,在 ResNet-50v1 。 5 上搜索 TensorFlow ,并從 Download 頁面獲取最新的檢查點。
將。 pb 文件轉換為 ONNX
第二步是將。 pb 模型轉換為 ONNX 格式。為此,首先安裝 tf2onnx 。
安裝 tf2onnx 后,有兩種方法可以將模型從。 pb 文件轉換為 ONNX 格式。第二種方法是使用命令行。運行以下命令:

從 ONNX 創建 TensorRT 引擎
要從 ONNX 文件創建 TensorRT 引擎,請運行以下命令:
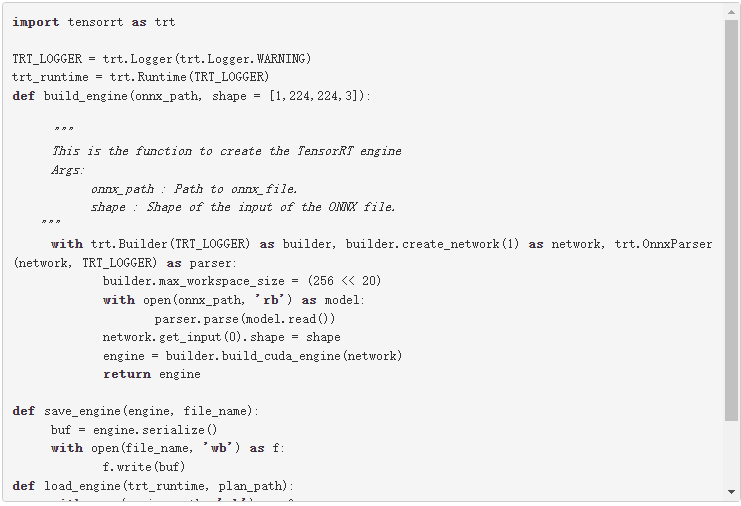

此代碼應保存在引擎。 py 文件,稍后在文章中使用。
此代碼示例包含以下變量:
最大工作區大小: 在執行時 ICudaEngine 可以使用的最大 GPU 臨時內存。
構建器創建一個空網絡( builder.create_network() ), ONNX 解析器將 ONNX 文件解析到網絡( parser.parse(model.read()) )。您可以為網絡( network.get_input(0).shape = shape )設置輸入形狀,然后生成器將創建引擎( engine = builder.build_cuda_engine(network) )。要創建引擎,請運行以下代碼示例:
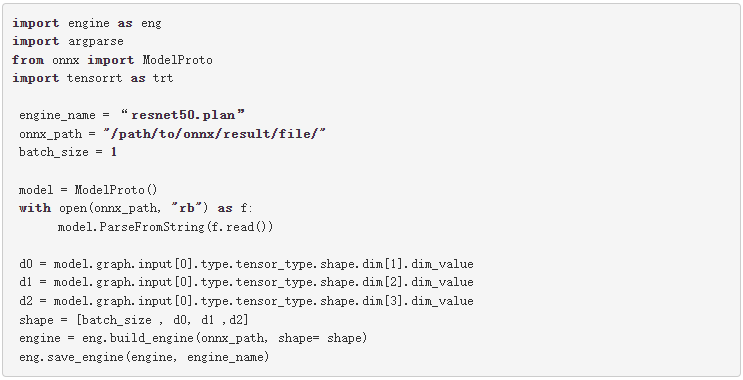
在這個代碼示例中,首先從 ONNX 模型獲取輸入形狀。接下來,創建引擎,然后將引擎保存在。 plan 文件中。
運行來自 TensorRT 引擎的推理:
TensorRT 引擎在以下工作流中運行推理:
為 GPU 中的輸入和輸出分配緩沖區。
將數據從主機復制到 GPU 中分配的輸入緩沖區。
在 GPU 中運行推理。
將結果從 GPU 復制到主機。
根據需要重塑結果。
下面的代碼示例詳細解釋了這些步驟。此代碼應保存在推理。 py 文件,稍后將在本文中使用。


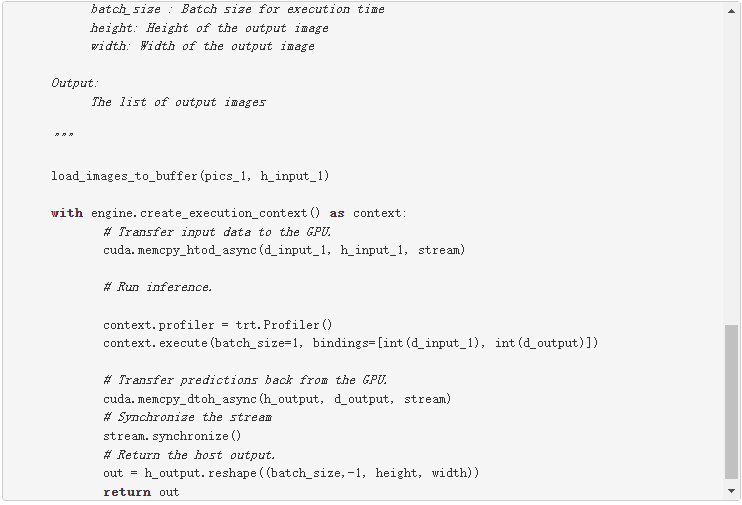
為第一個輸入行和輸出行確定兩個維度。您可以在主機( h_input_1 、 h_output )中創建頁鎖定內存緩沖區。然后,為輸入和輸出分配與主機輸入和輸出相同大小的設備內存( d_input_1 , d_output )。下一步是創建 CUDA 流,用于在設備和主機分配的內存之間復制數據。
在這個代碼示例中,在 do_inference 函數中,第一步是使用 load_images_to_buffer 函數將圖像加載到主機中的緩沖區。然后將輸入數據傳輸到 GPU ( cuda.memcpy_htod_async(d_input_1, h_input_1, stream) ),并使用 context.execute 運行推理。最后將結果從 GPU 復制到主機( cuda.memcpy_dtoh_async(h_output, d_output, stream) )。
ONNX 工作流語義分割實例
在本文 基于 TensorRT 3 的自主車輛快速 INT8 推理 中,作者介紹了一個語義分割模型的 UFF 工作流過程。
在本文中,您將使用類似的網絡來運行 ONNX 工作流來進行語義分段。該網絡由一個基于 VGG16 的編碼器和三個使用反褶積層實現的上采樣層組成。網絡在 城市景觀數據集 上經過大約 40000 次迭代訓練
有多種方法可以將 TensorFlow 模型轉換為 ONNX 文件。一種方法是 ResNet50 部分中解釋的方法。 Keras 也有自己的 Keras 到 ONNX 文件轉換器。有時, TensorFlow -to-ONNX 不支持某些層,但 Keras-to-ONNX 轉換器支持這些層。根據 Keras 框架和使用的層類型,您可能需要在轉換器之間進行選擇。
在下面的代碼示例中,使用 Keras-to-ONNX 轉換器將 Keras 模型直接轉換為 ONNX 。下載預先訓練的語義分段文件 semantic_segmentation.hdf5 。

圖 3 顯示了網絡的體系結構。

圖 3 。基于 VGG16 的語義分割模型。
與前面的示例一樣,使用下面的代碼示例創建語義分段引擎。

要測試模型的輸出,請使用 城市景觀數據集 。要使用城市景觀,必須具有以下功能: sub_mean_chw 和 color_map 。這些函數也用于 post , 基于 TensorRT 3 的自主車輛快速 INT8 推理 。
在下面的代碼示例中, sub_mean_chw 用于從圖像中減去平均值作為預處理步驟, color_map 是從類 ID 到顏色的映射。后者用于可視化。
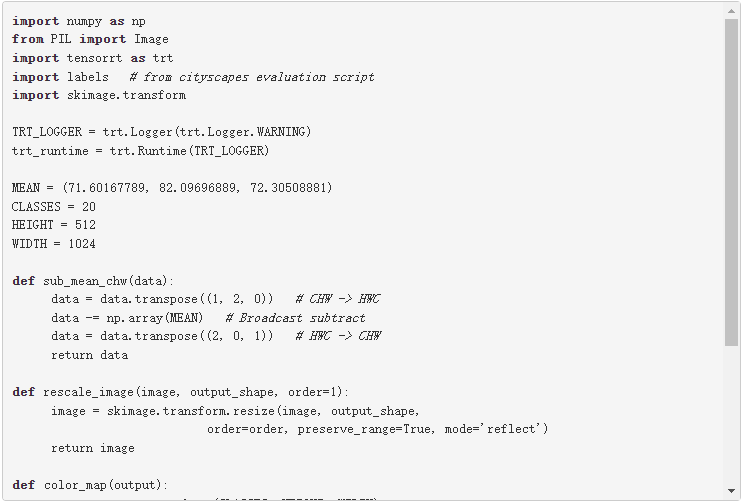

下面的代碼示例是上一個示例的其余代碼。必須先運行上一個塊,因為需要定義的函數。使用這個例子比較 Keras 模型和 TensorRT 引擎 semantic 。 plan 文件的輸出,然后可視化這兩個輸出。根據需要替換占位符 /path/to/semantic_segmentation.hdf5 和 input_file_path 。
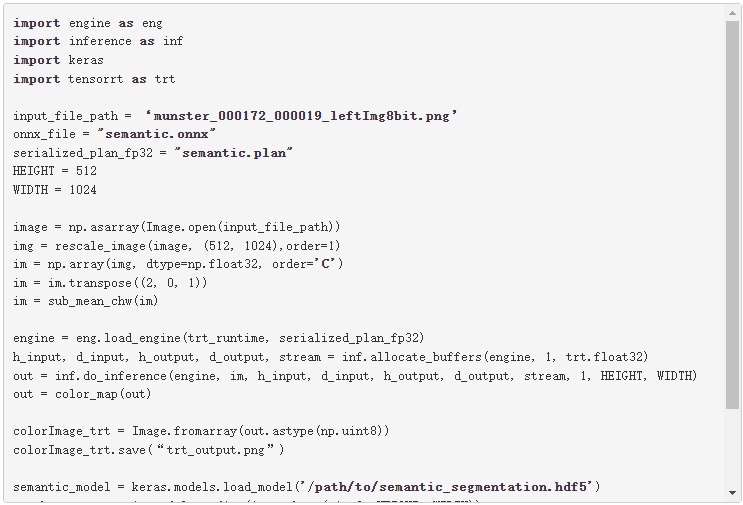

圖 4 顯示了實際圖像和實際情況,以及 Keras 的輸出與 TensorRT 引擎的輸出的對比。如您所見, TensorRT 發動機的輸出與 Keras 的類似。

圖 4a 原始圖像 。

圖 4b 地面真相標簽。

圖 4c 。 TensorRT 的輸出。

圖 4d : Keras 的輸出。
在其他網絡上試試
現在您可以在其他網絡上嘗試 ONNX 工作流。有關分段網絡的好例子的更多信息,請參閱 GitHub 上的 具有預訓練主干的分割模型 。
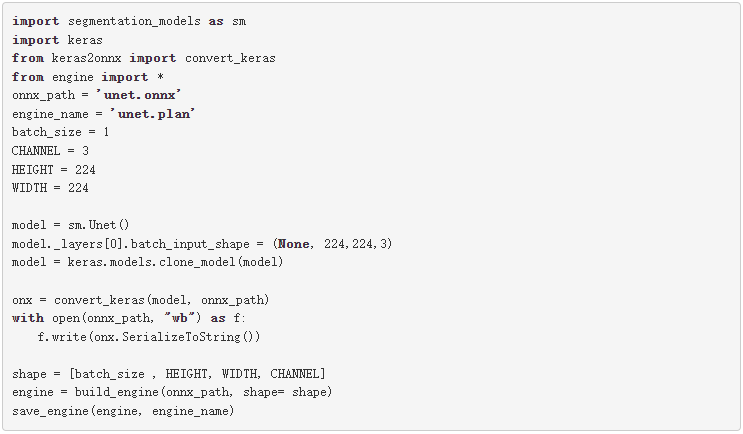
作為一個例子,我們用一個 ONNX 網絡來說明如何使用。本例中的網絡是來自 segmentation_models 庫的 U-Net 。在這里,我們只加載模型,而沒有對其進行訓練。您可能需要在首選數據集上訓練這些模型。
關于這些網絡的一個重要點是,當您加載這些網絡時,它們的輸入層大小如下所示:( None , None , None , 3 )。要創建一個 TensorRT 引擎,您需要一個輸入大小已知的 ONNX 文件。在將此模型轉換為 ONNX 之前,請通過為其輸入指定大小來更改網絡,然后將其轉換為 ONNX 格式。
例如,從這個庫( segmentation _ models )加載 U-Net 網絡并為其輸入指定大小( 244 、 244 、 3 )。在為推理創建了 TensorRT 引擎之后,做一個與語義分段類似的轉換。根據應用程序和數據集的不同,可能需要使用不同的顏色映射。
我們之前提到的另一種下載方式是從 vz6 下載。它有一個預先訓練模型的檢查點列表。例如,您可以在 TensorFlow 中搜索 UNet ,然后轉到 Download 頁面以獲取最新的檢查點。
總結
在這篇文章中,我們解釋了如何使用 TensorFlow-to-ONNX-to-TensorRT 工作流來部署深度學習應用程序,并給出了幾個示例。第一個例子是 ResNet-50 上的 ONNX- TensorRT ,第二個例子是在 Cityscapes 數據集上訓練的基于 英偉達數據中心深度學習產品性能 的語義分割。
關于作者
Houman 是 NVIDIA 的高級深度學習軟件工程師。他一直致力于開發和生產 NVIDIA 在自動駕駛車輛中的深度學習解決方案,提高 DNN 的推理速度、精度和功耗,并實施和試驗改進 NVIDIA 汽車 DNN 的新思想。他在渥太華大學獲得計算機科學博士學位,專注于機器學習
About Yu-Te Cheng
Yu-Te Cheng 是 NVIDIA 自主駕駛組高級深度學習軟件工程師,從事自駕領域的各種感知任務的神經結構搜索和 DNN 模型訓練、壓縮和部署,包括目標檢測、分割、路徑軌跡生成等。他于 2016 年獲得卡內基梅隆大學機器人學碩士學位。
About Josh Park
Josh Park 是 NVIDIA 的汽車解決方案架構師經理。到目前為止,他一直在研究使用 DL 框架的深度學習解決方案,例如在 multi-GPUs /多節點服務器和嵌入式系統上的 TensorFlow 。此外,他一直在評估和改進各種 GPUs + x86 _ 64 / aarch64 的訓練和推理性能。他在韓國大學獲得理學學士和碩士學位,并在德克薩斯農工大學獲得計算機科學博士學位
審核編輯:郭婷
-
代碼
+關注
關注
30文章
4828瀏覽量
69055 -
深度學習
+關注
關注
73文章
5515瀏覽量
121553
發布評論請先 登錄
相關推薦
大模型訓練框架(五)之Accelerate
卷積神經網絡的實現工具與框架

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案






 工商網監
工商網監
評論