 使用NCCL 2.12將所有all2all性能翻倍
使用NCCL 2.12將所有all2all性能翻倍
集體通信是現代分布式人工智能培訓工作(如推薦系統和自然語言處理)的一個關鍵性能組成部分。
NVIDIA Collective Communication Library ( NCCL )是一個 Magnum IO 庫,可實現 GPU 加速的集體操作:
集合
全部減少
廣播
減少
減少分散
點對點發送和接收
NCCL 具有拓撲意識,經過優化,可通過 PCIe 、 NVLink 、以太網和 InfiniBand 互連實現高帶寬和低延遲。 NCCL GCP 插件 和 NCCL AWS 插件 通過自定義網絡連接,在流行的云環境中實現高性能 NCCL 操作。
NCCL 版本一直致力于提高集體溝通績效。這篇文章主要關注 NCCL 2.12 版本帶來的改進。
結合 NVLink 和網絡通信
NCCL 2.12 中引入的新功能稱為 PXN ,稱為 PCI × NVLink ,因為它使 GPU 能夠通過 NVLink 然后通過 PCI 與節點上的 NIC 通信。這不是使用 QPI 或其他無法提供全部帶寬的 CPU 協議通過 CPU 。這樣,即使每個 GPU 仍然盡可能多地使用其本地 NIC ,但如果需要,它可以訪問其他 NIC 。
GPU 在中間 GPU 上準備緩沖區,通過 NVLink 寫入,而不是在其本地內存上準備緩沖區供本地 NIC 發送。然后,它通知管理該 NIC 的 CPU 代理數據已就緒,而不是通知其自己的 CPU 代理。 GPU- CPU 同步可能會稍微慢一點,因為它可能必須穿過 CPU 插槽,但數據本身只使用 NVLink 和 PCI 交換機,以保證最大帶寬。
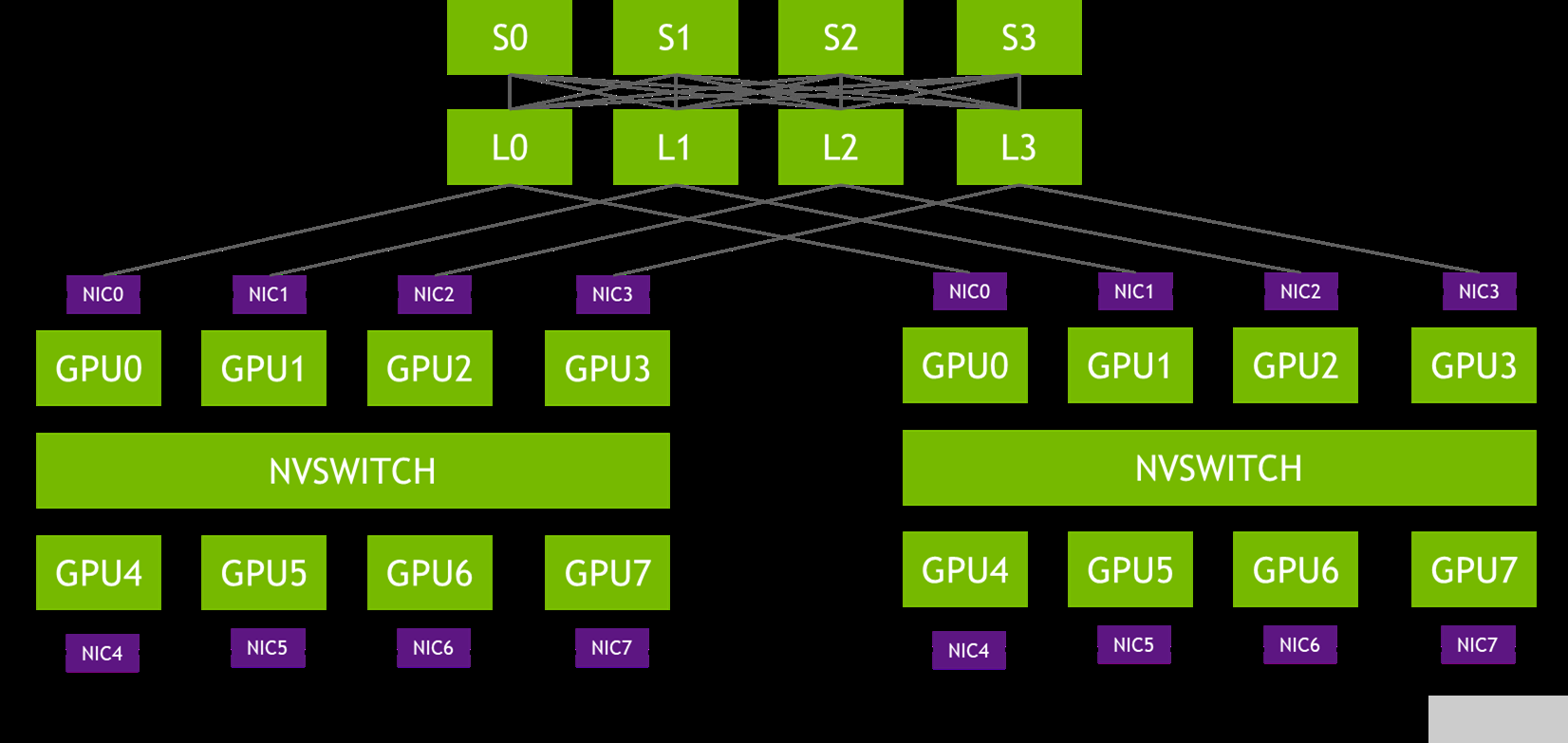
圖 1 。軌道優化拓撲
在圖 1 的拓撲中,每個 DGX 系統的 NIC-0 連接到同一個葉交換機( L0 ), NIC-1 連接到同一個葉交換機( L1 ),依此類推。這種設計通常被稱為 rail-optimized 。鐵路優化網絡拓撲有助于最大限度地提高所有流量,降低性能,同時最大限度地減少流量之間的網絡干擾。它還可以通過輕軌之間的連接來降低網絡成本。
PXN 利用節點內 GPU 之間的 NVIDIA NVSwitch 連接,首先將 GPU 上的數據移動到與目的地相同的軌道上,然后在不跨越軌道的情況下將其發送到目的地。這可以實現消息聚合和網絡流量優化。
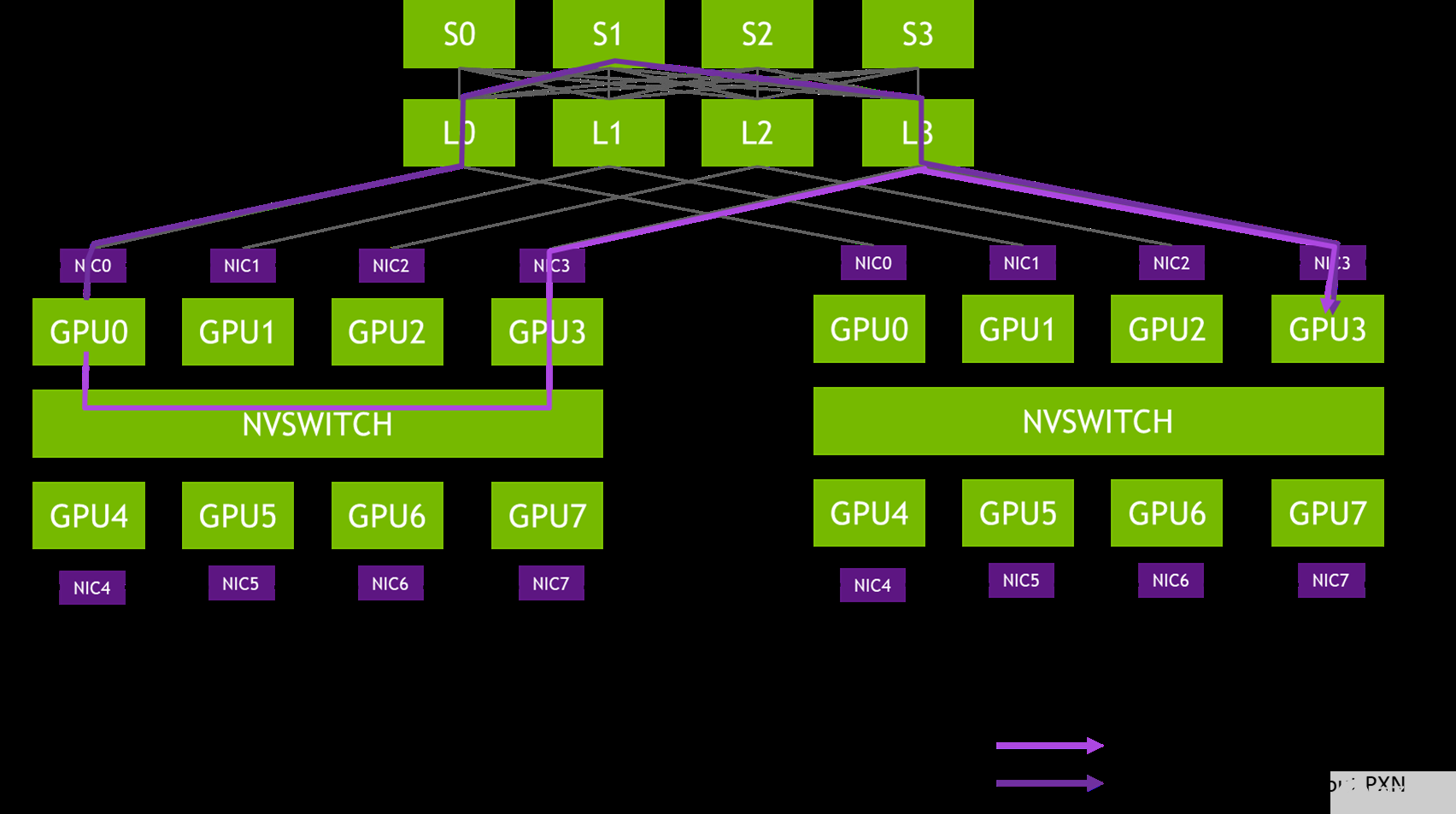
圖 2 。從 DGX-A 中的 GPU0 到 DGX-B 中的 GPU3 的消息路徑示例
在 NCCL 2.12 之前,圖 X 中的消息會穿過網絡交換機的三個躍點( L0 、 S1 和 L3 ),這可能會導致爭用,并被其他流量減慢。在同一對 NIC 之間傳遞的消息被聚合,以最大限度地提高有效消息速率和網絡帶寬。
消息聚合
使用 PXN ,給定節點上的所有 GPU 將其數據移動到給定目的地的單個 GPU 上。這使得網絡層能夠通過實現新的多接收功能來聚合消息。該功能使遠程 CPU 代理能夠在所有消息準備就緒后立即將它們作為一個整體發送。
例如,如果節點上的 GPU 正在執行 all2all 操作,并且要從遠程節點的所有八個 GPU 接收數據, NCCL 調用具有八個緩沖區和大小的多接收。在發送方方面,網絡層可以等待所有八次發送就緒,然后一次發送所有八條消息,這會對消息速率產生顯著影響。
消息聚合的另一個方面是,現在在給定目的地的所有 GPU 節點之間共享連接。這意味著要建立的連接更少。如果路由算法依賴于有很多不同的連接來獲得良好的熵,這也會影響路由效率。
PXN 提高了所有 2 的性能
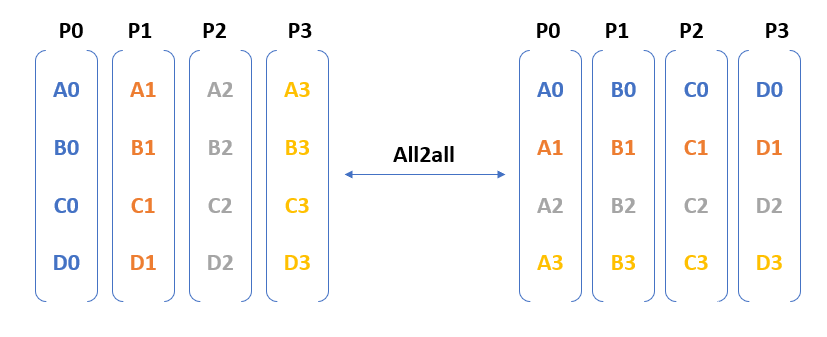
圖 3 。所有 2 跨四個參與流程的所有集體操作
圖 3 顯示了 all2all 需要從每個進程到其他每個進程的通信。換句話說,在 N – GPU 集群中,作為 all2all 操作的一部分交換的消息數是$ O ( N ^{ 2 })$。
GPU 之間交換的消息是不同的,無法使用 樹/環等算法(用于 allreduce ) 進行優化。當您在 GPU 的 100 秒內運行十億個以上的參數模型時,消息的數量可能會觸發擁塞、創建網絡熱點,并對性能產生不利影響。
如前所述, PXN 將 NVLink 和 PCI 通信結合起來,以減少通過第二層脊椎交換機的流量,并優化網絡流量。它還通過將多達八條消息聚合為一條消息來提高消息速率。這兩項改進都顯著提高了所有 2 的性能。
所有 reduce 都基于 1:1 GPU:NIC 拓撲
PXN 解決的另一個問題是拓撲的情況,即每個 NIC 附近都有一個 GPU 。環形算法要求兩個 GPU 靠近每個 NIC 。數據必須從網絡傳輸到第一個 GPU ,通過 NVLink 繞過所有 GPU ,然后從最后一個 GPU 退出網絡。第一個和最后一個 GPU 必須都靠近 NIC 。第一個 GPU 必須能夠有效地從網絡接收,最后一個 GPU 必須能夠有效地通過網絡發送。如果只有一個 GPU 靠近給定的 NIC ,則無法關閉環,必須通過 CPU 發送數據,這可能會嚴重影響性能。
有了 PXN ,只要最后一個 GPU 可以通過 NVLink 訪問第一個 GPU ,它就可以將數據移動到第一個 GPU 。數據從那里發送到 NIC ,將所有傳輸保持在 PCI 交換機的本地。
這種情況不僅與每個 PCI 交換機具有一個 GPU 和一個 NIC 的 PCI 拓撲有關,而且當 NCCL 通信器僅包含 GPU 的子集時,也可能發生在其他拓撲上。考慮具有 nVLink 超立方體網格的 8x GPU 互連的節點。
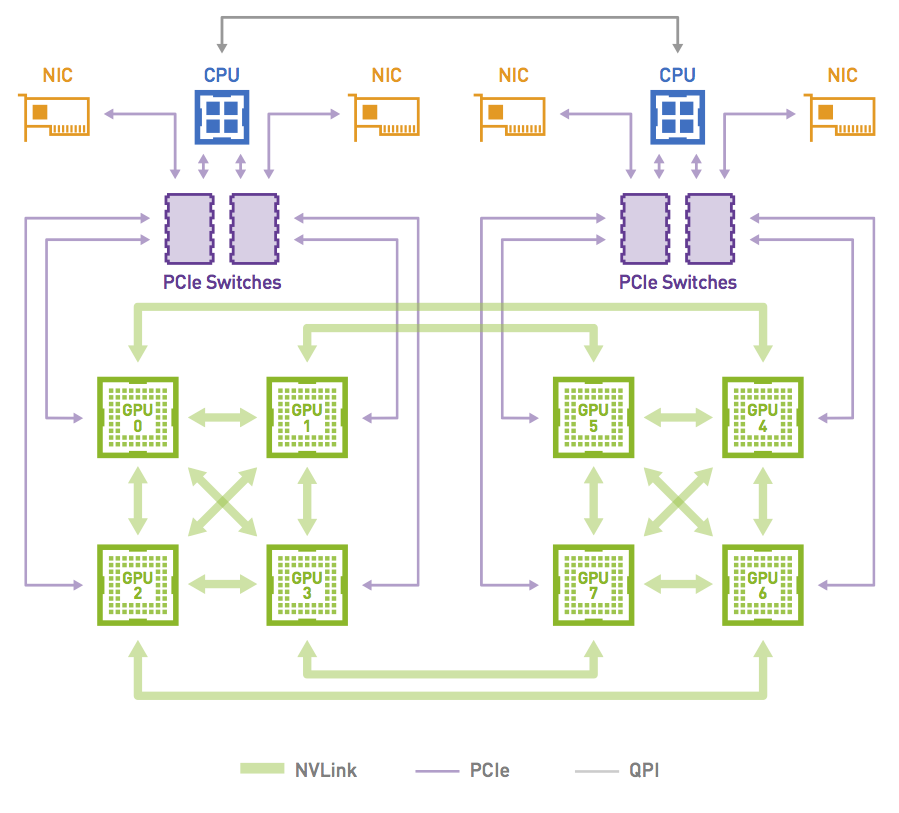
圖 4 。 NVIDIA DGX-1 系統中的網絡拓撲
圖 5 顯示了當通信器包括系統中的所有 8x GPU 時,利用拓撲中可用的高帶寬 NVLink 連接可以形成的環。這是可能的,因為 GPU0 和 GPU1 共享對同一本地 NIC 的訪問。
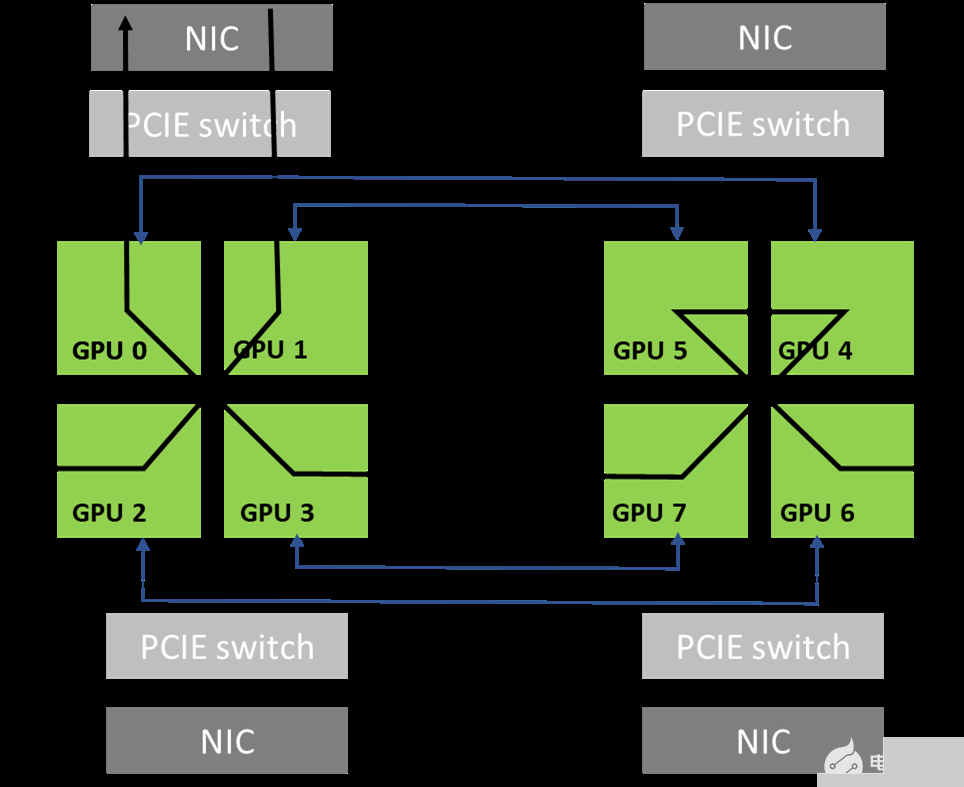
圖 5 。 NCCL 使用的環形路徑示例
通訊器只能包含 GPU 的一個子集。例如,它可以只包含 GPU 0 、 2 、 4 和 6 。在這種情況下,如果不穿過軌道,就不可能創建環:從 GPU 0 進入節點的環必須從 GPU 2 、 4 或 6 退出,這些環不能直接訪問 GPU 0 ( NIC 0 和 1 )的本地 NIC 。
另一方面, PXN 允許形成環,因為 GPU 2 可以在通過 NIC 0 / 1 之前將數據移回 GPU 0 。
這種情況在模型并行性中很常見,具體取決于模型的拆分方式。例如,如果一個模型在 GPU 0-3 之間拆分,則另一個模型在 GPU 4-7 上運行。這意味著 GPU 0 和 4 負責模型的同一部分,并且在所有節點上創建了一個 NCCL 通信器,其中包含所有 GPU 0 和 4 ,以執行相應層的所有 reduce 操作。沒有 PXN ,這些通訊器無法有效地執行所有 reduce 操作。
到目前為止,實現高效模型并行的唯一方法是在 GPU 0 , 2 , 4 , 6 和 1 , 3 , 5 , 7 上拆分模型,這樣 NCCL 子通信程序將包括 GPU [0 , 1]、[2 , 3]、[4 , 5]和[6 , 7],而不是[0 , 4]、[1 , 5]、[2 , 6]和[3 , 7]。新的 PXN 特性為您提供了更大的靈活性,并簡化了模型并行性的使用。
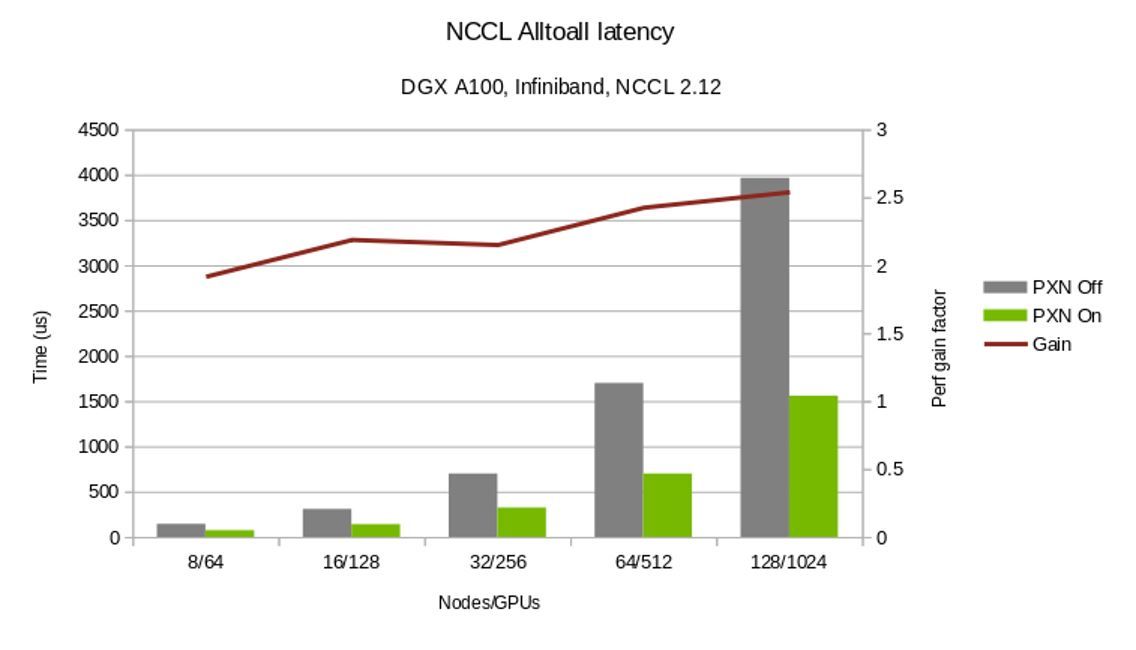
圖 6 。 NCCL 2.12 PXN 性能改進
圖 6 對比了在使用和不使用 PXN 的情況下完成所有集合操作的時間。此外, PXN 為所有 reduce 操作提供了更靈活的 GPU 選擇。
總結
NCCL 2.12 版本顯著提高了所有 2 所有通信集體性能。 Download 最新的 NCCL 版本,并親身體驗改進后的性能。
關于作者
Karthik Mandakolathur 是 NVIDIA Magnum IO 的產品經理,專注于加速分布式 AI 、數據分析和 HPC 應用。憑借 20 多年的行業經驗, Karthik 曾在 Broadcom 和 Cisco 擔任高級工程和產品職務。他在沃頓商學院獲得工商管理碩士學位,在斯坦福大學獲得工商管理碩士學位,在印度理工學院獲得工商管理學士學位。他在高性能交換架構領域擁有多項美國專利。
Sylvain Jeaugey 是 NVIDIA 的高級軟件工程師,自 2015 年創建 NCCL 庫以來一直在開發該庫。他在大規模分布式計算方面有 15 年的經驗。他一直致力于各種 MPI 實現,開發和集成高速網絡技術,并設計大型網絡結構。
審核編輯:郭婷
-
gpu
+關注
關注
28文章
4777瀏覽量
129362 -
人工智能
+關注
關注
1796文章
47683瀏覽量
240311
發布評論請先 登錄
相關推薦
dac8563中的Write to DAC-A input register and update all DACs中的 update all DACs具體是什么意思呀?
案例驗證:分析NCCL-Tests運行日志優化Scale-Out網絡拓撲


天合光能智慧光儲解決方案亮相All Energy展會
聯想集團公布下一階段Smarter AI for all愿景
高效先進的全功能工業級All-in-One觸控電腦解決方案

opensuse linux安裝好了交叉工具鏈并且設置了 IDF_PATH,make all的時候會報錯為什么?
一機實現All in one,NAS如何玩轉虛擬機!





 工商網監
工商網監
評論