") 華南理工開源VISTA:雙跨視角空間注意力機(jī)制實(shí)現(xiàn)3D目標(biāo)檢測SOTA
華南理工開源VISTA:雙跨視角空間注意力機(jī)制實(shí)現(xiàn)3D目標(biāo)檢測SOTA
本文提出了 VISTA,一種新穎的即插即用多視角融合策略,用于準(zhǔn)確的 3D 對象檢測。為了使 VISTA 能夠關(guān)注特定目標(biāo)而不是一般點(diǎn),研究者提出限制學(xué)習(xí)的注意力權(quán)重的方差。將分類和回歸任務(wù)解耦以處理不平衡訓(xùn)練問題。在 nuScenes 和 Waymo 數(shù)據(jù)集的基準(zhǔn)測試證明了 VISTA 方法的有效性和泛化能力。該論文已被CVPR 2022接收。
第一章 簡介 LiDAR (激光雷達(dá))是一種重要的傳感器,被廣泛用于自動駕駛場景中,以提供物體的精確 3D 信息。因此,基于 LiDAR 的 3D 目標(biāo)檢測引起了廣泛關(guān)注。許多 3D 目標(biāo)檢測算法通過將無序和不規(guī)則的點(diǎn)云進(jìn)行體素化,隨后利用卷積神經(jīng)網(wǎng)絡(luò)處理體素數(shù)據(jù)。然而,3D 卷積算子在計算上效率低下且容易消耗大量內(nèi)存。為了緩解這些問題,一系列工作利用稀疏 3D 卷積網(wǎng)絡(luò)作為 3D 骨干網(wǎng)絡(luò)來提取特征。如圖 1 所示,這些工作將 3D 特征圖投影到鳥瞰圖 (BEV) 或正視圖 (RV) 中,并且使用各種方法從這些 2D 特征圖生成對象候選 (Object Proposals)。
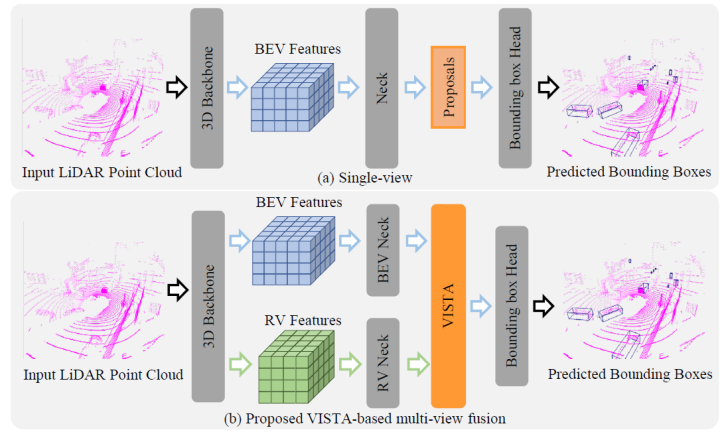
圖 1:單視角檢測和文章提出的基于 VISTA 的多視角融合檢測的對比 不同的視角有各自的優(yōu)缺點(diǎn)需要考慮。在 BEV 中,對象不相互重疊,每個對象的大小與距自我車輛 (ego-vehicle) 的距離無關(guān)。RV 是 LiDAR 點(diǎn)云的原生表征,因此,它可以產(chǎn)生緊湊和密集的特征。然而,無論是選擇 BEV 還是 RV,投影都會不可避免地?fù)p害 3D 空間中傳遞的空間信息的完整性。例如,由于 LiDAR 數(shù)據(jù)生成過程自身的特性和自遮擋效應(yīng),BEV 表征非常稀疏,并且它壓縮了 3D 點(diǎn)云的高度信息,在 RV 中,由于丟失了深度信息,遮擋和對象大小的變化會更加嚴(yán)重。顯然,從多個視角進(jìn)行聯(lián)合學(xué)習(xí),也就是多視角融合,為我們提供了準(zhǔn)確的 3D 目標(biāo)檢測的解決方案。先前的一些多視角融合算法從單個視角生成候選目標(biāo),并利用多視角特征來細(xì)化候選目標(biāo)。此類算法的性能高度依賴于生成的候選的質(zhì)量;但是,從單一視角生成的候選沒有使用所有可用信息,可能導(dǎo)致次優(yōu)解的產(chǎn)生。其他工作根據(jù)不同視角之間的坐標(biāo)投影關(guān)系融合多視角特征。這種融合方法的準(zhǔn)確性依賴于另一個視角的相應(yīng)區(qū)域中可提供的補(bǔ)充信息;然而遮擋效應(yīng)是不可避免的,這會導(dǎo)致低質(zhì)量的多視角特征融合產(chǎn)生。 為了提高 3D 目標(biāo)檢測的性能,在本文中,給定從 BEV 和 RV 學(xué)習(xí)到的 3D 特征圖,我們提出通過雙跨視角空間注意力機(jī)制 (VISTA) 從全局空間上下文中生成高質(zhì)量的融合多視角特征用于預(yù)測候選目標(biāo),如圖 1 所示。所提出的 VISTA 利用源自Transformer 的注意機(jī)制,其中 Transformer 已經(jīng)被成功應(yīng)用于各種研究環(huán)境(例如自然語言處理、2D 計算機(jī)視覺)中。與通過坐標(biāo)投影直接融合相比,VISTA 中內(nèi)置的注意力機(jī)制利用全局信息,通過將單個視角的特征視為特征元素序列,自適應(yīng)地對視角間的所有成對相關(guān)性進(jìn)行建模。為了全面建模跨視角相關(guān)性,必須考慮兩個視角中的局部信息,因此我們用卷積算子替換傳統(tǒng)注意力模塊中的 MLP,我們在實(shí)驗部分展示了這樣做的有效性。盡管如此,如實(shí)驗部分所示,學(xué)習(xí)視角之間的相關(guān)性仍然具有挑戰(zhàn)性。直接采用注意力機(jī)制進(jìn)行多視角融合帶來的收益很小,我們認(rèn)為這主要是由于 3D 目標(biāo)檢測任務(wù)本身的特性導(dǎo)致的。 一般來說,3D 目標(biāo)檢測任務(wù)可以分為兩個子任務(wù):分類和回歸。正如先前一些工作(LaserNet, CVCNet) 中所闡述的,3D 目標(biāo)檢測器在檢測整個 3D 場景中的物體時面臨許多挑戰(zhàn),例如遮擋、背景噪聲和點(diǎn)云缺乏紋理信息。因此,注意力機(jī)制很難學(xué)習(xí)到相關(guān)性,導(dǎo)致注意力機(jī)制傾向于取整個場景的均值,這是出乎意料的,因為注意力模塊是為關(guān)注感興趣的區(qū)域而設(shè)計的。因此,我們顯式地限制了注意力機(jī)制學(xué)習(xí)到的注意力圖 (Attention Map) 的方差,從而引導(dǎo)注意力模塊理解復(fù)雜的 3D 戶外場景中的有意義區(qū)域。此外,分類和回歸的不同學(xué)習(xí)目標(biāo)決定了注意力模塊中學(xué)習(xí)的 queries 和 keys 的不同期望。不同物體各自的回歸目標(biāo)(例如尺度、位移)期望 queries 和 keys 了解物體的特性。相反,分類任務(wù)推動網(wǎng)絡(luò)了解物體類的共性。不可避免地,共享相同的注意力建模會給這兩個任務(wù)的訓(xùn)練帶來沖突。此外,一方面,由于紋理信息的丟失,神經(jīng)網(wǎng)絡(luò)難以從點(diǎn)云中提取語義特征。另一方面,神經(jīng)網(wǎng)絡(luò)可以很容易地從點(diǎn)云中學(xué)習(xí)物體的幾何特性。這帶來的結(jié)果就是,在訓(xùn)練過程中,產(chǎn)生了以回歸為主導(dǎo)的困境。為了應(yīng)對這些挑戰(zhàn),我們在提出的 VISTA 中將這兩個任務(wù)解耦,以學(xué)習(xí)根據(jù)不同任務(wù)整合不同的線索。 我們提出的 VISTA 是一個即插即用的模塊,可以被用于近期的先進(jìn)的目標(biāo)分配 (Target Assignment) 策略中。我們在 nuScenes 和 Waymo 兩個基準(zhǔn)數(shù)據(jù)集上測試了提出的基于 VISTA 的多視角融合算法。在驗證集上的消融實(shí)驗證實(shí)了我們的猜想。提出的 VISTA 可以產(chǎn)生高質(zhì)量的融合特征,因此,我們提出的方法優(yōu)于所有已公布開源的算法。在提交時,我們的最終結(jié)果在 nuScenes 排行榜上的 mAP 和 NDS 達(dá)到 63.0% 和 69.8%。在 Waymo 上,我們在車輛、行人和騎自行車人上分別達(dá)到了 74.0%、72.5% 和 71.6% 的 2 級 mAPH。我們將我們的主要貢獻(xiàn)總結(jié)如下:
我們提出了一種新穎的即插即用融合模塊:雙跨視角空間注意力機(jī)制 (VISTA),以產(chǎn)生融合良好的多視角特征,以提高 3D 目標(biāo)檢測器的性能。我們提出的 VISTA 用卷積算子代替了 MLP,這能夠更好地處理注意力建模的局部線索。
我們將 VISTA 中的回歸和分類任務(wù)解耦,以利用單獨(dú)的注意力建模來平衡這兩個任務(wù)的學(xué)習(xí)。我們在訓(xùn)練階段將注意力方差約束應(yīng)用于 VISTA,這有助于注意力的學(xué)習(xí)并使網(wǎng)絡(luò)能夠關(guān)注感興趣的區(qū)域。
我們在 nuScenes 和 Waymo 兩個基準(zhǔn)數(shù)據(jù)集上進(jìn)行了徹底的實(shí)驗。我們提出的基于 VISTA 的多視角融合可用于各種先進(jìn)的目標(biāo)分配策略,輕松提升原始算法并在基準(zhǔn)數(shù)據(jù)集上實(shí)現(xiàn)最先進(jìn)的性能。具體來說,我們提出的方法在整體性能上比第二好的方法高出 4.5%,在騎自行車的人等安全關(guān)鍵對象類別上高出 24%。

論文鏈接:https://arxiv.org/abs/2203.09704
代碼鏈接:https://github.com/Gorilla-Lab-SCUT/VISTA
第二章 雙跨視角空間注意力機(jī)制 對于大多數(shù)基于體素的 3D 目標(biāo)檢測器,它們密集地產(chǎn)生逐 pillar 的目標(biāo)候選,經(jīng)驗上講,生成信息豐富的特征圖可以保證檢測質(zhì)量。在多視角 3D 目標(biāo)檢測的情況下,目標(biāo)候選來自融合的特征圖,因此需要在融合期間全面考慮全局空間上下文。為此,我們尋求利用注意力模塊捕獲全局依賴關(guān)系的能力進(jìn)行多視角融合,即跨視角空間注意力。在考慮全局上下文之前,跨視角空間注意力模塊需要聚合局部線索以構(gòu)建不同視角之間的相關(guān)性。因此,我們提出 VISTA,其中基于多層感知器 (MLP) 的標(biāo)準(zhǔn)注意力模塊被卷積層取代。然而,在復(fù)雜的 3D 場景中學(xué)習(xí)注意力是很困難的。為了采用跨視角注意力進(jìn)行多視角融合,我們進(jìn)一步解耦了 VISTA 中的分類和回歸任務(wù),并應(yīng)用提出的注意力約束來促進(jìn)注意力機(jī)制的學(xué)習(xí)過程。 在本節(jié)中,我們將首先詳細(xì)介紹所提出的雙跨視角空間注意力機(jī)制(VISTA)的整體架構(gòu),然后詳細(xì)闡述所提出的 VISTA 的解耦設(shè)計和注意力約束。 2.1 整體架構(gòu)
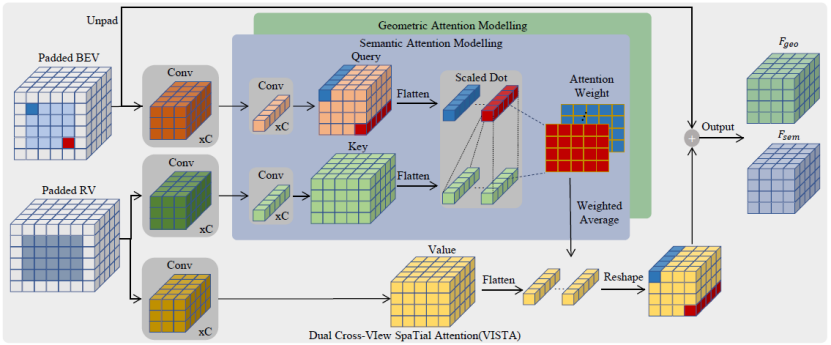
圖 2:VISTA 整體架構(gòu) 如圖 2 所示,VISTA 將來自兩個不同視角的特征序列作為輸入,并對多視角特征之間的跨視角相關(guān)性進(jìn)行建模。與使用線性投影轉(zhuǎn)換輸入特征序列的普通注意力模塊不同,VISTA 通過 3x3 卷積操作子將輸入特征序列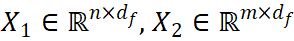 投影到 queries
投影到 queries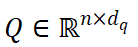 和
和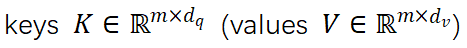 中。為了將分類和回歸解耦開,Q和K通過單獨(dú)的 MLP 投影到
中。為了將分類和回歸解耦開,Q和K通過單獨(dú)的 MLP 投影到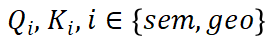 。為了計算V的加權(quán)和作為跨視角輸出F,我們應(yīng)用縮放的點(diǎn)積來獲得跨視角注意力權(quán)重
。為了計算V的加權(quán)和作為跨視角輸出F,我們應(yīng)用縮放的點(diǎn)積來獲得跨視角注意力權(quán)重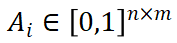 : ?
: ?
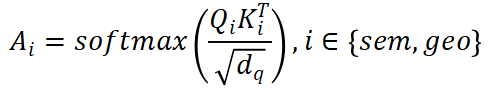
并且輸出將是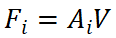 。輸出F_i將被饋送到單個前饋網(wǎng)絡(luò)以FFN_i獲得最終結(jié)果。我們采用先前工作中廣泛使用的架構(gòu)作為我們的 FFN,以確保非線性和多樣性。我們提出的 VISTA 是一種單階段方法,可根據(jù)跨視角融合的特征直接生成候選目標(biāo);這樣的設(shè)計可以利用更多信息進(jìn)行準(zhǔn)確高效的 3D 目標(biāo)檢測。 ?2.2 解耦分類和回歸任務(wù)? VISTA 將分類和回歸任務(wù)解耦。在共享卷積算子之后,queries 和 keys 通過單獨(dú)的線性投影進(jìn)一步處理產(chǎn)生Q_i和K_i,然后它們將根據(jù)語義信息或幾何信息參與不同的注意力建模。這種解耦的動機(jī)是分類和回歸的監(jiān)督信號對訓(xùn)練造成的不同影響。 ? 給定場景中的 query 目標(biāo),為了分類,注意力模塊需要從全局上下文中的對象中聚合語義線索,以豐富融合特征中傳達(dá)的語義信息。這樣的目標(biāo)要求學(xué)習(xí)的 queries 和 keys 知道同一類別的不同對象之間的共性,以使同一類別的對象在語義上應(yīng)該相互匹配。然而,回歸任務(wù)不能采用相同的 queries 和 keys,因為不同的對象有自己的幾何特征(例如位移、尺度、速度等),回歸特征應(yīng)該在不同的對象上是多樣的。因此,在分類和回歸的聯(lián)合訓(xùn)練過程中,共享相同的 queries 和 keys 會導(dǎo)致注意力學(xué)習(xí)發(fā)生沖突。 ? 此外,無論是單視角還是多視角,分類和回歸結(jié)果都是從傳統(tǒng)的基于體素的 3D 目標(biāo)檢測器中的相同特征圖預(yù)測的。然而,由于 3D 場景的固有屬性,3D 點(diǎn)云中不可避免地存在遮擋和紋理信息丟失,3D 檢測器難以提取語義特征,給分類學(xué)習(xí)帶來很大挑戰(zhàn)。相反,3D 點(diǎn)云傳達(dá)的豐富幾何信息減輕了網(wǎng)絡(luò)理解物體幾何屬性的負(fù)擔(dān),這是學(xué)習(xí)回歸任務(wù)的基礎(chǔ)。結(jié)果,在網(wǎng)絡(luò)訓(xùn)練過程中,出現(xiàn)了分類和回歸之間學(xué)習(xí)的不平衡現(xiàn)象,其中分類的學(xué)習(xí)被回歸主導(dǎo)。這種不平衡的學(xué)習(xí)是基于 3D 點(diǎn)云的,包含分類和回歸任務(wù)的 3D 目標(biāo)檢測中的常見問題,這將對檢測性能產(chǎn)生負(fù)面影響。具體來說,3D 檢測器在具有相似幾何特征的不同對象類別(例如卡車和公共汽車)上不會很魯棒。 ? 為了緩解上述問題,我們分別為語義和幾何信息分別建立注意力模型。注意力模塊的輸出是基于構(gòu)建的語義和幾何注意力權(quán)重的
。輸出F_i將被饋送到單個前饋網(wǎng)絡(luò)以FFN_i獲得最終結(jié)果。我們采用先前工作中廣泛使用的架構(gòu)作為我們的 FFN,以確保非線性和多樣性。我們提出的 VISTA 是一種單階段方法,可根據(jù)跨視角融合的特征直接生成候選目標(biāo);這樣的設(shè)計可以利用更多信息進(jìn)行準(zhǔn)確高效的 3D 目標(biāo)檢測。 ?2.2 解耦分類和回歸任務(wù)? VISTA 將分類和回歸任務(wù)解耦。在共享卷積算子之后,queries 和 keys 通過單獨(dú)的線性投影進(jìn)一步處理產(chǎn)生Q_i和K_i,然后它們將根據(jù)語義信息或幾何信息參與不同的注意力建模。這種解耦的動機(jī)是分類和回歸的監(jiān)督信號對訓(xùn)練造成的不同影響。 ? 給定場景中的 query 目標(biāo),為了分類,注意力模塊需要從全局上下文中的對象中聚合語義線索,以豐富融合特征中傳達(dá)的語義信息。這樣的目標(biāo)要求學(xué)習(xí)的 queries 和 keys 知道同一類別的不同對象之間的共性,以使同一類別的對象在語義上應(yīng)該相互匹配。然而,回歸任務(wù)不能采用相同的 queries 和 keys,因為不同的對象有自己的幾何特征(例如位移、尺度、速度等),回歸特征應(yīng)該在不同的對象上是多樣的。因此,在分類和回歸的聯(lián)合訓(xùn)練過程中,共享相同的 queries 和 keys 會導(dǎo)致注意力學(xué)習(xí)發(fā)生沖突。 ? 此外,無論是單視角還是多視角,分類和回歸結(jié)果都是從傳統(tǒng)的基于體素的 3D 目標(biāo)檢測器中的相同特征圖預(yù)測的。然而,由于 3D 場景的固有屬性,3D 點(diǎn)云中不可避免地存在遮擋和紋理信息丟失,3D 檢測器難以提取語義特征,給分類學(xué)習(xí)帶來很大挑戰(zhàn)。相反,3D 點(diǎn)云傳達(dá)的豐富幾何信息減輕了網(wǎng)絡(luò)理解物體幾何屬性的負(fù)擔(dān),這是學(xué)習(xí)回歸任務(wù)的基礎(chǔ)。結(jié)果,在網(wǎng)絡(luò)訓(xùn)練過程中,出現(xiàn)了分類和回歸之間學(xué)習(xí)的不平衡現(xiàn)象,其中分類的學(xué)習(xí)被回歸主導(dǎo)。這種不平衡的學(xué)習(xí)是基于 3D 點(diǎn)云的,包含分類和回歸任務(wù)的 3D 目標(biāo)檢測中的常見問題,這將對檢測性能產(chǎn)生負(fù)面影響。具體來說,3D 檢測器在具有相似幾何特征的不同對象類別(例如卡車和公共汽車)上不會很魯棒。 ? 為了緩解上述問題,我們分別為語義和幾何信息分別建立注意力模型。注意力模塊的輸出是基于構(gòu)建的語義和幾何注意力權(quán)重的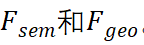 。分類和回歸的監(jiān)督分別應(yīng)用于
。分類和回歸的監(jiān)督分別應(yīng)用于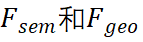 ,保證了相應(yīng)任務(wù)的有效學(xué)習(xí)。 ?2.3 注意力約束? 當(dāng)學(xué)習(xí)從全局上下文中對跨視角相關(guān)性進(jìn)行建模時,所提出的 VISTA 面臨著許多挑戰(zhàn)。3D 場景包含大量背景點(diǎn)(大約高達(dá) 95%),只有一小部分是有助于檢測結(jié)果的興趣點(diǎn)。在跨視角注意力的訓(xùn)練過程中,海量的背景點(diǎn)會給注意力模塊帶來意想不到的噪音。此外,復(fù)雜 3D 場景中的遮擋效應(yīng)給注意力學(xué)習(xí)帶來了不可避免的失真。因此,注意力模塊傾向于關(guān)注不相關(guān)的區(qū)域。注意力學(xué)習(xí)不佳的極端情況是全局平均池化(GAP)操作,正如我們在實(shí)驗部分中所展示的,沒有任何明確的監(jiān)督,直接采用注意力模塊進(jìn)行多視角融合會產(chǎn)生類似于 GAP 的性能,這表明注意力模塊不能很好地對跨視角相關(guān)性建模。 ? 為了使注意力模塊能夠?qū)W⒂谔囟繕?biāo)而不是一般的點(diǎn),我們提出對學(xué)習(xí)的注意力權(quán)重的方差施加約束。利用提出的約束,我們使網(wǎng)絡(luò)能夠?qū)W習(xí)注意到特定目標(biāo)。通過將注意力方差約束與傳統(tǒng)的分類回歸監(jiān)督信號相結(jié)合,注意力模塊專注于場景中有意義的目標(biāo),從而產(chǎn)生高質(zhì)量的融合特征。我們將提出的約束設(shè)定為訓(xùn)練期間的輔助損失函數(shù)。為簡單起見,我們忽略 batch 維度,給定學(xué)習(xí)的注意力權(quán)重
,保證了相應(yīng)任務(wù)的有效學(xué)習(xí)。 ?2.3 注意力約束? 當(dāng)學(xué)習(xí)從全局上下文中對跨視角相關(guān)性進(jìn)行建模時,所提出的 VISTA 面臨著許多挑戰(zhàn)。3D 場景包含大量背景點(diǎn)(大約高達(dá) 95%),只有一小部分是有助于檢測結(jié)果的興趣點(diǎn)。在跨視角注意力的訓(xùn)練過程中,海量的背景點(diǎn)會給注意力模塊帶來意想不到的噪音。此外,復(fù)雜 3D 場景中的遮擋效應(yīng)給注意力學(xué)習(xí)帶來了不可避免的失真。因此,注意力模塊傾向于關(guān)注不相關(guān)的區(qū)域。注意力學(xué)習(xí)不佳的極端情況是全局平均池化(GAP)操作,正如我們在實(shí)驗部分中所展示的,沒有任何明確的監(jiān)督,直接采用注意力模塊進(jìn)行多視角融合會產(chǎn)生類似于 GAP 的性能,這表明注意力模塊不能很好地對跨視角相關(guān)性建模。 ? 為了使注意力模塊能夠?qū)W⒂谔囟繕?biāo)而不是一般的點(diǎn),我們提出對學(xué)習(xí)的注意力權(quán)重的方差施加約束。利用提出的約束,我們使網(wǎng)絡(luò)能夠?qū)W習(xí)注意到特定目標(biāo)。通過將注意力方差約束與傳統(tǒng)的分類回歸監(jiān)督信號相結(jié)合,注意力模塊專注于場景中有意義的目標(biāo),從而產(chǎn)生高質(zhì)量的融合特征。我們將提出的約束設(shè)定為訓(xùn)練期間的輔助損失函數(shù)。為簡單起見,我們忽略 batch 維度,給定學(xué)習(xí)的注意力權(quán)重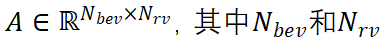 分別是 BEV 和 RV 中的 pillar 數(shù)量,xy 平面中 GT 框的尺度和中心位置的集合
分別是 BEV 和 RV 中的 pillar 數(shù)量,xy 平面中 GT 框的尺度和中心位置的集合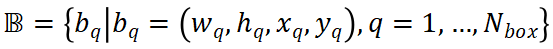 ,其中
,其中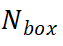 是場景中的框數(shù)量。對于 BEV 中的每個 pillar,我們根據(jù)體素大小計算其中心的真實(shí)坐標(biāo),并得到集合
是場景中的框數(shù)量。對于 BEV 中的每個 pillar,我們根據(jù)體素大小計算其中心的真實(shí)坐標(biāo),并得到集合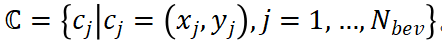 。每個 GT 框的注意力權(quán)重通過以下方式獲得: ?
。每個 GT 框的注意力權(quán)重通過以下方式獲得: ?
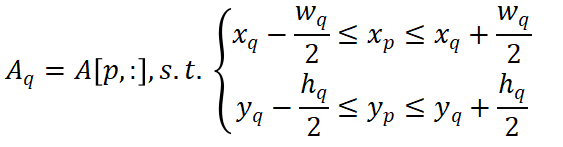
然后我們?yōu)樗?GT 框制定方差約束如下:
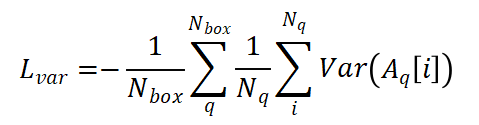
其中N_q是b_q由包圍的 pillar 的數(shù)量,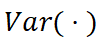 計算給定向量的方差。 ?第三章 實(shí)現(xiàn)?3.1 體素化? 我們根據(jù) x,y,z 軸對點(diǎn)云進(jìn)行體素化。對于 nuScenes 數(shù)據(jù)集,體素化的范圍是[-51.2, 51.2]m, [-51.2,51.2]m 和[-5.0,3]m,以 x,y,z 表示。對于 Waymo 數(shù)據(jù)集,范圍為[-75.2,75.2]m、[-75.2,75.2]m 和[-2,4]m。除非特別提及,否則我們所有的實(shí)驗都是在 x、y、z 軸的[0.1,0.1,0.1]m 的低體素化分辨率下進(jìn)行的。 ?3.2 數(shù)據(jù)增廣? 點(diǎn)云根據(jù) x,y 軸隨機(jī)翻轉(zhuǎn),圍繞 z 軸旋轉(zhuǎn),范圍為[-0.3925,0.3925]rad,縮放系數(shù)范圍為 0.95 到 1.05,平移范圍為[ 0.2,0.2,0.2]m 在 x,y,z 軸上。采用類別平衡分組采樣和數(shù)據(jù)庫采樣來提高訓(xùn)練時正樣本的比例。 ?3.3 聯(lián)合訓(xùn)練? 我們在各種目標(biāo)分配策略 (CBGS, OHS, CenterPoint) 上訓(xùn)練 VISTA。為了訓(xùn)練網(wǎng)絡(luò),我們計算不同目標(biāo)分配策略的原始損失函數(shù),我們建議讀者參考他們的論文以了解更多關(guān)于損失函數(shù)的細(xì)節(jié)。簡而言之,我們將分類和回歸考慮在內(nèi): ?
計算給定向量的方差。 ?第三章 實(shí)現(xiàn)?3.1 體素化? 我們根據(jù) x,y,z 軸對點(diǎn)云進(jìn)行體素化。對于 nuScenes 數(shù)據(jù)集,體素化的范圍是[-51.2, 51.2]m, [-51.2,51.2]m 和[-5.0,3]m,以 x,y,z 表示。對于 Waymo 數(shù)據(jù)集,范圍為[-75.2,75.2]m、[-75.2,75.2]m 和[-2,4]m。除非特別提及,否則我們所有的實(shí)驗都是在 x、y、z 軸的[0.1,0.1,0.1]m 的低體素化分辨率下進(jìn)行的。 ?3.2 數(shù)據(jù)增廣? 點(diǎn)云根據(jù) x,y 軸隨機(jī)翻轉(zhuǎn),圍繞 z 軸旋轉(zhuǎn),范圍為[-0.3925,0.3925]rad,縮放系數(shù)范圍為 0.95 到 1.05,平移范圍為[ 0.2,0.2,0.2]m 在 x,y,z 軸上。采用類別平衡分組采樣和數(shù)據(jù)庫采樣來提高訓(xùn)練時正樣本的比例。 ?3.3 聯(lián)合訓(xùn)練? 我們在各種目標(biāo)分配策略 (CBGS, OHS, CenterPoint) 上訓(xùn)練 VISTA。為了訓(xùn)練網(wǎng)絡(luò),我們計算不同目標(biāo)分配策略的原始損失函數(shù),我們建議讀者參考他們的論文以了解更多關(guān)于損失函數(shù)的細(xì)節(jié)。簡而言之,我們將分類和回歸考慮在內(nèi): ?
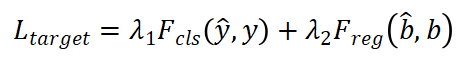
其中λ_1和λ_2是損失函數(shù)權(quán)重,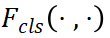 是 GT 標(biāo)簽y和
是 GT 標(biāo)簽y和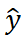 預(yù)測之間的分類損失函數(shù),
預(yù)測之間的分類損失函數(shù),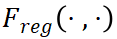 是 GT 框b和預(yù)測框
是 GT 框b和預(yù)測框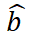 的回歸損失函數(shù)。 ? 總損失函數(shù)L是
的回歸損失函數(shù)。 ? 總損失函數(shù)L是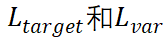 的加權(quán)和:
的加權(quán)和: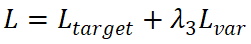 。我們將λ_1、λ_2和λ_3設(shè)置為 1.0、0.25、1.0。我們將 Focal loss 作為
。我們將λ_1、λ_2和λ_3設(shè)置為 1.0、0.25、1.0。我們將 Focal loss 作為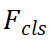 ,并將 L1 損失作為
,并將 L1 損失作為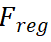 。 ?第四章 實(shí)驗
。 ?第四章 實(shí)驗
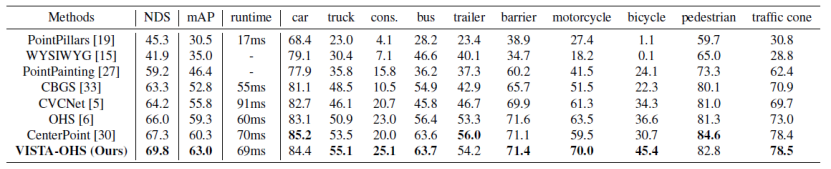
表一:nuScenes 測試集上的 3D 檢測結(jié)果
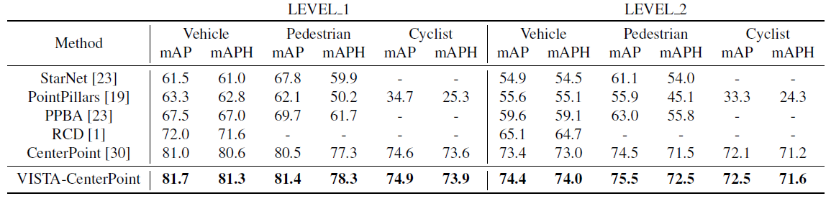
表二:Waymo 測試集上的 3D 檢測結(jié)果 我們在 nuScenes 數(shù)據(jù)集和 Waymo 數(shù)據(jù)集上評估 VISTA。我們在三種具有不同目標(biāo)分配策略的最先進(jìn)方法上測試 VISTA 的功效:CBGS、OHS 和 CenterPoint。 4.1 數(shù)據(jù)集和技術(shù)細(xì)節(jié) nuScenes 數(shù)據(jù)集包含 700 個訓(xùn)練場景、150 個驗證場景和 150 個測試場景。數(shù)據(jù)集以 2Hz 進(jìn)行標(biāo)注,總共 40000 個關(guān)鍵幀被標(biāo)注了 10 個對象類別。我們?yōu)槊總€帶標(biāo)注的關(guān)鍵幀組合 10 幀掃描點(diǎn)云以增加點(diǎn)數(shù)。平均精度 (mAP) 和 nuScenes 檢測分?jǐn)?shù) (NDS) 被應(yīng)用于我們的性能評估。NDS 是 mAP 和其他屬性度量的加權(quán)平均值,包括位移、尺度、方向、速度和其他框的屬性。在訓(xùn)練過程中,我們遵循 CBGS 通過 Adam 優(yōu)化器和單周期學(xué)習(xí)率策略 (one-cycle) 優(yōu)化模型。 Waymo 數(shù)據(jù)集包含 798 個用于訓(xùn)練的序列,202 個用于驗證的序列。每個序列的持續(xù)時間為 20 秒,并以 10Hz 的頻率采樣,使用 64 通道的激光雷達(dá),包含 610 萬車輛、280 萬行人和 6.7 萬個騎自行車的人。我們根據(jù)標(biāo)準(zhǔn) mAP 和由航向精度 (mAPH) 加權(quán)的 mAP 指標(biāo)來評估我們的網(wǎng)絡(luò),這些指標(biāo)基于車輛的 IoU 閾值為 0.7,行人和騎自行車的人為 0.5。官方評估協(xié)議以兩個難度級別評估方法:LEVEL_1 用于具有超過 5 個 LiDAR 點(diǎn)的框,LEVEL_2 用于具有至少一個 LiDAR 點(diǎn)的框。 4.2 與其他方法的比較 我們將提出的基于 VISTA 的 OHS 的測試結(jié)果提交給 nuScenes 測試服務(wù)器。為了對結(jié)果進(jìn)行基準(zhǔn)測試,我們遵循 CenterPoint 來調(diào)整訓(xùn)練分辨率并利用雙翻轉(zhuǎn)測試增強(qiáng)。由于我們的結(jié)果基于單一模型,因此我們的比較中不包括使用集成模型和額外數(shù)據(jù)的方法,測試性能見表一。我們提出的 VISTA 在 nuScenes 測試集上實(shí)現(xiàn)了最先進(jìn)的性能,在整體 mAP 和 NDS 中都大大優(yōu)于所有已發(fā)布的方法。特別是在摩托車和自行車上的表現(xiàn),mAP 上超過了第二好的方法 CenterPoint 高達(dá) 48%。具體來說,幾何相似類別(例如卡車、工程車輛)的性能提升證實(shí)了我們提出的解耦設(shè)計的有效性。 為了進(jìn)一步驗證我們提出的 VISTA 的有效性,我們將提出的 VISTA 應(yīng)用在 CenterPoint 上,并將測試結(jié)果提交到 Waymo 測試服務(wù)器。在訓(xùn)練和測試期間,我們遵循與 CenterPoint 完全相同的規(guī)則,測試性能見表二。VISTA 在所有級別的所有類別中為 CenterPoint 帶來了顯著改進(jìn),優(yōu)于所有已發(fā)布的結(jié)果。 4.3 消融學(xué)習(xí)
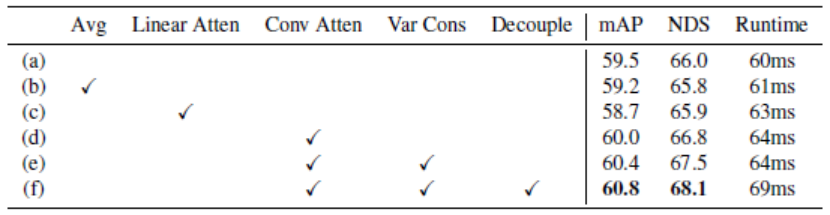
表三:多視角融合消融學(xué)習(xí),實(shí)驗在 nuScenes 驗證集上進(jìn)行

表四:基于 VISTA 的先進(jìn)方法的性能提升,實(shí)驗在 nuScenes 驗證集上進(jìn)行 如表三所示,為了證明所提出的 VISTA 的優(yōu)越性,我們以 OHS 作為我們的基線 (a) 在 nuScenes 數(shù)據(jù)集的驗證集上進(jìn)行了消融研究。正如前文所述,如果沒有注意力約束,注意力權(quán)重學(xué)習(xí)的極端情況將是全局平均池化(GAP)。為了澄清,我們通過 GAP 手動獲取 RV 特征,并將它們添加到所有 BEV 特征上實(shí)現(xiàn)融合。這種基于 GAP 的融合方法 (b) 將基線的性能 mAP 降低到 59.2%,表明自適應(yīng)融合來自全局空間上下文的多視角特征的必要性。直接采用 VISTA 進(jìn)行多視角融合 (d),mAP 為 60.0%。當(dāng)將卷積注意力模塊替換為傳統(tǒng)的線性注意力模塊(c) 時,整體 mAP 下降到 58.7%,這反映了聚合局部線索對于構(gòu)建跨視角注意力的重要性。在添加提出的注意力方差約束后,如 (e) 所示,整體 mAP 的性能提高到 60.4%。從 (d) 到(e)行的性能提升表明注意力機(jī)制可以通過注意力約束得到很好的引導(dǎo),使得注意力模塊能夠關(guān)注整個場景的興趣區(qū)域。然而,共享注意力建模會帶來分類學(xué)習(xí)和回歸任務(wù)之間的沖突,在 3D 目標(biāo)檢測中,分類任務(wù)將被回歸任務(wù)占主導(dǎo)地位。如(f)所示,在解耦注意力模型后,整體 mAP 的性能從 60.4% 提高到 60.8%,進(jìn)一步驗證了我們的假設(shè)。 所提出的 VISTA 是一種即插即用的多視角融合方法,只需稍作修改即可用于各種最近提出的先進(jìn)目標(biāo)分配策略。為了證明所提出的 VISTA 的有效性和泛化能力,我們在 CenterPoint、OHS 和 CBGS 上實(shí)現(xiàn)了 VISTA,它們是最近的先進(jìn)方法。這些方法代表基于 anchor 或 anchor-free 的不同主流目標(biāo)分配。我們在 nuScenes 數(shù)據(jù)集的驗證集上評估結(jié)果,所有方法都是基于他們的官方代碼庫。如表四所示,所有三個目標(biāo)分配策略在 mAP 和 NDS 分?jǐn)?shù)中都實(shí)現(xiàn)了很大的性能提升(在 mAP 和 NDS 中分別約為 1.3% 和 1.4%),表明所提出的 VISTA 可以通過跨視角空間注意力機(jī)制融合普遍高質(zhì)量的多視角特征。 我們在表三中展示了提出的 VISTA 在一個 RTX3090 GPU 上的運(yùn)行時間。未經(jīng)任何修改,基線 (a) 以每幀 60 毫秒運(yùn)行。在基線中采用卷積注意力模塊 (d) 后,運(yùn)行時間增加到 64 毫秒。我們可以從 (e) 和(f)中觀察到,雖然應(yīng)用所提出的注意力方差約束不會影響推理速度,但解耦設(shè)計花費(fèi)了 5ms,但額外的延遲仍然可以忽略不計。以這樣的效率運(yùn)行,我們認(rèn)為所提出的 VISTA 完全符合實(shí)際應(yīng)用的要求。 4.4 VISTA 分析

圖 3:具有((a)和(c))和沒有((b)和(d))注意方差約束的 VISTA 學(xué)習(xí)到的注意力權(quán)重的可視化。每行呈現(xiàn)一個場景,Query 框以紅色顯示,點(diǎn)的顏色越亮,點(diǎn)的注意力權(quán)重越高。
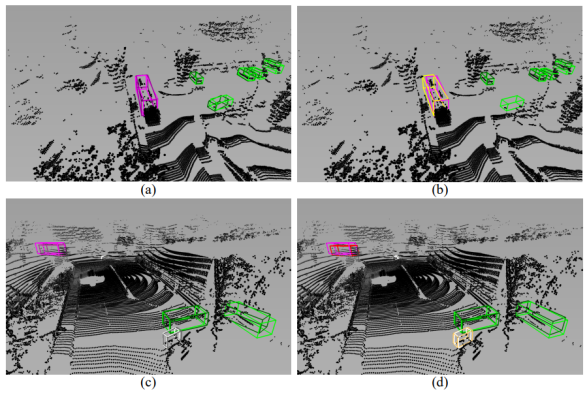
圖 4:在有和沒有解耦設(shè)計的情況下的檢測結(jié)果的可視化。每行代表一個場景。淺色表示的框指的是 GT 框,深色表示的框表示正確的預(yù)測結(jié)果,不同強(qiáng)調(diào)色表示的框表示錯誤的預(yù)測。 我們認(rèn)為,通過所提出的注意力約束訓(xùn)練的 VISTA 可以捕捉 BEV 和 RV 之間的全局和局部相關(guān)性,從而可以有效地執(zhí)行多視角融合以進(jìn)行準(zhǔn)確的框預(yù)測。為了生動地展示注意力方差約束在訓(xùn)練 VISTA 中的有效性,我們在圖 3 中可視化了網(wǎng)絡(luò)在有和沒有注意力方差約束情況下構(gòu)建的的跨視角相關(guān)性。給定包含目標(biāo)視角(BEV)的框的區(qū)域以 query 源視角(RV),我們得到上述區(qū)域中每個 pillar 的相應(yīng)跨視角注意力權(quán)重,并將權(quán)重映射回原點(diǎn)云以可視化。我們觀察到,在沒有注意力方差約束的情況下,學(xué)習(xí)到的注意力權(quán)重對于 RV 中的幾乎每個 pillar 都保持較小的值,從而導(dǎo)致近似的全局平均池化操作。在圖 3(b)和 (d) 中,注意力模塊關(guān)注遠(yuǎn)離 query 汽車和行人的背景點(diǎn),每個聚焦區(qū)域的注意力權(quán)重相對較低。相反,用注意力方差約束訓(xùn)練的注意力模塊突出顯示具有相同 query 類別的物體,如圖 3(a)和 (c) 所示。特別是對于 query 汽車,通過注意力方差約束訓(xùn)練的注意力模塊成功地關(guān)注了場景中的其他汽車。 我們提出的 VISTA 的另一個關(guān)鍵設(shè)計是分類和回歸任務(wù)的解耦。這兩個任務(wù)的各自的注意力建模緩解了學(xué)習(xí)的不平衡問題,因此檢測結(jié)果更加準(zhǔn)確和可靠。為了展示我們設(shè)計的意義,我們在圖中展示了解耦前后的檢測結(jié)果。每行代表一個場景,左列顯示解耦后的結(jié)果,另一列顯示未解耦的結(jié)果。如圖 4(b)和 (d) 所示,沒有解耦設(shè)計的 3D 目標(biāo)檢測器很容易將物體 A 誤認(rèn)為具有相似幾何特性的另一個物體 B,我們將這種現(xiàn)象稱為 A-to-B,例如公共汽車(紫色)到卡車(黃色)、公共汽車(紫色)到拖車(紅色)和自行車(白色)到摩托車(橙色),證明了分類和回歸任務(wù)之間存在不平衡訓(xùn)練。此外,當(dāng)將右列與左列進(jìn)行比較時,混淆的預(yù)測并不準(zhǔn)確。相反,具有解耦設(shè)計的 VISTA 成功區(qū)分了對象的類別,并預(yù)測了緊密的框,如圖 4(a)和 (c) 所示,證明了所提出的解耦設(shè)計的功效。 第五章 總結(jié) 在本文中,我們提出了 VISTA,一種新穎的即插即用多視角融合策略,用于準(zhǔn)確的 3D 對象檢測。為了使 VISTA 能夠關(guān)注特定目標(biāo)而不是一般點(diǎn),我們提出限制學(xué)習(xí)的注意力權(quán)重的方差。我們將分類和回歸任務(wù)解耦以處理不平衡訓(xùn)練問題。我們提出的即插即用 VISTA 能夠產(chǎn)生高質(zhì)量的融合特征來預(yù)測目標(biāo)候選,并且可以應(yīng)用于各種目標(biāo)分配策略方法。nuScenes 和 Waymo 數(shù)據(jù)集的基準(zhǔn)測試證明了我們提出的方法的有效性和泛化能力。
審核編輯 :李倩
-
傳感器
+關(guān)注
關(guān)注
2553文章
51407瀏覽量
756657 -
Vista
+關(guān)注
關(guān)注
0文章
28瀏覽量
19678 -
目標(biāo)檢測
+關(guān)注
關(guān)注
0文章
211瀏覽量
15664
原文標(biāo)題:CVPR 2022 | 即插即用!華南理工開源VISTA:雙跨視角空間注意力機(jī)制實(shí)現(xiàn)3D目標(biāo)檢測SOTA
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
開源項目!3D打印的遠(yuǎn)程控制雙速全驅(qū)汽車
TechWiz LCD 3D應(yīng)用:賓主液晶
一種基于因果路徑的層次圖卷積注意力網(wǎng)絡(luò)

關(guān)于\"OPA615\"的SOTA的跨導(dǎo)大小的疑問求解
海康微影DV式手持測溫?zé)嵯駜x助力提升科研效率
安寶特產(chǎn)品 安寶特3D Analyzer:智能的3D CAD高級分析工具
蘇州吳中區(qū)多色PCB板元器件3D視覺檢測技術(shù)

天馬微電子首發(fā)TIANMA META SIGHT光場3D解決方案

VR虛擬空間中的3D 技術(shù)
采用單片超構(gòu)表面與元注意力網(wǎng)絡(luò)實(shí)現(xiàn)快照式近紅外光譜成像

木幾智能接待華南理工大學(xué)自動化科學(xué)與工程學(xué)院開展校企合作交流活動

新質(zhì)生產(chǎn)力探索| AICG浪潮下的3D打印與3D掃描技術(shù)
Stability AI推出Stable Video 3D模型,可制作多視角3D視頻
裸眼3D頻頻“出圈” 電信積極布局并發(fā)力裸眼3D領(lǐng)域
Nullmax提出多相機(jī)3D目標(biāo)檢測新方法QAF2D





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論