") 如何在OCI Ampere A1上啟動(dòng)計(jì)算密集AI應(yīng)用程序
如何在OCI Ampere A1上啟動(dòng)計(jì)算密集AI應(yīng)用程序
本文將向您展示如何在 OCI Ampere A1 上準(zhǔn)備和啟動(dòng)計(jì)算密集的 AI 應(yīng)用程序。
使用 Ampere A1,我們將發(fā)揮 Ampere Altra 處理器和 Ampere AIO 一流的 AI 推理性能。
我將使用此 Github 中的演練/腳本(請(qǐng)注意,這些腳本也將在我們將創(chuàng)建的實(shí)例上)。此外,如果您想繼續(xù),您需要 Ampere A1 實(shí)例 - 可以在 OCI 上免費(fèi)創(chuàng)建。
創(chuàng)建免費(fèi)的 Ampere VM
首先,我將創(chuàng)建 Ampere A1 的單個(gè)實(shí)例。該實(shí)例使用 VM.Standard.A 1.Flex 并具有 4 個(gè) OCPU 和 24 GB 內(nèi)存。
“根據(jù) Oracle 的定價(jià)頁,Oracle CPU (OCPU) 計(jì)費(fèi)單元實(shí)際上是處理器的一個(gè)物理內(nèi)核。一個(gè)開啟超線程的 CPU,對(duì)應(yīng)的是兩個(gè)硬件執(zhí)行線程,即所謂的 vCPU。而對(duì)于 A1 實(shí)例,一個(gè) OCPU 就是一個(gè) vCPU。”
打開導(dǎo)航菜單并選擇計(jì)算和實(shí)例以創(chuàng)建計(jì)算實(shí)例,您可以選擇 Running Hugo 文章中使用的相同的隔層或在實(shí)例頁面上創(chuàng)建新隔層。
單擊創(chuàng)建實(shí)例按鈕打開創(chuàng)建頁面,創(chuàng)建新實(shí)例。創(chuàng)建頁面上有多個(gè)部分。但是,我們只會(huì)更改其中的幾個(gè)。
首先,您可以將隨機(jī)生成的名稱更改為更易于使用的名稱,例如 ai- vm。以下內(nèi)容是 Placement——我們可以在此處保留默認(rèn)值,但您可以為實(shí)例選擇不同的可用性域(AD) 和故障域(FD)。最后,將默認(rèn)設(shè)置 Always Free-eligible 可用性域。
選擇圖像和形狀
下一部分稱為 Image and Shape(圖像和形狀),我們將在這里選擇實(shí)例形態(tài)(實(shí)例形態(tài)是 GCP 中的機(jī)器類型和 Azure 中的 VM 大小)和計(jì)算實(shí)例的操作系統(tǒng)映像。
1
單擊 Change shape 按鈕以選擇不同的 VM 實(shí)例形態(tài),確保您已選擇虛擬機(jī)的實(shí)例類型。您可以在下一行中選擇形態(tài)系列。我們正在尋找包含基于 ARM 的處理器和名為 VM.Standard.A 1.Flex 的形態(tài)名稱的 Ampere 系列(它應(yīng)該是此視圖中唯一可用的形狀)
2
選擇 VM.Standard.A 1.Flex ,將 OCPU 數(shù)量調(diào)整為 4,并將內(nèi)存量調(diào)整為 24 GB。完成此項(xiàng)操作后,我們將能夠永久免費(fèi)使用這一規(guī)格。
3
單擊 Select shape 按鈕以確認(rèn)選擇。
4
單擊 Change image 按鈕。然后讓我們?yōu)樾螤瞰@取正確的鏡像。
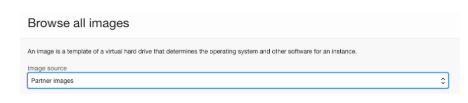
選擇鏡像
5
在下拉菜單中選擇 Partner Image 。然后在搜索框中,輸入 Ampere 。您將看到可用于 Ampere A1 形狀的可用鏡像。
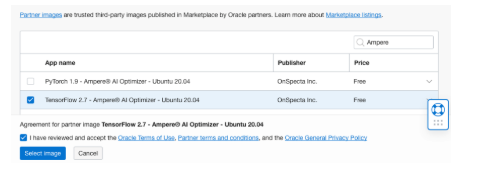
Ampere Tensorflow 鏡像
6
選中Tensorflow 2.7 – Ampere AI Optimizer – Ubuntu 20.04 框和以下復(fù)選框以同意“Terms of Use(使用條款)”。然后,單擊 Select Image 按鈕。您應(yīng)該會(huì)看到選定的 shape 和 image 框,如下圖所示。
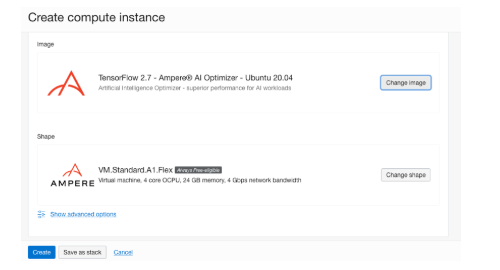
Tensorflow 2.7 – Ampere AI Optimizer – 已選擇 Ubuntu 20.04 鏡像
添加 SSH 密鑰
我們還想稍后使用 SSH 密鑰連接到實(shí)例。您可以選擇創(chuàng)建新的 SSH 密鑰對(duì)或上傳/粘貼一個(gè)或多個(gè)現(xiàn)有公鑰文件。
如果您正在生成新的 SSH 密鑰對(duì),請(qǐng)確保單擊 Save Private Key 按鈕以保存生成的密鑰。
“注意:您必須將 SSH 密鑰文件的權(quán)限設(shè)置為 400。您可以運(yùn)行 chmod 400 < keyfile > 來執(zhí)行此操作。”
創(chuàng)建 AI 實(shí)例
我們不會(huì)更改任何其他設(shè)置,因此讓我們單擊 Create 按鈕來創(chuàng)建實(shí)例。
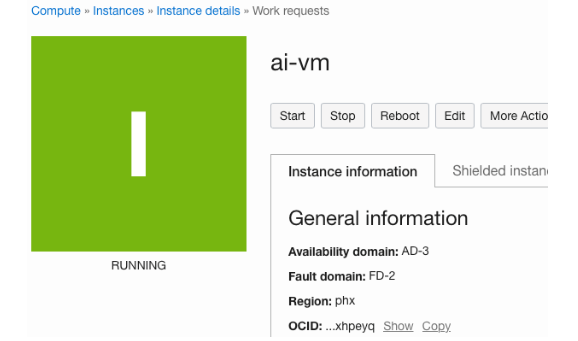
創(chuàng)建 AI 實(shí)例
幾分鐘后,OCI 會(huì)創(chuàng)建實(shí)例,并且實(shí)例的狀態(tài)會(huì)從配置變?yōu)檫\(yùn)行。
連接到實(shí)例
要連接到實(shí)例,我們將使用實(shí)例的公共 IP 地址和我們?cè)O(shè)置的 SSH 密鑰。
您可以從實(shí)例頁面獲取公共 IP 地址,然后使用 ubuntu 用戶名通過 SSH 連接到機(jī)器。
$ ssh -i ubuntu@
AI虛擬機(jī)登錄畫面
請(qǐng)注意,您可能會(huì)看到重新啟動(dòng) VM 的消息 - 為此,只需運(yùn)行 sudo reboot 并在一分鐘后再次登錄。
運(yùn)行 TensorFlow-AIO示例
TensorFlow 是一個(gè)用于機(jī)器學(xué)習(xí)的開源平臺(tái)。它擁有一系列工具、庫和資源,可讓您輕松構(gòu)建和部署基于 ML 的應(yīng)用程序。
我們?cè)趧?chuàng)建實(shí)例時(shí)選擇的 TensorFlow 鏡像包含簡(jiǎn)單的 TensorFlow 示例。為了準(zhǔn)備運(yùn)行示例,讓我們先下載模型:
$ cd ~/aio-examples
$ ./download_models.sh
“請(qǐng)注意,將所有模型下載到 VM 需要幾分鐘時(shí)間。”
模型文件被下載到 ~/ aioi -examples 和多個(gè)文件夾(例如classifications、 object_detection)。這些模型用來執(zhí)行一些常用的 AI 推理計(jì)算機(jī)視覺任務(wù),如圖像分類和對(duì)象檢測(cè)。
讓我們從一個(gè)使用 Tensorflow resnet_50_v15 模型進(jìn)行分類的示例開始:
“resnet50 模型是什么?這是一個(gè)流行的模型,是 MLCommon 基準(zhǔn)組件之一。您可以在這里讀更多關(guān)于它的內(nèi)容 ”
cd classifications/resnet_50_v15
“對(duì)于 Ampere A1 實(shí)例,一個(gè) OCPU 對(duì)應(yīng)一個(gè)物理的 Ampere Altra處理核心。它不同于 AMD (E3/E4)或 Intel Standard3(S3)中,一個(gè) OCPU 對(duì)應(yīng)一個(gè)超線程(HT)內(nèi)核(一個(gè)物理內(nèi)核對(duì)應(yīng)兩個(gè) HT 內(nèi)核)。”
我們使用4個(gè) Altra 內(nèi)核來運(yùn)行這個(gè)示例。同時(shí)選擇 FP32(全精度浮點(diǎn))模型來運(yùn)行此示例:
export AIO_NUM_THREADS=4
python run.py -m resnet_50_v15_tf_fp32.pb -p fp32
“在內(nèi)存中,F(xiàn)P32 或全精度浮點(diǎn)是一種 32 位的數(shù)字格式。”
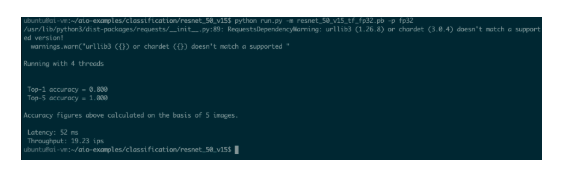
可以看到,使用四個(gè)核心,resnet_50_v15 每秒可以處理 19.23 張圖像(ips)。
AIO 運(yùn)行半精度 (FP16) 模型
Ampere A1 在硬件中提供對(duì) FP16 計(jì)算的原生支持。半精度(FP16)模型可提供比 FP32 多 2 倍的額外性能,同時(shí)也不會(huì)影響模型的精確度。AMD E4 和 Intel S3 都沒有對(duì) FP16 提供原生支持,因此運(yùn)行 FP16 會(huì)異常緩慢。
“FP16 是一種半精度浮點(diǎn)計(jì)算機(jī)數(shù)字格式,在內(nèi)存中占用 16 位。”
讓我們嘗試在 Ampere A1 上運(yùn)行 FP16:
python run.py -m resnet_50_v15_tf_fp16.pb -p fp16
ubuntu@ai-vm:~/aio-examples/classification/resnet_50_v15$ python run.py -m resnet_50_v15_tf_fp16.pb -p fp16
/usr/lib/python3/dist-packages/requests/__init__.py:89: RequestsDependencyWarning: urllib3 (1.26.8) or chardet (3.0.4) doesn't match a supported version!
warnings.warn("urllib3 ({}) or chardet ({}) doesn't match a supported "
Running with 4 threads
Top-1 accuracy = 0.800
Top-5 accuracy = 1.000
Accuracy figures above calculated on the basis of 5 images.
Latency: 28 ms
Throughput: 36.29 ips
使用 FP16 時(shí),我們每秒可以處理 36.29 張圖像。
將數(shù)字與 AMD 和 Intel 實(shí)例(4 個(gè) vCPU)進(jìn)行比較
我們可以通過在 AMD 和 Intel Flex 形狀上運(yùn)行相同的腳本來比較這些數(shù)字。運(yùn)行此模型和應(yīng)用程序每秒的形狀和圖像的成本如下表所示。
對(duì)于 FP32 resnet_50_v15 模型:
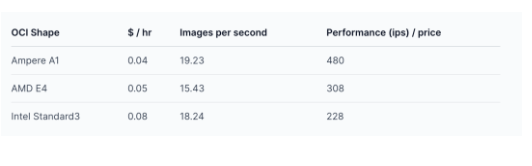
對(duì)于 FP16 resnet_50_v15 模型:

在相同的成本下,運(yùn)行 resnet_50_v15 FP32 模型的 Ampere A1 形狀可提供超過 AMD 最佳 E4 實(shí)例 1.5 倍的性能,以及超過英特爾Standard3實(shí)例 2 倍的性能。
利用 Ampere Altra 對(duì) FP16 的原生支持,在相同的成本下,Ampere A1 形狀達(dá)到的性能超過AMD E4 的 2.8 倍和Intel Standard3的 3.8 倍!
此外,Ampere A1形狀的性能比 AMD/Intel 更好。例如,如果使用更高核心數(shù)的 VM,與運(yùn)行 FP32 模型的 E4 相比,Ampere A1 可提供額外 2 倍的性能增益。
Jupyter Notebook 的可視化示例
首先,讓我們?cè)?VM 上啟動(dòng) Jupyter Notebook 服務(wù)器。
Jupyter Notebook 通常用于在瀏覽器上輕松實(shí)現(xiàn)編輯、調(diào)試和可視化 Python 應(yīng)用程序的需求。我們使用的 VM 圖像包括一個(gè)Jupyter Notebook 示例。
cd ~/.aio-examples./start_notebook.sh
buntu@ai-vm:~/aio-examples$ ./start_notebook.shOn your local system please open a new terminal window and run:ssh -N -L 8080:localhost:8080 -i ./your_key.key your_user@xxx.xxx.xxx.xxx
After that open one of the links printed out below in your local browser
[I 23:08:01.841 NotebookApp] Writing notebook server cookie secret to /home/ubuntu/.local/share/jupyter/runtime/notebook_cookie_secret[I 23:08:02.270 NotebookApp] Serving notebooks from local directory: /home/ubuntu/aio-examples
[I 23:08:02.270 NotebookApp] Jupyter Notebook 6.4.8 is running at:
[I 23:08:02.270 NotebookApp] http://localhost:8080/?token=fd98a68431793485bb9dbf8590ad6f571dbabbfa96757b37
[I 23:08:02.270 NotebookApp] or http://127.0.0.1:8080/?token=fd98a68431793485bb9dbf8590ad6f571dbabbfa96757b37
[I 23:08:02.270 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 23:08:02.274 NotebookApp]
To access the notebook, open this file in a browser: file:///home/ubuntu/.local/share/jupyter/runtime/nbserver-1367-open.html
Or copy and paste one of these URLs: http://localhost:8080/?token=fd98a68431793485bb9dbf8590ad6f571dbabbfa96757b37 or http://127.0.0.1:8080/?token=fd98a68431793485bb9dbf8590ad6f571dbabbfa96757b37
接下來,我們將通過本地主機(jī)打開一個(gè)用于瀏覽器連接的通道。在第二個(gè)終端窗口中,運(yùn)行以下命令:
ssh -N -L 8080:localhost:8080 -i ./your_key.key your_user@xxx.xxx.xxx.xxx
然后,使用上一步中的鏈接在瀏覽器中打開Jupyter Notebook(例如
http://localhost:8080/?token=....)。
您會(huì)看到如下圖所示的頁面。
連接到Ampere 上的Jupyter服務(wù)器
我們將使用 object_detection 文件夾中的對(duì)象檢測(cè)示例。雙擊文件夾的名稱,然后單擊 examples.ipynb 項(xiàng)目。
單擊“運(yùn)行”按鈕來逐步執(zhí)行該示例。您會(huì)看到對(duì)象檢測(cè)的結(jié)果以及 AIO 對(duì) Tensorflow 的加速情況。
您會(huì)注意到啟用或禁用 AIO 時(shí)的延遲差異。例如,當(dāng)以 FP16 精度運(yùn)行已啟用 AIO 的模型時(shí),延遲約為 44 毫秒。在禁用 AIO 的情況下運(yùn)行相同的模型,延遲為 3533 ms!這是一個(gè)明顯的區(qū)別。

運(yùn)行示例
您也可以用相同的方式運(yùn)行分類示例——單擊 classification文件夾,然后單擊 examples.ipynb 項(xiàng)目。
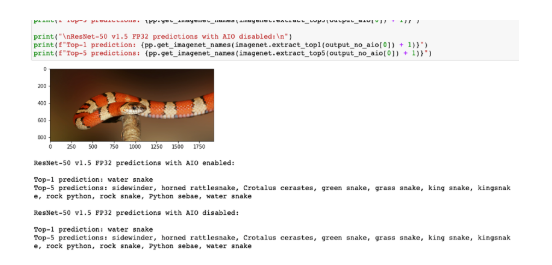
分類示例
結(jié)論
恭喜!您已完成在 Ampere A1 形狀上運(yùn)行通用 AI 應(yīng)用程序的全過程。
運(yùn)行這些示例相當(dāng)簡(jiǎn)單——不用進(jìn)行任何轉(zhuǎn)換或更改應(yīng)用程序代碼就能在 Ampere A1 上運(yùn)行 API 應(yīng)用程序。
像 TensorFlow 等的標(biāo)準(zhǔn)框架會(huì)自動(dòng)加速。我們可以很輕松地以相同的成本達(dá)到比其他形狀高 2 到 4 倍的性能增益。
您可以在 Github repo 中查看本文中使用的腳本——這些腳本與我們?cè)谒褂玫氖纠龍D像上自動(dòng)下載的腳本相同。
-
AI
+關(guān)注
關(guān)注
87文章
31513瀏覽量
270323 -
應(yīng)用程序
+關(guān)注
關(guān)注
38文章
3292瀏覽量
57911 -
虛擬機(jī)
+關(guān)注
關(guān)注
1文章
937瀏覽量
28426
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何在ML605板上從Platform-flash-XL自動(dòng)運(yùn)行應(yīng)用程序的教程?
如何在PC上測(cè)試固件應(yīng)用程序?
如何在NFC Tap iOS應(yīng)用程序上輸入密碼?
如何在手機(jī)上打開/啟動(dòng)應(yīng)用程序?
TrueFFS上VxWorks應(yīng)用程序的啟動(dòng)及動(dòng)態(tài)更新





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論