 使用NVIDIA RTX MU提供壓縮和子分配解決方案
使用NVIDIA RTX MU提供壓縮和子分配解決方案
加速結構在空間上組織幾何體以加速光線跟蹤遍歷性能。創建加速結構時,會分配保守的內存大小。
在初始構建時,圖形運行時不知道幾何體如何最佳地適應超大的加速結構內存分配。
在 GPU 上執行構建之后,圖形運行時報告加速結構可以容納的最小內存分配。
這個過程稱為壓縮加速結構,它對于減少加速結構的內存開銷非常重要。
減少記憶的另一個關鍵因素是對加速結構的子分配。子分配通過使用比圖形 API 所要求的內存對齊方式更小的內存對齊方式,使加速結構能夠在內存中緊密地打包在一起。
通常,緩沖區分配對齊最小為 64 KB ,而加速結構內存對齊要求僅為 256 B 。使用許多小加速結構的游戲從子分配中受益匪淺,使許多小分配能夠緊密打包。
NVIDIA RTX 內存實用程序( RTX MU ) SDK 旨在降低與加速結構優化內存管理相關的編碼復雜性。 RTX MU 為 DXR 和 Vulkan 光線跟蹤提供壓縮和子分配解決方案,同時客戶端管理加速結構構建的同步和執行。 SDK 為這兩個 API 提供了子分配器和壓縮管理器的示例實現,同時為客戶機實現自己的版本提供了靈活性。
有關壓縮和子分配在減少加速結構內存開銷方面為何如此重要的更多信息,請參見 提示:加速結構壓實 。
為什么使用 RTX MU ?
RTX MU 允許您將加速結構內存縮減技術快速集成到他們的游戲引擎中。下面是這些技術的總結,以及使用 RTX MU 的一些關鍵好處
減少加速結構的內存占用,包括壓縮和子分配代碼,實現起來并不簡單。 RTX MU 可以完成繁重的工作。
抽象了底層加速結構( blase )的內存管理,但也足夠靈活,允許用戶根據引擎的需要提供自己的實現。
管理壓縮大小回讀和壓縮副本所需的所有屏障。
將句柄傳遞回引用復雜 BLAS 數據結構的客戶端。這可以防止對 CPU 內存的任何管理不當,包括訪問已經釋放或不存在的 BLAS 。
有助于將 BLAS 內存減少 50% 。
通過將更多的 BLASE 打包到 64 KB 或 4 MB 頁中,可以減少翻譯查找緩沖區( TLB )未命中。
RTX MU 設計
RTX MU 有一種設計理念,可以降低大多數開發人員的集成復雜性。該設計理念的主要原則如下:
所有函數都是線程安全的。如果同時訪問發生,它們將被阻塞。
客戶機傳入客戶機擁有的命令列表, RTX MU 填充它們。
客戶機負責同步命令列表執行。
API 函數調用
RTX MU 抽象了與壓縮和子分配相關的編碼復雜性。本節中詳細介紹的函數描述了 RTX MU 的接口入口點。
Initialize – 指定子分配程序塊大小。
PopulateBuildCommandList – 接收 D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS 數組并返回加速結構句柄向量,以便客戶端稍后在頂級加速結構( TLAS )構造期間獲取加速結構 GPU VAs ,依此類推。
PopulateUAVBarriersCommandList –接收加速度結構輸入并為其放置 UAV 屏障
PopulateCompactionSizeCopiesCommandList –執行拷貝以傳遞任何壓縮大小數據
PopulateUpdateCommandList – 接收 D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS 數組和有效的加速結構句柄,以便記錄更新。
PopulateCompactionCommandList – 接收有效的加速結構句柄數組,并記錄壓縮命令和屏障。
RemoveAccelerationStructures – 接收一個加速結構句柄數組,該數組指定可以完全釋放哪個加速結構。
GarbageCollection – 接收一個加速結構句柄數組,該數組指定可以釋放生成資源(暫存和結果緩沖區內存)。
GetAccelStructGPUVA – 接收加速結構句柄并根據狀態返回結果或壓縮緩沖區的 GPU VA 。
Reset – 釋放與當前加速結構句柄關聯的所有內存。
子分配程序 DXR 設計
BLAS 子分配程序通過將小的 BLAS 分配放在較大的內存堆中,來滿足 64kb 和 4mb 的緩沖區對齊要求。 BLAS 子分配程序仍然必須滿足 BLAS 分配所需的 256B 對齊。
如果應用程序請求 4mb 或更大的子分配塊,那么 RTX MU 使用具有堆的已放置資源,這些堆可以提供 4mb 對齊。
如果應用程序請求的子分配塊少于 4MB ,那么 RTX MU 將使用提交的資源,它只提供 64KB 的對齊。
BLAS 子分配程序通過維護空閑列表重用塊中的空閑子分配。如果內存請求大于子分配程序塊大小,則會創建一個無法子分配的分配。
壓實 DXR 設計
如果構建請求壓縮,那么 RTX MU 請求將壓縮大小寫入視頻內存塊。壓縮大小從視頻內存復制到系統內存后, RTX MU 分配一個子分配的壓縮緩沖區,用作壓縮復制的目的地。
壓縮拷貝獲取包含未使用的內存段的原始構建,并將其截短到可以容納的最小內存占用。壓縮完成后,原始的非壓縮構建和暫存內存將釋放回子分配程序。唯一需要擔心的是傳入 allow compression 標志并用 BLAS 句柄調用 GetGPUVA 。 GPU VA 可以是原始版本,也可以是壓縮版本,這取決于 BLAS 處于什么狀態。
如何使用 RTX MU
在本節中,我將詳細介紹 RTX MU 序列循環和同步。
RTX MU 序列環路
圖 1 顯示了 RTX MU 的正常使用模式。客戶機管理命令列表的執行,而其他一切都是對 RTX MU 的調用
首先,通過傳入子分配程序塊大小和負責分配子分配塊的設備來初始化 RTX MU 。在每一幀中,引擎構建新的加速結構,同時也壓縮先前幀中構建的加速結構。
在 RTX MU 填充客戶機的命令列表之后,客戶機就可以自由地執行和管理初始構建到最終壓縮拷貝構建的同步。在調用 PopulateCompactionCommandList 之前,確保每個加速結構構建都已完全執行,這一點很重要。這是留給客戶妥善管理。
當加速結構最終達到壓縮狀態時,客戶機可以選擇調用 GarbageCollection ,它通知 RTX MU 可以釋放暫存和原始加速結構緩沖區。如果引擎執行大量的資產流,那么客戶端可以通過使用有效的加速結構句柄調用 RemoveAS 來釋放所有加速結構資源。
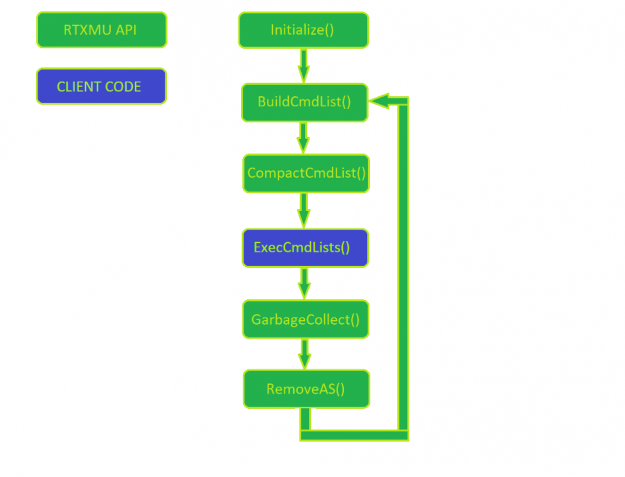
圖 1 描述客戶機和 RTX MU 代碼的典型用例的 RTX MU 流程圖
客戶端加速結構生成同步
圖 2 顯示了客戶端正確管理壓縮就緒工作負載所需的同步。這里的示例是一個三幀緩沖循環,其中客戶端最多可以有三個異步幀構建在 CPU 上并在 GPU 上執行。
若要獲取 CPU 側可用的壓縮大小,生成 0 必須已在 GPU 上執行完畢。在客戶端接收到來自 GPU 的 fence 信號后,客戶端可以調用 RTX MU 來開始壓縮命令列表記錄。
管理加速結構的壓縮同步的一種有用方法是使用某種類型的鍵/值對數據結構,它跟蹤 RTX MU 給定的每個加速結構句柄的狀態。加速度結構的四種基本狀態可描述如下:
Prebuilt – 生成命令記錄在命令列表中,但尚未在 GPU 上完成執行。
Built – 初始構建已在 GPU 上執行,并準備好執行壓縮命令。
Compacted – 壓縮拷貝已經在 GPU 上完成,并且準備好讓 GarbageCollection 釋放暫存和初始構建緩沖區。
Released – 客戶端從內存中釋放加速結構,因為它不再在場景中。此時,與加速結構句柄相關的所有內存都被釋放回操作系統。
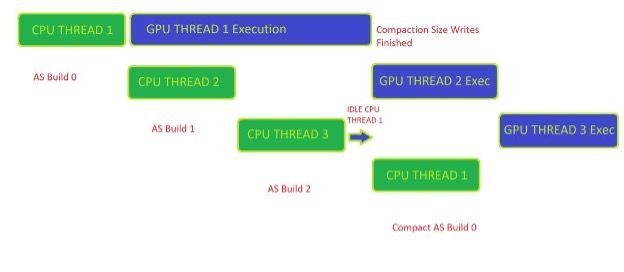
圖 2 。客戶機代碼只能在初始加速結構構建完成在 GPU 上的執行之后啟動壓縮工作負載。
RTX MU 測試場景
RTX MU 使用六個文本場景進行了測試,以提供有關壓縮和子分配的好處的真實用例數據。下面的圖只顯示了一些場景。
RTX MU 積分結果
在測試場景中, NVIDIA RTX 卡上的壓縮平均減少了 52% 的加速度結構。壓縮記憶降低的標準差為 2 。 8% ,比較穩定。
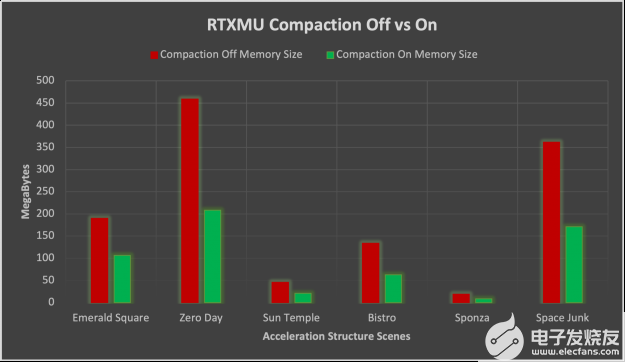
圖 6 。 ZVK3] RTX 3000 系列 GPU s 上壓縮打開與關閉的比較條形圖
在 NVIDIA 和 AMD-HW 上啟用壓縮時, NVIDIA HW 上的內存節省比 AMD 上的內存節省大得多。在啟用壓縮時, NVIDIA 的加速結構內存平均比 AMD 小 3 。 26 倍。在 NVIDIA 上如此巨大的內存占用減少的原因是沒有壓縮的 AMD 使用的內存是 NVIDIA 的兩倍。壓縮還將 NVIDIA 內存平均再減少 50% ,而 AMD 傾向于只減少 75% 的內存。
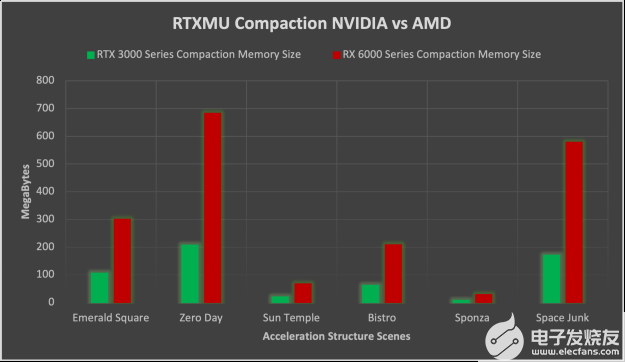
圖 7 。 NVIDIA 3000 系列與 AMD 6000 系列 GPU s 的壓縮比較條形圖
子分配在這里講述了一個稍有不同的故事,其中有許多小加速結構的場景(如零日)受益匪淺。子分配帶來的平均內存節省最終為 123MB ,但標準差在 153MB 時相當大。從這些數據中,我們可以斷言子分配高度依賴于場景幾何體,并受益于數千個小三角形計數的 BLAS 幾何體。
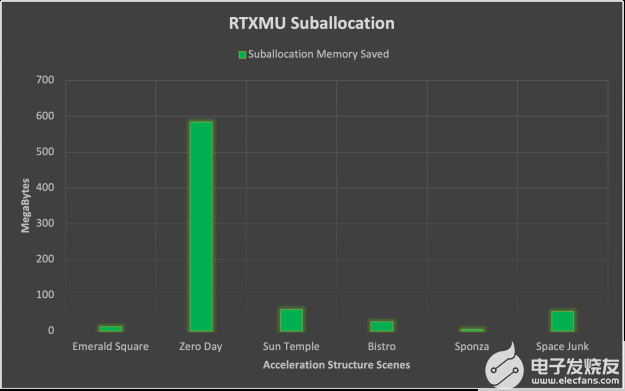
圖 8 。顯示特定場景子分配節省內存的條形圖
源代碼
NVIDIA 是一個開源的 RTX MU SDK ,以及一個集成 RTX MU 的示例應用程序。在 GitHub 上將 RTX MU 作為一個開源項目進行維護可以幫助開發人員理解邏輯流程并提供修改底層實現的訪問。 RT Bindless 示例應用程序提供了一個 RTX MU 集成的示例 Vulkan 光線跟蹤和 DXR 后端。
下面是如何構建和運行集成 RTX MU 的示例應用程序。您必須擁有以下資源:
Windows 、 Linux 或支持 DXR 或 Vulkan 光線跟蹤的操作系統
克馬克 3.12
C ++ 17
Git
首先,使用以下命令克隆存儲庫:
git clone --recursive https://github.com/NVIDIAGameWorks/donut_examples.git
接下來,打開 CMake 。對于 源代碼在哪里 ,輸入 /donut_examples 文件夾。在 /donut_examples 文件夾中創建生成文件夾。對于 在哪里構建二進制文件 ,輸入 new build 文件夾。選擇 cmake 變量 NVRHI \ u ,并將“ RTX MU ”設置為“開”,選擇“配置”,等待其完成,然后單擊“生成”。
如果要使用 Visual Studio 進行構建,請選擇 2019 和 x64 version 。在 visualstudio 中打開 donut_examples.sln 文件并生成整個項目。
在 /Examples/Bindless Ray 跟蹤下找到 rt_bindless 應用程序文件夾,選擇項目上下文(右鍵單擊)菜單,然后選擇 啟動項目 。
默認情況下,無綁定光線跟蹤在 DXR 上運行。要運行 Vulkan 版本,請在項目中添加 -vk 作為命令行參數。
Summary
RTX MU 結合了壓縮和子分配技術來優化和減少任何 DXR 或 Vulkan 光線跟蹤應用程序的加速結構的內存消耗。數據表明,使用 RTX MU 可以顯著減少加速結構的內存。這使您可以向光線跟蹤場景添加更多幾何體,或將額外內存用于其他資源。
關于作者
Peter Morley 在 NVIDIA 擔任高級開發技術工程師。他的大部分工作集中在將 DXR 集成到 AAA 游戲引擎上。他以前的工作包括在 AMD 的驅動程序堆棧中實現 DXR1.0 和 1.1 。他于 2017 完成了羅德島大學的 MSC ,并幫助使用隱馬爾可夫模型研究體素空間光線跟蹤狀態估計。當他不玩游戲時,他喜歡和家人一起玩足球。
Jarvis McGee 是 NVIDIA 的高級開發技術工程師,致力于各種圖形技術的集成和優化 Vulkan 。 7 年來, Jarvis 一直在游戲行業內優化 AAA 游戲的渲染。他為 2K Games 和 Playstation 的各種游戲的發行做出了貢獻。他完成了在加利福尼亞南部加利福尼亞大學的 MSC ,并協助在美國南加州大學創新技術研究所展示數字人類的研究。在他的閑暇時間,你可以發現他在舊金山灣地區嘗試新的渲染技術和徒步旅行。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103731 -
API
+關注
關注
2文章
1511瀏覽量
62402
發布評論請先 登錄
相關推薦
技嘉科技發布GeForce RTX 5090 D 和RTX 5080系列顯卡

$1999 的 RTX 5090 來了
NVIDIA推出面向RTX AI PC的AI基礎模型
技嘉于 CES 2025 首度亮相升級散熱設計與精實體積的 NVIDIA GeForce RTX 50 系列顯卡
Supermicro推出直接液冷優化的NVIDIA Blackwell解決方案

NVIDIA RTX AI套件簡化AI驅動的應用開發
RTX AI PC和工作站提供強大AI性能
Nvidia 再推出特供版顯卡 GeForce RTX 5090D

NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業軟件支持
NVIDIA推出用于支持在全新GeForce RTX AI筆記本電腦上運行的AI助手及數字人
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業軟件支持,實現邊緣實時醫療、工業和科學 AI 應用

英偉達考慮縮減RTX 5090 Founder版顯卡尺寸,配備雙槽雙風扇設計
NVIDIA發布兩款新的專業顯卡RTX A1000、RTX A400

NVIDIA RTX 5090痛失512位顯存!






 工商網監
工商網監
評論