 Vitis HLS的基礎知識科普
Vitis HLS的基礎知識科普
Vitis HLS簡介
VitisHLS是一種高層次綜合工具,支持將C、C++和OpenCL函數硬連線到器件邏輯互連結構和RAM/DSP塊上。
Vitis HLS可在Vitis應用加速開發流程中實現硬件內核,并使用C/C++語言代碼在VivadoDesign Suite中為賽靈思器件設計開發RTL IP。
參考:《Vitis高層次綜合用戶指南》(UG1399)。
在 Vitis 應用加速流程中,在可編程邏輯中實現和最優化 C/C++ 語言代碼以及實現低時延和高吞吐量所需的大部分代碼修改操作均可通過 Vitis HLS 工具來自動執行。在應用加速流程中,Vitis HLS 的基本作用是通過推斷所需的編譯指示來為函數實參生成正確的接口,并對代碼內的循環和函數執行流水打拍。Vitis HLS 還支持自定義代碼以實現不同接口標準或者實現特定最優化以達成設計目標。
Vitis HLS 設計流程如下所述:
- 編譯、仿真和調試 C/C++ 語言算法。
- 查看報告以分析和最優化設計。
- 將 C 語言算法綜合到 RTL 設計中。
- 使用 RTL 協同仿真來驗證 RTL 實現。
- 將 RTL 實現封裝到已編譯的對象文件 (.xo) 擴展中,或者導出到 RTL IP。
Vitis HLS 存儲器布局模型
Vitis 應用加速開發流程提供了相應的框架,可通過使用標準編程語言來為軟件和硬件組件開發和交付 FPGA 加速應用。軟件組件或主機程序是使用 C/C++ 語言開發的,可在 x86 或嵌入式處理器上運行,借助 OpenCL 或 XRT 本機 API 調用來管理與加速器的運行時間交互。硬件組件或內核(在實際 FPGA 卡/平臺上運行)則可使用 C/C++、OpenCL C 或 RTL 來開發。Vitis 軟件平臺有助于促進對異構應用的硬件和軟件元素進行并發開發和測試。因此,在主機上運行的軟件程序需要使用精確定義的接口和協議來與在 FPGA 硬件模型上運行的加速內核進行通信。因此,精確定義所使用的存儲器模型以便正確處理讀寫的數據就顯得尤為重要。存儲器模型可以定義計算機存儲器中排列和訪問數據的方式。其中涉及兩個獨立但相關的問題:數據對齊和數據結構填充。此外,Vitis HLS 編譯器支持指定特殊屬性(和編譯指示)來更改默認的數據對齊和數據結構填充規則。
數據對齊
軟件程序員習慣于將存儲器視為簡單的字節陣列,而將基本數據類型視為是由一個或多個存儲器塊組成的。但計算機處理器并不會在單個字節大小的區塊內對存儲器執行讀取和寫入。現今的現代化 CPU 實際上每次訪問 2、4、8、16 甚至是 32 字節的區塊,雖說最常用的指令集架構 (ISA) 是 32 位和 64 位的。鑒于系統內存儲器的組織方式,這些區塊的地址應為其大小的倍數。如果地址滿足此要求,則將其稱為已對齊。高級程序員對于存儲器的看法與現代化處理器實際處理存儲器的方式之間的差別在應用程序的正確性和性能方面實際上是非常重要的。例如,如果您不了解軟件中的地址對齊問題,那么就可能發生下列情況:
- 軟件運行緩慢
- 應用將鎖定/掛起
- 操作系統可能崩潰
- 軟件將靜默失敗,產生錯誤結果
C++ 語言可以提供一系列不同大小的基本類型。為了能快速操作這些類型的變量,生成的對象代碼將嘗試使用能立即讀取/寫入整個數據類型的 CPU 指令。這也就意味著這些類型的變量在存儲器內的布局方式應確保其地址能以合適方式保持對齊。由此導致每個基本類型除大小之外還有另一個屬性:即對齊要求。基本類型的對齊可能看似與其大小相同。但實際情況往往并非如此,因為最適合特定類型的 CPU 指令可能每次只能訪問其數據中的一部分。例如,32 位 x86 GNU/Linux 機器可能每次只能讀取最多 4 個字節,因此,64 位 long long 類型的大小為 8,對齊為 4。下表顯示了 C/C++ 中對應 32 位和 64 位 x86-64 GNU/Linux 機器的基本原生數據類型的大小和對齊(以字節數為單位)。
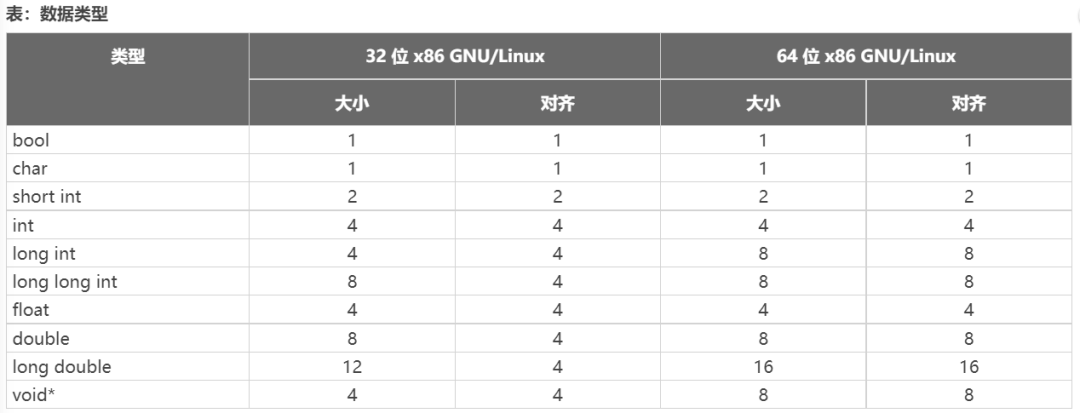
根據以上排列,程序員為什么需要更改對齊?原因有多個,但主要原因是在存儲器要求與性能之間的取舍。在主機與加速器之間往返發送數據時,發射的每個字節都有成本。幸好,GCC C/C++ 編譯器可提供語言擴展 ,用于為變量、結構/類或結構字段更改默認對齊(以字節數為單位來測量)。例如,以下聲明會導致編譯器在 16 字節邊界上分配全局變量 x。
intx__attribute__((aligned(16)))=0;
不會更改所應用到的變量的大小,而是可以更改結構的存儲器布局,方法是在結構體的各元素之間插入填充。由此即可更改結構的大小。如果您在已對齊的屬性中不指定對齊因子,那么編譯器會將聲明的變量或字段的對齊設置為要編譯的目標機器上的任意數據類型所使用的最大對齊。這樣通常能夠提升復制操作的效率,因為編譯器在對已通過這種方式對齊的變量或字段執行往來復制時,可以使用任何能復制最大存儲器區塊的指令。aligned 屬性只能增大對齊,而不能減小對齊。C++ 函數 offsetof 可用于判定結構中每個成員元素的對齊。
數據結構填充
如 數據對齊(上一節) 中的表格所示,本地數據類型具有精心定義的對齊結構,但用戶定義的數據類型的對齊結構又如何呢?C++ 編譯器也需要確保結構體或類中的所有成員變量都正確對齊。為此,編譯器可在成員變量之間插入填充字節。此外,為了確保用戶定義的類型的陣列中的每個元素都對齊,編譯器可以在最后一個數據成員之后添加額外的填充。請考量以下示例:

GCC 編譯器始終假定 的實例的起始地址對齊到所有結構體成員的要求最嚴格的對齊地址處,在此例中,即 int。實際上,用戶定義的類型的對齊要求正是以此方式計算所得的。假定存儲器為 x86-64 對齊,其中 的對齊為 2,int 的對齊為 4,為了使 的 i 數據成員得以適當對齊,編譯器需要在 s 與 i 之間插入 2 個額外的填充字節以創建對齊,如下圖所示。同樣,為了對齊數據成員 c,編譯器需要在 c 之后插入 3 個字節。
對于 ,編譯器將基于結構體元素的對齊方式推斷總計大小為 12 個字節。但如果結構體的元素已重新排序(如 中所示),那么編譯器現在即可推斷得到較小的大小,即 8 個字節。
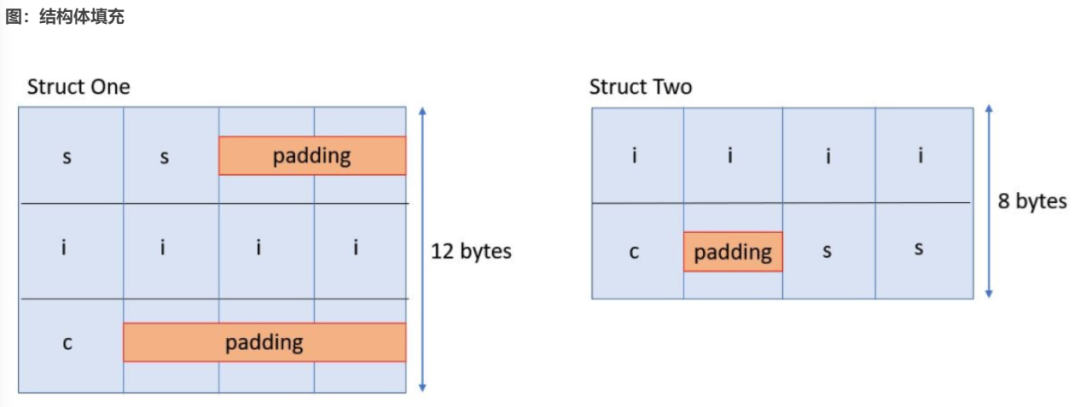
默認情況下,C/C++ 編譯器將按結構體成員的聲明順序來完成這些成員的布局,在成員間或者最后一個成員之后可能按需插入填充字節,以確保每個成員都能正確對齊。但是,GCC C/C++ 編譯器會提供語言擴展,以告知編譯器不插入填充,而是改為允許結構體成員間不對齊。例如,如果系統正常情況下要求所有 int 對象都采用 4 字節對齊,那么使用 可能導致將 int 結構體成員分配至錯誤偏移處。
您必須審慎考量 的使用,因為訪問未對齊的存儲器可能導致編譯器插入代碼以逐個字節讀取存儲器,而不是一次性讀取多個存儲器區塊。
Vitis HLS 對齊規則和語義
鑒于前述 GCC 編譯器的行為,本節將詳述 Vitis HLS 如何使用 aligned 和 packed 屬性來創建高效硬件。首先,您需要了解 Vitis HLS 中的 聚合 和 解聚 功能特性。代碼中的結構或類對象(例如,內部變量和全局變量)默認情況下處于解聚 (disaggregated) 狀態。解聚暗示此結構/類已分解為多個不同對象,針對每個結構體/類成員各一個對象。創建的元素數量和類型取決于結構體本身的內容。結構體陣列作為多個陣列來實現,每個結構體成員都具有獨立的陣列。
但默認情況下,用作為頂層函數的實參的結構體則保持聚合狀態。聚合暗示任一結構體的所有元素都集合到一個單寬矢量內。這樣即可同時讀寫結構體的所有成員。結構體的成員元素按 C/C++ 代碼中所示順序置于該矢量內:結構體的第一個元素對齊矢量的 LSB,結構體的最后一個元素對齊矢量的 MSB。結構體中的任意陣列都分區到獨立陣列元素中,并按從低到高的順序置于矢量內。
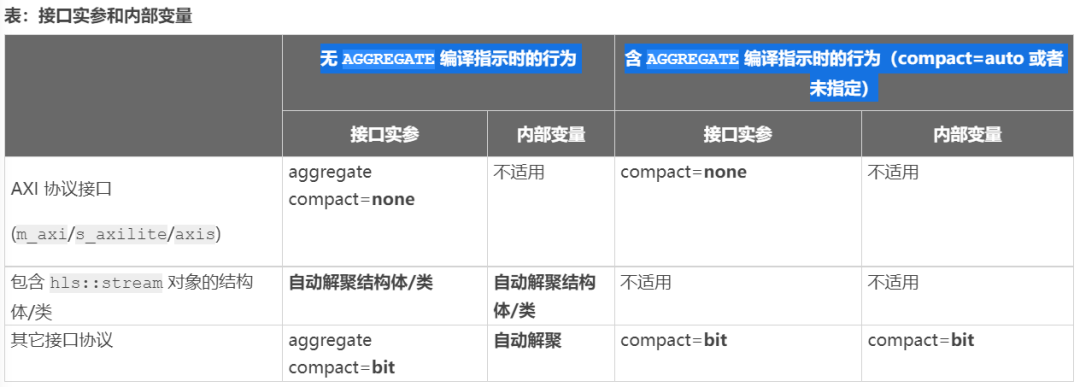
Vitis HLS 中的默認聚合目的是在硬件接口頂層使用 x86_64-gnu-linux 存儲器布局,同時最優化內部硬件以提升結果質量 (QoR)。上表顯示了 Vitis HLS 的默認行為。該表中顯示了 2 種模式:用戶不指定 編譯指示(默認模式),和用戶指定 編譯指示的模式。
對于 AXI4 接口 (m_axi/s_axilite/axis),默認根據結構體元素對該結構進行填充,如 數據結構填充 中所述。這樣即可將結構大小聚合為最接近 2 的冪值,并且在此情況下可應用部分填充。這樣即可有效推斷 編譯指示上的 e 選項。
對于其它接口協議,按位級來對結構體進行封裝,以便根據該結構體所含的各元素來調整聚合的矢量的大小。這樣即可有效推斷 編譯指示上的 選項。
以上規則的唯一例外是在接口中以間接方式使用 時(即,在結構體/類內部使用 對象,隨后將此結構體/類用作為接口端口的類型)。包含 對象的結構體將始終解聚為其各獨立成員元素。
聚合示例
聚合存儲器映射接口
這是 m_axi 接口的 AGGREGATE 編譯指示或指令的示例。
structA{
charfoo;//1byte
shortbar;//2bytes
};
intdut(A*arr){
#pragmaHLSinterfacem_axiport=arrdepth=10
#pragmaHLSaggregatevariable=arrcompact=auto
intsum=0;
for(unsignedi=0;i<10;?i++)?{
????auto?tmp?=?arr[i];
????sum?+=?tmp.foo?+?tmp.bar;
??}
??returnsum;
}
對于以上示例,m_axi 接口端口 arr 的大小為 3 個字節(或 24 位),但由于 編譯指示的作用,該端口的大小將對齊到 4 個字節(或 32 位),因為這是最接近的 2 的冪值。Vitis HLS 將在 log 日志文件中發出以下消息:<Vitis HLS 2021.1 GUI 中有哪些新功能?>
INFO:[HLS214-241]Aggregatingmaxivariable'arr'withcompact=nonemodein32-bits(example.cpp0)
僅當使用 AGGREGATE 編譯指示時,才會發出以上消息。但即使不使用編譯指示,該工具仍將自動聚合接口端口 arr 并將其填充至 4 個字節,這是 AXI 接口端口的默認行為。
在接口上聚合結構體
這是 ap_fifo 接口的 AGGREGATE 編譯指示或指令的示例。
structA{
intmyArr[3];//4bytesperelement(12bytestotal)
ap_int<23>length;//23bits
};
intdut(Aarr[N]){
#pragmaHLSinterfaceap_fifoport=arr
#pragmaHLSaggregatevariable=arrcompact=auto
intsum=0;
for(unsignedi=0;i<10;?i++)?{
????auto?tmp?=?arr[i];
????sum?+=?tmp.myArr[0]?+?tmp.myArr[1]?+?tmp.myArr[2]?+?tmp.length;
??}
??returnsum;
}
對于 ap_fifo 接口,無論是否使用聚合編譯指示,結構體都將在位級進行封裝。
在以上示例中,AGGREGATE 編譯指示將為端口 arr 創建大小為 119 位的端口。陣列 myArr 將取 12 個字節(或 96 位),元素 length 將取 23 位,總計 119 位。Vitis HLS 將在 log 日志文件中發出以下消息:《Xilinx HLS 導出IP失敗的最新解決方案(2022.1.15)》
INFO:[HLS214-241]Aggregatingfifo(array-to-stream)variable'arr'withcompact=bitmode
in119-bits(example.cpp0)
聚合嵌套結構體端口
這是 Vivado IP 流程中 AGGREGATE 編譯指示或指令的示例。
#defineN8
structT{
intm;//4bytes
intn;//4bytes
boolo;//1byte
};
structS{
intp;//4bytes
Tq;//9bytes
};
voidtop(Sa[N],Sb[N],Sc[N]){
#pragmaHLSinterfacebramport=c
#pragmaHLSinterfaceap_memoryport=a
#pragmaHLSaggregatevariable=acompact=byte
#pragmaHLSaggregatevariable=bcompact=bit
#pragmaHLSaggregatevariable=ccompact=byte
for(inti=0;i
在以上示例中,聚合算法將為端口 a 和端口 c 創建大小為 104 位的端口,因為在聚合編譯指示中已指定 compact=byte 選項,但針對端口 b 使用默認選項 compact=bit,其打包大小將為 97 位。嵌套的結構 S 和 T 將聚合以包含 3 個 32 位成員變量(p、m 和 n)以及 1 個位/字節成員變量 (o)。
注意:此示例使用 Vivado IP 流程來演示聚合行為。在 Vitis 內核流程中,端口 b 將自動推斷為 m_axi 端口,故而將不允許使用 compact=bit 設置。
<【Vivado那些事兒】高層次綜合技術(HLS)原理淺析>
Vitis HLS 將在 log 日志文件中發出以下消息:
INFO:[HLS214-241]Aggregatingbramvariable'b'withcompact=bitmodein97-bits(example.cpp0)
INFO:[HLS214-241]Aggregatingbramvariable'a'withcompact=bytemodein104-bits(example.cpp0)
INFO:[HLS214-241]Aggregatingbramvariable'c'withcompact=bytemodein104-bits(example.cpp0)
解聚示例
解聚 AXIS 接口
這是 axis 接口的 DISAGGREGATE 編譯指示或指令的示例。
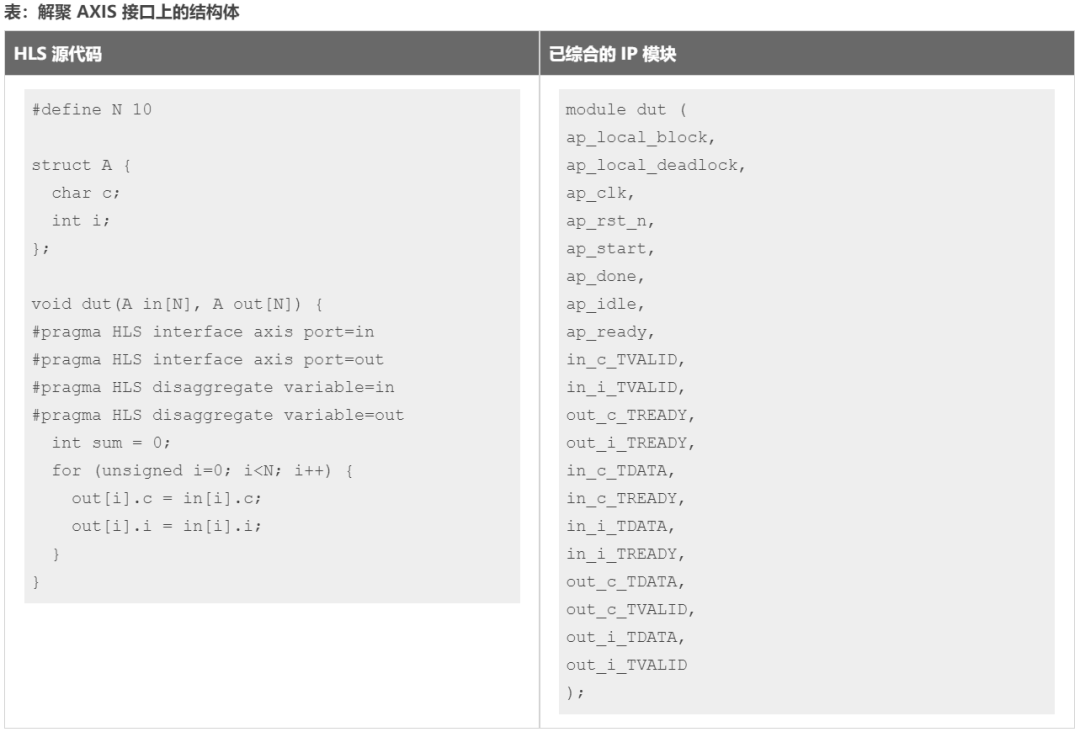
在以上解聚示例中,結構體實參 in 和 out 均映射到 AXIS 接口,然后進行解聚。這導致 Vitis HLS 為每個實參創建 2 條 AXI 串流:in_c、in_i、out_c 和 out_i。結構體 A 的每個成員都各成一條獨立串流。
生成的模塊的 RTL 接口顯示在上表右側,其中成員元素 c 和 i 均為獨立 AXI 串流端口,每個端口都有自己的 TVALID、TREADY 和 TDATA 信號。
Vitis HLS 將在 log 日志文件中發出以下消息:
INFO:[HLS214-210]Disaggregatingvariable'in'(example.cpp0)
INFO:[HLS214-210]Disaggregatingvariable'out'(example.cpp0)
解聚 HLS::STREAM
這是搭配 hls::stream 類型一起使用的 DISAGGREGATE 編譯指示或指令的示例。
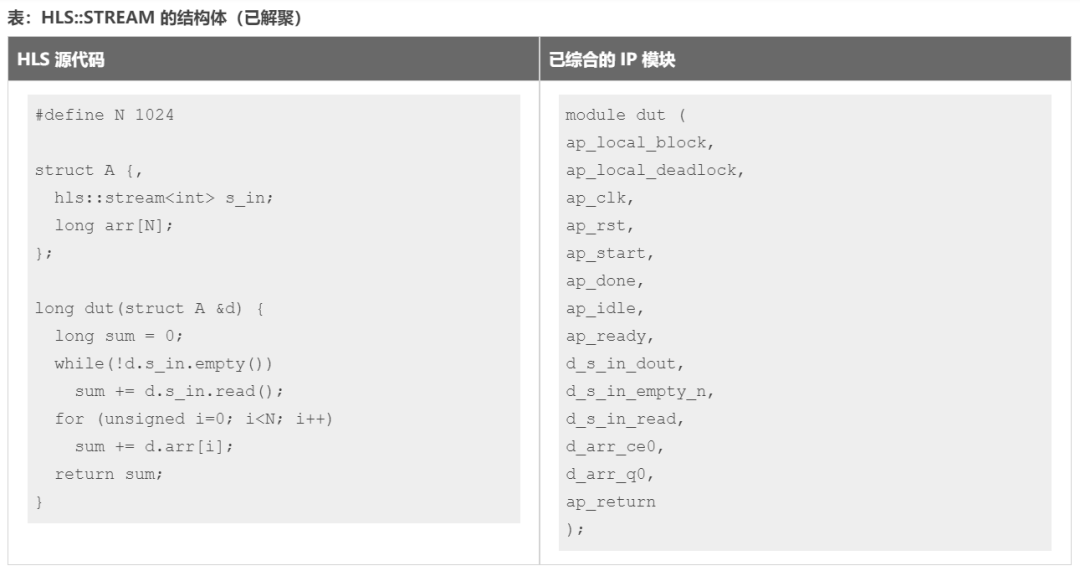
如果在用于接口中的結構內部使用 hls::stream 對象,則會導致 Vitis HLS 編譯器將該結構體端口自動解聚。如以上示例所示,生成的 RTL 接口將為 hls::stream 對象 s_in 包含獨立的 RTL 端口(名為 d_s_in_*),并為陣列 arr 包含獨立的 RTL 端口(名為 d_arr_*)。
Vitis HLS 將在 log 日志文件中發出以下消息:
INFO:[HLS214-210]Disaggregatingvariable'd'
INFO:[HLS214-241]Aggregatingfifo(hls::stream)variable'd_s_in'withcompact=bitmodein32-bits
結構體大小對于流水打拍的影響
函數接口中使用的結構體的大小對于循環中的流水打拍可能存在不利影響,主要影響的是有權訪問函數主體中的接口的函數。以下列包含 2 個 M_AXI 接口的代碼為例:
structA{/*Totalsize=192bits(32x6)or24bytes*/
ints_1;
ints_2;
ints_3;
ints_4;
ints_5;
ints_6;
};
voidread(A*a_in,Abuf_out[NUM]){
READ:
for(inti=0;ifor(intj=0;jfor(intk=0;k#pragmaHLSINTERFACEm_axiport=a_inbundle=gmem0
#pragmaHLSINTERFACEm_axiport=a_outbundle=gmem1
Abuffer_in[NUM];
Abuffer_out[NUM];
#pragmaHLSdataflow
read(a_in,buffer_in);
compute(buffer_in,buffer_out,size);
write(buffer_out,a_out);
}
在以上示例中,結構體 A 的大小為 192 位,這并非 2 的冪。如前文所述,默認情況下,所有 AXI4 接口大小均設為 2 的冪。Vitis HLS 將自動把這 2 個 M_AXI 接口(a_in 和 a_out)的大小調整為 256 - 即與 192 位大小最接近的 2 的冪值(并在 log 日志文件中報告此行為,如下所示)。
INFO:[HLS214-241]Aggregatingmaxivariable'a_out'withcompact=nonemodein
256-bits(example.cpp0)
INFO:[HLS214-241]Aggregatingmaxivariable'a_in'withcompact=nonemodein256-bits
(example.cpp0)
這其中隱含的意義是在寫入結構數據并輸出時,首次寫入將在一個周期內把 24 個字節寫入第一個緩沖器,但第二次寫入將必須把 8 個字節寫入第一個緩沖器內的剩余 8 個字節,然后將 16 個字節寫入第二個緩沖器,這樣就會生成 2 次寫入,如下圖所示。
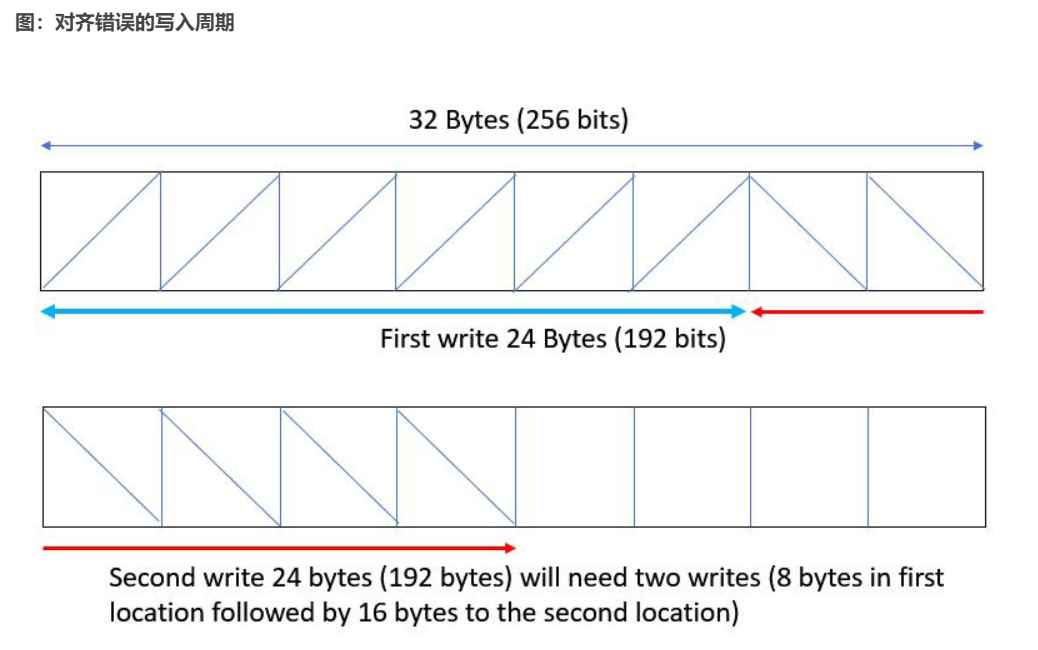
這將導致函數 write() 中的 WRITE 循環的 II 發生 II 違例,因為它需要 II=2 而不是 II=1。讀取時也會發生類似的行為,因此 read() 函數同樣會發生 II 違例,因為它需要 II=2。Vitis HLS 將為函數 read() 和 write() 中的 II 違例發出以下警告:
WARNING:[HLS200-880]TheIIViolationinmodule'read_r'(loop'READ'):Unable
toenforceacarrieddependenceconstraint(II=1,distance=1,offset=1)between
busreadoperation('gmem0_addr_read_1',example.cpp:23)onport'gmem0'(example.cpp:23)
andbusreadoperation('gmem0_addr_read',example.cpp:23)onport'gmem0'(example.cpp:23).
WARNING:[HLS200-880]TheIIViolationinmodule'write_Pipeline_WRITE'(loop'WRITE'):
Unabletoenforceacarrieddependenceconstraint(II=1,distance=1,offset=1)
betweenbuswriteoperation('gmem1_addr_write_ln44',example.cpp:44)onport'gmem1'
(example.cpp:44)andbuswriteoperation('gmem1_addr_write_ln44',example.cpp:44)on
port'gmem1'(example.cpp:44).
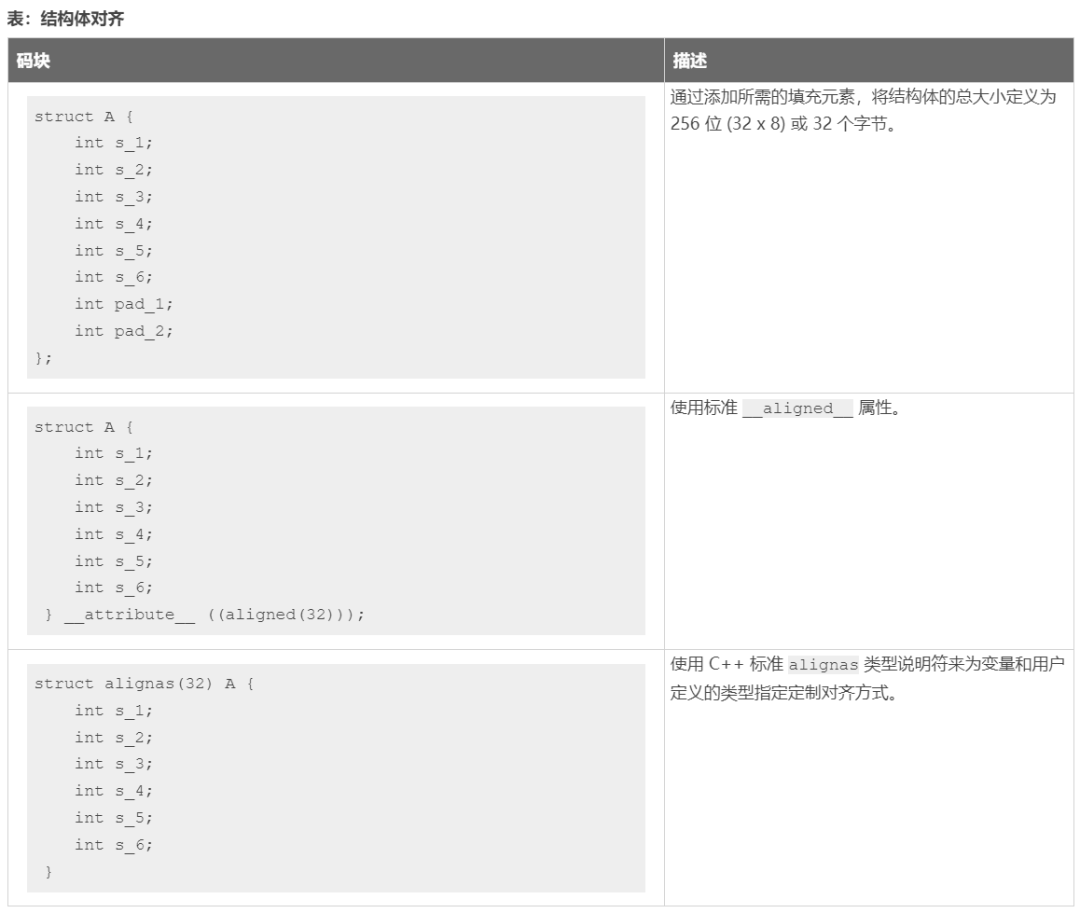
修復此類 II 問題的方法是以 8 個額外字節填充結構體 A,這樣即可始終同時寫入 256 位(32 個字節),或者使用下表所示的其它替代方法。這將允許調度器在 READ/WRITE 循環內按 II=1 來調度讀/寫。
教程與示例
為幫助您快速上手 Vitis HLS,您可在以下位置找到教程與應用示例:
-
Vitis HLS 簡介示例 (https://github.com/Xilinx/Vitis-HLS-Introductory-Examples)包含許多小型代碼示例,用于演示良好的設計實踐、編碼指南、常用應用的設計模式以及(最重要的)最優化技巧,從而最大程度提升應用性能。所有示例都包含 README 文件和 run_hls.tcl 腳本以幫助您使用示例代碼。
-
Vitis 加速示例倉庫 (https://github.com/Xilinx/Vitis_Accel_Examples)包含示例,用于演示 Vitis 工具和平臺的各項功能特性。此倉庫提供了小型有效示例,用于演示與 Vitis 應用加速開發流程的主機代碼和內核編程相關的具體案例。這些示例中的內核代碼均可在 Vitis HLS 中直接編譯。
-
Vitis 應用加速開發流程教程 (https://github.com/Xilinx/Vitis-Tutorials)提供多種教程,通過這些教程可以教授有關工具流程和應用開發的具體概念,包括將 Vitis HLS 作為獨立應用來使用的方式,以及在 Vitis 自下而上的設計流程中使用該工具的方式。
原文標題:Vitis HLS簡介
文章出處:【微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
-
存儲器
+關注
關注
38文章
7528瀏覽量
164349 -
C++
+關注
關注
22文章
2114瀏覽量
73859 -
HLS
+關注
關注
1文章
130瀏覽量
24208 -
Vitis
+關注
關注
0文章
147瀏覽量
7499
原文標題:Vitis HLS簡介
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA高層次綜合HLS之Vitis HLS知識庫簡析
使用Vitis HLS創建屬于自己的IP相關資料分享
如何在Vitis HLS中使用C語言代碼創建AXI4-Lite接口
Vivado HLS和Vitis HLS 兩者之間有什么區別
基于Vitis HLS的加速圖像處理
Vitis HLS工具簡介及設計流程
如何在Vitis HLS中使用C語言代碼創建AXI4-Lite接口
Vitis HLS如何添加HLS導出的.xo文件
Vitis HLS前端現已全面開源
Vitis HLS知識庫總結
理解Vitis HLS默認行為
HLS最全知識庫
AMD全新Vitis HLS資源現已推出
如何在Vitis HLS GUI中使用庫函數?






 工商網監
工商網監
評論