") PolarDB云原生數(shù)據(jù)庫(kù)是如何進(jìn)行性能優(yōu)化的?
PolarDB云原生數(shù)據(jù)庫(kù)是如何進(jìn)行性能優(yōu)化的?
云數(shù)據(jù)庫(kù)實(shí)現(xiàn)計(jì)算存儲(chǔ)分離,支持計(jì)算與存儲(chǔ)的獨(dú)立擴(kuò)展,其用戶還可以享受按量付費(fèi)等特性。這使得基于云數(shù)據(jù)庫(kù)的系統(tǒng)更加高效、靈活。因此,構(gòu)建并使用云原生數(shù)據(jù)庫(kù)的勢(shì)頭愈演愈烈。另一方面,云化存儲(chǔ)服務(wù)已經(jīng)是云的標(biāo)準(zhǔn)能力,存儲(chǔ)側(cè)提供兼容通用的文件接口,并且不對(duì)外暴露持久化、容錯(cuò)處理等復(fù)雜細(xì)節(jié),其易用性和規(guī)模化帶來(lái)的高性價(jià)比使得云存儲(chǔ)成為了云上系統(tǒng)的第一選擇。在通用云存儲(chǔ)服務(wù)上構(gòu)建云數(shù)據(jù)庫(kù),無(wú)疑是一種既能夠享受規(guī)模化云存儲(chǔ)紅利,又能夠通過(guò)可靠云存儲(chǔ)服務(wù)實(shí)現(xiàn)降低維護(hù)成本、加速數(shù)據(jù)庫(kù)開(kāi)發(fā)周期的方案。 然而,考慮到云存儲(chǔ)和本地存儲(chǔ)之間的特性差異,在將本地?cái)?shù)據(jù)庫(kù)遷移到云上構(gòu)建云數(shù)據(jù)庫(kù)時(shí),如何有效使用云存儲(chǔ)面臨了許多挑戰(zhàn)。對(duì)此,我們?cè)谡撐睦锓治隽嘶贐-tree和LSM-tree的存儲(chǔ)引擎在云存儲(chǔ)上部署時(shí)面臨的挑戰(zhàn),并提出了一個(gè)優(yōu)化框架CloudJump,以希望能夠幫助數(shù)據(jù)庫(kù)開(kāi)發(fā)人員在基于云存儲(chǔ)構(gòu)建數(shù)據(jù)庫(kù)時(shí)使系統(tǒng)更為高效。我們以云原生數(shù)據(jù)庫(kù)PolarDB為案例,展示了一系列針對(duì)性優(yōu)化,并將部分工作擴(kuò)展應(yīng)用到基于云存儲(chǔ)的RocksDB上,以此來(lái)演示CloudJump的可用性。
背景 我們討論的云存儲(chǔ)主要基于彈性分布式塊存儲(chǔ),云中其他類型的存儲(chǔ)服務(wù),例如基于對(duì)象的存儲(chǔ),不在本文的討論范圍內(nèi)。共享云存儲(chǔ)(如分布式塊存儲(chǔ)服務(wù)加分布式文件系統(tǒng))可以作為多個(gè)計(jì)算節(jié)點(diǎn)的共享存儲(chǔ)層,提供QoS(服務(wù)質(zhì)量)保證、大容量、彈性和按量付費(fèi)定價(jià)模型。對(duì)于大多數(shù)云廠商和云用戶來(lái)說(shuō),擁有云存儲(chǔ)服務(wù)比構(gòu)建和維護(hù)裸機(jī)SSD集群更有吸引力。因此,與其為云本機(jī)數(shù)據(jù)庫(kù)構(gòu)建和優(yōu)化專用存儲(chǔ)服務(wù),不如利用現(xiàn)有云存儲(chǔ)服務(wù)構(gòu)建云本機(jī)數(shù)據(jù)庫(kù),這是一種非常可行的選擇。此外,隨著云存儲(chǔ)服務(wù)幾乎實(shí)現(xiàn)了標(biāo)準(zhǔn)化,相應(yīng)的開(kāi)發(fā)、遷移變得更加快速。
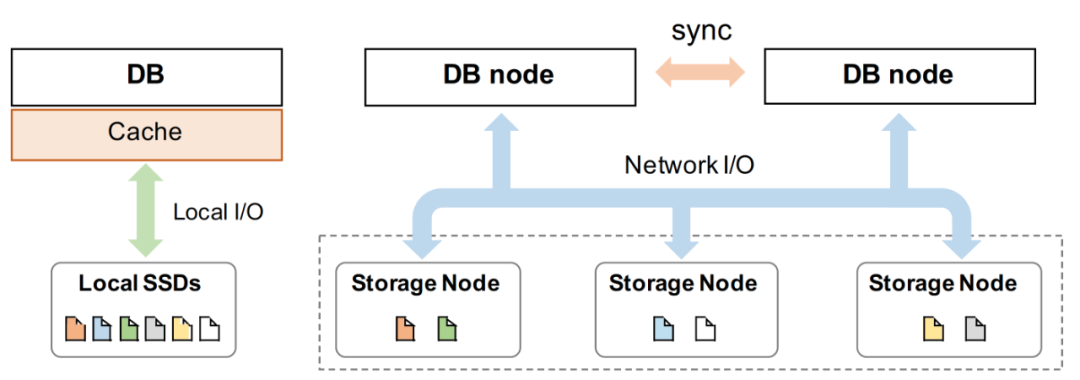
圖1展示了本地?cái)?shù)據(jù)庫(kù)(不含備份)與shared-storage云原生數(shù)據(jù)庫(kù)的系統(tǒng)結(jié)構(gòu),AWS Aurora首先引導(dǎo)了這種從本地?cái)?shù)據(jù)庫(kù)向shared-storage云原生數(shù)據(jù)庫(kù)的遷移。它將數(shù)據(jù)庫(kù)分為存儲(chǔ)層和計(jì)算層,并可以獨(dú)立擴(kuò)展每一層。為了消除了傳輸數(shù)據(jù)頁(yè)中產(chǎn)生的沉重的網(wǎng)絡(luò)開(kāi)銷,它進(jìn)一步定制了存儲(chǔ)層,在數(shù)據(jù)頁(yè)上應(yīng)用重做日志,從而不再需要在兩層之間傳輸數(shù)據(jù)頁(yè)。無(wú)疑這種設(shè)計(jì)在云中提供了一種非標(biāo)準(zhǔn)存儲(chǔ)服務(wù),只能由Aurora的計(jì)算層使用。 另一種方案是依賴標(biāo)準(zhǔn)化接口的云存儲(chǔ)服務(wù)遷移或構(gòu)建獲得云數(shù)據(jù)庫(kù),這也是本文的研究目標(biāo)。前面已經(jīng)提到過(guò),這樣做的優(yōu)勢(shì)主要在于的可以實(shí)現(xiàn)系統(tǒng)的快速開(kāi)發(fā)、平滑遷移、收納標(biāo)準(zhǔn)化規(guī)模化存儲(chǔ)服務(wù)的原有優(yōu)勢(shì)等。此外,特別是在我們項(xiàng)目(PolarDB)的硬件環(huán)境、已有背景下,兼顧服務(wù)可靠性和開(kāi)發(fā)迭代需求,針對(duì)進(jìn)行云存儲(chǔ)服務(wù)特性進(jìn)行性能優(yōu)化是最迫切的第一步。
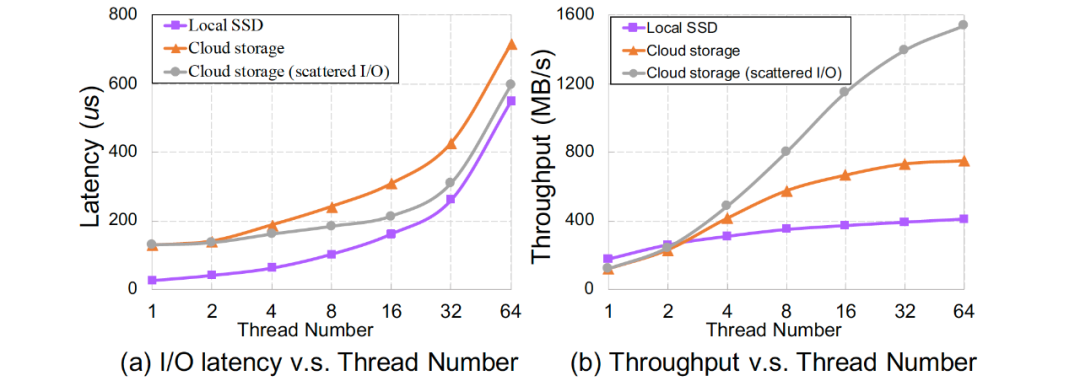
挑戰(zhàn)與分析 云存儲(chǔ)和本地SSD存儲(chǔ)在帶寬、延遲、彈性、容量等方面存在巨大差異,例如圖2展示了在穩(wěn)態(tài)條件下本地SSD與云存儲(chǔ)I/O延時(shí)、帶寬與工作線程關(guān)系,它們對(duì)數(shù)據(jù)庫(kù)等設(shè)計(jì)有著巨大影響。此外,共享存儲(chǔ)的架構(gòu)特性也會(huì)對(duì)云存儲(chǔ)帶來(lái)影響,如多個(gè)節(jié)點(diǎn)之間的數(shù)據(jù)一致性增加了維護(hù)cache一致性開(kāi)銷。
通過(guò)系統(tǒng)實(shí)驗(yàn)、總結(jié)分析等,我們發(fā)現(xiàn)CloudJump面臨以下技術(shù)挑戰(zhàn):
遠(yuǎn)程分布式存儲(chǔ)集群的訪問(wèn)導(dǎo)致云存儲(chǔ)服務(wù)的I/O延遲高;
通常聚合I/O帶寬未被充分利用;
在具有本地存儲(chǔ)的單機(jī)上運(yùn)行良好但需要適應(yīng)云存儲(chǔ)而導(dǎo)致特性改變的傳統(tǒng)設(shè)計(jì),例如文件cache緩存;
長(zhǎng)鏈路導(dǎo)致各種數(shù)據(jù)庫(kù)I/O操作之間的隔離度較低(例如,日志刷寫(xiě)與大量數(shù)據(jù)I/O的競(jìng)爭(zhēng));
云用戶允許且可能使用非常大的單表文件(例如數(shù)十TB)而不進(jìn)行數(shù)據(jù)切分,這加劇了I/O問(wèn)題的影響。
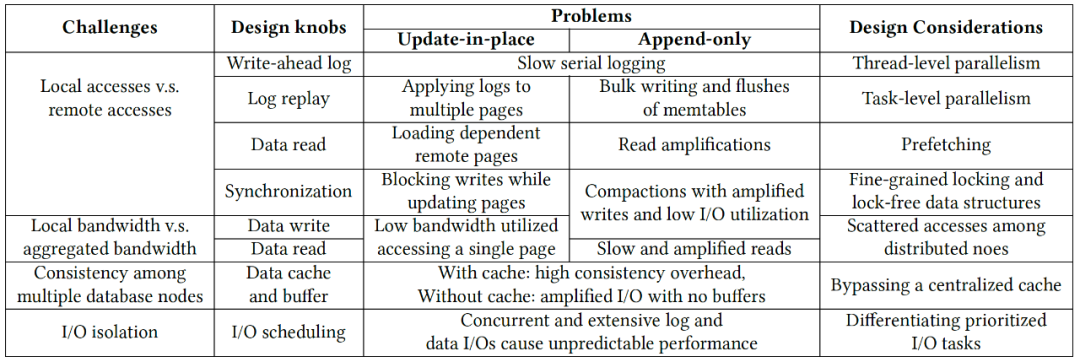
針對(duì)不同的數(shù)據(jù)存儲(chǔ)引擎,如基于B-tree和LSM-tree的存儲(chǔ)引擎,這些特性差異會(huì)帶來(lái)不同的性能差異,表1歸納總結(jié)了這些挑戰(zhàn)及其對(duì)數(shù)據(jù)庫(kù)設(shè)計(jì)的影響。其中有共性問(wèn)題,如WAL路徑寫(xiě)入變慢、共享存儲(chǔ)(分布式文件系統(tǒng))cache一致性代價(jià)等;也有個(gè)性問(wèn)題,如B-tree結(jié)構(gòu)在獨(dú)占資源情況下做遠(yuǎn)程I/O、遠(yuǎn)程加劇I/OLSM-tree讀放大影響等。
優(yōu)化原則 CloudJump針對(duì)上述挑戰(zhàn),提出7條優(yōu)化準(zhǔn)則:
Thread-level Parallelism:例如依據(jù)I/O特性實(shí)驗(yàn),采用(更)多線程的日志、數(shù)據(jù)I/O線程及異步I/O模型,將數(shù)據(jù)充分打散到多個(gè)存儲(chǔ)節(jié)點(diǎn)上。
Task-level Parallelism:例如對(duì)集中Log buffer按Page Partition分片,實(shí)現(xiàn)并行寫(xiě)入并基于分片進(jìn)行并行Recovery。
Reduce remote read and Prefetching:例如通過(guò)收集并聚合原分散meta至統(tǒng)一的superblock,將多個(gè)I/O合一實(shí)現(xiàn)fast validating;通過(guò)預(yù)讀利用聚合讀帶寬、減少讀任務(wù)延時(shí);通過(guò)壓縮、filter過(guò)濾減少讀取數(shù)據(jù)量。與本地SSD上相比,這些技術(shù)在云存儲(chǔ)上更能獲得收益。
Fine-grained Locking and Lock-free Data Structures:云存儲(chǔ)中較長(zhǎng)的I/O延遲放大了同步開(kāi)銷,主要針對(duì)Update-in-place系統(tǒng),實(shí)現(xiàn)無(wú)鎖刷臟、無(wú)鎖SMO等。
Scattering among Distributed Nodes:在云存儲(chǔ)中,多個(gè)節(jié)點(diǎn)之間的分散訪問(wèn)可以利用更多的硬件資源,例如將單個(gè)大I/O并發(fā)分散至不同存儲(chǔ)節(jié)點(diǎn) ,充分利用聚合帶寬。
Bypassing Caches:通過(guò)Bypassing Caches來(lái)避免分布式文件系統(tǒng)的cache coherence,并在DB層面優(yōu)化I/O格式匹配存儲(chǔ)最佳request格式。
Scheduling Prioritized I/O Tasks:由于訪問(wèn)鏈路更長(zhǎng)(如路徑中存在更多的排隊(duì)情況),不填I(lǐng)/O請(qǐng)求間的隔離性相對(duì)本地存儲(chǔ)更低,因此需要在DB層面對(duì)不同I/O進(jìn)行打標(biāo)、調(diào)度優(yōu)先級(jí),例:優(yōu)先WAL、預(yù)讀分級(jí)。
實(shí)踐案例
實(shí)踐案例:PolarDB
PolarDB構(gòu)建基于具有兼容Posix接口的分布式文件系統(tǒng)PolarFS,與Aurora一樣采用計(jì)算存儲(chǔ)分離架構(gòu),借助高速RDMA網(wǎng)絡(luò)以及最新的塊存儲(chǔ)技術(shù)實(shí)現(xiàn)超低延遲和高可用能力能力。在PolarDB上,我們做了許多適配于分布式存儲(chǔ)特性、符合CloudJump準(zhǔn)則的性能優(yōu)化,大幅提升了云原生數(shù)據(jù)庫(kù)PolarDB的性能。
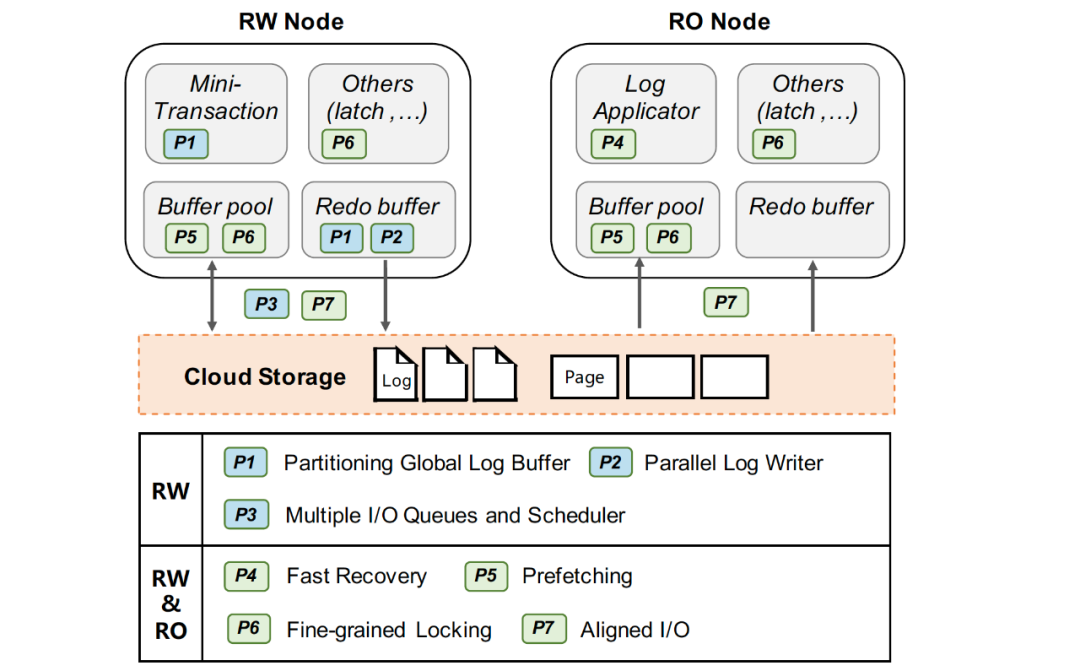
1. WAL寫(xiě)入優(yōu)化 WAL(Write ahead log)寫(xiě)入是用于一致性和持久性的關(guān)鍵路徑,事務(wù)的寫(xiě)入性能對(duì)log I/O的延遲非常敏感。原生InnoDB以MTR(Mini-Transaction)的粒度組織日志,并保有一個(gè)全局redo日志緩沖區(qū)。當(dāng)一個(gè)MTR被提交時(shí),它緩存的所有日志記錄被追加到全局日志緩沖區(qū),然后集中的順序刷盤(pán)以保證持久化特性。這一傳統(tǒng)集中日志模式在本地盤(pán)上工作良好,但使用云存儲(chǔ)時(shí),集中式日志的寫(xiě)入性能隨著遠(yuǎn)程I/O時(shí)延變高而下降,進(jìn)而影響事務(wù)寫(xiě)入性能。基于云存儲(chǔ)的特性,我們提出了兩個(gè)優(yōu)化來(lái)提升WAL的寫(xiě)入性能:日志分片和(大)I/O任務(wù)并行打散。
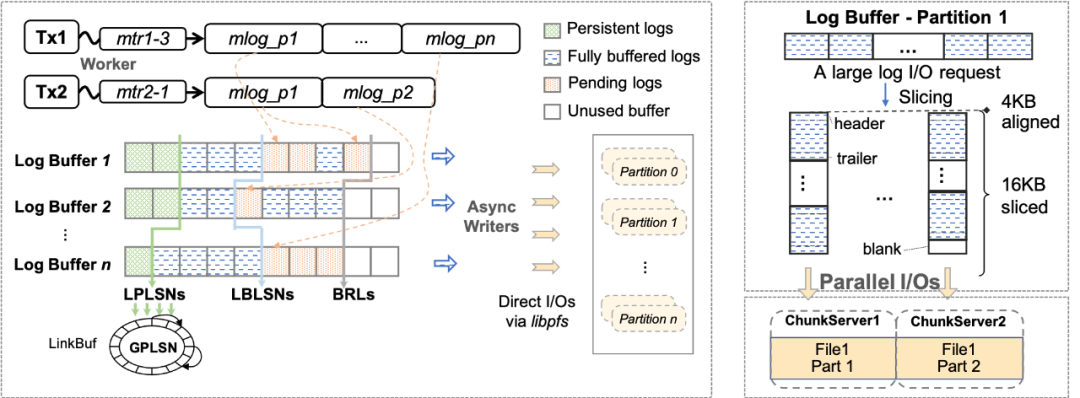
Redo日志分片:InnoDB的redo采用的是Physiological Logging的方式,大部分MTR針對(duì)單個(gè)的數(shù)據(jù)頁(yè)(除部分特殊),頁(yè)之間基本相互獨(dú)立。如圖5(左),我們將redo日志、redo緩沖區(qū)等按其修改的page進(jìn)行分片(partition),分別寫(xiě)入不同的文件中,來(lái)支持并發(fā)寫(xiě)log(以及并發(fā)Recovery,并發(fā)物理復(fù)制等),從而在并發(fā)寫(xiě)友好的分布式文件系統(tǒng)上的獲得寫(xiě)入性能優(yōu)勢(shì)。 I/O任務(wù)并行打散:在云存儲(chǔ)中,一個(gè)文件由多個(gè)chunk組成,根據(jù)chunk的分配策略,不同chunk很可能位于不同的存儲(chǔ)節(jié)點(diǎn)中。我們將每個(gè)redo分片(partition)的文件進(jìn)一步拆分為多個(gè)物理分片(split),如圖5(右)所示,對(duì)于單個(gè)大log I/O任務(wù)(如group commit、BLOB record等),log writer會(huì)將I/O按lsn切片并且并發(fā)的分發(fā)I/O請(qǐng)求至不同split。通過(guò)這種方式,可以將大延時(shí)的log I/O任務(wù)拆分,并利用分布式存儲(chǔ)高分布寫(xiě)特性來(lái)減少整體I/O時(shí)間。 2. 快速恢復(fù) 為了實(shí)現(xiàn)快速恢復(fù),我們提出了兩個(gè)優(yōu)化:快速(啟動(dòng))驗(yàn)證和全并行恢復(fù)。
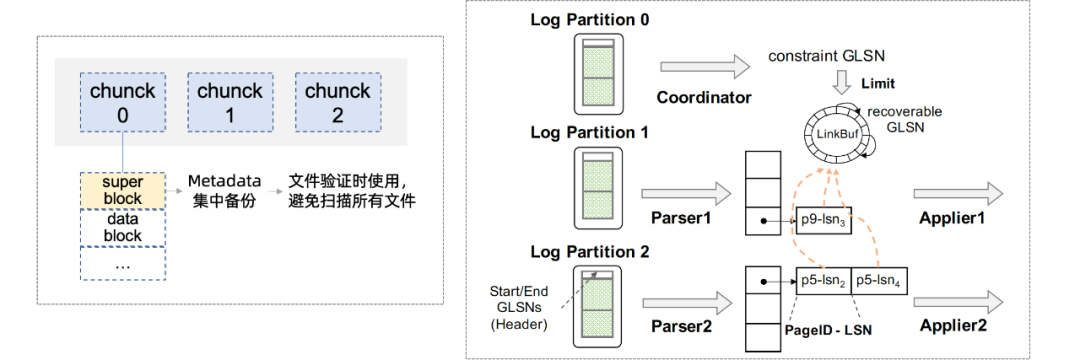
在InnoDB的原有恢復(fù)過(guò)程中,InnoDB首先在啟動(dòng)期間會(huì)打開(kāi)所有文件讀取元信息(如文件名、表ID等)并驗(yàn)證正確性,然后通過(guò)ARIES風(fēng)格的恢復(fù)算法重做未checkpoint的數(shù)據(jù)。為了加速啟動(dòng),快速驗(yàn)證方法不會(huì)掃描所有文件,而是在數(shù)據(jù)庫(kù)的生命周期中記錄和集中必要的元信息,并在創(chuàng)建、修改文件時(shí)將必要的元信息集中記錄在一個(gè)superblock中,在啟動(dòng)時(shí)僅掃描元數(shù)據(jù)塊文件。因此,減少了啟動(dòng)掃描過(guò)程中的遠(yuǎn)程I/O訪問(wèn)開(kāi)銷。其次,依賴于Redo日志分片,我們將log file按page拆分成多個(gè)文件,在恢復(fù)階段(可以進(jìn)一步劃分為parse、redo、undo三個(gè)階段),可以天然的支持并發(fā)parse和redo(undo階段在后臺(tái)進(jìn)行),通過(guò)并發(fā)任務(wù)充分調(diào)動(dòng)CPU和I/O資源加速恢復(fù)。
3. 預(yù)讀取
在云存儲(chǔ)環(huán)境下,讀I/O延時(shí)大大增加,當(dāng)用戶任務(wù)訪問(wèn)數(shù)據(jù)發(fā)生cache miss的情況下,而有效的預(yù)讀取能夠充分利用聚合讀帶寬來(lái)減少讀任務(wù)延時(shí)。InnoDB中有線性預(yù)讀和非線性預(yù)讀兩種原生的物理預(yù)讀方法,我們進(jìn)一步引入了邏輯預(yù)讀策略(由于無(wú)序的插入和更新,索引在物理上不一定是順序的)。例如對(duì)于主索引掃描,當(dāng)任務(wù)線程從起始鍵順序掃描索引超過(guò)一定閾值時(shí),邏輯預(yù)讀會(huì)在主索引上按邏輯順序觸發(fā)異步預(yù)讀,提前讀取一定量的順序頁(yè)。又如對(duì)于具有二級(jí)索引和非索引列回表操作的掃描,在對(duì)二級(jí)索引進(jìn)行掃描同時(shí)批量收集相關(guān)命中的主鍵,積累一定批數(shù)據(jù)后觸發(fā)異步任務(wù)預(yù)讀對(duì)應(yīng)主索引數(shù)據(jù)(此時(shí)剩余的二級(jí)索引掃描可能仍在進(jìn)行中)。
4. 同步(鎖)優(yōu)化
相關(guān)背景可以先查閱《InnoDB btree latch 優(yōu)化歷程》[1]這篇文章。
無(wú)鎖刷臟:原生InnoDB在刷臟時(shí)需要持有當(dāng)前page的sx鎖,導(dǎo)致I/O期間當(dāng)前page的寫(xiě)入被完全阻塞。而在云存儲(chǔ)上I/O延遲更高,阻塞時(shí)間更久。我們采用shadow page的方式,首先對(duì)當(dāng)前page構(gòu)建內(nèi)存副本,構(gòu)建好內(nèi)存副本后原有page的sx鎖被釋放,然后用這個(gè)shadow page內(nèi)容去做刷臟及相關(guān)刷寫(xiě)信息更新。
SMO加鎖優(yōu)化:在InnoDB 里面, 依然有一個(gè)全局的index latch, 由于全局的index latch 存在會(huì)導(dǎo)致同一時(shí)刻在Btree 中只有一個(gè)SMO 能夠發(fā)生, index latch 依然會(huì)成為全局的瓶頸點(diǎn)。上述index latch不僅是計(jì)算瓶頸,而從另一方面考慮,鎖同步期間index上其他可能I/O操作無(wú)法并行,存儲(chǔ)帶寬利用率較低。相關(guān)實(shí)現(xiàn)可以參考文章《路在腳下, 從BTree 到Polar Index》[2]。
5. 多I/O任務(wù)隊(duì)列適配
針對(duì)云存儲(chǔ)具有I/O隔離性低的挑戰(zhàn),同時(shí)為了避免云存儲(chǔ)無(wú)法識(shí)別DB層存儲(chǔ)內(nèi)核的I/O語(yǔ)義,而造成優(yōu)先級(jí)低的I/O請(qǐng)求(如page刷臟、低優(yōu)先級(jí)預(yù)讀)影響關(guān)鍵I/O路徑的性能,在數(shù)據(jù)庫(kù)內(nèi)核中提供合理的I/O調(diào)度模型是很重要的。在 PolarDB 中,我們?cè)跀?shù)據(jù)庫(kù)內(nèi)核層為不同類型的I/O請(qǐng)求進(jìn)行調(diào)度,實(shí)現(xiàn)根據(jù)當(dāng)前I/O壓力實(shí)現(xiàn)數(shù)據(jù)庫(kù)最優(yōu)的性能,每個(gè)I/O請(qǐng)求都具有 DB 層的語(yǔ)義標(biāo)簽,如 WAL 讀/寫(xiě),Page 讀/寫(xiě)。
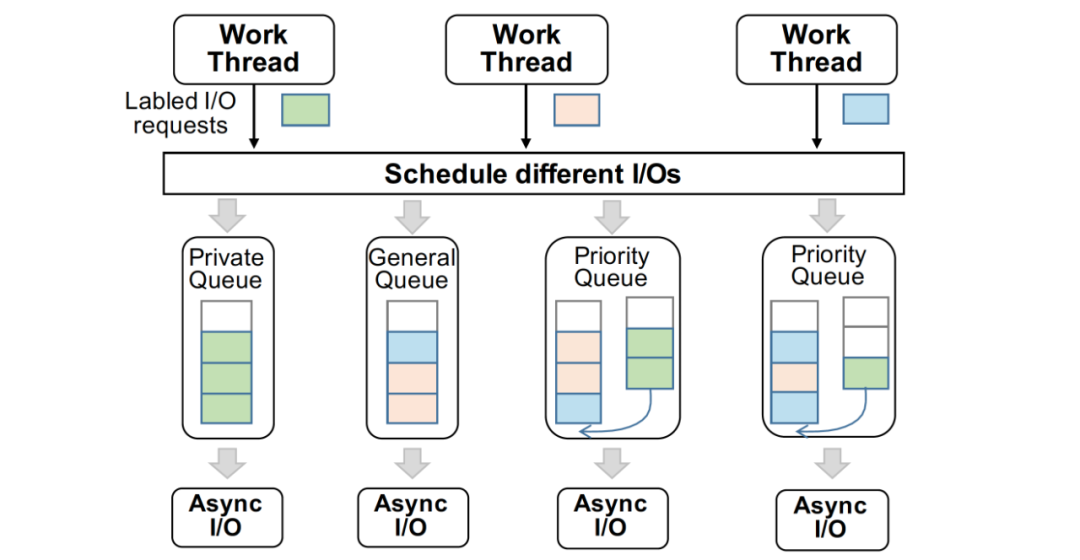
我們?yōu)閿?shù)據(jù)庫(kù)的異步I/O請(qǐng)求建立了多個(gè)支持并發(fā)寫(xiě)入的生產(chǎn)者 / 消費(fèi)者隊(duì)列,并且其存在三種不同特性的隊(duì)列,分別為 Private 隊(duì)列,Priority 隊(duì)列,以及 General 隊(duì)列,不同隊(duì)列的數(shù)量是根據(jù)當(dāng)前云存儲(chǔ)的I/O能力決定的。
正常情況下,WAL 的寫(xiě)入只通過(guò)其 Private 隊(duì)列,當(dāng)寫(xiě)入量增大時(shí),其I/O請(qǐng)求也會(huì)轉(zhuǎn)發(fā)至 Priority 隊(duì)列,此時(shí) Priority 隊(duì)列會(huì)優(yōu)先執(zhí)行 WAL 的寫(xiě)入,并且后續(xù)Page寫(xiě)入的I/O不會(huì)進(jìn)入 Priority 隊(duì)列。基于這種I/O模型,我們保證了一定部分的I/O資源時(shí)預(yù)留給WAL寫(xiě)入,保證事務(wù)提交的寫(xiě)入性能,充分利用云存儲(chǔ)的高聚合帶寬。此外,I/O任務(wù)隊(duì)列的長(zhǎng)度和數(shù)目也進(jìn)行了拓展以一步匹配云存儲(chǔ)高吞吐、大帶寬但時(shí)延較高且波動(dòng)大的特性。
6. 格式化I/O請(qǐng)求
云存儲(chǔ)和本地存儲(chǔ)在I/O格式上具有顯著的不同,例如 Block 大小,I/O請(qǐng)求的發(fā)起方式。在大多數(shù)分布式的云存儲(chǔ)中,在實(shí)現(xiàn)多個(gè)計(jì)算節(jié)點(diǎn)的共享時(shí),為了避免維護(hù)計(jì)算節(jié)點(diǎn) cache 一致性的問(wèn)題,不存在 page cache,此時(shí)采用原先本地存儲(chǔ)的I/O格式在云上會(huì)造成例如 read-on-write 和邏輯與物理位置映射的問(wèn)題,造成性能下降。在 PolarDB中,我們?yōu)閃AL I/O和 Page I/O匹配了適應(yīng)云存儲(chǔ)的請(qǐng)求I/O格式以盡可能降低單個(gè)I/O的延時(shí)。
WAL I/O對(duì)齊:文件是通過(guò)固定大小的 block 進(jìn)行讀寫(xiě)的。云存儲(chǔ)具有更大的 block size (4-128 KB),傳統(tǒng)的 log 對(duì)齊策略不適合云存儲(chǔ)上的 stripe boundary。我們?cè)?log 數(shù)據(jù)進(jìn)行提交的時(shí)候,將I/O請(qǐng)求的長(zhǎng)度和偏移與云存儲(chǔ)的 block size進(jìn)行對(duì)齊。
Data I/O對(duì)齊:例如當(dāng)前存在兩種類型的數(shù)據(jù)頁(yè):常規(guī)頁(yè)和壓縮頁(yè),常規(guī)頁(yè)為16 KB,可以很容易與云存儲(chǔ)的 Block size 進(jìn)行對(duì)齊,但是壓縮頁(yè)會(huì)造成后續(xù)大量的不對(duì)齊I/O。以PolarDB 中對(duì)于壓縮頁(yè)的對(duì)齊為例。首先,我們讀取時(shí)保證以最小單位(如PolarFS的4 KB)讀取。而在寫(xiě)入時(shí),對(duì)于所有小于最小訪問(wèn)單元的壓縮頁(yè)數(shù)據(jù),我們會(huì)拓展到最小單位再進(jìn)行寫(xiě)入,以保證存儲(chǔ)上的頁(yè)數(shù)據(jù)都是最小單位對(duì)齊的。
去除 Data I/O合并:在本地?cái)?shù)據(jù)庫(kù)中,數(shù)據(jù)頁(yè)的I/O會(huì)被合并來(lái)形成大的I/O實(shí)現(xiàn)連續(xù)地順序?qū)懭搿T谠拼鎯?chǔ)中,并發(fā)地向不同存儲(chǔ)節(jié)點(diǎn)寫(xiě)入具有更高的性能,因此在云存儲(chǔ)的數(shù)據(jù)庫(kù)上,可以無(wú)需數(shù)據(jù)頁(yè)的I/O合并操作。
受篇幅所限,我們?cè)诒疚闹兄缓?jiǎn)單介紹所提優(yōu)化方法的大致實(shí)現(xiàn)邏輯,具體實(shí)現(xiàn)細(xì)節(jié)請(qǐng)讀者查閱論文及相關(guān)文章。
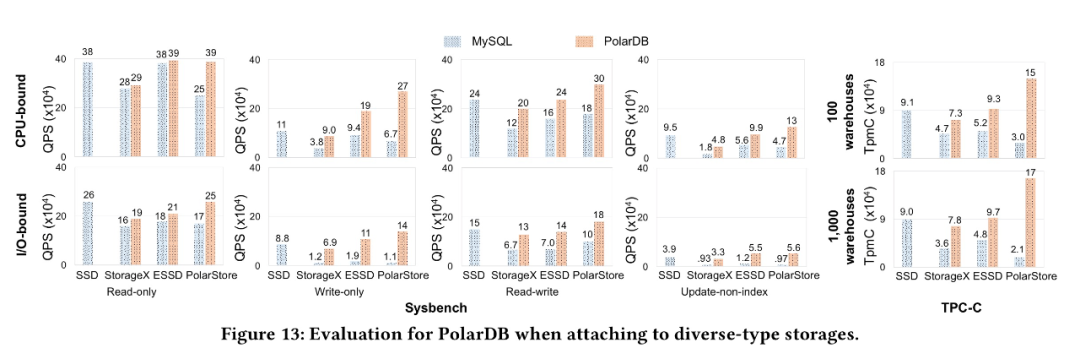
為了驗(yàn)證我們的優(yōu)化效果, 我們對(duì)比了為針對(duì)云存儲(chǔ)優(yōu)化的MySQL 分別運(yùn)行在PolarStore 和 Local Disk, 以及我們優(yōu)化以后的PolarDB, 從下圖可以看到PolarDB 在CPU-bound, IO-bound sysbench, TPCC 等各個(gè)場(chǎng)景下都表現(xiàn)除了明顯的性能優(yōu)勢(shì)。
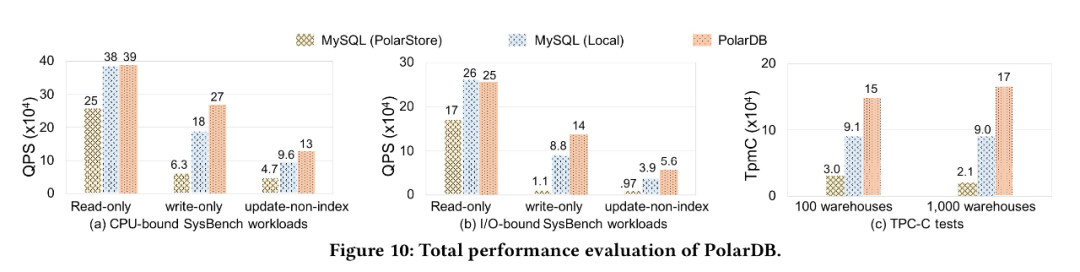
同時(shí), 為了證明我們的優(yōu)化效果不僅僅對(duì)于我們自己的云存儲(chǔ)PolarStore 有收益, 對(duì)于所有的云存儲(chǔ)應(yīng)該都有收益, 因此我們將針對(duì)云存儲(chǔ)優(yōu)化的PolarDB 運(yùn)行在 StorageX, ESSD 等其他云存儲(chǔ)上, 我們發(fā)現(xiàn)均能獲得非常好的性能提升, 從而說(shuō)明我們的優(yōu)化對(duì)于大部分云存儲(chǔ)都是有非常大的收益
實(shí)踐案例:RocksDB
我們還將CloudJump的分析框架和部分優(yōu)化方法拓展到基于云存儲(chǔ)的RocksDB上,同樣獲得了預(yù)計(jì)的性能收益。
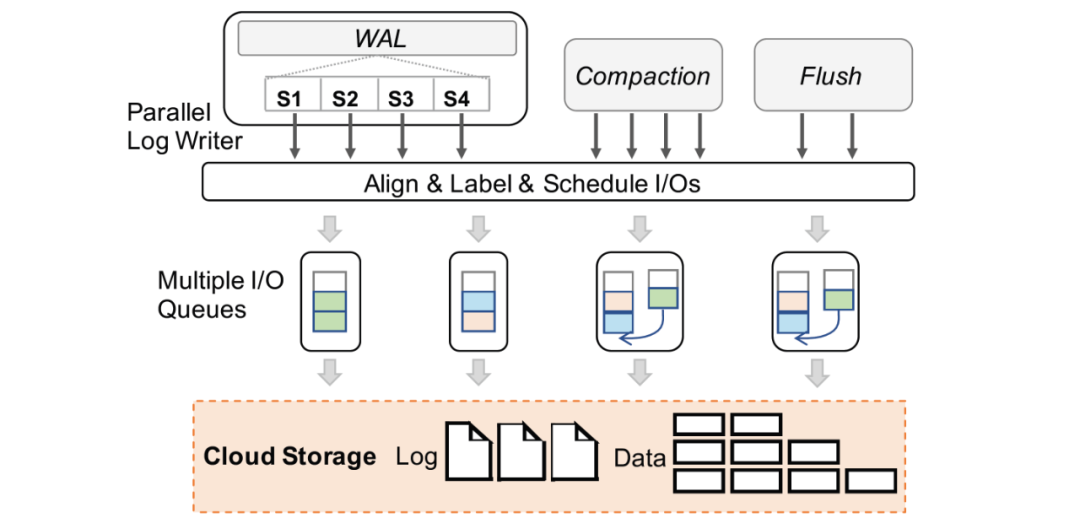
1. Log I/O任務(wù)并行打散
RocksDB同樣使用集中WAL來(lái)保證進(jìn)程崩潰的一致性,集中日志收集多個(gè)column family的日志記錄并持久化至單個(gè)日志文件。考慮到LSM-Tree只需要恢復(fù)尾部append-only的數(shù)據(jù)塊,我們采用在上一個(gè)案例中提到的log I/O并行打散的方法在log writer中切分批日志并且并行分發(fā)到不同文件分片中。
2. 數(shù)據(jù)訪問(wèn)加速
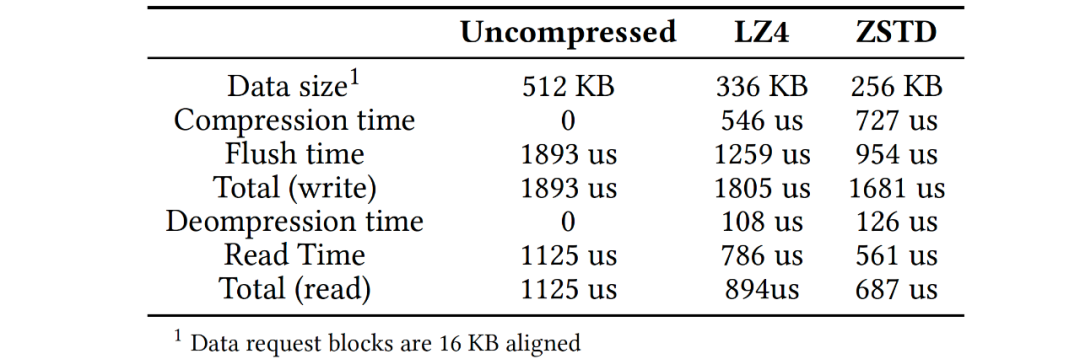
在RocksDB中有許多加速數(shù)據(jù)訪問(wèn)的技術(shù),主要有prefetching, filtering 和compression機(jī)制。考慮到云存儲(chǔ)的特性,這些技術(shù)(經(jīng)過(guò)適當(dāng)改造)在云存儲(chǔ)環(huán)境中更有價(jià)值。經(jīng)過(guò)分析和實(shí)驗(yàn),我們提出了以下建議:1)預(yù)讀機(jī)制能加速部分查詢和compaction操作,建議compaction操作開(kāi)啟預(yù)讀并設(shè)定合理的預(yù)讀I/O任務(wù)優(yōu)先級(jí),并將單個(gè)預(yù)讀操作的大小對(duì)齊存儲(chǔ)粒度,對(duì)于查詢操作預(yù)讀應(yīng)由用戶場(chǎng)景確定;2)在云存儲(chǔ)上建議開(kāi)啟bloom filters,并且將filter的meta和常規(guī)數(shù)據(jù)分離,將filter信息并集中管理;3)采用塊壓縮來(lái)減小數(shù)據(jù)訪問(wèn)的整體用時(shí),如下表展示了數(shù)據(jù)量和PolarFS訪問(wèn)延時(shí),表中存儲(chǔ)基于RDMA,在延遲更高的存儲(chǔ)環(huán)境中,壓縮收益更高,引入壓縮后數(shù)據(jù)訪問(wèn)的整體延時(shí)(特別是讀延時(shí))下降。
3. 多I/O任務(wù)隊(duì)列及適配
在多核硬件環(huán)境中,我們引入了一個(gè)多隊(duì)列I/O模型并在RocksDB中拆分I/O任務(wù)和工作任務(wù)(例如壓縮作業(yè)和刷新作業(yè))。這是因?yàn)槲覀兺ㄟ^(guò)調(diào)整I/O線程的數(shù)量來(lái)控制較好吞吐和延遲關(guān)系。由于將I/O任務(wù)與后臺(tái)刷寫(xiě)作業(yè)分離,因此無(wú)需進(jìn)一步增加刷寫(xiě)線程的數(shù)量,刷寫(xiě)線程只會(huì)對(duì)齊I/O請(qǐng)求并進(jìn)行調(diào)度分發(fā)。RocksDB本身提供了基于線程角色的優(yōu)先級(jí)調(diào)度方案,而我們的調(diào)度方法這里是基于I/O標(biāo)簽。
我們根據(jù)云存儲(chǔ)調(diào)整I/O請(qǐng)求和數(shù)據(jù)組織(例如block和SST)的大小,并進(jìn)行更精確的控制,以使SST文件過(guò)濾器的塊大小也正確對(duì)齊。以PolarFS為例,存儲(chǔ)的最小請(qǐng)求大小為4 KB(表示最小的處理單元),理想的請(qǐng)求大小為16 KB的倍數(shù)(不造成read-on-write),元數(shù)據(jù)存儲(chǔ)粒度為4 MB。SST大小和塊大小分別嚴(yán)格對(duì)齊存儲(chǔ)粒度和理想請(qǐng)求大小的倍數(shù)。原生RocksDB也有對(duì)齊策略,我們?cè)诖诵枰M(jìn)行存儲(chǔ)參數(shù)適配并且對(duì)壓縮數(shù)據(jù)塊也進(jìn)行對(duì)齊。
我們不會(huì)向多隊(duì)列I/O模型傳遞小于最小請(qǐng)求大小的I/O請(qǐng)求,而是對(duì)齊最小I/O大小,并將未對(duì)齊的后綴緩存在內(nèi)存中以供后續(xù)對(duì)齊使用。其次,我們不會(huì)下發(fā)單個(gè)大于存儲(chǔ)粒度的I/O請(qǐng)求,而是通過(guò)多隊(duì)列I/O模型執(zhí)行并行任務(wù)(例如一個(gè)6 MB的I/O會(huì)分散成4 MB加1 MB的兩個(gè)任務(wù))。這不僅可以將數(shù)據(jù)盡可能分散在不同的存儲(chǔ)節(jié)點(diǎn)上,還可以最大限度地提高并行性以充分利用帶寬。
4. I/O對(duì)齊
在所有日志和數(shù)據(jù)I/O請(qǐng)求排入隊(duì)列前,對(duì)其的大小和起始o(jì)ffset進(jìn)行對(duì)齊。對(duì)于WAL寫(xiě)入路徑,類似于PolarDB的log I/O對(duì)齊。對(duì)于數(shù)據(jù)寫(xiě)入路徑,在采用數(shù)據(jù)壓縮時(shí),LSM樹(shù)結(jié)構(gòu)可能會(huì)有大量未對(duì)齊的數(shù)據(jù)塊。例如要刷寫(xiě)從1 KB開(kāi)始的2 KB日志數(shù)據(jù)時(shí),它將從內(nèi)存緩存的數(shù)據(jù)中填充前1 KB(對(duì)于append-only結(jié)構(gòu)通過(guò)保存尾部數(shù)據(jù)緩存實(shí)現(xiàn),這是與update-in-place結(jié)構(gòu)直接拓展原生頁(yè)至最小單位的不同之處),并在3-4 KB中附加零,然后從0 KB起始發(fā)送一個(gè)4 KB的I/O。
總結(jié)
在這項(xiàng)論文工作中,我們分析了云存儲(chǔ)的性能特征,將它們與本地SSD存儲(chǔ)進(jìn)行了比較,總結(jié)了它們對(duì)B-tree和LSM-tree類數(shù)據(jù)庫(kù)存儲(chǔ)引擎設(shè)計(jì)的影響,并推導(dǎo)出了一個(gè)框架CloudJump來(lái)指導(dǎo)本地存儲(chǔ)引擎遷移到云存儲(chǔ)的適配和優(yōu)化。并通過(guò)PolarDB, RocksDB 兩個(gè)具體Case 展示優(yōu)化帶來(lái)的收益。
審核編輯 :李倩
-
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3846瀏覽量
64685 -
云存儲(chǔ)
+關(guān)注
關(guān)注
7文章
773瀏覽量
46153
原文標(biāo)題:過(guò)去5年,PolarDB云原生數(shù)據(jù)庫(kù)是如何進(jìn)行性能優(yōu)化的?
文章出處:【微信號(hào):inf_storage,微信公眾號(hào):數(shù)據(jù)庫(kù)和存儲(chǔ)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
云原生AI服務(wù)怎么樣
云原生LLMOps平臺(tái)作用
鴻蒙原生頁(yè)面高性能解決方案上線OpenHarmony社區(qū) 助力打造高性能原生應(yīng)用
艾體寶與Kubernetes原生數(shù)據(jù)平臺(tái)AppsCode達(dá)成合作
什么是云原生MLOps平臺(tái)
AI時(shí)代的數(shù)據(jù)庫(kù)技術(shù)發(fā)展論壇亮點(diǎn)前瞻
軟通動(dòng)力榮登2024云原生企業(yè)TOP50榜單
云原生和數(shù)據(jù)庫(kù)哪個(gè)好一些?
PolarDB-MySQL引擎層的索引前綴壓縮能力的技術(shù)實(shí)現(xiàn)和效果
云原生和非云原生哪個(gè)好?六大區(qū)別詳細(xì)對(duì)比
從積木式到裝配式云原生安全
基于DPU與SmartNic的云原生SDN解決方案
阿里云與中興通訊達(dá)成開(kāi)源數(shù)據(jù)庫(kù)合作,助推國(guó)產(chǎn)數(shù)據(jù)庫(kù)發(fā)展
華為云多模數(shù)據(jù)庫(kù) GeminiDB 架構(gòu)與應(yīng)用實(shí)踐直播問(wèn)答實(shí)錄
華為云原生多模數(shù)據(jù)庫(kù) GeminiDB 架構(gòu)與應(yīng)用實(shí)踐

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論