 圖像去噪方法總結
圖像去噪方法總結
圖像降噪的英文名稱是Image Denoising, 圖像處理中的專業術語。是指減少數字圖像中噪聲的過程,有時候又稱為圖像去噪。
噪聲是圖像干擾的重要原因。一幅圖像在實際應用中可能存在各種各樣的噪聲,這些噪聲可能在傳輸中產生,也可能在量化等處理中產生。根據噪聲和信號的關系可將其分為三種形式:(f(x, y)表示給定原始圖像,g(x, y)表示圖像信號,n(x, y)表示噪聲。)
1)加性噪聲,此類噪聲與輸入圖像信號無關,含噪圖像可表示為f(x, y)=g(x, y)+n(x, y),信道噪聲及光導攝像管的攝像機掃描圖像時產生的噪聲就屬這類噪聲;
2)乘性噪聲,此類噪聲與圖像信號有關,含噪圖像可表示為f(x, y)=g(x, y)+n(x ,y)g(x, y),飛點掃描器掃描圖像時的噪聲,電視圖像中的相干噪聲,膠片中的顆粒噪聲就屬于此類噪聲。
3)量化噪聲,此類噪聲與輸入圖像信號無關,是量化過程存在量化誤差,再反映到接收端而產生。 目前來說圖像去噪分為三大類:基于濾波器的方法(Filtering-Based Methods)、基于模型的方法(Model-Based Methods)和基于學習的方法(Learning-Based Methods)。 接下來讓我們分別來看一下,這幾種去噪方法的優缺點。
01
基于濾波器的方法
經典的基于濾波的方法,如中值濾波和維納濾波等,利用某些人工設計的低通濾波器來去除圖像噪聲。
中值濾波器[1]:它是一種常用的非線性平滑濾波器,其基本原理是把數字圖像或數字序列中一點的值用該點的一個領域中各點值的中值代換,其主要功能是讓周圍像素灰度值的差比較大的像素改取與周圍的像素值接近的值,從而可以消除孤立的噪聲點,所以中值濾波對于濾除圖像的椒鹽噪聲非常有效。
自適應維納濾波器[2]:它能根據圖像的局部方差來調整濾波器的輸出,局部方差越大,濾波器的平滑作用越強。
同一個圖像中具有很多相似的圖像塊,可以通過非局部相似塊堆疊的方式去除噪聲,如經典的非局部均值(NLM)算法[3]、基于塊匹配的3D濾波(BM3D)算法[4]等。缺點:1. 塊操作會導致模糊輸出。2. 需要手動設置超參數。
02
基于模型的方法
基于模型的方法試圖對自然圖像或噪聲的分布進行建模。然后,它們使用模型分布作為先驗,試圖獲得清晰的圖像與優化算法。基于模型的方法通常將去噪任務定義為基于最大后驗(MAP)的優化問題,其性能主要依賴于圖像的先驗。如Xu等人[5]提出了一種基于低秩矩陣逼近的紅外加權核范數最小化(WNNM)方法。Pang等人[9]引入了基于圖的正則化器來降低圖像噪聲。 在過去的幾十年中,各種基于模型的方法已經被用于圖像先驗建模,包括非局部自相似(NSS)模型,稀疏模型,梯度模型和馬爾可夫隨機場(MRF)模型。盡管它們具有高的去噪質量,但是大多數基于圖像先驗方法都有兩個缺點:
這些方法在測試階段通常涉及復雜的優化問題,使去噪過程時非常耗時的。因此,大多數基于先驗圖像先驗方法在不犧牲計算效率的情況下很難獲得高性能。
模型通常是非凸的并且涉及幾個手動選擇的參數,提供一些余地以提高去噪性能。
為了克服先驗方法的局限性,最近開發了幾種判別學習方法以在截斷推理過程的背景下,學習圖像先驗模型。得到的先驗模型能夠擺脫測試階段的迭代優化過程。Schmidt和Roth提出了一種收縮場級聯(CSF)方法,該方法將基于隨機場的模型和展開的半二次優化算法統一為一個學習框架。陳等人提出了一種可訓練的非線性反應擴散(TNRD)模型,該模型通過展開固定數量的梯度下降推斷步驟來學習改進的專家領域。盡管CSF和TNRD在彌補計算效率和去噪質量上的差距方面已經取得了好的效果,但它們的性能本質上僅限于先前那種特定的形式。具體而言,CSF和TNRD采用的先驗是基于分析模型,這個模型在捕獲圖像結構整體特征上被限制。此外,通過階段式貪婪訓練以及所有階段之間的聯合微調來學習參數,并且涉及許多手工參數。另外一個不可忽視的缺點是他們針對特定水平的噪音訓練特定的模型,并且在盲圖像去噪上受限制。 雖然這些基于模型的方法有很強的數學推導性,但在重噪聲下恢復紋理結構的性能將顯著下降。此外,由于迭代優化的高度復雜性,它們通常是耗時的。
03
基于學習的方法
基于學習的方法側重于學習有噪聲圖像到干凈圖像的潛在映射,可以分為傳統的基于學習的方法和基于深度網絡的學習方法。近年來,由于基于深度網絡的方法比基于濾波、基于模型和傳統的基于學習的方法獲得了更有前景的去噪結果,它們已成為主流方法。 Zhang等人[6]通過疊加卷積、批歸一化和校正線性單元(ReLU)層,提出了一種簡單但有效的去噪卷積神經網絡(CNN)。 受圖像非局部相似度的啟發,將非局部操作納入到的循環神經網絡中[7]。 Anwar等人[8]提出了一種帶特征注意力的單階段去噪網絡。 DnCNN[10]、FFDnet[11]、CBDnet[12]這三篇覺得應該是聯系十分緊密的一個系列,是逐步泛化,逐步考慮增加噪聲復雜的一個過程,DnCNN主要針對高斯噪聲進行去噪,強調殘差學習和BN的作用,FFDnet考慮將高斯噪聲泛化為更加復雜的真實噪聲,將噪聲水平圖作為網絡輸入的一部分,CBDnet主要是針對FFDnet的噪聲水平圖部分入手,通過5層FCN來自適應的得到噪聲水平圖,實現一定程度上的盲去噪。 DnCNN使用了Batch Normalization和Residual Learning加速訓練過程和提升去噪性能。網絡的結構圖如下:
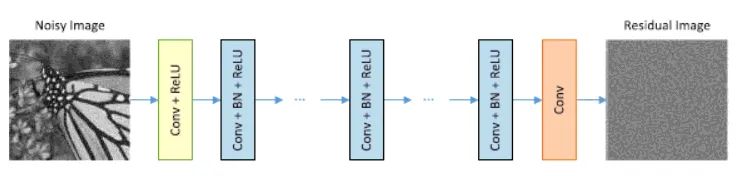
FFDNet側重與去除更加復雜的高斯噪聲。主要是不同的噪聲水平。之前的基于卷積神經網絡的去噪算法,大多數都是針對于某一種特定噪聲的,為了解決不同噪聲水平的問題,FFDNet的作者利用noise level map作為輸入,使得網絡可以適用于不同噪聲水平的圖片:

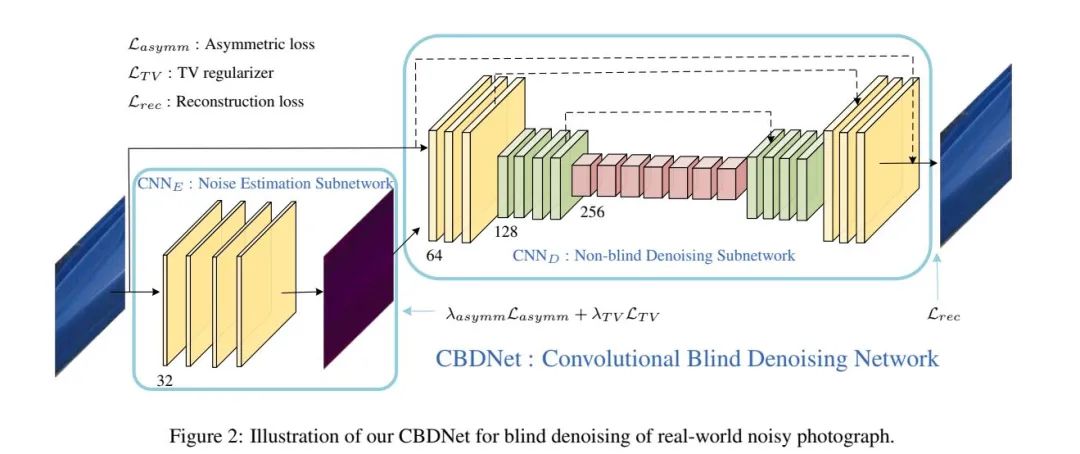
CBDNet網絡由噪聲估計子網絡和去噪子網絡兩部分組成。同時進行end to end的訓練。并采用基于信號獨立的噪聲以及相機內部處理的噪聲合成的圖片和真是的噪聲圖片(所謂“真實”的噪聲圖片是來自于別人的數據集RENOIR、DND、NC12等,)聯合訓練。提高去噪網絡的泛化能力,也增強去噪的效果:
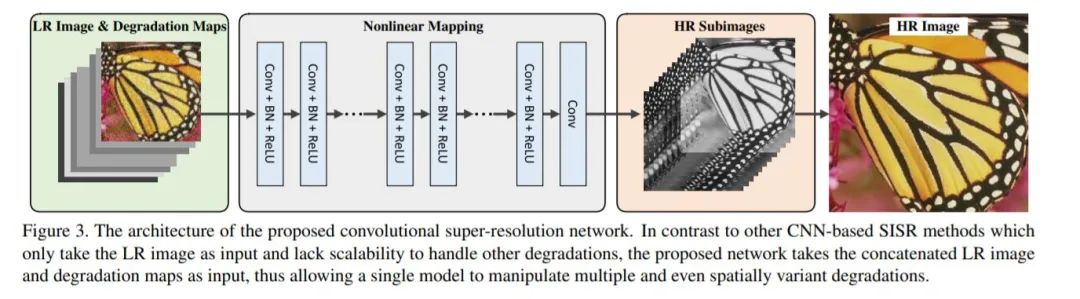
SRMD[13]不同于前三篇,主要是從bicubic入手,考慮模糊核和噪聲水平的影響,將LR、模糊核、噪聲水平統一的輸入網絡中,來實現對不同退化模型的復原。可以將退化圖和LR圖像合并在一起作為CNN的輸入。為了證明此策略的有效性,選取了快速有效的ESPCN超分辨網絡結構框架。值得注意的是為了加速訓練過程的收斂速度,同時考慮到LR圖像中包含高斯噪聲,因此網絡中加入了Batch Normalization層。網絡結構如下圖所示:
等等等...... 基于深度網絡的方法具有很大的發展潛力,但是它主要依靠于經驗設計,沒有充分考慮到傳統的方法,在一定程度上缺乏可解釋性。所以最新的CVPR2021論文:Adaptive Consistency Prior based Deep Network for Image Denoising就是通過可解釋性來設計網絡的,它首先,在傳統一致性先驗中引入非線性濾波算子、可靠性矩陣和高維特征變換函數,提出一種新的自適應一致性先驗(ACP)。其次,將ACP項引入最大后驗框架,提出了一種基于模型的去噪方法。該方法進一步用于網絡設計,形成了一種新穎的端到端可訓練和可解釋的深度去噪網絡,稱為DeamNet。網絡結構如下如所示:
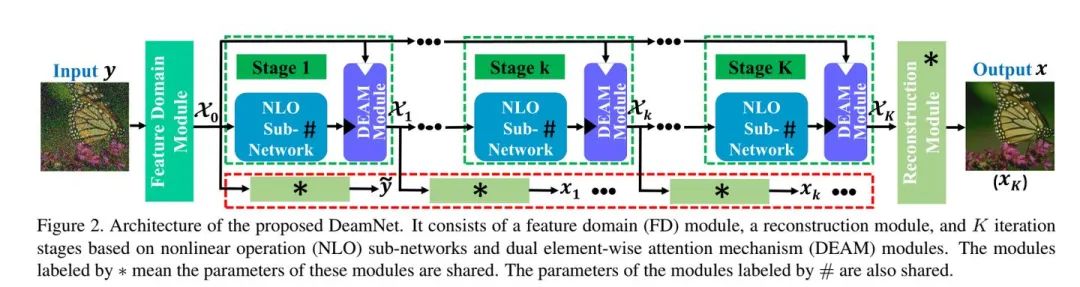
DeamNet整體的網絡結構
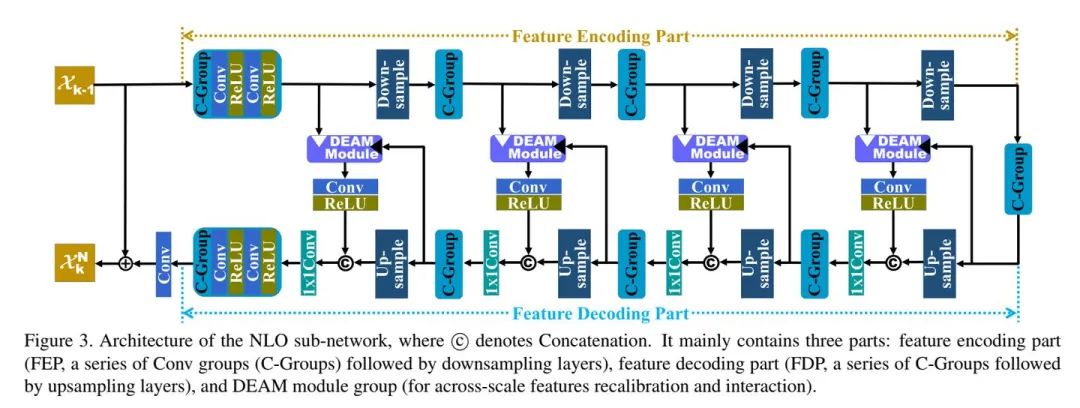
NLO子網絡結構
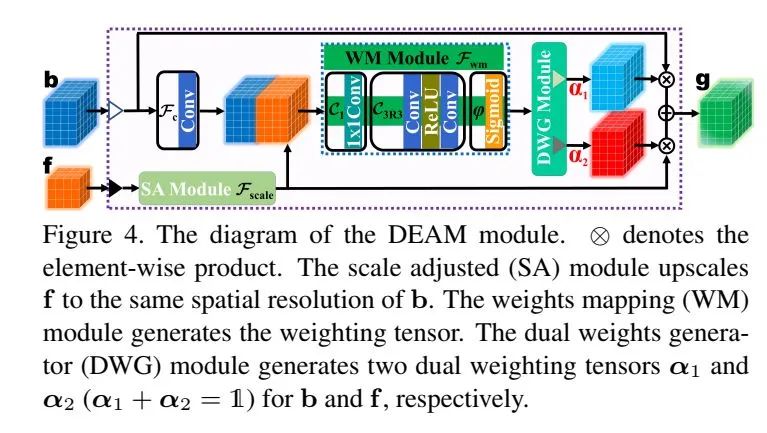
DEAM注意力模塊
04
數據集的發展
近年來,去噪問題的研究焦點已經從AWGN(添加高斯白噪聲)如BSD68、Set12等轉向了更真實的噪聲。最近的一些研究工作在真實噪聲圖像方面取得了進展,通過捕獲真實的噪聲場景,建立了幾個真實的噪聲數據集如DnD、RNI15、SIDD等,促進了對真實圖像去噪的研究。

‘test039’from BSD68 (合成的噪聲圖像)

‘Starfish’from Set12 (合成的噪聲圖像)
DnD(真實的噪聲圖像)

RNI15(真實的噪聲圖像)

SIDD(真實的噪聲圖像)
審核編輯 :李倩
-
濾波器
+關注
關注
161文章
7862瀏覽量
178948 -
圖像處理
+關注
關注
27文章
1300瀏覽量
56899 -
圖像
+關注
關注
2文章
1089瀏覽量
40575
原文標題:圖像去噪方法總結,最全、最詳細……
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于中國汽研風噪標模的風噪共性課題征集

Mamba入局圖像復原,達成新SOTA
AD9914相位截斷導致相噪變差,這個問題怎么解決?
tlv320aic3106底噪過大要如何解決?
高斯卷積核函數在圖像采樣中的意義
運放的反饋電阻習慣性并聯上一個反饋電容,主要目的就是去噪,為什么會起到這種作用?
圖像識別算法都有哪些方法
圖像識別技術的原理是什么
機器人視覺技術中常見的圖像分割方法
機器人視覺技術中圖像分割方法有哪些
ESP32-S2-Kaluga-1更新了重新編譯的camera代碼,比出廠時噪點多很多怎么解決?
示波器如何測量底噪?示波器測量底噪的步驟
基于FPGA的常見的圖像算法模塊總結

OpenCV筑基之圖像的仿射變換方法總結





 工商網監
工商網監
評論