") DocumentAI的模型、任務和基準數(shù)據(jù)集
DocumentAI的模型、任務和基準數(shù)據(jù)集
隨著最近幾年多模態(tài)大火的,越來越多的任務都被推陳出新為多模態(tài)版本。譬如,傳統(tǒng)對話任務,推出了考慮視覺信息的多模態(tài)數(shù)據(jù)集;事件抽取,也推出視頻形式的多模態(tài)版本;就連 grammar induction(語法歸納),也有了多模態(tài)版的(詳見 NAACL'2021 best paper)。
然而,多模態(tài)大火雖是最近的事情,但它并不是近兩年才有的什么新技術。如果是想要對這一領域有比較深的研究,甚至想要做出工作、有所創(chuàng)新,那僅僅了解多模態(tài)最近兩年幾個大火的多模態(tài)模型顯然是不足夠的。
事實上,有些任務已經(jīng)天生就是多模態(tài)很多年了。早在多模態(tài)成為焦點之前,就已經(jīng)默默被研究二十來年了。比如,智能文檔(Document AI)技術。所謂智能文檔技術,也就是自動理解、分析業(yè)務文檔技術,文檔內(nèi)容可包含文字、圖片、視頻等多種形式。由于理解多模態(tài)形式的多模態(tài)形式文的需求其實廣泛長期存在,所以智能文檔技術很多年來都是幾個大廠的研究重點之一。近年來,深度學習技術的普及也更好地推動了例如文檔布局分析、可視化信息提取、文檔可視化問答、文檔圖像分類等智能文檔算法的發(fā)展。近期,微軟亞研院發(fā)表了一篇綜述,簡要回顧了一些有代表性的DocumentAI的模型、任務和基準數(shù)據(jù)集。小編認為這篇概述的總結體系非常扎實,是值得細細閱讀的多模態(tài)相關綜述,故與各位分享。
Document AI 發(fā)展歷程
作者概述智能文檔的發(fā)展大致經(jīng)歷了以下三個階段:
第一階段: 啟發(fā)式階段
20世紀90年代初,研究人員主要使用基于規(guī)則的啟發(fā)式(Heuristic rule-based document layout analysis)來理解和分析文檔,通過手動觀察文檔的布局信息,從而總結出一些啟發(fā)式規(guī)則。啟發(fā)式規(guī)則方法主要使用固定的布局信息來處理文檔.方法較為固定,定制的規(guī)則可擴展性較差,通用性較差。
基于啟發(fā)式規(guī)則的文檔的布局分析大致分為三種方式:
(1)自頂向下:文檔圖像逐步劃分到不同的區(qū)域,遞歸執(zhí)行切割直到該區(qū)域被劃分為預定義的標準,通常是塊或列。例如projection profile,采用X-Y cut算法對文檔進行剪切,通常用于文本區(qū)域和行距固定的結構化文本,對特定格式的文檔進行更快、更有效的分析.但其對邊界噪聲敏感,對傾斜文本的處理效果不佳。
(2)自底向上:使用像素或組件作為基本單元,將其分組并合并成一個更大的同質(zhì)區(qū)域,自底向上方法雖然需要更多的計算資源,但更通用,可以覆蓋更多具有不同布局類型的文檔。
(3)混合策略:將自上而下和自下而上相結合,例如Okamoto & Takahashi使用分隔符和空格來切割塊,并將內(nèi)部組件進一步合并到每個塊中的文本行中,進而解析文檔的布局。
第二階段:機器學習階段
直到從2000年來 隨著機器學習技術的發(fā)展,以機器學習模型逐漸成為文檔處理的主流方法。研究者設計功能模板以了解不同功能的權重,進而理解和分析文檔的內(nèi)容和布局。
基于機器學習的文檔分析過程通常分為兩個階段:
1)對文檔圖像進行分割,獲得多個候選區(qū)域;
2)對文檔區(qū)域進行分類和區(qū)分,如文本塊和圖像。
盡管帶注釋的數(shù)據(jù)被用于監(jiān)督學習,并且以前的方法可以帶來一定程度的性能改進,但是由于缺乏定制規(guī)則和訓練樣本數(shù)量,通用性仍然不令人滿意。此外,不同類型文檔的遷移和適應成本相對較高,這使得以前的方法不適合廣泛的商業(yè)應用。
第三階段:深度學習階段
隨著深度學習的發(fā)展和大量未標注電子文檔的積累,可以通過工具HTML/XML提取、PDF解析器、OCR等提取不同類型的文檔中的內(nèi)容,其文本內(nèi)容、布局信息和基本圖像信息等基本組織良好,然后對大規(guī)模深度神經(jīng)網(wǎng)絡進行預訓練和微調(diào),以完成各種下游文檔AI任務.包括文檔布局分析、視覺信息提取、文檔視覺問答和文檔圖像分類等。現(xiàn)有的基于深度學習的智能文檔模型主要分為兩大類:
針對特定任務的深度學習模型
支持各種下游任務的通用預訓練模型
DocumentAI的主要任務
Document AI在我們現(xiàn)實的應用場景主要有以下四類任務:
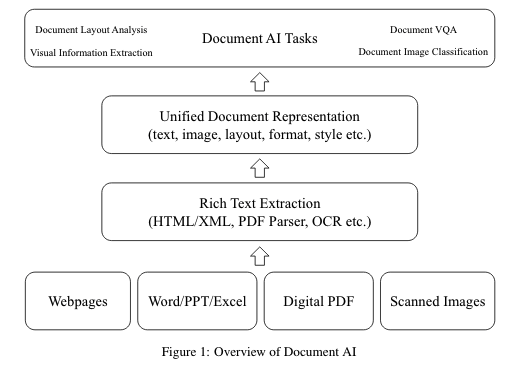
Document Layout Analysis
該任務主要是對文檔布局中的圖像、文本、表格、圖等位置關系進行自動分析、識別、理解的過程.主要分為兩個主任務:Visual analysis 與Semantic analysis.Visual analysis為視覺元素的分析,主要目的是檢測文檔的結構,確定相似區(qū)域的邊界,而Semantic analysis為語義分析檢測區(qū)域識別特定的文檔元素,例如標題、段落、表格等。
Visual Information Extraction
該任務從文檔中的大量非結構化內(nèi)容中提取實體及關系.對于視覺豐富的文檔建模為計算機視覺問題,通過語義分割或文本框檢測來進行信息提取,將文檔圖像視為像素網(wǎng)格,將文本特征添加到視覺特征圖中。根據(jù)文本信息的粒度,該任務從字符級發(fā)展到單詞級,再發(fā)展到上下文級。
Document Visual Question Answering
該任務為通過判斷識別文本的內(nèi)部邏輯來回答關于文檔的自然語言問題。文檔VQA中的文本信息在任務中起著至關重要的作用,現(xiàn)有的有代表性的方法都是以文檔圖像的OCR獲取的文本作為輸入。獲得文檔文本后,將VQA任務建模為不同的問題.主流方法將其建模為機器閱讀理解(MRC)問題,根據(jù)問題從給定文檔中提取文本片段作為相應的答案。
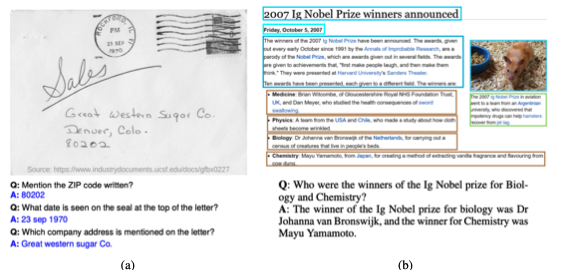
Document Image Classi?cation
該任務是對文檔圖像進行分析和識別,并將其劃分為不同類別的過程,如科學論文、簡歷、發(fā)票、收據(jù)等。最早文檔圖像分類問題的方法與自然圖像分類方法基本一樣,例如基于CNN的文檔圖像分類方法使用經(jīng)過ImageNet訓練的Alexnet作為初始化對文檔圖像進行模型適配。
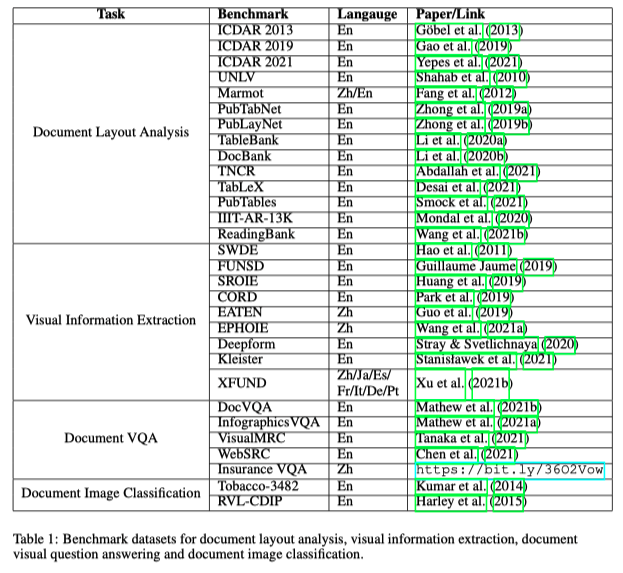
下圖為作者整理的四大Task的Benchmark:
Document AI 主流模型
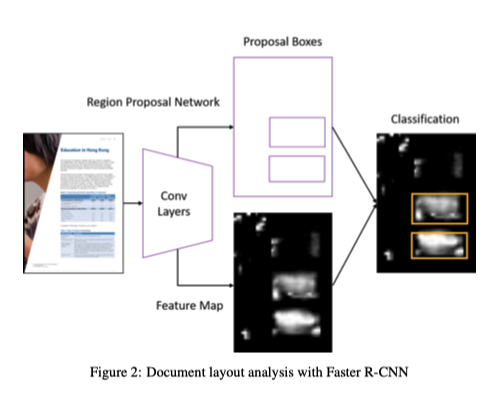
Documents layout analysis with convolutional neural networks
文檔布局分析可以看作是對文檔圖像進行目標檢測的任務。將文檔中的標題、段落、表格、圖表等基本單元是需要檢測和識別的對象。Yang等人將文檔布局分析作為像素級的分割任務,利用卷積神經(jīng)網(wǎng)絡進行像素分類,取得了較好的效果.
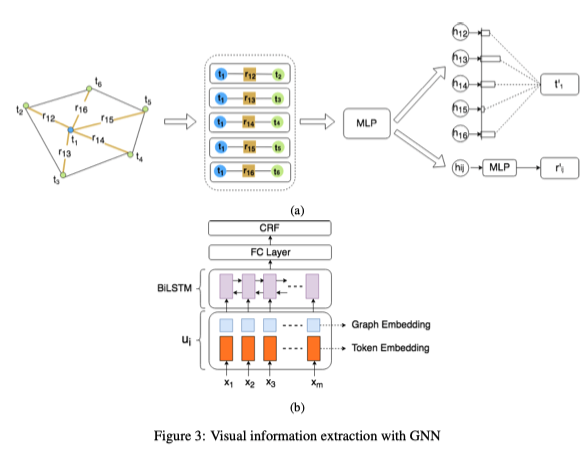
Visual information extraction with graph networks
對于視覺信息豐富的文檔的結構不僅僅由文本內(nèi)容的結構決定,與布局、排版、格式、表/圖結構等視覺元素同樣相關.例如收據(jù)、證書、保險文件等.Liu等人提出的利用圖卷積神經(jīng)網(wǎng)絡建模視覺元素豐富的文檔,首先通過OCR系統(tǒng)獲得一組Text Blocks,每一個Text Block包含其在圖像中與文本內(nèi)容的坐標信息,將其構成一個完全連通的有向圖,即每個Text Blocks構成一個節(jié)點,通過Bi-LSTM獲取節(jié)點的初始特征,邊的初始特征是相鄰文本塊與當前文本塊之間的相對距離以及這兩個文本塊的長寬比。對“節(jié)點-邊緣-節(jié)點”三元特征集進行卷積,實驗表明,視覺信息發(fā)揮了主要作用,增加了文本識別相似語義的能力,對視覺信息也起到一定的輔助作用。
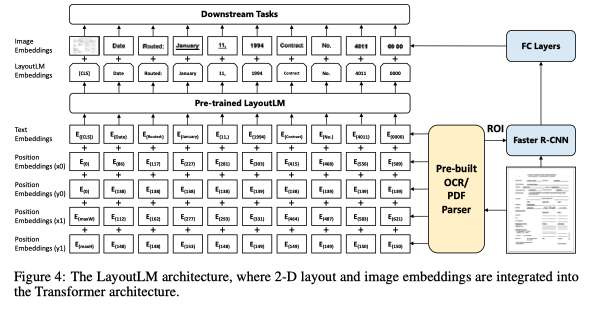
General-purpose multimodal pre-training with the transformer
文本塊的空間關系通常包含豐富的語義信息。例如,在表格中本塊通常以網(wǎng)格布局排列,標題通常出現(xiàn)在第一列或第一行。不同文檔類型之間的布局不變性是通用預訓練的一個關鍵屬性。通過預訓練與文本自然對齊的位置信息可以為下游任務提供更豐富的語義信息。對于視覺信息豐富的文檔,其視覺信息如字體類型、大小、樣式等明顯的視覺差異,其可以通過視覺編碼器提取出來,結合到預訓練階段,從而有效地改善下游任務。為了利用布局和視覺信息,2020年Xu提出通用文檔預訓練模型LayoutLM,在已有預訓練模型的基礎上,增加了2-Dposition embedding 和image embedding.首先根據(jù)OCR得到的文本邊界框得到文本在文檔中的坐標。將對應的坐標轉(zhuǎn)換為虛坐標后,模型計算出x、y、w、h四個embedding sublayers對應的坐標表示,最終的二維位置嵌入是四個子層的embedding之和。在imageembedding 中,模型將每個文本對應的邊框作為Faster R-CNN,提取相應的局部特征。特別是,由于[CLS]符號用于表示整個文檔的語義,因此模型還使用整個文檔的image作為image embedding以保持多模態(tài)對齊,Layout模型在三個下游任務,表單理解,票據(jù)理解,文檔圖像分類,都取得了顯著的準確率提升。
LayoutLM的兩個自監(jiān)督預訓練任務Masked Visual-Language :隨機mask除了2D postionembedding,以及其他文本的text embdedding,讓模型預測mask的 token.Task2:Multi-Label Document Classi?cation:在給定一組掃描文檔的情況下,利用文檔標簽對訓練前的過程進行監(jiān)督,使模型能夠?qū)碜圆煌I域的知識進行聚類,生成更好的文檔級表示.該模型的相關實驗表明,利用布局和視覺信息的預訓練可以有效地轉(zhuǎn)移到下游任務中。
小結
除了這篇文章介紹的之外LayoutLM等經(jīng)典模型,最近DocumentAI的研究工作中幾個后起之秀也非常值得關注。例如LayouLM后出現(xiàn)的LayoutLMv2以及LayoutXML,將跨模態(tài)對齊的思路貫徹在模型訓練的過程中。不僅僅利用文本和布局信息,將圖像信息也融合到文檔多模態(tài)的框架內(nèi)。除此之外,跨模態(tài)文檔理解模型ERINE-Layout,提出閱讀順序預測和細粒度圖文匹配兩個與訓練任務,除了跨模態(tài)予以對齊能力外,增加了布局理解能力。我們可以看到,在預訓練時代下,DocumentAI正在逐漸向“多模態(tài)文檔理解”方向前進,從模態(tài)之間的對齊到預測,DocumentAI將會怎樣找尋可以建模的更多元素,挖掘視覺與文本、布局之間的精細關系,變得更加值得期待了。
-
模型
+關注
關注
1文章
3305瀏覽量
49220 -
機器學習
+關注
關注
66文章
8438瀏覽量
133082 -
數(shù)據(jù)集
+關注
關注
4文章
1209瀏覽量
24833
原文標題:MSRA-萬字綜述 直擊多模態(tài)文檔理解
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
NVIDIA文本嵌入模型NV-Embed的精度基準
【大語言模型:原理與工程實踐】大語言模型的評測
請問NanoEdge AI數(shù)據(jù)集該如何構建?
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調(diào)技術解讀
高階API構建模型和數(shù)據(jù)集使用
一個深度學習模型能完成幾項NLP任務?
基準數(shù)據(jù)集(CORR2CAUSE)如何測試大語言模型(LLM)的純因果推理能力





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論