 數據火器庫 - 八卦系列之借老槍談可靠性
數據火器庫 - 八卦系列之借老槍談可靠性
來源:云數據庫技術
數據庫打工仔喃喃自語的八卦
1. 老槍:Db2/z和可靠性
2. K.I.S.S (Keep it Simple, Stupid!)
3. 系統驗證和測試:豬肉出廠的質檢章
數據庫的可靠性
1、數據庫里的老槍 - Db2 for zOS
上次聊了瑞士軍刀SQLite, 從年紀上SQLite出生于大數據和手機時代之前,對比后來的大數據引擎和云原生數據庫,SQLite可謂個頭不大,輩分不小了。不過數據庫的爺爺輩應該算是79年的Oracle和83年的Db2/z(z又叫mainframe,國內稱主機)。今天用這把老槍講講可靠性。
系統RAS(Reliability, availability and serviceability)概念最早是由IBM提出,來形容曾經是神一樣存在的主機(也叫大機,mainframe)。為什么說神一樣的存在呢?主機是第一批商用計算機,1950出現,活躍至今,最新(本文原稿為2022.1)版本為2019.9月的z15。最早的一批商用數據庫就包括主機上的DB2/z(1983年GA v2.3)。也許你從沒有聽說過,但是如果你每一天在消費,過程中,不論銀行卡,支付寶,微信都會最終走到銀聯,而且很可能是工農建交等大銀行,那么你的交易就是在主機上完成和記錄的。
2021年的AWS Re:Invest有一個session, 講AWS Mainframe Modernization; 2022年初某公告《8.38 億元、中國銀行單一來源采購:IBM z15主機》也可見一斑。
神在我們身邊默默的存在,不打擾一片云彩
我們談論數據庫的可靠性時候,籠統的時候會泛指RAS,大部分時候單指Reliability。
可靠性Reliability
數據庫系統無故障可以持續運行的能力。MTBF(Mean Time Between Failure)/MTTF(Mean Time to Faillure),MTTR(Mean Time to Repair/Recover)。這些都是工業界通用的衡量標準。具體計算公式大家自己去Google/wiki。這里盜個圖湊數。
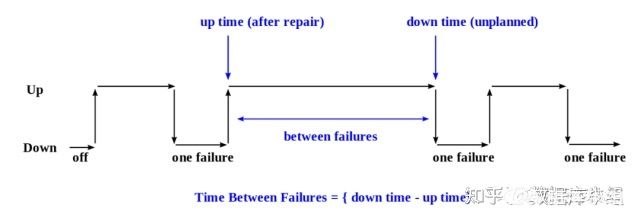
2、如何保證可靠性
教科書里有很多,架構設計的書也可以輕而易舉的找到。本文既然是八卦篇,就只分享現實世界的事情。那些理論上支撐的功能,原則上不會宕機的架構設計不是這里的重點
怎么能不犯錯?do nothing;
要保證軟件不出bug? 一行不寫。
如果不得不code呢?可靠方面先思考這兩項。
2.1核心代碼的復雜度
架構設計有個說法K.I.S.S(Keep it Simple, Stupid!)。其實系統軟件的核心code, 揚名天下立萬的骨架,也就那么幾萬行,完成系統80%的工作,換句話說,系統連續運行過程中每小時(甚至每分鐘)都必然運行的code logic。這些code中簡潔易懂是系統存活的關鍵。
簡潔可減少系統的bug。MySQL依賴最簡單可靠的nest-loop join算法二十多年,而"先進"的Hash Join是在最近兩年才實現,在MySQL8.0.18正式GA。從算法復雜度看(兩個都有改進版本),Nest Loop J是O(MN), Hash J是O(M+N)。Hash join 在教科書里屬于advance的章節,直接翻譯是“進步”,褒義詞。可是另一方面,幾乎所有的advance技術都更復雜(電車是個反例,降維打擊了),需要更多或更特殊的資源才能發揮其能力。Hash Join就需要在大內存支持下才能發揮,否則要么OOM,要么落盤造成性能斷崖,尤其不適合高并發的TP場景。比如各位同學中午在食堂買飯,就是高并發場景,如果系統中突然出現一個大查詢把內存都吃掉,也把各位的飯就吃掉了。
如何解決這個問題呢?workload management(WLM) 就要被引入,以自動調低“爛”query的優先級,限制其資源。而又引入進一步的系統復雜度。
nest loop保證了每個join的內存空間消耗是固定的,所以在上面場景中,不用WLM,不用系統DBA也可以保證各位吃上午飯。
給我自己頂個鍋蓋保護一下,絕沒有想引戰NLJ vs HJ的意思,PG有比較完整成熟的優化器,就好很多。靠,又跑題到MySQL vs PG 了。只是想說,如果一個系統可以簡單化,就可以減少其bug數,增加可靠性。
有興趣研究軟件工程的東西,可以看看Unix philosophy。哲學的事情咱不懂,用數據說話,第一版Unix據稱是不到5千行的匯編語言;linux 0.0.1版是10243 line of code(C) 和386LoC(匯編)。多年前,我參與系統軟件項目排期的時候,是按1.5KLoC/Person-Year 做的計劃。所以偶爾聽說系統開發同學談績效的時候提一年幾萬行代碼,還經常是早春二三月份提交的,兄弟我怕呀。前端同學代碼量會多些,不過這些代碼的生命力會差些。其實我認為衡量一個開發的代碼能力不應簡單的line of code, 更應該與服務年掛勾。
那么如果做到simple/簡單呢,上次八卦SQL的時候專注到產品邊界,就是要有節制,開發有明確的特點的產品,而不要試圖做大而全的產品。
2.2 測試
測試經常在數據庫設計和實現過程中被忽略,尤其在相對不成熟的開發團隊中 只做簡單的功能測試,甚至是單邏輯flow,而不考慮邊界條件。更談不上系統壓力測試(system stress testing),比如說連接數/concurrency突然提升情況下,是否還能夠保證吞吐量和延時保持著正常水平,后面的任務可以排隊,而不會因為高壓力下造成系統完全不可用。
寫code就會有bug, 越早發現fix的成本約少。軟件工程中這張圖是1996的文章。每每在前線客戶反饋一個簡單的bug, 我腦海里就是這張圖和16000美刀
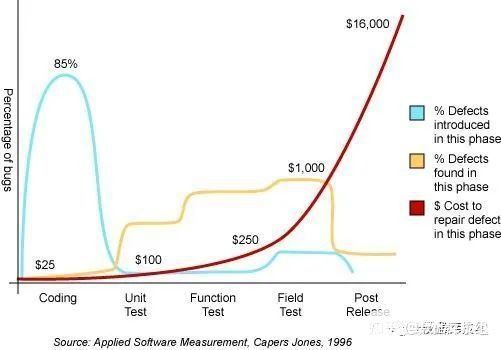
鄙視鏈那都有,軟件開發也不例外,常常一方面說測試多么重要,一方面測試工程師的工資級別屬于末端集結號。自然沒有牛人過來投入。這是全球普世的,而某些團隊尤甚。尤其是近些年,開始學Agile,學開源,甚至不設測試崗位。殊不知,開源社區最注重測試,測試代碼量常常是產品代碼的3X。筆者有幸十年前在HBase社區打醬油,很是佩服一個健康社區對代碼質量的管理。而當時的主席Stack,自號HBase Janitor(清潔工),最重要的工作就是QA。
上次提到的SQLite, 每一行code對應600行測試程序。“Due to its reliability, SQLite is often used in mission-critical applications such as flight software“
試問你所在的團隊,能否保證測試程序LOC與開發程序LOC是1:1的關系?產品發布時最后的否決權,是否在測試手里?
豬肉出廠還要蓋個質檢章呢。如果客戶現場發現了一個bug, 你的團隊的復盤時,是否能確認這個bug應該在軟件工程的那個環節被發現?

3、總結
一個系統的可靠性(其實是系統的各個方面了)是從三方面完成的:
3.1 系統的架構設計
對于大部分軟件工程師這一點上不需要太重視, 為什么呢?因為像數據庫有歷史以來,它的基本架構就那么幾種(single-node/monolithic, shared-storage/everything, shared-nothing), 架構帶來的優勢和劣勢已經被無數學術論文討論和工業系統驗證過。我們99.9%是在前人肩膀上討生活,在高手腳邊打醬油。
3.2 系統的實現
也就是code的工程能力。同樣打個桌子,朱由校(明熹宗)很可以超越我周邊所有的朋友。同樣實現一個hash join, 其實現算法至少從最早的relation model和關系幾何就有了。隨便找一篇三十年前的吧,An Adaptive Hash Join Algorithm for Multiuser Environments。
開發實現的好壞要看工程能力和工匠精神了。如果有理論就能沖出亞洲,中國男足也不會這樣。這樣就是軟件開發工程化的問題。如何使團隊更有效的開發,要對功能有節制,明確產品的邊界,求精而不求全。
3.3 系統的驗證
上邊專門提到,也是最容易被忽視的。大家常常會提到雙活(active-active),兩地三中心, 跨城分布, 高可用,多少個九。這些高大上的詞我也常常用, 有時候認真一點,我去請問這些系統能力是如何驗證通過的?高興的時候我會再多問點直擊靈魂的,W H W(who 誰測的,how 怎么測的,what 那些場景被測了?)。比如簡單的雙活, 用什么樣的workload(W:R 比例?),多大數據量, 連續跑了多長時間,P95延時是多少?
4、一點思考
當一個軟件架構師用呵護培養兒女的心寫code的時候,她/他就不會為三個月的短期目標commit code,讓孩子長歪了,比如"My"SQL和“Maria”DB。
做正確的事情是很難的,筆者在壓力下往repo里扔的爛code估計不比其他人少。"I always knew what the right path was. ....It was too damn hard." (聞香識女人)。做正確的事情太他媽難!】

5、注
傳奇老頭莫辛納甘:對應火器庫,可以對應古董級數據庫,可能就是 Mosin–Nagant 傳奇老頭莫辛納甘。
原始稿:本文原稿為2022.1,故部分內容非最新信息
審核編輯 黃昊宇
-
數據庫
+關注
關注
7文章
3848瀏覽量
64691 -
MySQL
+關注
關注
1文章
829瀏覽量
26745
發布評論請先 登錄
相關推薦
半導體封裝的可靠性測試及標準

提升產品穩定性:可靠性設計的十大關鍵要素

PCB高可靠性化要求與發展——PCB高可靠性的影響因素(上)

基于可靠性設計感知的EDA解決方案

燈具可靠性之關鍵:高低溫沖擊試驗全面解析

汽車功能安全與可靠性的關系

請問FATFS文件系統可靠性如何?
AC/DC電源模塊的可靠性設計與測試方法

選擇 KV 數據庫最重要的是什么?
硬件工程師在可靠性設計中所面臨的挑戰及解決之道






 工商網監
工商網監
評論