 語義分割模型 SegNeXt方法概述
語義分割模型 SegNeXt方法概述
語義分割是對圖像中的每個像素進行識別的一種算法,可以對圖像進行像素級別的理解。作為計算機視覺中的基礎任務之一,其不僅僅在學術界廣受關注,也在無人駕駛、工業檢測、輔助診斷等領域有著廣泛的應用。
近期,計圖團隊與南開大學程明明教授團隊、非十科技劉政寧博士等合作,提出了一種全新的語義分割模型 SegNeXt,該方法大幅提高了當前語義分割方法的性能,并在Pascal VOC 分割排行榜上名列第一。該論文已被 NeurIPS 2022 接收。
Part1
語義分割模型SegNeXt
研究背景 自2015年FCN[2] 被提出以來,語義分割開始逐漸走向深度學習算法,其常用架構為編碼-解碼器結構(Encoder-Decoder)。在 vision transformer 被提出之前,人們通常采用卷積神經網絡(如 ResNet、VGGNet、GoogleNet 等) 作為其編碼器部分;最近,由于vision transformer 在視覺領域的成功,語義分割編碼器部分開始逐漸被換成基于vision transformer的模型(如 ViT、SegFormer、HRFormer等)。但是,基于 vision transformer編碼器的方法真的比基于卷積神經網絡的方法更好么?為了回答這個問題,Jittor團隊重新思考了語義分割任務對神經網絡的要求,并針對語義分割的任務專門設計了一個基于卷積神經網絡的編碼器MSCAN 和一個語義分割模型 SegNeXt。
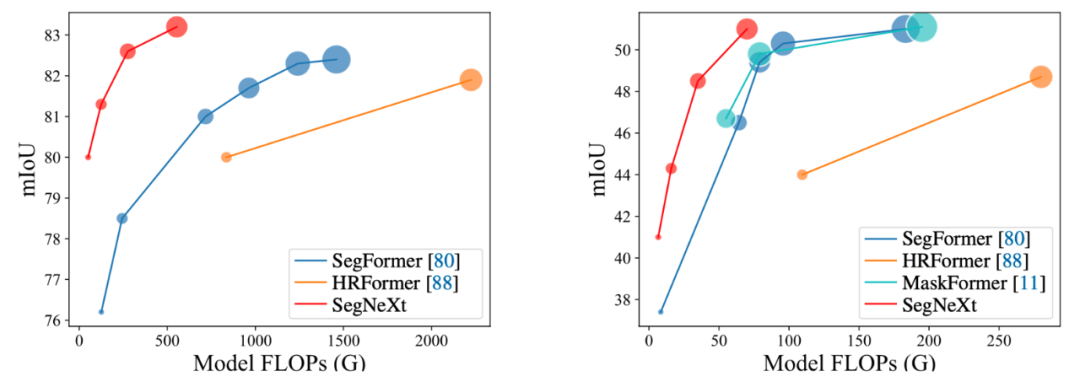
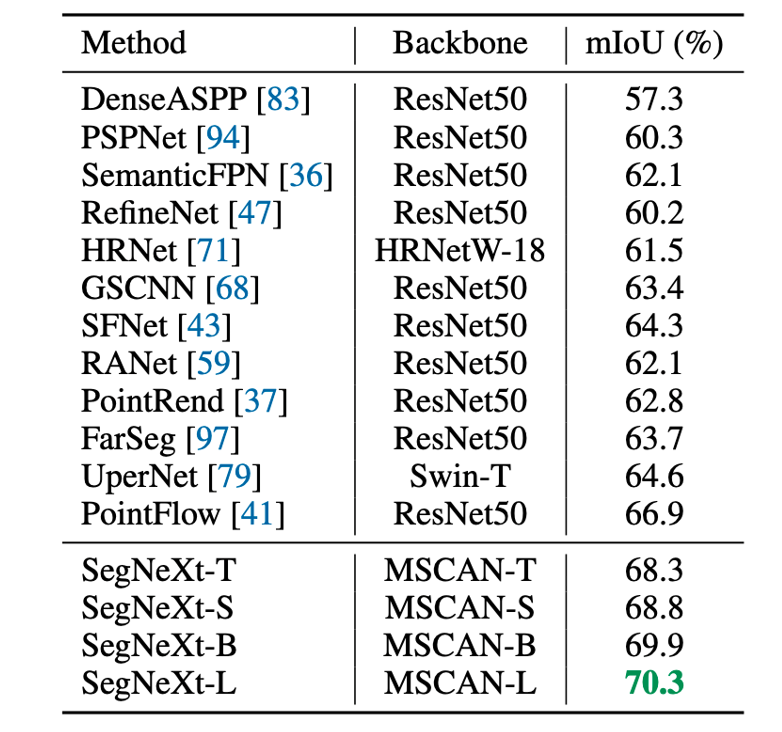
圖1. SegNeXt 和其他語義分割方法的性能對比,其中紅色為SegNeXt
方法概述
論文首先分析了語義分割任務本身以及之前的相關工作,總結出四點語義分割任務所需的關鍵因素。1)強大的骨干網絡作為編碼器。與之前基于 CNN 的模型相比,基于Transformer 的模型的性能提升主要來自更強大的骨干網絡。2)多尺度信息交互。與主要識別單個對象的圖像分類任務不同,語義分割是一項密集的預測任務,因此需要在單個圖像中處理不同大小的對象,這就使得針對語義分割任務的網絡需要多尺度信息的交互。3)注意力機制:注意力可以使得模型關注到重點的部分,并且可以使得網絡獲得自適應性。4)低計算復雜度:這對于常常處理高分辨率圖像的語義分割任務來說至關重要。
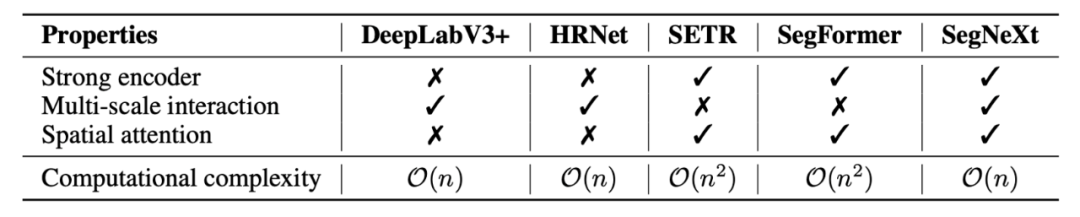
表 1 不同方法所具有的的屬性對比
為了滿足上述四點要求,作者設計了一種簡單的多尺度卷積注意力機制 (MSCA)。如圖 2 所示,MSCA 主要是采用大卷積核分解、多分支并行架構以及類似VAN[3]的注意力機制。這使得 MSCA 可以獲得大感受野、多尺度信息以及自適應性等有益屬性。基于 MSCA,該論文搭建了一種層次化神經網絡 MSCAN 作為SegNeXt 的編碼器部分。除此之外,作者采用了 UNet 架構,并選擇了HamNet[4] 作為 SegNeXt 的解碼器部分。分析和實驗證明,MSCAN和 Ham 優勢互補,兩者相互配合,使得 SegNeXt 實現了優異的性能。
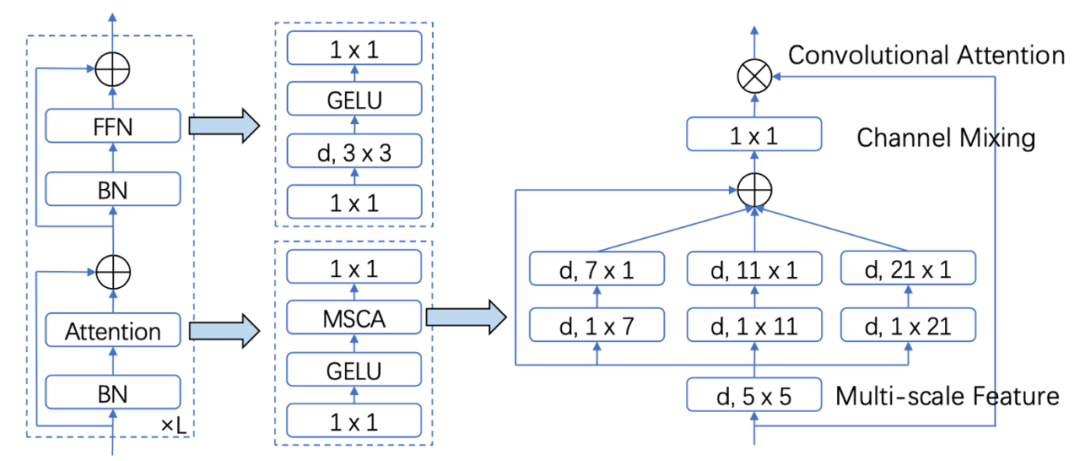
圖 2:多尺度卷積注意力(MSCA) 示意圖 實驗結果 本文在五個常見分割數據集上 ADE20K, Cityscapes,COCO-Stuff, Pascal VOC, Pascal Context 和一個遙感分割數據集 iSAID做了測評,SegNeXt均超過了之前的方法。限于篇幅,我們僅展示部分結果。
表2:在 ADE20K、Cityscapes, COCO-Stuff 上的實驗結果
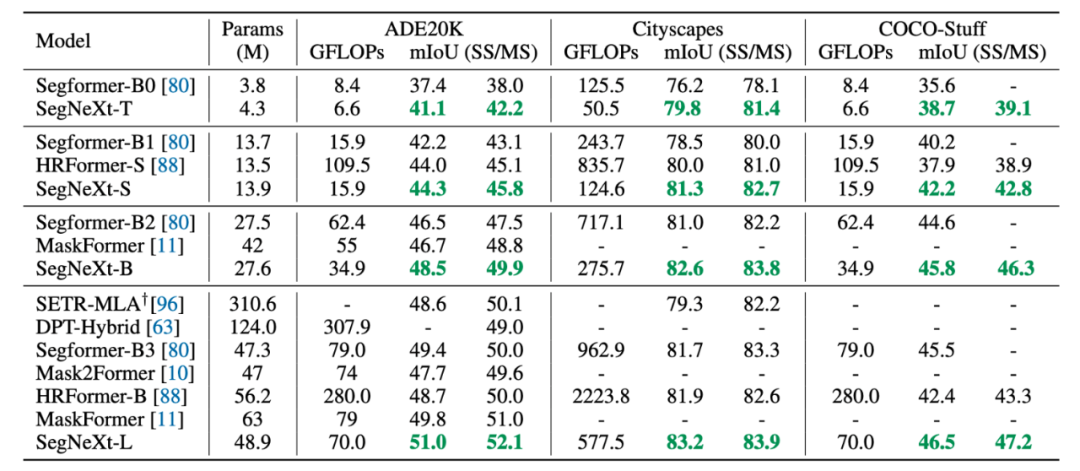
表 3 SegNeXt 在遙感數據集上的實驗結果
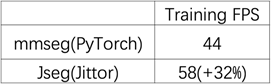
Part2 計圖語義分割算法庫JSeg Jittor團隊基于自主深度學習框架Jittor[5],并借鑒MMSegmentation語義分割算法庫的特點,開發了語義分割算法庫JSeg。MMSegmentation是廣泛使用的功能強大的語義分割算法庫,新推出的JSeg可以直接加載MMSegmentation的模型,同時借助Jittor深度學習平臺的優勢,使其更高效、穩定運行,可以實現訓練和推理快速的從PyTorch向Jittor遷移。 目前JSeg已經支持4個模型、4個數據集,其中模型包括在Pascal VOC test dataset斬獲第一的SegNeXt模型,數據集包括經典的ADE20K Dataset、CityScapes Dataset以及遙感分割中的iSAID Dataset等,后續JSeg也將支持更多的模型和數據集! 性能提升 我們使用SegNeX-Tiny模型,與Pytorch實現的版本在NVIDIA TITAN RTX上進行了對比,可以顯著縮短模型訓練所需要的時間。
表1JSeg和mmseg(PyTorch)的訓練時間對比
易用性提升
由于Jittor動態編譯的特性及code算子對python內聯C++及CUDA的支持,JSeg在不同環境下無需對任何算子進行手動編譯,即可輕松運行不同模型,免去了用戶對不同模型分別配置環境的負擔,同時方便用戶對不同方法進行更公平的比較。此外,JSeg的設計易于拓展,用戶可以基于JSeg已有的模型和功能方便地開展進一步的研究和開發。
實踐案例
下面,我們將簡要介紹如何使用JSeg訓練一個基礎模型。
首先,下載數據集到原始數據集目錄。

通過tools/convert_datasets下的數據處理腳本對原始數據進行預處理,得到處理后的數據集。然后即可對模型進行單卡或者多卡訓練、評估和測試,同時提供了推理接口,用戶可以使用10行代碼完成一張圖片的語義分割,盡可能地降低了用戶的使用成本。
-
解碼器
+關注
關注
9文章
1147瀏覽量
40932 -
模型
+關注
關注
1文章
3305瀏覽量
49221 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46127 -
深度學習
+關注
關注
73文章
5513瀏覽量
121551
原文標題:NeurIPS 2022 | 清華&南開提出SegNeXt:重新思考語義分割的卷積注意力設計
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
聚焦語義分割任務,如何用卷積神經網絡處理語義圖像分割?
Facebook AI使用單一神經網絡架構來同時完成實例分割和語義分割

DeepLab進行語義分割的研究分析
語義分割算法系統介紹
語義分割方法發展過程
分析總結基于深度神經網絡的圖像語義分割方法

結合雙目圖像的深度信息跨層次特征的語義分割模型


基于SEGNET模型的圖像語義分割方法
圖像語義分割的概念與原理以及常用的方法
語義分割標注:從認知到實踐
CVPR 2023 | 華科&MSRA新作:基于CLIP的輕量級開放詞匯語義分割架構

深度學習圖像語義分割指標介紹






 工商網監
工商網監
評論