") 語音UI的基本原則
語音UI的基本原則
Amazon Echo和Google Home中的語音用戶界面(語音UI)功能吸引了消費(fèi)者的注意。語音識(shí)別系統(tǒng)的效率很大程度上取決于麥克風(fēng)陣列和算法集合,這些算法允許陣列聚焦于用戶的語音并拒絕不需要的噪聲。下面解釋這些算法的基本功能。
觸發(fā)/喚醒詞
語音 UI 系統(tǒng)使用分配的觸發(fā)詞(如“Alexa”或“確定谷歌”)來激活語音 UI 設(shè)備。設(shè)備必須使用自己的算法立即進(jìn)行識(shí)別,因?yàn)槭褂没ヂ?lián)網(wǎng)資源會(huì)產(chǎn)生太多的延遲。
觸發(fā)詞必須產(chǎn)生一個(gè)獨(dú)特的波形,該波形可以使算法與正常語音區(qū)分開來,否則成功識(shí)別的百分比可能低得令人無法接受。通常,使用三到五個(gè)音節(jié)的觸發(fā)詞是最好的。
小觸發(fā)詞算法占用較少的內(nèi)存和處理,但犯更多的錯(cuò)誤,而大的算法需要更多的資源,但犯的錯(cuò)誤更少。模型也是可調(diào)的 - 它們可以更嚴(yán)格(更少的誤報(bào),但更難觸發(fā))或更寬松(更多的誤報(bào),但更容易觸發(fā))。大多數(shù)產(chǎn)品設(shè)計(jì)師選擇更嚴(yán)格的調(diào)整,因?yàn)榭蛻魧?duì)錯(cuò)誤觸發(fā)沒有同情心。
圖 1 比較了不同調(diào)諧點(diǎn)的三觸發(fā)模型的性能。在測試條件下,每小時(shí)實(shí)現(xiàn)少于兩個(gè)錯(cuò)誤觸發(fā)器是一個(gè)合理的目標(biāo)。小模型只能通過圖形最左側(cè)的兩個(gè)最嚴(yán)格的調(diào)諧來實(shí)現(xiàn)這一點(diǎn)。中型和大型型號(hào)在更寬的工作范圍內(nèi)實(shí)現(xiàn)了這一目標(biāo)。
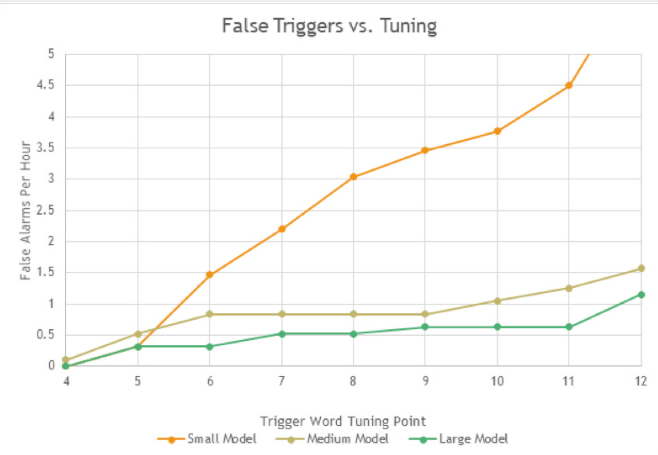
圖 1. 每小時(shí)使用小型、中型和大型算法模型測試誤報(bào),左側(cè)調(diào)整更嚴(yán)格,右側(cè)調(diào)整更寬松。
到達(dá)目的地(到達(dá)方向)
一旦觸發(fā)詞被識(shí)別出來,下一步就是確定用戶語音的到達(dá)方向(DOA)。一旦確定了方向,DOA算法就會(huì)告訴波束成形算法它應(yīng)該聚焦在哪個(gè)方向。
DOA算法的核心功能是檢查來自陣列中不同麥克風(fēng)的信號(hào)的相位關(guān)系,并使用此信息來確定哪個(gè)麥克風(fēng)首先接收聲音。但是,由于來自墻壁,地板,天花板和房間內(nèi)其他物體的反射,用戶的聲音也將從其他方向傳來。為此,DOA算法包括優(yōu)先邏輯,它將更響亮的初始到達(dá)與更安靜的反射分開。
DOA 算法的操作通過自動(dòng)調(diào)整環(huán)境噪聲水平得到增強(qiáng)。該算法測量房間內(nèi)的平均噪聲水平,并且僅當(dāng)輸入信號(hào)至少比環(huán)境噪聲水平高出一定數(shù)量的分貝時(shí),才會(huì)重新計(jì)算用戶嘴巴的位置。
回聲消除器
為了更好地關(guān)注用戶的聲音,語音 UI 設(shè)備必須從其麥克風(fēng)拾取的聲音中減去自己的揚(yáng)聲器產(chǎn)生的聲音。這似乎很簡單,就像將節(jié)目材料的相位反轉(zhuǎn)版本混合到來自麥克風(fēng)的信號(hào)中一樣簡單。然而,該過程不足以處理揚(yáng)聲器對(duì)波形的改變、數(shù)字信號(hào)處理(DSP)均衡、麥克風(fēng)和聲學(xué)反射。
AEC算法中的第一步是將麥克風(fēng)的輸出與原始(前DSP)輸入信號(hào)進(jìn)行比較,并計(jì)算校正曲線,以從語音命令的波形中減去揚(yáng)聲器的直接聲音。
第二步是減去聲學(xué)回聲。該算法必須在一定的誤差范圍內(nèi)“尋找”與節(jié)目材料匹配的聲音(以補(bǔ)償由聲學(xué)引起的波形變化),以及對(duì)應(yīng)于預(yù)期混響時(shí)間的已定義時(shí)間窗口內(nèi)的聲音。由于每個(gè)麥克風(fēng)接收的回聲集略有不同,并且來自揚(yáng)聲器的直接聲音也不同,因此要實(shí)現(xiàn)最佳性能,需要對(duì)每個(gè)麥克風(fēng)進(jìn)行單獨(dú)的 AEC 處理。
AEC 查找反射的時(shí)間段稱為“回波尾部長度”。回聲尾部長度越長,可以消除的反射越多,算法的性能就越好。然而,較長的尾巴需要更多的內(nèi)存和更多的處理。圖2顯示了回聲消除器在逐漸增加混響的房間中的表現(xiàn)。對(duì)更長的回聲尾部的需求是顯而易見的。
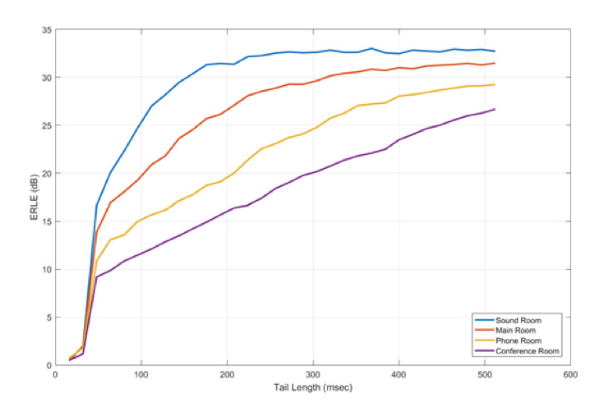
圖 2. 回聲消除器在四個(gè)房間中表現(xiàn),混響時(shí)間增加。較大的房間受益于使用長回聲尾部的算法。
波束成形
波束成形允許麥克風(fēng)陣列聚焦于來自特定方向的聲音。它提高了信噪比(SNR),因?yàn)樗兄诟綦x用戶的聲音,同時(shí)抑制來自其他方向的聲音。
例如,如果用戶位于麥克風(fēng)陣列的一側(cè),而空調(diào)位于另一側(cè),則來自空調(diào)的聲音首先到達(dá)用戶對(duì)面的麥克風(fēng),然后在幾分之一秒后到達(dá)離用戶最近的麥克風(fēng)。波束成形算法使用這些時(shí)差來消除空調(diào)聲音,同時(shí)保留用戶的聲音。
具有兩個(gè)麥克風(fēng)的陣列取消聲音的能力有限,但具有三個(gè)或更多麥克風(fēng)的陣列可以消除來自更多方向的聲音。麥克風(fēng)越少,性能就越會(huì)隨著視角(用戶的聲音與語音 UI 產(chǎn)品前軸之間的角度)的變化而變化。
噪
雖然麥克風(fēng)陣列系統(tǒng)使用定向拾音模式來濾除噪聲,但某些噪聲可以通過識(shí)別將噪聲與所需信號(hào)分離的特性,然后消除噪聲的算法進(jìn)行衰減。降噪算法可以幫助觸發(fā)單詞識(shí)別,并在所有其他算法完成其工作后提高語音UI性能。
語音命令是瞬時(shí)事件。可以檢測到始終存在或重復(fù)的任何聲音,并將其從來自麥克風(fēng)陣列的信號(hào)中刪除。示例包括汽車中的道路噪聲,以及家庭中的洗碗機(jī)和HVAC系統(tǒng)噪聲。高于或低于人聲頻譜的聲音也可以從信號(hào)中濾除。
手機(jī)中使用的常見降噪算法傾向于突出顯示對(duì)人類理解最關(guān)鍵的頻譜,而不是對(duì)電子系統(tǒng)隔離和理解語音命令最關(guān)鍵的頻譜。大多數(shù)此類算法實(shí)際上會(huì)降低語音 UI 性能。簡單地說,人類聽的東西與語音UI系統(tǒng)不同。
圖3顯示了在有和沒有降噪的情況下觸發(fā)字檢測的功效。降噪算法將整體語音識(shí)別提高了2 dB -考慮到用戶的聲音通常僅比周圍噪聲大幾dB,這是一個(gè)很大的差異。
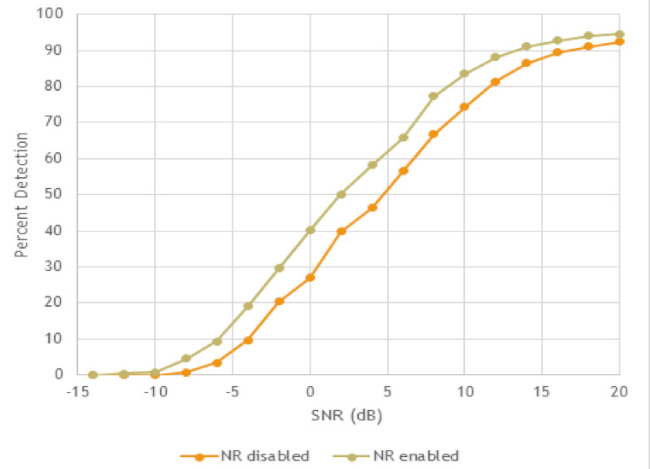
圖 3. 降噪算法對(duì)觸發(fā)字檢測的影響。
審核編輯:郭婷
-
dsp
+關(guān)注
關(guān)注
554文章
8059瀏覽量
350451 -
觸發(fā)器
+關(guān)注
關(guān)注
14文章
2003瀏覽量
61350
發(fā)布評(píng)論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論