 介紹一下使用NMT協助排查內存問題的案例
介紹一下使用NMT協助排查內存問題的案例
從前面幾篇文章,我們了解了 NMT 的基礎知識以及 NMT 追蹤區域分析的相關內容,本篇文章將為大家介紹一下使用 NMT 協助排查內存問題的案例。
6.使用 NMT 協助排查內存問題案例
我們在搞清楚 NMT 追蹤的 JVM 各部分的內存分配之后,就可以比較輕松的協助排查定位內存問題或者調整合適的參數。
可以在 JVM 運行時使用 jcmd
比如我們看到 MetaSpace 的內存增長異常,可以結合 MAT 等工具查看是否類加載器數量異常、是否類重復加載、reflect 的 inflation 參數設置是否合理;如果 Symbol 內存增長異常,可以查看項目 String.intern 是否使用正常;如果 Thread 使用內存過多,考慮是否可以適當調整線程堆棧大小等等。
案例一:虛高的 VIRT 內存
我們還記得前文(NMT 內存 & OS 內存概念差異性章節)中使用 top 命令查看啟動的 JVM 進程,仔細觀察會發現一個比較虛高的 VIRT 內存(10.7g),我們使用 NMT 追蹤的 Total: reserved 才 2813709KB(2.7g),這多出來的這么多虛擬內存是從何而來呢?
top PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COMMAND 27420douyiwa+20010.7g69756017596S100.00.30:18.79java NativeMemoryTracking: Total:reserved=2813077KB,committed=1496981KB
使用pmap -X
27420:java-Xmx1G-Xms1G-XX:+UseG1GC-XX:MaxMetaspaceSize=256M-XX:MaxDirectMemorySize=256M-XX:ReservedCodeCacheSize=256M-XX:NativeMemoryTracking=detail-jarnmtTest.jar AddressPermOffsetDeviceInodeSizeRssPssReferencedAnonymousLazyFreeShmemPmdMappedShared_HugetlbPrivate_HugetlbSwapSwapPssLockedMapping c0000000rw-p0000000000:00010490886372366372366372366372360000000 100080000---p0000000000:000104806400000000000 aaaaea835000r-xp00000000fd:0245613083444400000000java aaaaea854000r--p0000f000fd:0245613083444440000000java aaaaea855000rw-p00010000fd:0245613083444440000000java aaab071af000rw-p0000000000:0003041081081081080000000[heap] fffd60000000rw-p0000000000:00013244440000000 fffd60021000---p0000000000:0006540400000000000 fffd68000000rw-p0000000000:00013288880000000 fffd68021000---p0000000000:0006540400000000000 fffd6c000000rw-p0000000000:00013244440000000 fffd6c021000---p0000000000:0006540400000000000 fffd70000000rw-p0000000000:000132404040400000000 fffd70021000---p0000000000:0006540400000 ......
可以發現多了很多 65404 KB 的內存塊(大約 120 個),使用 /proc/
...... fffd60021000-fffd64000000---p0000000000:000 Size:65404kB KernelPageSize:4kB MMUPageSize:4kB Rss:0kB Pss:0kB Shared_Clean:0kB Shared_Dirty:0kB Private_Clean:0kB Private_Dirty:0kB Referenced:0kB Anonymous:0kB LazyFree:0kB AnonHugePages:0kB ShmemPmdMapped:0kB Shared_Hugetlb:0kB Private_Hugetlb:0kB Swap:0kB SwapPss:0kB Locked:0kB VmFlags:mrmwmenr ......
對照 NMT 的情況,我們發現如 fffd60021000-fffd64000000 這種 65404 KB 的內存是并沒有被 NMT 追蹤到的。這是因為在 JVM 進程中,除了 JVM 進程自己 mmap 的內存(如 Java Heap,和用戶進程空間的 Heap 并不是一個概念)外,JVM 還直接使用了類庫的函數來分配一些數據,如使用 Glibc 的 malloc/free (也是通過 brk/mmap 的方式):
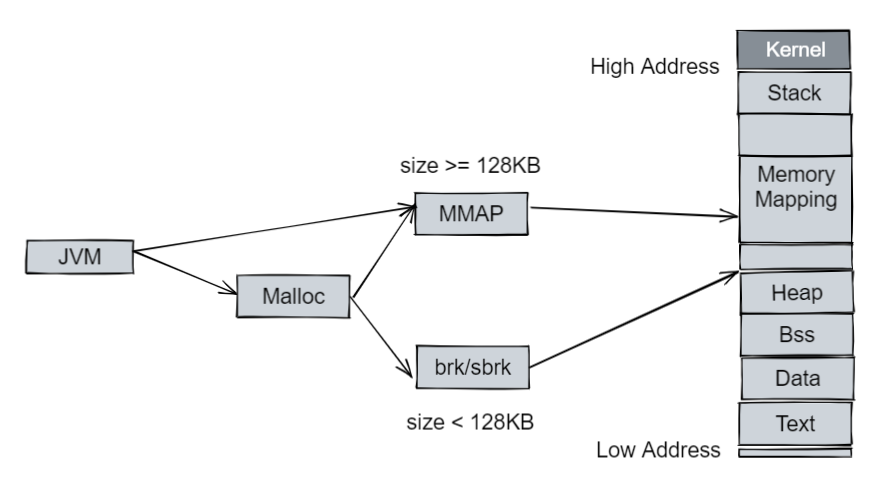
既然 JVM 使用了 Glibc 的 malloc/free,就不得不提及 malloc 的機制,早期版本的 malloc 只有一個 arena(分配區),每次分配時都要對分配區加鎖,分配完成之后再釋放,這就導致了多線程的情況下競爭比較激烈。
所以 malloc 改動了其分配機制,甚至有了 arena per-thread 的模式,即如果在一個線程中首次調用 malloc,則創建一個新的 arena,而不是去查看前面的鎖是否會發生競爭,對于一定數量的線程可以避免競爭在自己的 arena 上工作。
arena 的數量限制在 32 位系統上是 2 * CPU 核心數,64 位系統上是 8 * CPU 核心數,當然我們也可以使用 MALLOC_ARENA_MAX (Linux 環境變量,詳情可以查看 mallopt(3)[1])來控制。
查看發現運行 JVM 進程的環境 CPU 信息(物理 CPU 核數):Core(s) per socket: 64 。
我們給當前環境設置 MALLOC_ARENA_MAX=2,重啟 JVM 進程,查看使用情況:
top PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COMMAND 36319douyiwa+200310834069087217828S100.00.30:07.61java
虛高的 VIRT 內存已經降下來了,繼續查看 pmap/smaps 會發現眾多的 65404 KB 的內存空間也消失了(120 * 65404 KB = 7848480 KB 正好對應了 10.7g - 3108340 KB 的內存,即 VIRT 降低的內存)。
為什么我們的 JVM 進程會使用如此多的 arena 呢?因為我們在啟動 JVM 進程的時候,并沒有手動去設置一些進程的數目,如:CICompilerCount(編譯線程數)、ConcGCThreads/ParallelGCThreads(并發 GC 線程數)、G1ConcRefinementThreads(G1 Refine 線程數)等等。
這些參數大多數根據當前機器的 CPU 核數去計算默認值,使用 jinfo -flags
-XX:CICompilerCount=18 -XX:ConcGCThreads=11 -XX:G1ConcRefinementThreads=43
這些線程數目都是比較大的,我們也可以不修改 MALLOC_ARENA_MAX 的數量,而通過參數減小線程的數量來減少 arena 的數量。
Glibc 的 malloc 有時會出現碎片問題,可以使用 jemalloc/tcmalloc 等替代 Glibc。
案例二:堆外內存的排查
有時候我們會發現,Java 堆、MetaSpace 等區域是比較正常的,但是 JVM 進程整體的內存卻在不停的增長,此時我們就可以使用 NMT 的 baseline & diff 功能來觀察究竟是哪塊區域內存一直增長。
比如在一次案例中發現:
NativeMemoryTracking: Total:reserved=8149334KB+1535794KB,committed=6999194KB+1590490KB ...... -Internal(reserved=1723321KB+1472458KB,committed=1723321KB+1472458KB) (malloc=1723289KB+1472458KB#109094+47573) (mmap:reserved=32KB,committed=32KB) ...... [0x00007fceb806607a]Unsafe_AllocateMemory+0x17a [0x00007fcea1d24e68] (malloc=1485579KBtype=Internal+1455929KB#2511+2277) ......
我們可以確認內存 1590490KB 的增長,基本上都是由 Internal 的 Unsafe_AllocateMemory 所分配的,此時可以優先考慮 NIO 中 ByteBuffer.allocateDirect / DirectByteBuffer / FileChannel.map 等使用方式是不是出現了泄漏,可以使用 MAT 查看 DirectByteBuffer 對象的數量是否異常,并可以使用 -XX:MaxDirectMemorySize 來限制 Direct 的大小。
設置 -XX:MaxDirectMemorySize 之后,進程異常的內存增長停止,但是 GC 頻率變高,查看 GC 日志發現:.887+0800: 238210.127: [Full GC (System.gc()) 1175M->255M(3878),0.8370418 secs]。
FullGC 的頻率大大增加,并且基本上都是由 System.gc() 顯式調用引起的(HotSpot中的System.gc()為 FulGC),查看 DirectByteBuffer 相關邏輯:
#DirectByteBuffer.java
DirectByteBuffer(intcap){//package-private
......
Bits.reserveMemory(size,cap);
longbase=0;
try{
base=unsafe.allocateMemory(size);
}catch(OutOfMemoryErrorx){
Bits.unreserveMemory(size,cap);
throwx;
}
unsafe.setMemory(base,size,(byte)0);
if(pa&&(base%ps!=0)){
//Rounduptopageboundary
address=base+ps-(base&(ps-1));
}else{
address=base;
}
cleaner=Cleaner.create(this,newDeallocator(base,size,cap));
att=null;
}
#Bits.java
staticvoidreserveMemory(longsize,intcap){
......
System.gc();
......
}
DirectByteBuffer 在 unsafe.allocateMemory(size) 之前會先去做一個 Bits.reserveMemory(size, cap) 的操作,Bits.reserveMemory 會顯式的調用 System.gc() 來嘗試回收內存,看到這里基本可以確認為 DirectByteBuffer 的問題,排查業務代碼,果然發現一處 ByteBufferStream 使用了 ByteBuffer.allocateDirect 的方式而流一直未關閉釋放內存,修正后內存增長與 GC 頻率皆恢復正常。
審核編輯:劉清
-
JVM
+關注
關注
0文章
158瀏覽量
12261 -
LINUX內核
+關注
關注
1文章
316瀏覽量
21744 -
NMT
+關注
關注
0文章
7瀏覽量
3654
原文標題:Native Memory Tracking 詳解(4):使用 NMT 協助排查內存問題案例
文章出處:【微信號:openEulercommunity,微信公眾號:openEuler】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RTOS內存管理問題誰來解答一下
Native Memory Tracking 詳解(4):使用 NMT 協助排查內存問題案例
簡要介紹一下Python-UNO的使用方法

如何使用NMT和pmap來解決JVM的資源泄漏問題
介紹NMT追蹤區域的部分內存類型

記一次Rust內存泄漏排查之旅







 工商網監
工商網監
評論