 使用MATLAB進行異常檢測(上)
使用MATLAB進行異常檢測(上)
異常檢測任務,指的是檢測偏離期望行為的事件或模式,可以是簡單地檢測數值型數據中,是否存在遠超出正常取值范圍的離群值,也可以是借助相對復雜的機器學習算法識別數據中隱藏的異常模式。
在不同行業中,異常檢測的典型應用場景包括:
自動檢測生產線中產品加工異常,降低不良率或輔助質檢人員提高工作效率
監控金融交易中是否存在詐騙行為
根據醫學影像數據,識別癌組織及其邊界
針對異常數據的不同,以及是否可以人為判斷異常行為或故障模式,實現方式各有千秋。本文分為上下兩篇,在第一部分,將梳理異常檢測問題的一般處理思路,第二部分則結合示例重點討論基于統計和機器學習的無監督異常檢測方法。
什么是異常值
異常值包括離群值和奇異值,以下是相關定義:
離群值(outlier):偏離正常范圍的數據,可能是由傳感器故障、人為錄入錯誤或異常事件導致,在構建機器學習或統計模型前,如果不對離群值做任何處理,可能會導致模型出現偏差。
奇異值(novelty):數據集未受到異常值污染,但是存在某些區別于原數據分布的觀測數據。
首先,了解你的數據
在一頭扎進算法或模型開發之前,首先需要做的是仔細查看手中的數據,并考慮以下問題:
01原始數據中的異常是否是顯而易見的?
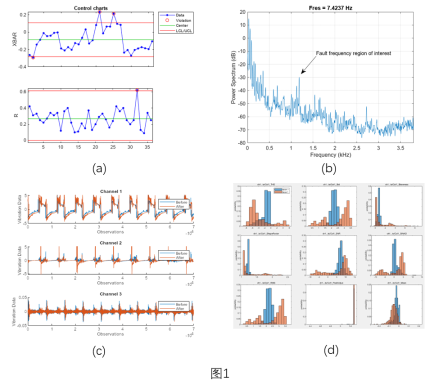
機電設備的停機、堵轉等異常現象,從信號波形就可以直接判斷異常原因和發生時間,這類問題比較簡單,常用突變點檢測函數findchangepts或過程控制SPC (Statistical Process Control) 中 control chart 進行處理。例如圖1(a)中超出上下置信區間的數據點即為異常點,具體可查看示例:Find abrupt changes in signal[1] ,Control Charts[2] ,統計過程控制[3]
02從原始數據中是否可以提取出能夠有效區分異常的特征?
旋轉機械設備的正常和異常數據,從時域信號的波形看上去往往相差無幾,但是經過頻域變換后,不同頻率分量的幅值,可能有較大的不同,這種情況下,可根據頻域特征直接檢測出異常,如圖 1(b) 中標記的異常部分。
03從統計分析的角度,是否可以分區異常和正常數據?
Predictive Maintenance Toolbox內置的Diagnostic Feature Designer App,可以幫助我們提取時域和頻域特征,并分析其統計分布,例如,在工業設備應用中,利用三軸加速度傳感器,分別采集設備維護前(藍色)和維護后(紅色)的振動信號,如圖 1(c) 所示,對這兩類信號(每類多個樣本)提取標準差、斜度等常用統計特征,再分析兩類信號的特征直方圖,見圖 1(d),不難看出,二者的各個特征的統計分布均存在一定差異。此外,在 Diagnostic Feature Designer App 中,還可以使用一系列特征排序的方法,例如在有標簽或無標簽的條件下,分別選用 One-Way ANOVA 和 Laplace Score 分析哪些特征可以更好地輔助判斷,并利用這些特征作訓練基于機器學習的異常檢測模型。
04如果無法確定數據中是否存在特定的異常模式,應該如何處理?
在全天候運行的工業設備中,故障停機意味著產能的降低,因此設備運營階段往往采取預防性維護的策略,這意味著異常數據稀缺,并且采集到數據全部或大多是正常數據,異常數據的占比往往較低(獲取難度大風險高,或是無法描述異常模式),這也是為什么異常檢測任務多被處理為無監督學習問題,僅僅通過正樣本(正常數據)訓練算法實現任務,或根據數據的隱藏特性篩選出其中的異常樣本。
關于如何選擇異常檢測方法,可參考該鏈接了解更多相關函數和適用條件:Decision Models for Fault Detection and Diagnosis [4]
簡單的一維數據異常檢測問題
針對一維數據的異常值檢測,處理方法有以下幾種:
是否超出歷史數據的最大值/最小值
3σ 原則:如果數據符合正態分布,可將 ±3σ 作為極限誤差,將落在 μ±3σ 以外樣本作為離群值
可以通過箱線圖分析/四分位數檢驗、Grubbs 等方法,進行檢測。
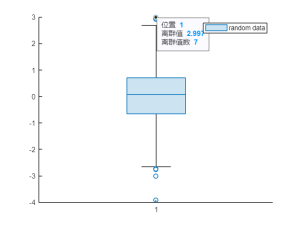
例如,針對一組隨機生成數,使用 boxchart 函數繪制箱線圖,可以簡單有效地可視化離群值,默認情況下,boxchart使用 'o'符號顯示每個離群值。
% 創建一個一維的隨機數向量 data = randn(1,1000); boxchart(data,"DisplayName","random data") legend % 選取其中一個離群值 ax = gca; chart = ax.Children(1); datatip(chart,"1",3.425);
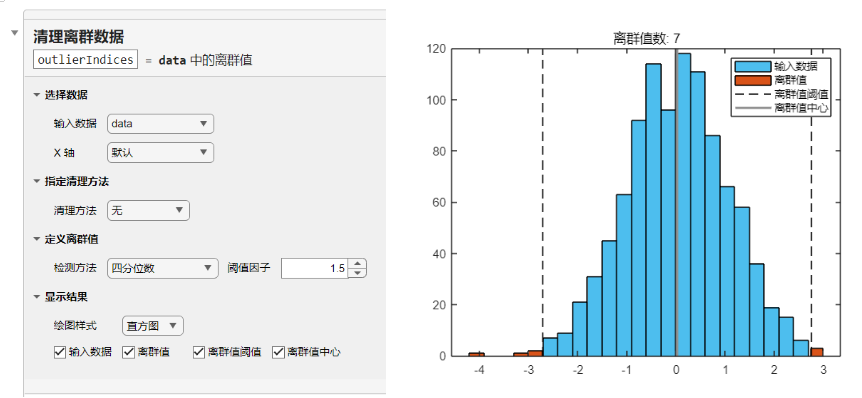
或者使用實時任務“清除離群值”,選擇合適的檢測方法和清理方法,并對數據分布和離群值進行可視化和處理:
對于多變量(特征)數據集,特征之間可能存在復雜和高度非線性的相關性,上述離群值剔除的方法將不再適用。
高維數據的異常檢測
接下來,通過一個基于工業設備振動信號的預測性維護示例,介紹如何著手處理高維數據的異常檢測問題,在該例中,原始數據為使用加速度傳感器采集的 x/y/z 三個通道的振動信號。在重要工業設備的實際運營過程中,使用者往往采取定期預防性維護的策略,以避免意外停機造成的風險和經濟損失,而設備運行一段時間,可能存在一定的零部件磨損和老化問題,這也是導致異常的部分潛在原因,因此樣本標簽分為兩類:“維護前”(before)和“維護后”(after)。
振動信號是典型的時間序列數據,在進行處理時,常用的方法之一是,按設定的時間窗口,對信號進行時域的統計特征提取或頻域特征提取,從而轉換成以下結構化數據形式:
load("FeatureEntire.mat") head(featureAll)

關于如何進行特征提取,可在命令行窗口運行以下指令,打開對應參考文檔查看:
>> openExample('predmaint_deeplearning/AnomalyDetectionUsing3axisVibrationDataExample')
將數據集劃分為訓練集和測試集:
rng(0) idx = cvpartition(featureAll.label, 'holdout', 0.1); featureTrain = featureAll(idx.training, :); featureTest = featureAll(idx.test, :);
將測試集部分的標簽進行替換,將“維護前”(before)定義為“異常”(Anomaly),“維護后”(after)定義為“正常”(Normal):
trueAnomaliesTest = featureTest.label; trueAnomaliesTest = renamecats(trueAnomaliesTest,["After","Before"], ["Normal","Anomaly"]); featureTestNoLabels = featureTest(:, 2:end);
將訓練集中“維護后”(after)的數據樣本篩選出來,作為后續異常檢測模型的訓練樣本:
featureNormal = featureTrain(featureTrain.label=='After', :);
feat = featureNormal{:,2:end};
[NumSamples,Dim] = size(feat)
NumSamples=10282
Dim=12
這個數據集一共有 12 個維度的特征和 10282 條樣本。
常用的高維數據可視化方法
為了方便理解數據,可采用以下方法,在低維空間內,對高維數據進行可視化:
1. 通過 plotmatrix 函數,隨機抽取 3 個特征,將任意兩個特征作為橫縱坐標:
plotmatrix(feat(:,randi(size(feat,2),1,3)))
title('原始特征')
2. 使用 fsulaplacian 函數,利用 LaplacianScore 算法,選取最重要 2 個特征(第 9 和第 10 個特征)后,繪制其二維平面散點圖,觀察數據中是否存在某些特定的聚集現象。
idx = fsulaplacian(feat); idx(1),idx(2)
ans=9
ans=10
scatter(feat(:,idx(1)),feat(:,idx(2)),4,'filled') title('基于Laplacian Score選擇后的特征')
3. 僅選取其中最重要的特征,可通過 tSNE(t-Distributed Stochastic Neighbor Embedding)對數據進行降維:
rng('default')
X=tsne(feat,Standardize=true,Perplexity=100,Exaggeration=20);
scatter(X(:,1),X(:,2),4,'filled')
title('使用tSNE降維 - 二維')
X3=tsne(feat,Standardize=true,Perplexity=100,Exaggeration=20,NumDimensions=3);
scatter3(X3(:,1),X3(:,2),X3(:,3),4,'filled')
title('使用tSNE降維 - 三維')
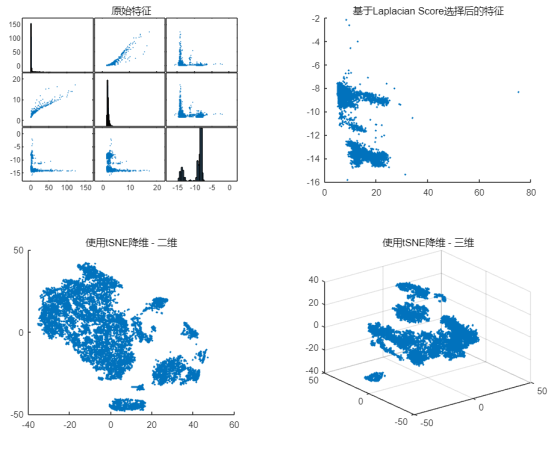
基于 tSNE 進行數據降維的過程中,將融合多個特征得到新的基向量,再將原始數據投射到對應基向量的低維空間進行可視化,在第二部分中,我們將利用這個方法查看訓練樣本中的異常情況。
有監督異常檢測
參考文檔頁面:Model-Specific Anomaly Detection[5]
Statistics and Machine Learning Toolbox 提供了基于模型的異常檢測算法,如果已將訓練數據標注為正常和異常,可以訓練二類分類模型,并使用 resubPredict 和 predict 對象函數分別檢測訓練數據和新數據中的異常。當對設備的全生命周期中的不同狀態,例如健康、老化、異常和壽命終末期有足夠了解和相關數據標簽時,可考慮數據擬合回歸模型,或構建聚類模型,以區分不同狀態數據。針對上述機器學習模型,以下對象函數常用于檢測數據中的異常:
相似度矩陣 — 使用 outlierMeasure[6]函數計算隨機森林 (CompactTreeBagger) 中,樣本和其他觀測點之間相似度平方值的平均值;
馬氏距離 — 使用mahal[7] 函數,適用于判別分析分類模型 (ClassificationDiscriminant) 和高斯混合模型 (gmdistribution)
無條件概率密度 —使用 logp[8],適用于判別分析分類模型 (ClassificationDiscriminant) 和樸素貝葉斯分類模型 (ClassificationNaiveBayes),包括對應的增量學習模型 (incrementalClassificationNaiveBayes)
此外,利用 DeepLearningToolbox構建深度神經網絡進行異常檢測也是目前該領域的研究熱點之一。
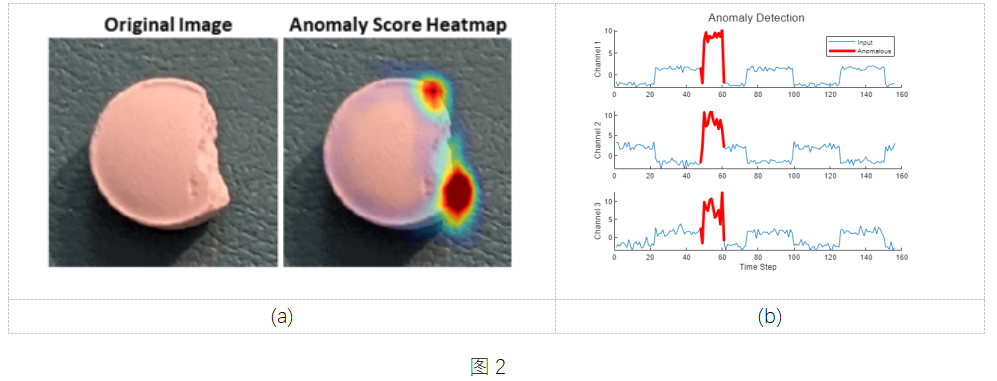
在光學檢測領域,如圖 2(a) 所示,需要檢測圖像數據中異常,可構建基于卷積神經網絡的圖像分類模型,并結合深度學習模型解析的方法,例如類激活映射,對異常區域進行可視化,具體示例可參考:Detect Image Anomalies Using Explainable One-Class Classification Neural Network。[9]
在設備預測性維護應用中,針對傳感器信號中的異常檢測,多用生成式模型,學習正常數據的特征,并嘗試重建數據,再利用重建誤差作為判定是否異常的指標,如圖 2(b) 所示,例如自編碼器AutoEncoder(Time Series Anomaly Detection Using Deep Learning )[10] 和 Graph Deviation Network (Multivariate Time Series Anomaly Detection Using Graph Neural Network) [11]進行多元時序異常檢測。
由于篇幅有限,在此先不詳細展開介紹上述方法,如感興趣,可參考對應文檔鏈接。在下一篇中,我們將討論在沒有標簽的條件下,或不確定異常類型和成因的場景中,如何針對上述數據集,利用統計和機器學習方法進行無監督異常檢測,歡迎繼續關注后續內容。
-
matlab
+關注
關注
185文章
2980瀏覽量
231007 -
異常檢測
+關注
關注
1文章
42瀏覽量
9754 -
機器學習
+關注
關注
66文章
8438瀏覽量
133084
原文標題:機器學習應用 | 使用 MATLAB 進行異常檢測(上)
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用部分異常觀測數據進行異常檢測

什么是異常檢測_異常檢測的實用方法
基于車輛軌跡特征的視頻異常事件檢測算法
采用基于時間序列的日志異常檢測算法應用
智能電網時間序列異常檢測:a survey

哈工大提出Myriad:利用視覺專家進行工業異常檢測的大型多模態模型






 工商網監
工商網監
評論