 一文徹底搞懂內存屏障與volatile
一文徹底搞懂內存屏障與volatile
最有價值的寫在最前面
內存屏障與 volatile 是高并發編程中比較常用的兩個技術,無鎖隊列的時候就會用到這兩項技術。然而這兩項技術涉及比較廣的基礎知識,所以比較難以理解,也比較不容易解釋清楚。關于內存屏障和 volatile 網上有相當多的資料,但是總感覺還是不夠系統和深入。當然由于我自身水平有限,所以也不敢保證就能把這兩個概念說清楚。所以在文章的開始,先列舉一些我在學習過程中比較好的資料。1.基本概念- 這篇博客深入淺出的介紹了內存屏障和volatile的概念,并且列舉了一些非常好的用例,可以直觀感受內存屏障與volatile的作用。并且列舉了 linux 內核中著名的無鎖隊列 kfifo 是如何使用內存屏障的。
- 這篇博客講解了 LOCK 前綴與內存屏障的關系,LOCK 是實現 CAS 操作的關鍵,所以弄清楚 LOCK 的作用也是非常有必要的。
- 《深入理解計算機系統》第三章、第四章、第六章《深入理解計算機系統》是一本神書(本文后面都簡稱CSAPP),有多神相信就不用我介紹了。第三章介紹了while循環的機器指令,第四章有關于分支預測的相關知識,第六章有關于緩存的知識。
- 《Memory Barriers: a Hardware View for Software Hackers》該文章深入淺出地講解了MESI的基本概念,MESI 引起的緩存可見性問題,從而引出了內存屏障的作用,以及為什么要使用內存屏障。該文章非常值得一讀。
《Memory Ordering in Modern Microprocessors》該文章和上一篇是同一個作者。該文章對上一篇中第6部分的內容進行了更加詳細的說明。3.Java volatile在剛開始學習volatile和內存屏障的時候,在網上搜到很多的資料都是講java實現的。volatile這個關鍵字在java和 CC++ 里面有非常大的區別,容易引起誤會。主要區別在于,java volatile 具有緩存同步的功能,而 CC++ 沒有這個功能,具體原因本文會簡單講下。詳細內容參見B站馬士兵老師的課程。 4.無鎖隊列實踐理論結合實踐,關于無鎖隊列的實現有幾篇文章值得一讀:
- 單生產者——單消費者模型 講解kfifo的實現,kfifo是linux內核實現的無鎖隊列,非常具有參考價值。
- 多對多模型 多個生產者和消費者,需要用到CAS操作。
volatile
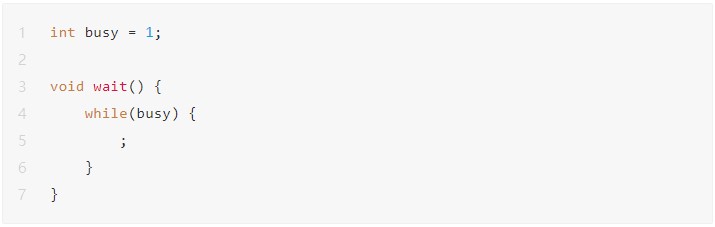
關于 volatile 關鍵字 這里有詳細描述。主要是為了防止優化編譯帶來的一些問題。注意:volatile 只作用于編譯階段,對運行階段沒有任何影響。1.防止直接從寄存器中獲取全局變量的值
//disorder_test.c #include
QUEUENODE定義了一個具體的商品。其中有兩個變量,m_flag用于標識隊列中對應位置是否存在商品,m_flag為 1 表示生產者已經生產了商品,m_flag為 0 表示商品還未被生產。m_data表示商品具體的值。m_queue為一個全局的循環隊列。Push函數向隊列中放入商品,在push前首先判斷指定位置是否存在商品,如果存在則等待(通過while自旋來實現),否則首先放入商品(為m_data賦值),再設置m_flag為 1。Pop函數用于從隊列中獲取商品,pop之前先判斷指定位置是否存在商品,如果不存在則等待(通過while自旋來實現),否則首先取出商品(將m_data賦值給goods),再設置m_flag為 0。main函數是一個死循環,每次開啟兩個線程,一個線程向隊列中push商品,一個線程從隊列中pop線程,然后等待兩個線程結束,最后打印出通過pop獲取到的商品的值,即goods。OK,現在用非優化編譯編譯該代碼,并運行:gccdisorder_test.c-odisorder_test-lpthread ./disorder_test
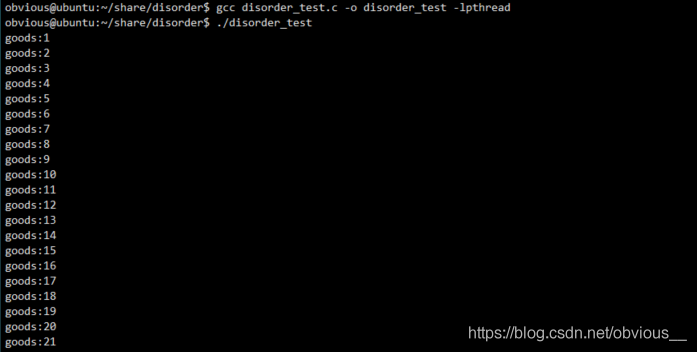 OK,看起來一切正常。現在我們換成優化編譯試試:
OK,看起來一切正常。現在我們換成優化編譯試試:gccdisorder_test.c-O2-odisorder_test-lpthread ./disorder_test
 img程序陷入了死循環…發生了什么?現在我們來看看這段代碼的匯編,首先是非優化編譯版本:
img程序陷入了死循環…發生了什么?現在我們來看看這段代碼的匯編,首先是非優化編譯版本:gcc-Sdisorder_test.c catdisorder_test.s
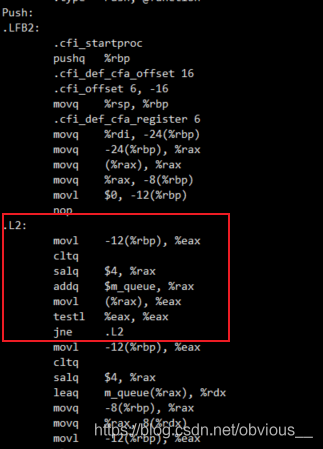 img這里我們只標注出最關鍵的部分,即 push 中的 while 循環。我們注意到,while 中每次循環都會執行取值和運算操作,然后才執行 testl 判斷。我們再來看看優化版本。
img這里我們只標注出最關鍵的部分,即 push 中的 while 循環。我們注意到,while 中每次循環都會執行取值和運算操作,然后才執行 testl 判斷。我們再來看看優化版本。gcc-S-O2disorder_test.c catdisorder_test.s
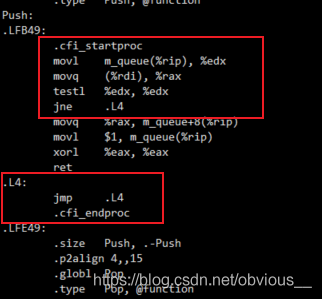 img這里就非常可怕了,可以看到
img這里就非常可怕了,可以看到.L4本身就是一個死循環,前面 testl 之后如果發現不滿足條件,則直接跳進死循環。這是為什么?我們來看看push的代碼:void*Push(void*param) { longlongdata=*(longlong*)param; intpos=data%QUEUE_LEN; while(m_queue[pos].m_flag) ; m_queue[pos].m_data=data; m_queue[pos].m_flag=1; returnNULL; } while循環會檢測m_queue[pos].m_flag,而在這個函數中,只有當m_queue[pos].m_flag為0時,循環才會跳出,執行line7及之后的代碼,而在line8才會對m_flag進行修改。所以編譯器認為在循環的過程中,沒人會修改m_flag。既然沒有修改m_flag,只要m_flag一開始的值不為0,那么m_flag就是一個不會改變的值,當然就是死循環!顯然編譯器并不知道另一個線程會執行pop函數,而pop會修改m_flag的值。如果觀察pop的匯編代碼也會發現完全相同的優化邏輯。所以,在這種情況下,就需要程序員顯式的告訴編譯器,m_flag是一個會發生改變的值,所以不要嘗試做這樣的優化。這就是volatile關鍵字。現在我們給m_flag加上volatile關鍵字:
typedefstruct { volatileintm_flag; longlongm_data; }QUEUENODE,LPQUEUENODE; 再次優化編譯并運行程序:
gccdisorder_test.c-O2-odisorder_test-lpthread ./disorder_test
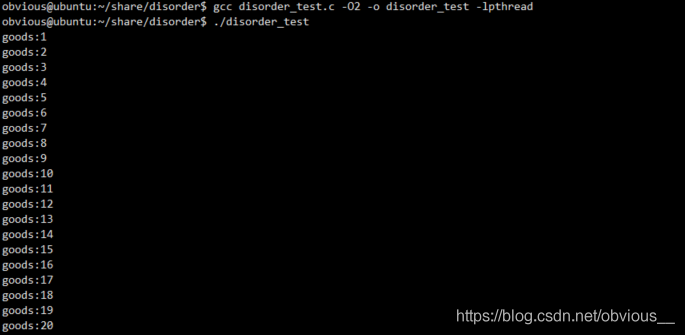 OK,一切正常!現在我們再來看看匯編代碼:
OK,一切正常!現在我們再來看看匯編代碼: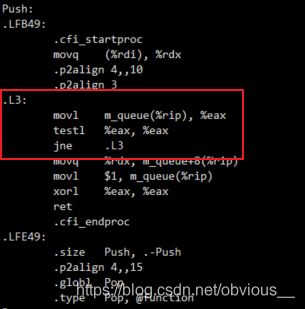 現在每次循環都會執行movl指令去獲取m_flag的值!一切都變得美好了。
現在每次循環都會執行movl指令去獲取m_flag的值!一切都變得美好了。2.防止指令亂序
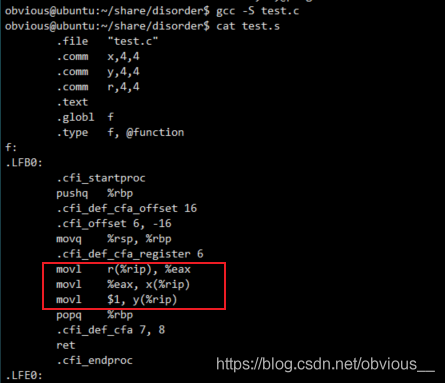
volatile 的第二個作用就是防止編譯時產生的指令亂序。這個很簡單,有如下代碼://test.c intx,y,r; voidf() { x=r; y=1; } voidmain() { f(); } 這次,我們直接對比非優化編譯與優化編譯的匯編代碼。
- 非優化編譯
- 優化編譯
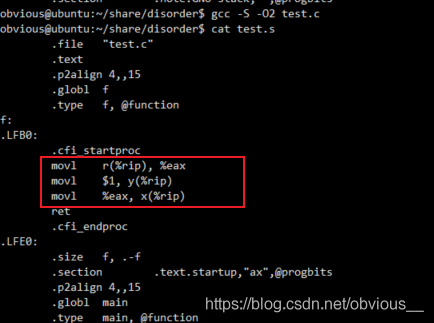 不難發現,優化編譯的版本,交換了
不難發現,優化編譯的版本,交換了x=r 和y=1的順序,先將 y 的值賦值為 1,再將 x 值賦值為 r。現在我們將 x,y, r 加上volatile關鍵字。volatileintx,y,r; 再次查看匯編代碼:
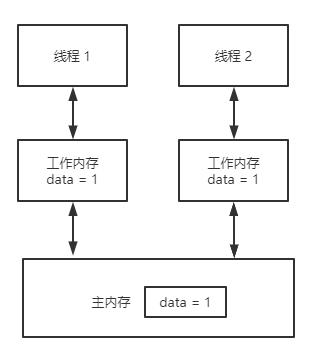
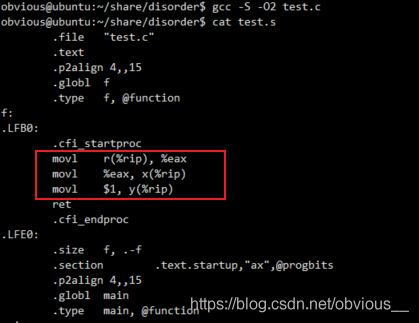 指令順序和代碼順序一致。在 https://www.runoob.com/w3cnote/c-volatile-keyword.html 介紹 volatile 時有這樣一段描述 “當使用 volatile 聲明的變量的值的時候,系統總是重新從它所在的內存讀取數據,即使它前面的指令剛剛從該處讀取過數據”。然而,實際情況真的是每次都從內存中讀取數據么?其實這只是一個籠統的說法,更為準確的說法應該是,系統不會直接從寄存器中讀取 volatile 修飾的變量。因為,寄存器的讀寫性能遠高于內存,所以在CPU寄存器和內存之前,通常有多級高速緩存。
指令順序和代碼順序一致。在 https://www.runoob.com/w3cnote/c-volatile-keyword.html 介紹 volatile 時有這樣一段描述 “當使用 volatile 聲明的變量的值的時候,系統總是重新從它所在的內存讀取數據,即使它前面的指令剛剛從該處讀取過數據”。然而,實際情況真的是每次都從內存中讀取數據么?其實這只是一個籠統的說法,更為準確的說法應該是,系統不會直接從寄存器中讀取 volatile 修飾的變量。因為,寄存器的讀寫性能遠高于內存,所以在CPU寄存器和內存之前,通常有多級高速緩存。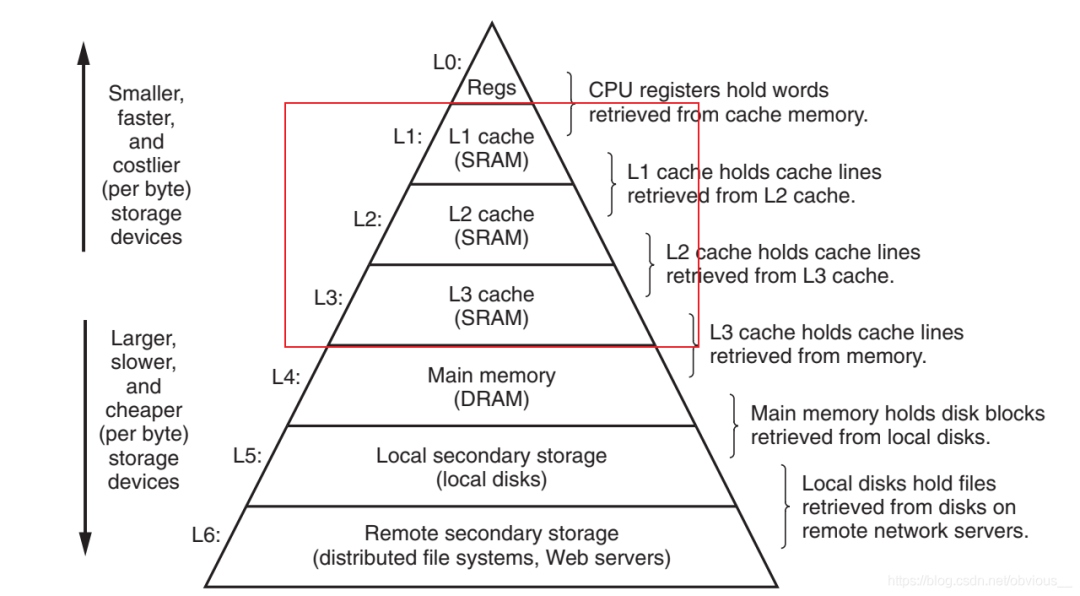 相信大家都見過這樣一張著名的圖,不難發現,圖中,在內存與寄存器之間,存在 L1、L2、L3 這樣三級緩存。所以指令在進行訪存操作的時候,會首先逐級查看緩存中是否有對應的數據,如果3級緩存有沒有期望的數據,才會訪問內存。而通常在多核CPU中緩存是如下圖所示的這樣一種結構:
相信大家都見過這樣一張著名的圖,不難發現,圖中,在內存與寄存器之間,存在 L1、L2、L3 這樣三級緩存。所以指令在進行訪存操作的時候,會首先逐級查看緩存中是否有對應的數據,如果3級緩存有沒有期望的數據,才會訪問內存。而通常在多核CPU中緩存是如下圖所示的這樣一種結構: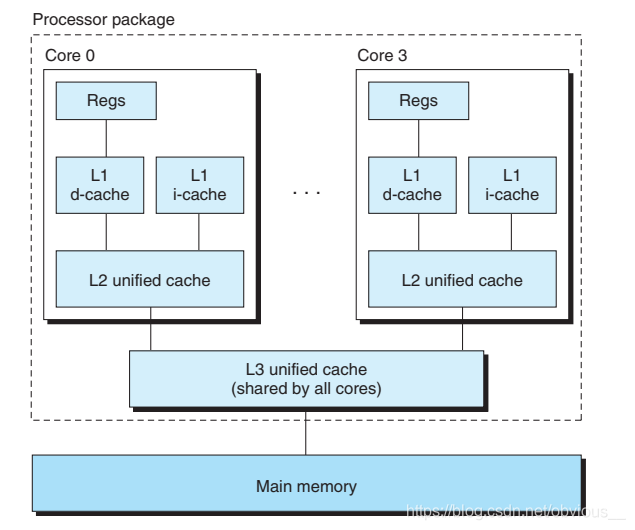 每個 CPU core 都有自己獨立的 L1 和 L2 緩存,多個 core 共享一個L3緩存,多個 CPU 有各自的 L3 緩存,多個CPU 共享內存。每個 core 都有自己獨立的 L1 和 L2 緩存,緩存可以獨立讀寫!這個就可怕了,因為這就存在不同 core 讀寫同一份數據的可能,如果不加任何限制,豈不天下大亂了?所以對于多核 CPU,需要一種機制來對緩存中的數據進行同步。這也就是我們接下來要講的
每個 CPU core 都有自己獨立的 L1 和 L2 緩存,多個 core 共享一個L3緩存,多個 CPU 有各自的 L3 緩存,多個CPU 共享內存。每個 core 都有自己獨立的 L1 和 L2 緩存,緩存可以獨立讀寫!這個就可怕了,因為這就存在不同 core 讀寫同一份數據的可能,如果不加任何限制,豈不天下大亂了?所以對于多核 CPU,需要一種機制來對緩存中的數據進行同步。這也就是我們接下來要講的MESI。MESI
MESI 在《Memory Barriers: a Hardware View for Software Hackers》一文中有非常詳細的描述,這里只對一些關鍵問題進行闡述。在描述 MESI 之前,我們先說明兩個重要的操作:- LoadLoad是指CPU從Cache中加載數據。
- StoreStore是指CPU將數據寫回Cache。
在《Memory Barriers: a Hardware View for Software Hackers》還有一個操作叫 write back(寫回),是指將Cache數據寫回內存。在 CSAPP 中,第4章講到指令的6個階段其中也有一個階段叫write back,這里是指將執行階段的結果寫回到寄存器,這兩個概念不要混淆了。MESI 是指緩存行的四種狀態:I:invalid,最簡單的一種狀態,表示該緩存行沒有數據,顯然這也是緩存行的初始狀態。S:shared,該緩存行中的數據被其他CPU共享。在shared狀態下,緩存行為只讀,不可以修改。E:exclusive,該緩存行中的數據沒有被其他CPU共享,且緩存中的數據與內存中保持一致。在exclusive狀態下,緩存行可以修改。M:modified,該緩存行保存了唯一一份 up-to-date 的數據。即該緩存行中的數據沒有被其他CPU共享,且緩存行的數據與內存不一致。這四種狀態之間是可以互相轉換的,具體的轉換方式在《Memory Barriers: a Hardware View for Software Hackers》一文中也有非常詳細的描述(重要的是事情說三遍,這篇文章很重要!!!)。這里我們只對部分狀態轉換加以說明。
- I to S
- S to E
- E to M
Store Buffer
a=1; b=a+1; assert(b==2); 如上面代碼所示。首先 line2 的加法運算要使用到 line1 中的變量a,所以兩行代碼是存在數據相關性的,那么編譯器不會嘗試交換指令順序。我們假設現在變量 a 在 CPU1 中,變量 b 在 CPU0 中,且初始值均為0。假設現在 CPU0 要執行上述代碼,根據前面 MESI 的規定,上述代碼的執行順序如下:
- CPU0 執行 a= 1
- CPU0執行b=a+1
- CPU0執行assert(b == 2)
a = 1;這行代碼不難發現,不論 CPU1 回傳給 CPU0 的值是什么,我們會將 a 的值最終修改為1,那么我們真正需要等待的只是 invalidate acknowledge。那么我們是不是可以先將a = 1;這條指令緩存起來,繼續執行后面的操作,等收到 invalidate acknowledge 之后再來真正修改 a 的值呢?答案是肯定的,如下圖所示: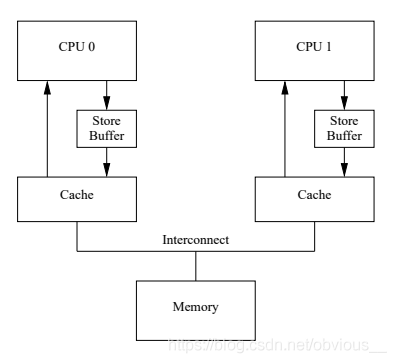
Store Buffer的問題
在 CPU 和 cache 之前,引入了一個稱為 store buffer 的緩存。現在,我們在執行a=1時,如果需要等待 invalidate acknowledge,那么就先將a=1寫入這個store buffer,然后繼續執行后面的代碼,等到收到 invalidate acknowledge 再將 store buffer 中的值寫入緩存。好了,那么現在問題來了。有了store buffer之后,前面代碼就可以是這樣的一種執行順序。- CPU0 執行a= 1
- CPU0執行b=a+1
- CPU0執行assert(b == 2)
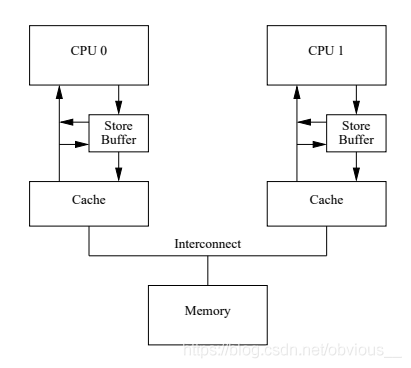 這個改進可以解決 CPU 的 self-consistency 問題,但是卻解決不了 global memory ordering 問題。有如下代碼:
這個改進可以解決 CPU 的 self-consistency 問題,但是卻解決不了 global memory ordering 問題。有如下代碼:voidfoo(void) { a=1; b=1; } voidbar(void) { while(b==0) continue; assert(a==1); } 假設,a,b初始值為0。a 在CPU1中且為 exclusive 狀態,b 在 CPU0 中且為 exclusive 狀態,CPU0 執行 foo(),CPU1 執行 bar()。情況如下:
- CPU0執行 a=1
- CPU1 執行 whie(b == 0)
- CPU0執行b=1
- CPU0 收到 CPU1 的 read 消息
- CPU1 收到 CPU0 的 read ack
-
CPU1執行
assert(a == 1);
- CPU1 收到 CPU0 的read invalidate
- CPU0收到CPU1的值以及invalid ack
內存屏障
造成上述問題的核心是a=1;還沒有被所有CPU的可見的時候,b=1;已經被所有CPU都可見了。而a=1不可見的原因是 store buffer 中的數據還沒有應用到緩存行中。解決這個問題可以有兩種思路:- store buffer 中還有數據時暫停執行。
- store buffer中還有數據時把后續的 store 操作也寫入 store buffer。
voidfoo(void) { a=1; smp_mb();//內存屏障 b=1; } voidbar(void) { while(b==0)continue; assert(a==1); } 按照思路1,CPU0 執行到 line4 時,發現 store buffer 中有 a=1,于是暫停執行,直到 store buffer 中的數據應用到cache中,再繼續執行 b=1。這樣便沒問題了。按照思路2,CPU0 執行到 line4 時,發現 store buffer中有 a=1,于是將該條目做一個標記(標記store buffer中的所有當前條目)。在執行b=1時,發現store buffer中有一個帶標記的條目,于是將b=1也寫入store buffer,這樣b=1對于CPU1也就不可見了。只有當代標記的條目應用于緩存之后,后續條目才可以應用于緩存。這相當于只有當標記條目都應用于緩存后,后續的store操作才能進行。通過這兩種方式就很好的解決了緩存可見性問題。仔細觀察這個流程,其實感覺有點數據庫事務的意思,哈哈,技術果然都是互通的。不難發現,內存屏障限制了CPU的執行流程,所以同樣會有一定的性能損失,但是顯然不滿足正確性任何性能都是扯淡。
Invalidate Queue
在使用了內存屏障之后,store buffer中就可能堆積很多條目,因為必須等到帶有標記的條目應用到緩存行。store buffer的大小也是有限的,當store buffer滿了之后便又會出現前面提到的性能問題。所以還有什么優化的方式么?MESI 性能問題的核心是 Invalidate ack 耗時太長。而這個耗時長的原因是,CPU必須確保cache真的被invalidate了才會發送 Invalidate ack。而在CPU忙時顯然會增加 Invalidate ack 的延遲。那么我們是不是也可以像store buffer那樣把invalidate 消息緩存起來呢?這個顯然也是可以的。于是,工程師們又增加了invalidate queue來緩存 invalidate 消息。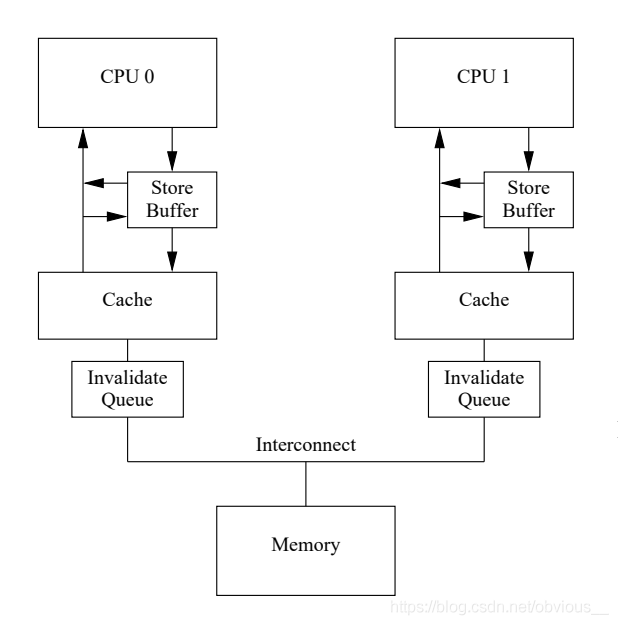 CPU收到invalidate消息后,不用真正等到 cache invalidate,只需要將 invalidate 消息存放到 Invalidatae Queue 中就可以發送 invalidate ack了。而收到 invalidate ack 的 CPU 就可以將 store buffer 中相應的條目應用到 cache。
CPU收到invalidate消息后,不用真正等到 cache invalidate,只需要將 invalidate 消息存放到 Invalidatae Queue 中就可以發送 invalidate ack了。而收到 invalidate ack 的 CPU 就可以將 store buffer 中相應的條目應用到 cache。Invalidate Queue的問題
前面store buffer的經驗告訴我們,天下沒有免費的午餐。Invalid Buffer的引入同樣也會帶來問題。我們再來看看前面的代碼:voidfoo(void) { a=1; smp_mb();//內存屏障 b=1; } voidbar(void) { while(b==0)continue; assert(a==1); } 假設,a,b初始值為0。a在CPU0和CPU1之前共享,狀態為shared,b在CPU0中且為exclusive狀態,CPU0執行foo(),CPU1執行bar()。情況如下:
- CPU0執行a=1
- CPU1執行whie(b == 0)
- CPU1收到invalidate消息
- CPU0收到invalidate ack
- CPU0執行b=1;
- CPU0收到CPU1的read消息
- CPU1收到CPU0的read ack
- CPU1執行assert(a == 1);
voidfoo(void) { a=1; smp_mb();//內存屏障 b=1; } voidbar(void) { while(b==0)continue; smp_mb();//內存屏障 assert(a==1); } 使用內存屏障后,會標記store buffer中的所有當前條目,只有當所有標記的條目都應用于緩存后,后續的load操作才能進行。
When a given CPU executes a memory barrier, it marks all the entries currently in its invalidate queue, and forces any subsequent load to wait until all marked entries have been applied to the CPU’s cache.所以在加上內存屏障之后,在執行 assert(a == 1)之前需要先將invalidate queue中的條目應用于緩存行。所以在執行
a== 1時,CPU1 會發現 a 不在 CPU1 的緩存,從而給 CPU0 發送read消息,獲得 a 的值1,最終assert(a == 1); 成功。其實在這里內存屏障還有一個非常重要的作用,因為a==1并不一定要等 b != 0時才會執行。這又是為什么?while (b == 0) continue;是一個條件循環,條件循環的本質是條件分支+無條件循環(IF+LOOP)。在執行條件分支時,為了更好的利用指令流水,有一種被稱作分支預測的機制。所以實際執行的時候可能會假定條件分支的值為FALSE,從而提前執行 assert(a == 1);關于while循環和指令流水可以參見CSAPP的第三、第四章。
三種內存屏障
smp_mb(); 會同時作用于store buffer和invalidate queue,所以被稱為全屏障。在上述代碼中,我們不難發現一個問題,foo()函數只會用到store buffer,而bar()函數只會用到invalidate queue。根據這個特點,除了全屏障之外通常還有讀屏障(smp rmb())和寫屏障(smp rmb())。讀屏障只作用于invalidate queue,而寫屏障只作用于store buffer。所以上述代碼還可以修改為下面的方式:voidfoo(void) { a=1; smp_wmb();//寫屏障 b=1; } voidbar(void) { while(b==0)continue; smp_rmb();//讀屏障 assert(a==1); }
內存屏障的使用
什么時候需要使用內存屏障
其實,在我們日常的開發中,尤其是應用研發。我們根本就用不上內存屏障?這是為什么?雖然內存屏障用不上,但是在并發編程里面鎖的概念卻無處不在!信號量、臨界區等等。然而這些技術的背后都是內存屏障。道理其實很簡單,種種的線程進程同步的手段,實際上都相當于鎖。對于臨界資源的訪問,我們總是希望先上鎖,再訪問。所以顯然,我們肯定不希望加鎖后的操作由于CPU的種種優化跑到了加鎖前去執行。那么這種時候自然就需要使用內存屏障。所以,對于使用了 線程進程 同步的手段進行加鎖的代碼,不用擔心內存屏障的問題。只有為了提高并發性采用的很多無鎖設計,才需要考慮內存屏障的問題。當然,對于單線程開發和單核CPU也不用擔心內存屏障的問題。補充:鎖是如何實現的通常情況下,鎖都是基于一種叫做CAS(compare-and-swap)的操作實現的。CAS的代碼如下:
static__inline__int tas(volatileslock_t*lock) { registerslock_t_res=1; __asm____volatile__( "lock " "xchgb%0,%1 " :"+q"(_res),"+m"(*lock) :/*noinputs*/ :"memory","cc"); return(int)_res; } 其中:xchgb 就是實現 CAS 的指令,而在 xchgb 之前有一個 lock 前綴,這個前綴的作用是鎖總線,達到的效果就是內存屏障的效果。這也就是為什么使用了鎖就不用擔心內存屏障的問題了。而 JAVA 對于內存屏障的底層實現其實就是用的這個lock。
實際案例
linux 內核的無鎖隊列 kfifo 就使用了內存屏障。這里主要說明__kfifo_put()函數和__kfifo_get()。__kfifo_put()用于向隊列中寫入數據,__kfifo_get()用于從隊列中獲取數據。/** *__kfifo_put-putssomedataintotheFIFO,nolockingversion *@fifo:thefifotobeused. *@buffer:thedatatobeadded. *@len:thelengthofthedatatobeadded. * *Thisfunctioncopiesatmost@lenbytesfromthe@bufferinto *theFIFOdependingonthefreespace,andreturnsthenumberof *bytescopied. * *Notethatwithonlyoneconcurrentreaderandoneconcurrent *writer,youdon'tneedextralockingtousethesefunctions. */ unsignedint__kfifo_put(structkfifo*fifo, unsignedchar*buffer,unsignedintlen) { unsignedintl; len=min(len,fifo->size-fifo->in+fifo->out); /* *Ensurethatwesamplethefifo->outindex-before-we *startputtingbytesintothekfifo. * line19是讀操作,line30之后是寫操作(向隊列中寫數據),所以需要使用全屏障(隔離讀和寫)。 */ smp_mb(); /*firstputthedatastartingfromfifo->intobufferend*/ l=min(len,fifo->size-(fifo->in&(fifo->size-1))); memcpy(fifo->buffer+(fifo->in&(fifo->size-1)),buffer,l); /*thenputtherest(ifany)atthebeginningofthebuffer*/ memcpy(fifo->buffer,buffer+l,len-l); /* *Ensurethatweaddthebytestothekfifo-before- *weupdatethefifo->inindex. * line34是寫操作,line44也是寫操作,所以使用寫屏障(隔離寫和寫)。 */ smp_wmb(); fifo->in+=len; returnlen; } EXPORT_SYMBOL(__kfifo_put);
/** *__kfifo_get-getssomedatafromtheFIFO,nolockingversion *@fifo:thefifotobeused. *@buffer:wherethedatamustbecopied. *@len:thesizeofthedestinationbuffer. * *Thisfunctioncopiesatmost@lenbytesfromtheFIFOintothe *@bufferandreturnsthenumberofcopiedbytes. * *Notethatwithonlyoneconcurrentreaderandoneconcurrent *writer,youdon'tneedextralockingtousethesefunctions. */ unsignedint__kfifo_get(structkfifo*fifo, unsignedchar*buffer,unsignedintlen) { unsignedintl; len=min(len,fifo->in-fifo->out); /* *Ensurethatwesamplethefifo->inindex-before-we *startremovingbytesfromthekfifo. * line18讀操作,line29是讀操作(從隊列中讀數據),所以需要使用讀屏障(隔離讀和讀)。 */ smp_rmb(); /*firstgetthedatafromfifo->outuntiltheendofthebuffer*/ l=min(len,fifo->size-(fifo->out&(fifo->size-1))); memcpy(buffer,fifo->buffer+(fifo->out&(fifo->size-1)),l); /*thengettherest(ifany)fromthebeginningofthebuffer*/ memcpy(buffer+l,fifo->buffer,len-l); /* *Ensurethatweremovethebytesfromthekfifo-before- *weupdatethefifo->outindex. * line33是讀操作,line43是寫操作,所以需要使用全屏障(隔離讀和寫)。 */ smp_mb(); fifo->out+=len; returnlen; } EXPORT_SYMBOL(__kfifo_get); kfifo 的詳細內容,請查閱相關資料,這里不再贅述。
深入理解
我們不難發現,不論是__kfifo_put還是__kfifo_get都使用了兩次內存屏障。我們以__kfifo_put為例子來觀察下這兩個內存屏障,在__kfifo_put中,第一次使用內存屏障是 line27 的 smp_mb 第二次是 line42 的 smp_wmb。現在思考一個問題,這兩個內存屏障可以省略么?為了解決這個問題,我們需要思考,如果省略了內存屏障會有什么問題?省略 smp_mb
- 省略 smp_mb 會出現優化編譯導致的指令亂序么?
- 省略 smp_mb 會造成緩存可見性問題么?
__kfifo_get函數修改。如果省略smp_mb在執行line30之前,__kfifo_get對于fifo->out的修改對于__kfifo_put可能不可見。不可見會造成什么后果?在__kfifo_get中會增加fifo->out的長度,如果這個增加不可見,那么line19的len值就會小一些(相對于可見情況),也就是說可以put的數據就少一些,除此之外并沒有什么其他后果。kfifo隊列依然可以正常工作。綜上所述,如果省略smp_mb,會造成一些性能問題,但不會有正確性問題。省略smp_wmb
- 省略smp_wmb會出現優化編譯導致的指令亂序么?
- 省略smp_wmb會造成緩存可見性問題么?
驗證
好了,我們可以驗證下上面的說法。上面闡述的代碼是linux新版本的kfifo。我們可以看看老版本的kfifo是如何實現的。在linux-3.0.10內核代碼中,可以找到老版本的kfifo。其中最重要的兩個函數是__kfifo_in(對應__kfifo_put)和__kfifo_out(對應__kfifo_get)。為了方便閱讀,我將__kfifo_in中的函數調用直接展開,如下圖: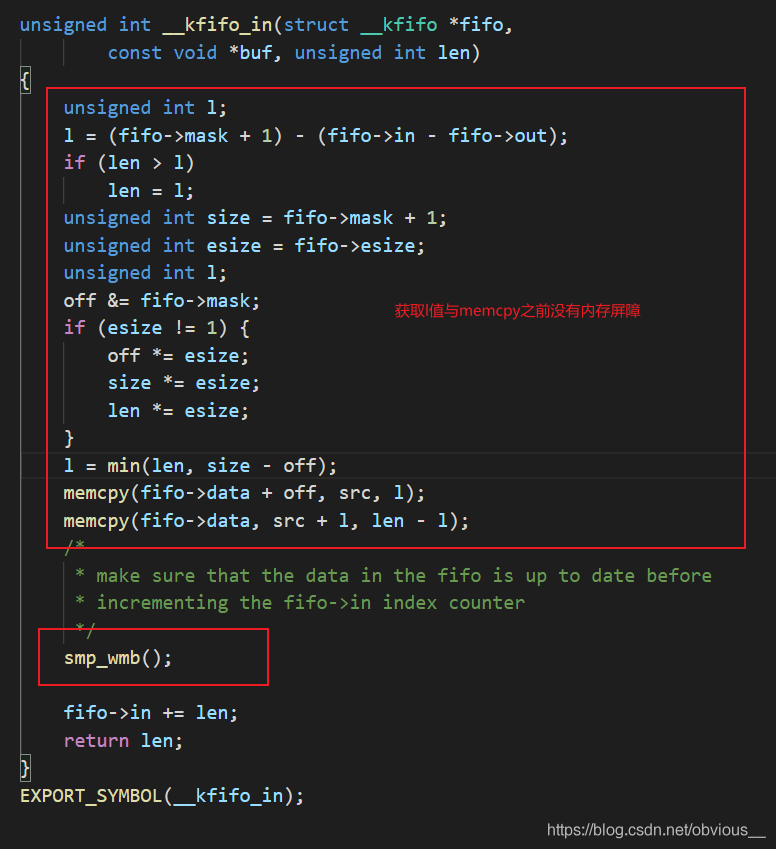 不難發現,老版的 __kfifo_in 就只使用了一個內存屏障,在 memcpy 和修改 fifo->in 之間,這也就是我們之前說的那個不可以省略的 smp_wmb。
不難發現,老版的 __kfifo_in 就只使用了一個內存屏障,在 memcpy 和修改 fifo->in 之間,這也就是我們之前說的那個不可以省略的 smp_wmb。審核編輯:湯梓紅
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
計算機
+關注
關注
19文章
7536瀏覽量
88639 -
volatile
+關注
關注
0文章
45瀏覽量
13061 -
內存屏障
+關注
關注
0文章
3瀏覽量
1758
原文標題:【C語言】徹底搞懂內存屏障與volatile
文章出處:【微信號:C語言學習聯盟,微信公眾號:C語言學習聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從硬件引申出內存屏障,帶你深入了解Linux內核RCU
本文從硬件的角度引申出內存屏障,這不是內存屏障的詳盡手冊,但是相關知識對于理解RCU有所幫助。
淺談緩存一致性協議 處理器與內存之間交互技術
在多線程并發的世界里synchronized、volatile、JMM是我們繞不過去的技術坎,而重排序、可見性、內存屏障又有時候搞得你一臉懵逼。
ARM體系結構之內存序與內存屏障
本文介紹 Armv8-A 架構的內存序模型,并介紹 arm 的各種內存屏障。本文還會指出一些需要明確內存保序的場景,并指明如何使用
發表于 06-15 18:19
?1789次閱讀
一文搞懂UPS主要內容
導讀:UPS是系統集成項目中常用到的設備,也是機房必備的設備。本文簡單介紹了UPS的種類、功能、原理,品質選擇與配置選擇方式,基礎維護等相關的內容。一文搞懂UPS本文主要內容:UPS種類、功能
發表于 09-15 07:49
學習下ARM內存屏障(memory barrier)指令
;等待前面的指令完成后更改系統寄存器。DMB(Data Memory Barrier)指令是一種內存屏障指令,它確保了屏障之前的內存訪問與之
發表于 02-07 14:08
volatile修飾的變量的認識和理解
,所有的讀操作都可以看到這個修改,即便使用了本地緩存也一樣,volatile會被立即寫入到主內存中,而讀的操作就發生在主內存中。在非volatile
發表于 12-01 11:36
?5774次閱讀


C語言中的關鍵字volatile到底有什么用呢
內存屏障是一類機器指令,該指令對處理器在該屏障指令之前與之后的內存操作進行了限制,確保不會出現重排問題。而
一文詳解volatile關鍵字
volatile 是易變的、不穩定的意思。和const一樣是一種類型修飾符,volatile關鍵字修飾的變量,編譯器對訪問該變量的代碼不再進行優化,從而可以提供對特殊地址的穩定訪問。
volatile的原理
今天來了解一下面試題:你對 volatile 了解多少。要了解 volatile 關鍵字,就得從 Java 內存模型開始。最后到 volatile
一文搞懂DDR內存原理
內存(DRAM-RandomAccessMemory)作為當代數字系統最主要的核心部件之一,從各種終端設備到核心層數據處理和存儲設備,從各種消費類電子設備到社會各行業專用設備,是各種級別的CPU進行





 工商網監
工商網監
評論