") CXL內(nèi)存延遲到底有多糟糕?
CXL內(nèi)存延遲到底有多糟糕?
傳統(tǒng)觀點認為,如果您非常關心延遲,那么嘗試將系統(tǒng)內(nèi)存連接到 PCI-Express 總線并不是一個好主意。因為內(nèi)存離 CPU 越遠,延遲就越高,這就是內(nèi)存 DIMM 通常盡可能靠近插槽的原因。
從邏輯上講,PCI-Express 是千里之外的。隨著每一代 PCI-Express 帶寬翻倍,如果沒有重定時器的幫助也會增加延遲,它可以傳輸?shù)木嚯x也會縮短。對于我們習慣于連接到 PCI-Express 的大多數(shù)類型的內(nèi)存來說,這不是什么大問題。閃存存儲的延遲以幾十微秒為單位的情況并不少見,這使得互連產(chǎn)生的額外幾百納秒成為一個有爭議的問題。然而,我們對DDR 和其他形式的易失性存儲器就沒有那么寬容了。
以前的內(nèi)存擴展嘗試都陷入了妥協(xié),特別是在延遲方面。例如,GigaIO 表示其FabreX 架構已經(jīng)可以使用 DMA 在 PCI-Express 上進行內(nèi)存池化,但這樣做需要應用程序能夠容忍 500 納秒到 1.5 微秒的延遲。
同樣,根據(jù) Blocks and Files 的說法,在英特爾今年夏天毫不客氣地削減其 Optane 持久內(nèi)存業(yè)務之前,部署該技術意味著會產(chǎn)生大約350 納秒的延遲。雖然可用,尤其是在分層內(nèi)存配置中,但它比直接連接 CPU 的 DDR 內(nèi)存預期的低于 100 納秒的往返延遲要長得多。
進入 CXL 內(nèi)存生態(tài)系統(tǒng)
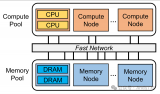
這為我們帶來了使用 Compute Express Link 協(xié)議或 CXL 的第一代內(nèi)存擴展模塊。基于 AMD 的Epyc 9004“Genoa”處理器的系統(tǒng)是首批系統(tǒng)之一,擁有 64 條 CXL 連接通道——不同于其 128 至 160 條整體 PCI-Express 通道——最多可分為四到十六個設備。至于英特爾將如何在其“Sapphire Rapids”Xeon SP 處理器上實施 CXL,我們將不得不等到它們明年初問世。
與這些服務器相得益彰的是我們確信的第一個是許多 CXL 內(nèi)存擴展模塊。雖然 CXL 最終將允許完全分解的系統(tǒng),在這些系統(tǒng)中,資源可以通過高速結構在整個機架上共享,但距離那一天還有幾年的時間。
對于首次涉足數(shù)據(jù)中心,CXL 直接專注于內(nèi)存擴展、分層內(nèi)存和一些早期的內(nèi)存池應用程序。目前,我們只關注內(nèi)存擴展,因為在這個早期階段,它可以說是最簡單和最實用的,尤其是在以可用延遲附加內(nèi)存時。
三星和Astera Labs已經(jīng)展示了 CXL 內(nèi)存模塊,他們說只需將它們插入兼容的 PCI-Express 5.0 插槽,即可為系統(tǒng)添加數(shù) TB 的內(nèi)存。從系統(tǒng)的角度來看,它們的外觀和行為就像通過內(nèi)存總線連接到相鄰插槽的常規(guī) DDR DRAM 內(nèi)存。
在最長的時間里,一旦達到 CPU 內(nèi)存控制器的限制,添加更多內(nèi)存的唯一方法就是添加更多插槽。如果工作負載可以利用額外的線程,那就更好了,但如果不能,這將成為一種非常昂貴的添加內(nèi)存的方式。實際上,額外的插槽只是一個內(nèi)存控制器,上面附有一堆昂貴的、不需要的內(nèi)核。
內(nèi)存擴展模塊的行為方式大致相同,但它不是使用專有的插槽到插槽互連,如英特爾的 UPI 或 AMD 的 xGMI 鏈接,而是 CXL。這意味著您可以擁有這些設備的整個生態(tài)系統(tǒng),事實上,我們已經(jīng)看到一個相當充滿活力,有時甚至是令人向往的設備圍繞 CXL 展開。
CXL 總裁 Siamak Tavallaei在 SC22上告訴 The Next Platform ,CXL 實際上包含三種協(xié)議,但并非所有協(xié)議都是延遲的靈丹妙藥。“CXL.io 仍然具有您預期的相同類型的延遲(來自 PCI-Express),但其他兩個協(xié)議——CXL.cache 和 CXL.mem——通過協(xié)議采用更快的路徑,并且它們減少了延遲。”
CXL 內(nèi)存延遲到底有多糟糕?
如果 Astera 值得信任,延遲并不像您想象的那么糟糕。該公司的Leo CXL 內(nèi)存控制器旨在接受高達 5600 MT/秒的標準 DDR5 內(nèi)存 DIMM。他們聲稱客戶可以預期延遲與訪問第二個 CPU 上的內(nèi)存大致相當,一個 NUMA 躍點。這使得它在 170 納秒到 250 納秒附近。事實上,就系統(tǒng)而言,這正是這些內(nèi)存模塊向操作系統(tǒng)顯示的方式。
Tavallaei 解釋說,大多數(shù) CXL 內(nèi)存控制器會增加大約 200 納秒的延遲,額外的重定時器會增加或花費幾十納秒,具體取決于設備與 CPU 的距離。這與其他 CXL 早期采用者所看到的一致。GigaIO 首席執(zhí)行官 Alan Benjamin 告訴The Next Platform,它所見過的大多數(shù) CXL 內(nèi)存擴展模塊的延遲都接近 250 納秒,而不是 170 納秒。
然而,正如 Tavallaei 指出的那樣,這仍然是對四插槽或八插槽系統(tǒng)的改進,在這些系統(tǒng)中,應用程序可能僅僅因為需要內(nèi)存而不得不應對多個 NUMA 躍點。(不過,公平地說,IBM 和英特爾在 CPU 之間添加了更多更快的鏈接,以減少跳數(shù)和每跳延遲。)
話雖如此,許多芯片制造商很快指出,CXL 生態(tài)系統(tǒng)現(xiàn)在才剛剛起步。在 CXL 董事會任職的 AMD 的 Kurtis Bowman 告訴The Next Platform,許多早期的 CXL 概念驗證和產(chǎn)品都使用尚未針對延遲進行優(yōu)化的 FPGA 或第一代 ASIC。隨著時間的推移,他預計延遲會大大改善。
如果 CXL 供應商能夠像他們聲稱的那樣,在展廳演示之外實現(xiàn)與多插槽系統(tǒng)同等的延遲,那么它應該在很大程度上消除利用它們所需的應用程序或操作系統(tǒng)特定定制的需要。好吧,至少就內(nèi)存擴展而言。正如我們在 Optane 中看到的那樣,CXL 內(nèi)存分層幾乎肯定需要某種操作系統(tǒng)或應用程序支持。
隨著插槽變得越來越大并且在板上安裝更多 DIMM 變得越來越難,這再合適不過了。放置它們的地方更少了。有可容納 32 個 DIMM 的雙插槽系統(tǒng),但隨著芯片制造商增加更多通道以滿足更高核心數(shù)的帶寬需求,這是不可擴展的。
我們已經(jīng)在某種程度上在 AMD 的 Genoa 芯片上看到了這一點,盡管該芯片將內(nèi)存通道數(shù)量增加到 12 個,但在發(fā)布時每個通道僅支持一個 DIMM,將雙插槽配置中的 DIMM 數(shù)量限制為 24 個。即使您可以為每個通道連接兩個 DIMM,我們被告知將 48 個 DIMM 安裝到標準機箱中是不切實際的。
當我們希望在更遠的距離(例如跨機架)連接內(nèi)存時,事情會變得更加復雜,因為電或光互連產(chǎn)生的延遲必須計入方程式。但對于機箱內(nèi) CXL 內(nèi)存擴展,延遲似乎并不像許多人擔心的那么令人頭疼。
審核編輯 :李倩
-
amd
+關注
關注
25文章
5500瀏覽量
134657 -
內(nèi)存
+關注
關注
8文章
3055瀏覽量
74338 -
生態(tài)系統(tǒng)
+關注
關注
0文章
704瀏覽量
20784
原文標題:CXL,面臨嚴峻的延遲問題
文章出處:【微信號:芯長征科技,微信公眾號:芯長征科技】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
內(nèi)存擴展CXL加速發(fā)展,繁榮AI存儲

SMART Modular世邁科技CXL內(nèi)存擴充卡獲CXL聯(lián)盟認證
TLC2578芯片中FS與SDI到底有什么作用?
瀾起科技CXL?內(nèi)存擴展控制器芯片通過CXL 2.0合規(guī)性測試
RK3506到底有多香?搶先看核心板詳細參數(shù)配置

24位或者說高分辨率的AD到底有什么用呢?
差分輸入和和單端輸入在本質(zhì)上到底有什么區(qū)別?
TFP401APZP到底有沒有HSYNC輸出?
影響內(nèi)存延遲的因素有哪些
業(yè)界首創(chuàng)512GB CXL AIC內(nèi)存擴展卡,江波龍革新AI與高性能計算領域內(nèi)存技術

FORESEE CXL 2.0內(nèi)存拓展模塊

利用CXL技術重構基于RDMA的內(nèi)存解耦合





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論