 點云分割相較圖像分割的優勢是啥?
點云分割相較圖像分割的優勢是啥?
0. 筆者個人體會
近年來,自動駕駛領域的各項下游任務基本上都要求了對場景的語義理解,比如自動駕駛車輛要能夠理解哪個是路面、哪個是交通燈、哪個是行人、哪個是樹木,因此點云分割的作用就不言而喻。
但隨著Transformer模型的大火,用于點云分割的深度神經網絡的參數量越來越龐大,動不動就上億參數。想要訓練如此龐大的模型,除了需要足夠強的GPU外,還需要大量的標簽和數據。數據很容易得到,64線的激光雷達一幀可以打出十幾萬個點云,現有的雷達數據集也不少了。但標簽呢?給點云打過label的人都知道這個過程有多繁瑣(haaaaa)。
由此,點云分割模型便出現了各種各樣的訓練范式,主要包括有監督、弱監督、無監督以及半監督。那么哪種訓練方法才是最優的?顯然這個問題在不同場景下有不同的答案。本文將帶領讀者閱讀幾種主流的頂會框架,探討不同訓練方法的基本原理。當然筆者水平有限,若有理解不當的地方,歡迎大家一起探討,共同學習!
劃重點,本文提到的算法都是開源的!文末附代碼鏈接!各位讀者可在現有模型的基礎上設計自己的點云分割模型。
1. 點云分割相較圖像分割的優勢是啥?
自動駕駛領域的下游任務,我認為主要包括目標檢測、語義分割、實例分割和全景分割。其中目標檢測是指在區域中提取目標的候選框并分類,語義分割是對區域中不同類別的物體進行區域性劃分,實例分割是將每個類別進一步細化為單獨的實例,全景分割則要求對區域中的每一個像素/點云都進行分類。
因為圖像中存在大量且豐富的紋理信息,且相機相較于雷達很便宜,所以對圖像進行分割非常容易。近年來也涌現了一大批圖像語義分割的深度模型,比如我們所熟知的ViT、TransUNet、YOLOP等等。各自架構層出不窮,不停的在各種排行榜上提點,似乎圖像語義分割已經非常完美。
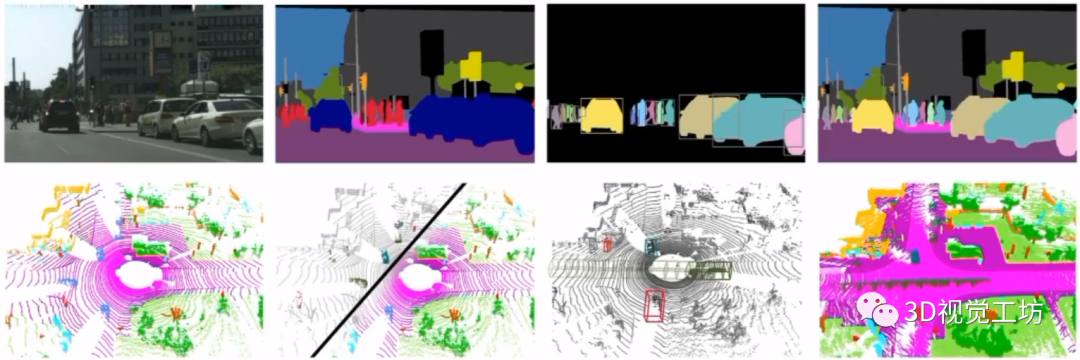
那么為啥還要對雷達點云進行分割呢?
主要有三個原因:
(1) 激光雷達可以獲得絕對尺度。
我們知道單目圖像是無法獲得絕對尺度的,并且自動駕駛汽車在長時間運行過程中也會發生尺度漂移問題。雖然現有的一些方法在嘗試從單目圖像中恢復出絕對尺度,但基本上也都不太準確。這就導致了單純從圖像中提取出來的語義信息,很難直接應用于軌跡規劃、避障、巡航等自動駕駛任務。
(2) 激光雷達對強/弱光線非常魯棒
視覺語義分割非常受光照和惡劣天氣影響,在過強、過弱、模糊等光線條件下,分割結果往往會出現很嚴重的畸變。但對于自動駕駛任務來說,惡劣天氣顯然是無法避免的。
(3) 激光雷達可以對環境進行3D感知
我們希望自動駕駛汽車能夠對周圍的整體環境進行全方位的感知,這對于激光雷達來說很容易。但對于圖像來說就很難了,僅僅依靠單目圖像很難恢復出完整的環境。依靠環視相機進行BEV感知的話也會帶來像素畸變問題。
2. 都用啥數據集?
這里介紹幾個主流的點云分割數據集,用于模型的訓練和評估。
2.1 nuScenes-Lidarseg數據集
數據集鏈接:https://www.nuscenes.org/nuscenes#lidarseg(注意總文件有293G)
nuScenes數據集是由Motional公司在2019年3月發布的用于自動駕駛的共有大型數據集。數據集來源于波士頓和新加坡采集的1000個駕駛場景,每個場景選取了20秒長的視頻,共計大約15小時的駕駛數據。場景選取時充分考慮多樣化的駕駛操作、交通情況和意外情況等,例如不同地點、天氣條件、車輛類型、植被、道路標和駕駛規則等。
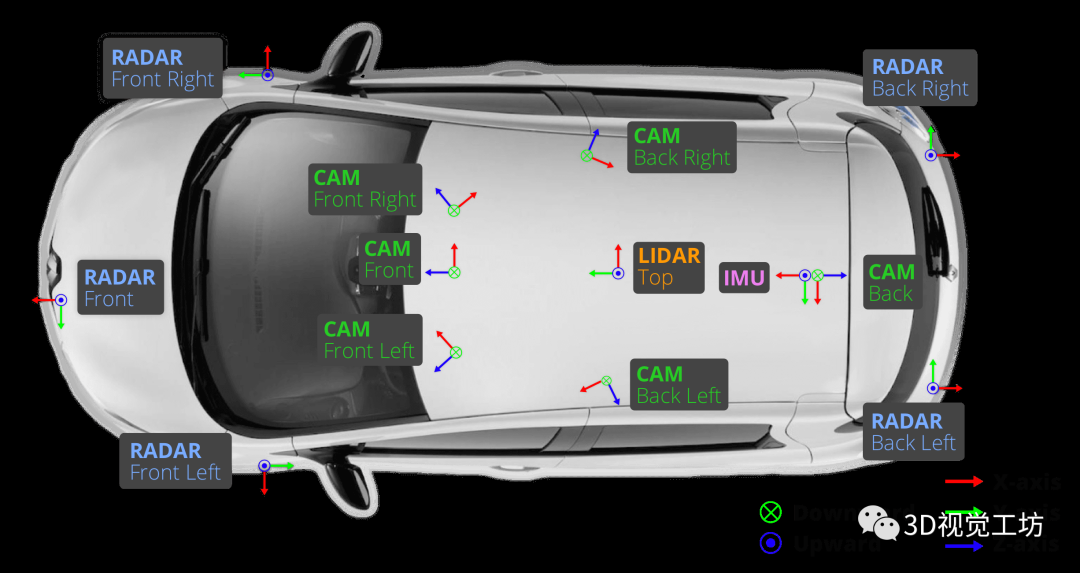
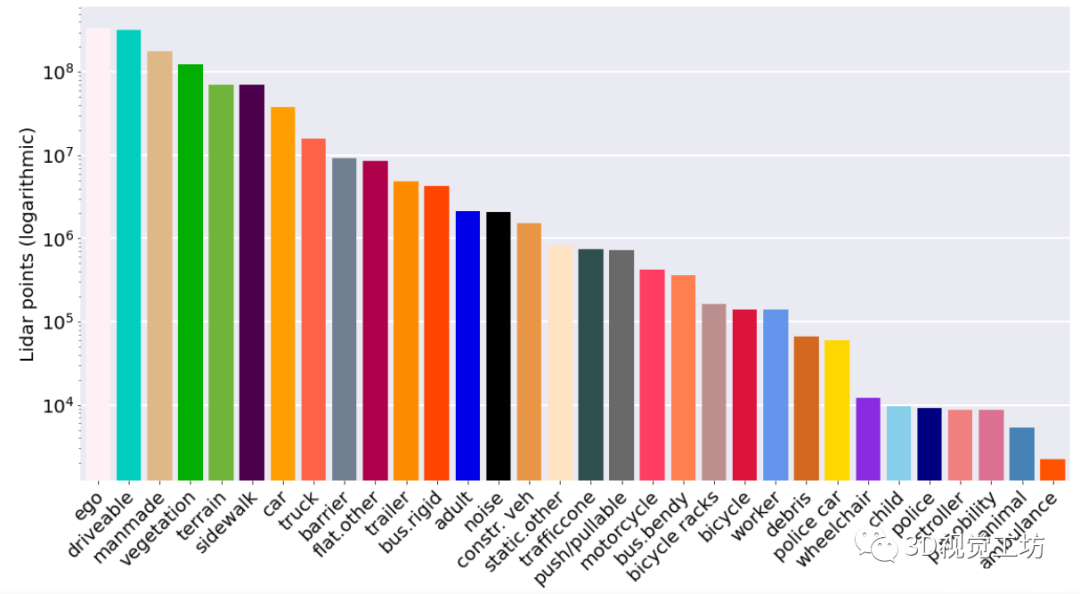
完整的nuScenes數據集包括大約140萬個圖像、40萬個激光雷達點云、140萬個雷達掃描和4萬個關鍵幀中的140萬個對象邊界框。其傳感器包括6個攝像頭、1個32線激光雷達、5個毫米波雷達、GPS和IMU,如下圖所示。2020年7月發布的nuScenes-lidarseg數據集,增加了激光雷達點云的語義分割標注,涵蓋了23個前景類和9個背景類。nuScenes-lidarseg在40萬個點云和1000個場景(850個用于訓練和驗證的場景,150個用于測試的場景)中包含14億個注釋點。
2.2 SemanticKITTI數據集
數據集地址:http://www.semantic-kitti.org/index.html
SemanticKITTI數據集是一個基于KITTI Vision Benchmark里程計數據集的大型戶外點云數據集,顯示了市中心的交通、住宅區,以及德國卡爾斯魯厄周圍的高速公路場景和鄉村道路。原始里程計數據集由22個序列組成,作者將序列00到10拆分為訓練集,將11到21拆分為測試集,并且為了與原始基準保持一致,作者對訓練和測試集采用相同的劃分,采用和KITTI數據集相同的標定方法,這使得該數據集和KITTI數據集等數據集可以通用。
SemanticKITTI數據集作者提供了精確的序列掃描注釋,并且在點注釋中顯示了前所未有的細節,包含28個類。

2.3 ScribbleKITTI數據集
這個數據集很新,是CVPR2022 Oral的成果。
論文鏈接:https://arxiv.org/abs/2203.08537
數據集鏈接:http://github.com/ouenal/scribblekitti
ScribbleKITTI數據集希望通過利用弱監督(weak supervision)來實現3D語義分割方法,首次提出了使用涂鴉(scribbles)對雷達點云進行標注。但這也導致那些包含邊緣信息的未標注點并未被使用,且由于缺乏大量標注點(該方法只使用8%的標注點)的數據,影響了具有長尾分布的類置信度,最終使得模型性能有所下降。
因此,ScribbleKITTI還提出了一個額外的pipeline,用以減少這種性能差距。該pipeline由三個獨立的部分組成,可以與任何LiDAR語義分割模型相結合。論文代碼采用Cylinder3D模型,在只使用8%標注的情況下,可達到95.7%的全監督性能。

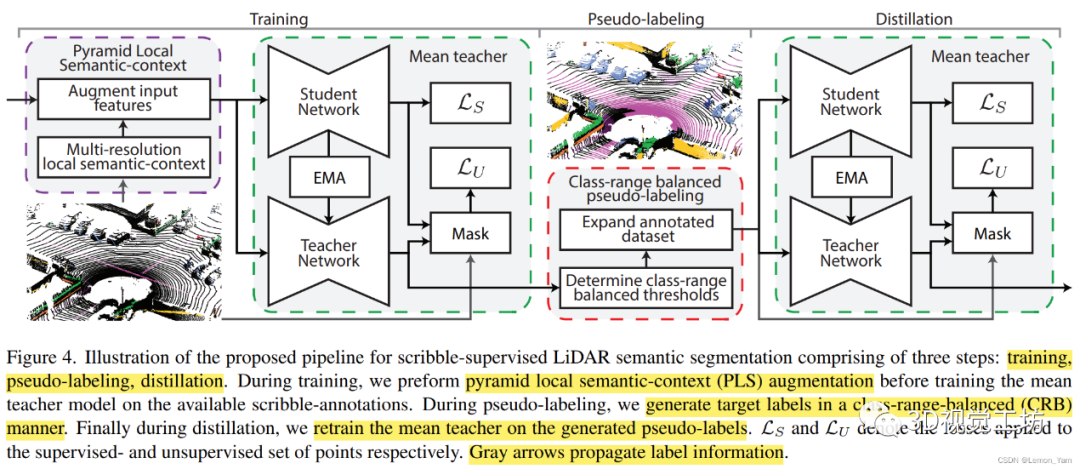
論文提出的pipeline可分為訓練、偽標簽和蒸餾這三個階段:在訓練期間,首先通過PLS來對數據進行增強,再訓練mean teacher,這有利于后面生成更高質量的偽標簽。在偽標簽階段,通過CRB來產生目標標簽,降低由于點云自身屬性降低生成偽標簽的質量。在蒸餾階段,通過前面生成的偽標簽再對mean teacher進行訓練。
3. 雷達點云表征
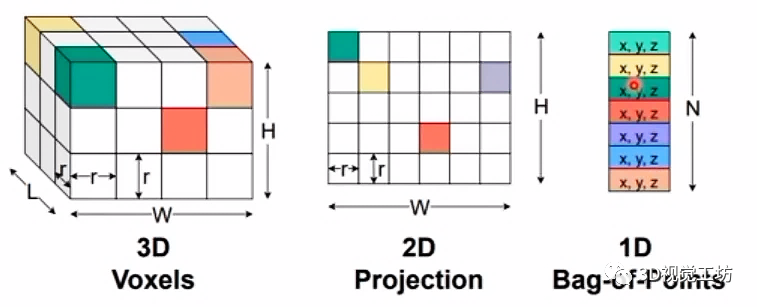
深度學習模型都需要一個規范化的數據表征,才能進行合理的特征提取和融合。對于圖像來說,是一個非常規整的2D表征,即每個像素位置都是固定的,這有利于模型訓練和測試。但對于3D點云來說,每幀點云有十幾萬個點,雜亂無章的點云必然不利于模型訓練。因此需要對雷達點云進行合理表征。
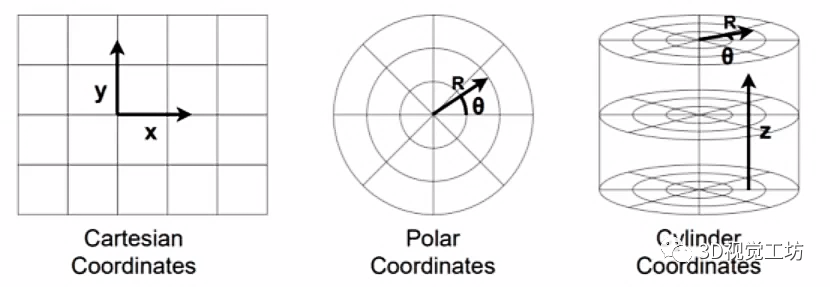
雷達點云主要的表征模式有四種:
(1) 2D Range View表征
非常接近圖像,將點云投影到平面,直接進行2D表征,得到x、y坐標。有時投影過程中還會考慮點云強度、深度以及每個方格是否有點云。網絡輸入也就是2D Range View,首先提取特征,然后進行特征融合,最后根據不同的分割頭進行語義訓練。
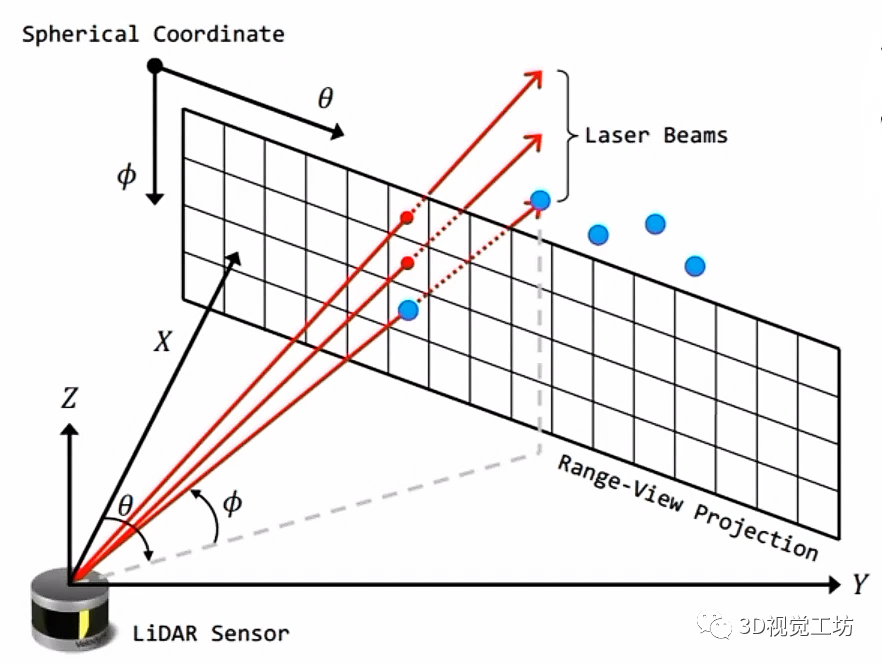
(2) 2D BEV表征
對于很多自動駕駛場景,往往是x和y坐標范圍有幾十米上百米,但z方向的坐標只有幾米。因此有些表征就直接省略掉z方向的表達,通過俯視圖得到極坐標表征。
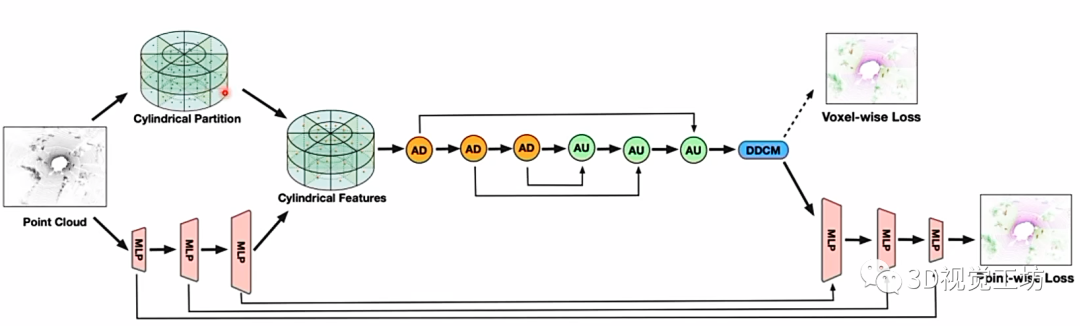
(3) 3D Cylinder Voxel表征
在點云z方向進行Cylinder的劃分,是一種3D描述,典型代表就是Cylinder3D。注意為什么要用Cylinder來表征而不是其他正方體呢?這是因為點云分布的密度是不一樣的,在自車周圍的點云密度很大,在周圍的點云密度很小。通過這種不規則的劃分就更有利于特征提取。
(4) 混合表征
顯然每種表征方法都有各自的特點和優劣,那么有些文章就將不同的表征模式進行混合,進而得到更強的表征。具體執行過程中會先通過不同的支路單獨進行特征提取,之后進行特征融合并輸出頭。
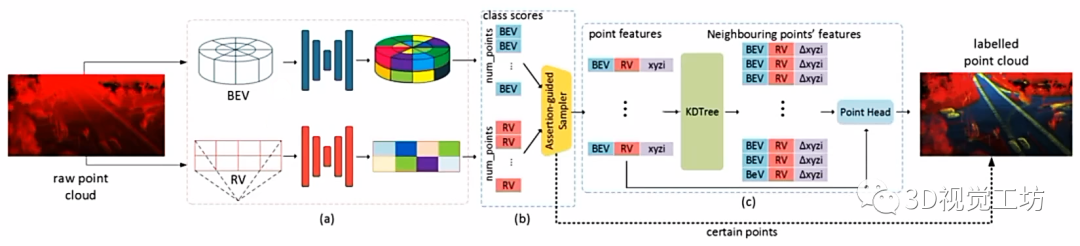
而針對不同的表征,也有不同的操作。對于3D表征來說,主要是Conv3d和SparseConv,對于2D表征來說,主要是Conv2d和線性Linear。對于直接將點作為輸入的一維表征,使用Conv1d和線性Linear。
4. 全監督算法
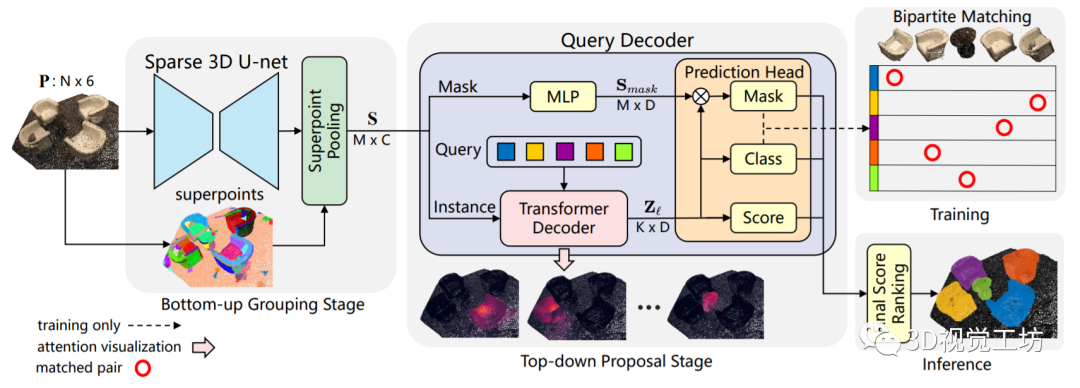
華南理工大學今年11月在arXiv上傳了論文“Superpoint Transformer for 3D Scene Instance Segmentation”,基于Transformer構建了一個新的點云分割框架,名為SPFormer。具體來說,作者提出一種基于Superpoint Transformer的新型端到端三維實例分割方法,它將點云中的隱特征分組為超點,并通過查詢向量直接預測實例,而不依賴目標檢測或語義分割的結果。
SPFormer其實針對的不是自動駕駛場景,它主要是在ScanNet和S3DIS這兩個室內數據集上進行訓練和評估。感覺最近很少有自動駕駛場景的全監督算法了,主要還是因為對數據量和標注要求太大。
這個框架的關鍵步驟是一個帶有Transformer的新型查詢解碼器,它可以通過超點交叉關注機制捕捉實例信息并生成實例的超點掩碼。通過基于超點掩碼的雙點匹配,SPFormer可以實現網絡訓練,而不需要中間的聚合步驟,這就加速了網絡的發展。
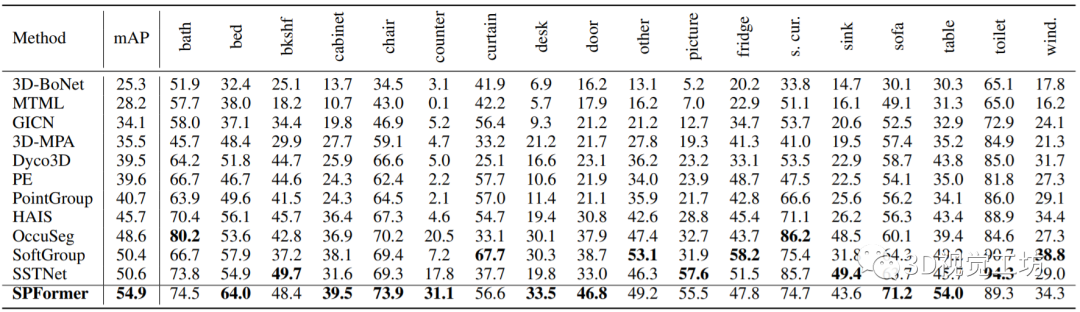
SPFormer的結果也很漂亮,在ScanNetv2 hidden上的mAP達到了54.9%,比之前最好的結果高出4.3%。對于具體的18個類別,SPFormer在其中的8個類別上取得了最高的AP得分。特別是在counter類別中,SPFormer超過了之前最好的AP分數10%以上。
總結一下,全監督算法的精度應該是最高的,因為接受了完全的標簽訓練,但是對數據量和標注的要求越來越大。
5. 弱監督算法
感覺ScribbleKITTI中提出的弱監督Pipeline非常妙了,可以與任何LiDAR語義分割模型相結合,這里再回顧一下。
這里再介紹一個基于雷達引導的圖像弱監督分割算法,感覺很有意思:
是由北京理工大學和上海AI Lab聯合提出的LWSIS,今年12月7日上傳到arXiv,錄用到了2023 AAAI,可以說非常新!論文題目是“LWSIS: LiDAR-guidedWeakly Supervised Instance Segmentation for Autonomous Driving”。
LWSIS利用現有的點云和3D框,作為訓練2D圖像實例分割模型的自然弱監督。LWSIS不僅在訓練過程中利用了多模態數據中的互補信息,而且顯著降低了稠密二維掩膜的標注成本。具體來說,LWSIS包括兩個關鍵模塊:點標簽分配(PLA)和基于圖的一致性正則化(GCR)。前者旨在將三維點云自動分配為二維逐點標簽,而后者通過增強多模態數據的幾何和外觀一致性來進一步優化預測。此外,作者對nuScenes進行了二次實例分割標注,命名為nuInsSeg,以鼓勵多模態感知任務的進一步研究。
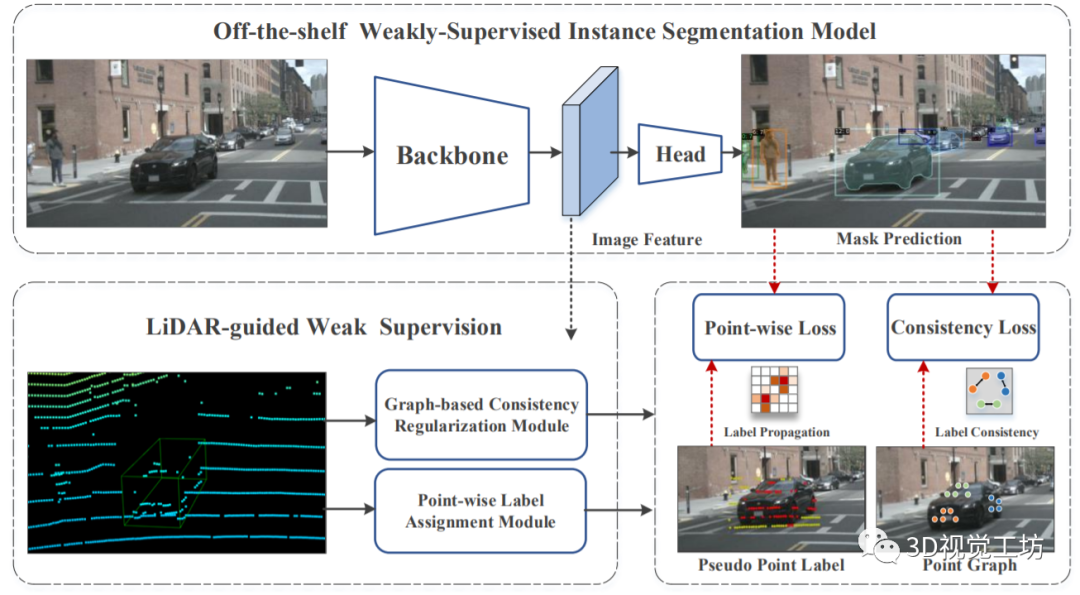
在nuInsSeg和大規模Waymo上的大量實驗表明,LWSIS在訓練過程中只涉及三維數據,可以顯著改進現有的弱監督分割模型。此外,LWSIS還可以與Point Painting等3D目標檢測器結合,提升3D檢測性能。

總結一下,感覺弱監督算法是現在的一個主流發展趨勢。也就是說,放棄標注復雜的目標,轉而去用一些容易得到的表情來引導訓練。感覺這種思想非常巧妙!當然用來引導的標簽不一定要是涂鴉或者點云,也可以是其他形式,讀者可以由此設計自己的弱監督分割網絡。
6. 無監督算法
點云分割算法是否可以完全不依賴標簽?
這似乎是個很難回答的問題,沒有標簽,也就完全無法知道物體的類別先驗,就更加無法進行訓練。
但香港理工大學的2022 NeurIPS論文“OGC: Unsupervised 3D Object Segmentation from Rigid Dynamics of Point Clouds”似乎回答了這個問題。作者的思路也很巧妙:一輛汽車上的所有點一起向前運動,而場景中其他的點則保持靜止。那么理論上,我們可以基于每個點的運動,將場景中屬于汽車的點和其他點分割開,實現右圖中的效果。
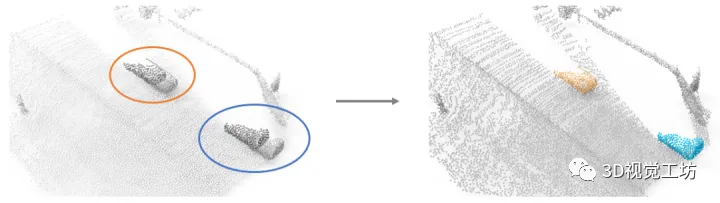
OGC是一種通用的、能分割多個物體的無監督3D物體分割方法,這種方法在完全無標注的點云序列上進行訓練,從運動信息中學習3D物體分割。經過訓練后,能夠直接在單幀點云上進行物體分割。OGC框架的核心是:以物體在運動中保持幾何形狀一致作為約束條件,設計一組損失函數,能夠有效地利用運動信息為物體分割提供監督信號。
OGC以單點云作為輸入,并直接在一次向前傳遞中估計多個對象遮罩。OGC利用連續點云的潛在動態作為監督信號。具體架構由三個主要組件組成: (1)目標分割網絡提取每一點的特征,并從單一點云估計所有對象掩模如橙色塊所示;(2)輔助自監督網絡來估計來自一對點云的每點運動矢量;3)一系列損失函數充分利用運動動態來監控目標分割骨干。對于前兩個組件,實際上可以靈活地采用現有的提取器和自監督運動估計器。


總結一下,無監督算法現在應該還比較少。OGC是利用了運動約束,可以很巧妙得訓練點云分割網絡。但是靜止的物體呢?比如樹木、交通燈、建筑。未來應該還會有很多大神提出更多巧妙的思路,讓我們拭目以待。
7. 半監督算法
全監督和弱監督都要求對每幀點云都進行標注,只是弱監督標注的少,無監督不需要標注。那么半監督呢?這里半監督指的是,一部分的點云需要進行標注,另外一部分不需要任何標注。即,在充分利用到現有的已標注數據的基礎上,結合便于收集的大量無標注數據,訓練泛化能力優異的模型。
本文介紹的算法是新加坡國立大學今年6月提出的LaserMix for Semi-Supervised LiDAR Semantic Segmentation。
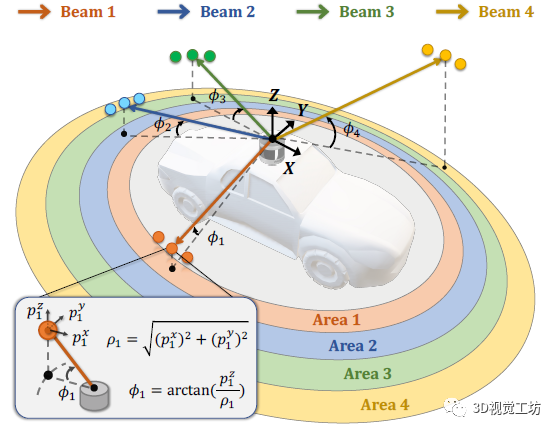
這項工作的思路非常巧妙!作者發現,無論是靜態背景還是動態前景對象,都在LiDAR點云場景中表現出很強的結構先驗,而這種先驗可以很好地由LiDAR的激光束所表征。以最常見的旋轉型LiDAR傳感器為例,其以自車為中心向周圍各向同性地發射具有固定傾角的激光射線,由于不同類別本身具有特殊的分布,由激光射線探測并返回的點便能夠較為精準地捕捉到這些不同類別所蘊藏的結構化信息。
例如,road類在靠近自車周圍的區域中大量分布,主要由位于下部的射線所收集;vegetation類分布在遠離自車的區域,主要由位于上部的具有較大正向傾角(inclination)的射線所收集;而car類主要分布在LiDAR點云場景的中部區域,主要由中間的射線所收集。
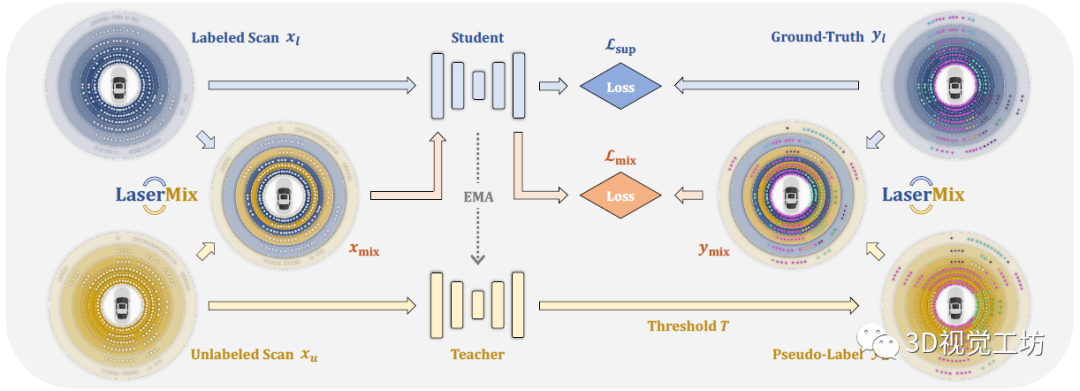
LaserMix管道有兩個分支,一個有標注的學生分支和沒有標注的教師分支。在訓練過程中,一個batch由一半有標簽數據和一半無標簽數據組成。LaserMix收集來自學生和教師的預測,并使用預定義的置信度閾值從教師網絡的預測中生成偽標簽。對于有標記數據,LaserMix計算學生網絡的預測和真實值之間的交叉熵損失。對于無標簽數據,LaserMix將每次掃描與隨機標記掃描混合在一起,加上偽標記或真值。然后,令學生對混合數據進行預測,計算交叉熵損失。
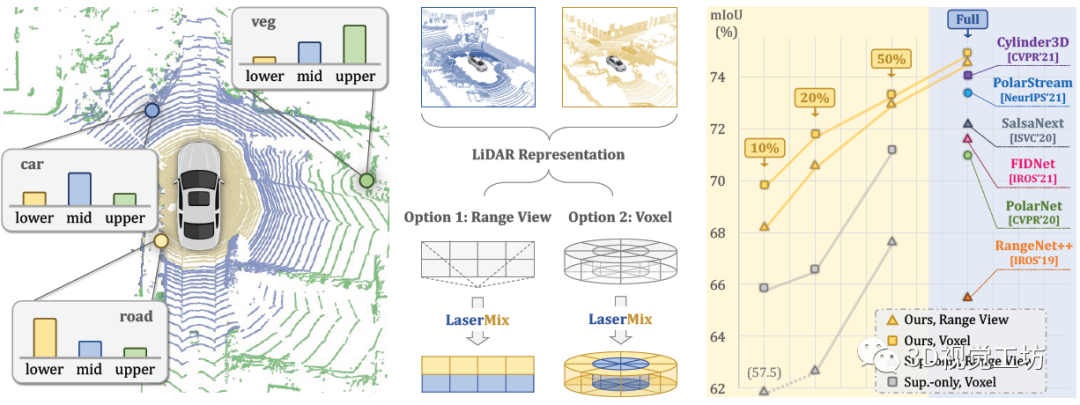
LaserMix在Range View和Voxel這兩種點云表征上都進行了驗證,體現出該方法的普適性和適配性。此外,作者將nuScenes、SemanticKITTI、ScribbleKITTI三個數據集按照1%,10%,20%和50%的有標注數據比例進行了劃分,并認為其余數據均為未標注數據。結果顯示,LaserMix極大地提升了半監督條件下的LiDAR分割結果。無論是在不同的數據集還是不同的LiDAR點云表征下,LaserMix的分割結果都明顯地超過了Sup.-only和SOTA的半監督學習方法。其中Sup.-only代表僅使用有標注數據進行訓練后的結果,可以理解為該任務的下界(lower bound)。
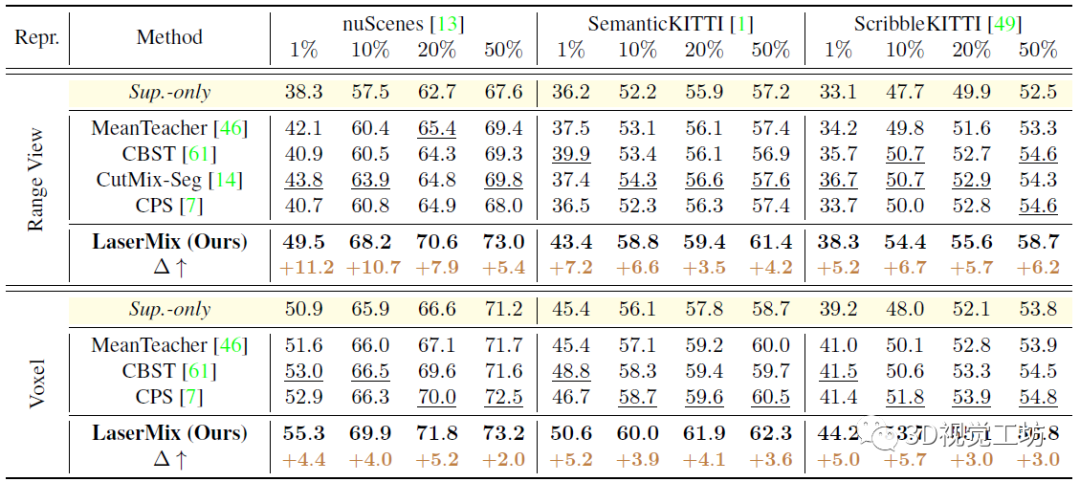
總結一下,半監督算法其實同時結合了弱監督和監督的優點。弱監督雖然標注的簡單了,但本質上還是需要對每幀數據都進行標注,這個工程量也非常大。但是半監督居然可以在僅有1%標簽數據的情況下進行訓練,訓練效果還超過了很多同類型的算法,所以我感覺半監督在未來也會成為主流發展趨勢,
8. 結論
本文首先介紹了點云分割相較于圖像分割的優勢,然后闡述了一些點云分割必備的基礎知識,最后分別探討了全監督、弱監督、無監督、半監督點云分割算法的網絡架構和基本原理。其中,全監督算法精度最高,但要求的數據量和標簽也很大。無監督往往是依靠環境中的某種特殊假設進行訓練,在特殊場景下會非常高效。弱監督和半監督在很少的數據標注條件下,達到了和全監督幾乎相當的精度。筆者認為,在未來,弱監督和半監督是點云分割領域的重要發展趨勢。
審核編輯 :李倩
-
圖像
+關注
關注
2文章
1089瀏覽量
40572 -
數據集
+關注
關注
4文章
1209瀏覽量
24833 -
點云
+關注
關注
0文章
58瀏覽量
3820
原文標題:點云分割訓練哪家強?監督,弱監督,無監督還是半監督?
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺談分割接地層的利弊
什么是三維點云分割
語義分割25種損失函數綜述和展望






 工商網監
工商網監
評論