 GPU加速成為共識,CAE和仿真模擬的未來將走向何方?
GPU加速成為共識,CAE和仿真模擬的未來將走向何方?
CAE(Computer Aided Engineering,計算機輔助工程)始于50年代,由數學家、科學家和工程師共同開發,可用于求解分析復雜工程和產品。起先,CAE旨在改善航空和汽車行業的設計,例如,模擬飛機周遭的沖擊波、氣流、溫度數據,計算汽車模型表面的壓力系數等。
隨著半導體工藝對摩爾定律的進一步推動、內存的每一次進步以及CPU和GPU并行處理能力的倍增,CAE性能隨之擴展,其應用范圍也逐漸延展至制造業的方方面面,并有勢頭成為 “數字孿生”、“工業互聯網”、“智能制造”,乃至“工業元宇宙”的引擎。
1/CAE轉型:從CPU走向GPU,這頭巨獸已邁出兩個十年
作為一種資源密集型技術,即便歷經大半個世紀的發展,CAE領域仍然充滿挑戰,始終向新技術與新解決方案敞開大門。
·精益求精的工程師們提出需求:更真實!更復雜!更大規模!
Altair、Ansys、Autodesk、Dassault Systèmes (Simulia)、Hexagon MSC和Siemens等主要工程仿真軟件提供商長期依賴將CPU作為驅動計算的主要引擎時開發出的技術。最初,模型已經過簡化,可適應計算系統,但制造業對仿真度有著孜孜不倦的追求。
然而,如若以基于CPU的工作流程來處理這些問題,則必須考慮到CPU的功能——必須縮小模型的大小、簡化設計并管理網格大小,因此,最終評估的實體可能與要分析的真實事物大相徑庭。顯然,這又將我們帶回了原點。1999年,NVIDIA發明了GPU (圖形處理器),這為CAE實現重大轉型創造了舞臺。就像許多受益于并行處理的領域一樣,CAE的主要任務是執行大規模并行進程。CAE通過在模型上創建節點網格來評估模型,然后對節點應用力和條件,評估設計是否適合其用途。網格越密集,仿真就越可靠。對于GPU來說,這是一個顯而易見的應用領域,軟件供應商和硬件開發者在GPU出現的初期就已經認識到了這一點。
·半導體巨頭推動GPU加速的普及
GPU的優勢在于單個芯片上的處理單元數量遠超CPU,從處理器的角度上來比較,GPU的成本遠低于CPU,但GPU和CPU的工作方式各不相同,需要針對兩者采用特定的編程方法,因而,為GPU調整這些程序卻并非易事。 這時,GPU的發明者NVIDIA做出表率,于2006年發布NVIDIA CUDA (Compute Unified Device Architecture)——一種并行計算平臺和編程模型,并于2008年之后,與業內領先的公司合作推進OpenCL (Open Computing Language,開放設計語言)——專為異構平臺(CPU/GPU/DSP/FPGA等)編程設計的框架。這些編程工具讓開發者能夠更輕松地利用GPU來大幅提升計算性能。
NVIDIA一直與CAE開發者合作,創建為仿真分析可視化常見任務量身打造的工具。公司獨樹一幟,專注于GPU,推動其進入專用工具開發領域。2023年,隨著NVIDIA的Grace CPU的推出,其將在GPU+CPU的道路上發展得更加深遠。
2/軟件生態向GPU算力靠攏
半導體發展趨勢、GPU在并行計算方面的獨特優勢,以及NVIDIA等GPU廠商為CAE搭建的開發工具,讓入局以GPU為基礎的CAE變得更加容易。
·CAE不斷迭代:提高自動化水平,注入AI
除了對更復雜、更逼真、更大規模的CAE應用的需求外,21世紀初,計算機輔助設計 (CAD) 軟件供應商也開始獲取CAE技術以添加到設計工作流。集成到CAD流程中的分析工具具有更高的自動化水平,這讓設計師能夠在工作時執行簡單分析。
要實現上述兩個愿景,需要構建插件和附加組件來實現GPU加速,并進一步添加云資源、推進高性能計算 (HPC) 的應用。同時,人們也越來越關注使用機器學習 (ML) 和人工智能 (AI) 來預處理和識別模型中值得關注的領域。
·軟件廠商爭先“吃螃蟹”
自2014年以來,各個主要CAE供應商都在某種程度上利用了GPU加速。
Ansys和Hexagon專門針對GPU設計并編寫了應用程序。
Ansys針對GPU從頭開始設計了應用Discovery,這一互動實時仿真解決方案允許在流體、熱力學、結構和模態應用中進行迭代設計探索。此后,PTC與Ansys在2018年的LiveWorx 18數字化轉型會議上宣布,PTC的Creo 3D CAD軟件中將實現Ansys Discovery Live實時模擬功能,這消除了CAD與模擬活動之間的界限。
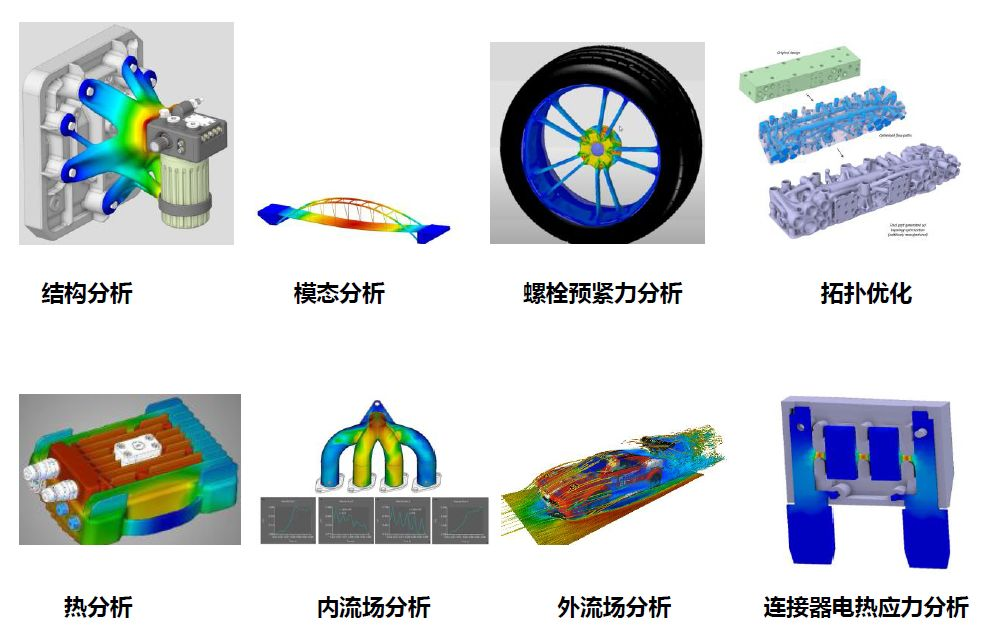
Ansys Discovery典型應用(圖片來源:Ansys)
同樣,Hexagon也決定從一開始就為GPU編寫其新產品MSC Apex Generative Design,NVIDIA的CUDA框架為Hexagon的開發者提供了一個輕松的切入點,他們能夠立即開始編碼,不僅能夠更快生成產品,而且將設計、網格化和分析功能融于一體。
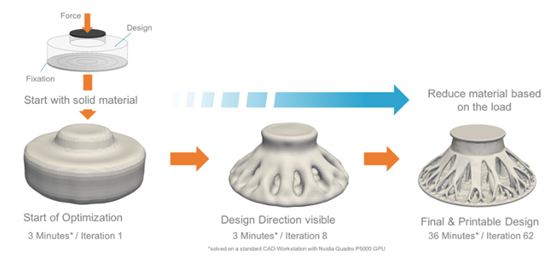
MSC Apex Generative Design的工作流程
西門子則是致力于讓其CFD軟件可以在CPU與GPU之間無縫切換。2022年初,西門子發布了首個GPU版本的Simcenter STAR-CCM+,這一版本在一開始專注于車輛外部空氣動力學應用,隨后,Siemens工程師投入巨資,移植所有可在未來數年從GPU中受益的物理、求解器和相關軟件部件。
達索系統(Dassault Systèmes)和Altair選擇將GPU加速逐漸應用于原有產品中。
達索發現,GPU的架構非常適合基于有限差時域仿真算法的CST Studio Suite電磁仿真和分析,且從工作站GPU到數據中心計算GPU的擴展效果非常出色。而Altair在實踐過程中得出,與用來處理類似工作負載的12個CPU相比,添加GPU可將AltairEDEM的性能提升20倍。

CST Studio Suite允許客戶訪問多種電磁仿真解算器

Altair EDEM的主要功能
迄今為止,已有來自10多個ISV的120多個CAE應用通過GPU進行加速。結果令人印象深刻,根據應用和工作負載不同,結果的交付速度最高可提升100倍。此外,隨著GPU的添加,性能提升會進一步飛躍。隨著越來越多的求解器移植到GPU上,可以預見性能會取得更大的突破。
·GPU自身的升級將為前期軟件投資帶來持續紅利
以NVIDIA為例,在今年9月的GTC大會上,其推出了基于全新Ada Lovelace架構的NVIDIA RTX 6000工作站GPU,具有最先進的NVIDIA RTX技術,特點包括:
1)第三代RT Core:吞吐量是上一代的2倍,能夠同時運行具有著色或去噪功能的光線追蹤技術。
2)第四代Tensor Core:相比上一代AI訓練性能提升近2倍,擴展支持FP8數據格式。
3)CUDA core:單精度浮點吞吐量最高達到上一代的2倍。
4)GPU顯存:具有48GB GDDR6顯存,可處理大規模的3D模型、圖像渲染、模擬和AI數據集。
5)虛擬化:將支持用于多個高性能虛擬工作站實例的NVIDIA虛擬GPU(vGPU)軟件,使遠程用戶能夠共享資源并驅動高端設計、AI和計算工作負載。
6)XR(擴展現實):視頻編碼性能相比上一代產品提升近3倍,可使用NVIDIA CloudXR流式傳輸實現多個XR會話同步。
NVIDIA RTX 6000 Ada架構GPU提供了實時渲染、圖形和AI功能,可以幫助設計師和工程師推動基于仿真的尖端工作流程,以構建和驗證更復雜的設計。
憑借更大的二級緩存、更多的新一代核心和更高的內存帶寬,Ansys Discovery和Ansys Fluent的用戶可以通過釋放NVIDIA RTX 6000的48GB GPU顯存的全部威力,進行互動式仿真驅動的設計研究和高保真CFD仿真。NVIDIA針對這一應用發布了演示視頻:
3/制造業利用GPU加速的CAE向工業元宇宙延伸
在CAE借助GPU過程中,沒有一家軟件公司采取相同的路線來實施GPU:他們都有自己的方法,對分析和仿真的作用有自己的理念,并有自身特別感興趣的領域。但我們確實看到,隨著GPU的出現,CAE及制造業產品設計流程正在迅速變化。
同時,在元宇宙概念席卷各行各業的背景下,GPU加速CAE的結果呈現方式將百花齊放。通過與XR相結合,設計師和審查人員可開啟沉浸式工作;采用虛擬GPU技術,將讓工作流程在不局限于本地算力的同時,保障數據安全性;將其置于協作平臺(例如NVIDIA Omniverse)中,則能打通制造業產品設計鏈路,大幅縮短正式投產前的準備時間。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4777瀏覽量
129360 -
仿真
+關注
關注
50文章
4124瀏覽量
133999
原文標題:GPU加速成為共識,CAE和仿真模擬的未來將走向何方?
文章出處:【微信號:baixiu01,微信公眾號:制造界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
借助NVIDIA GPU提升魯班系統CAE軟件計算效率
GPU加速云服務器怎么用的
《CST Studio Suite 2024 GPU加速計算指南》
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
LIBS激光誘導擊穿光譜:未來將走向何方?
智能網聯汽車仿真測試標準體系研究






 工商網監
工商網監
評論