 FreeSWITCH高可用部署與云原生集群部署知識分享
FreeSWITCH高可用部署與云原生集群部署知識分享
大家好,我本次分享的主題是FreeSWITCH高可用部署與云原生集群部署,主要是談一談從高可用到彈性伸縮的一些技術應用。
具體包含以下相關內容:雙機、三機,到可彈性伸縮的通信集群建設經驗,包含?對?通話、呼叫中?及?視頻會議、?志監控等場景,涉及FreeSWITCH、Kamailio、WebRTC、MCU、SFU、Docker、K8S、ETCD、NATS、Loki等相關技術。
主要會介紹我們用到的一些技術,希望能對大家有所幫助。上面提到的一些技術其實也不算是新技術,通信技術已經歷幾十年發展,早在二三十年前大家就已經在研究高可用相關技術。不過因為新時代的發展,最近大家開始關注云原生等相關技術,相應基礎設施產生一些變化,通信與互聯網的聯系也越來越緊密,由此產生了更多新的玩法。
01 單點故障
其實,一切的起源都是來自“單點故障”這個問題,我們就由此展開來進行介紹。
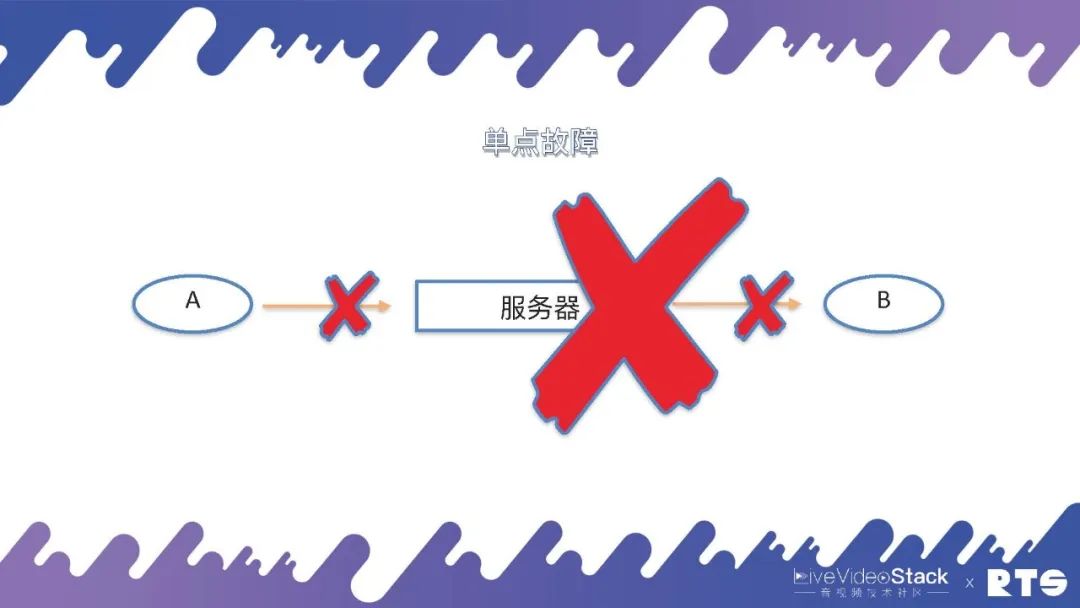
A和B兩個通信的實體,兩個電話(人)通過一臺服務器進行通信,當然這個服務器可以是FreeSWITCH,也可以是任何其它服務器。假設這臺服務器由于通信鏈路中斷或者是網絡連接中斷,A和B則無法完成通信,這就是單點故障的起源。
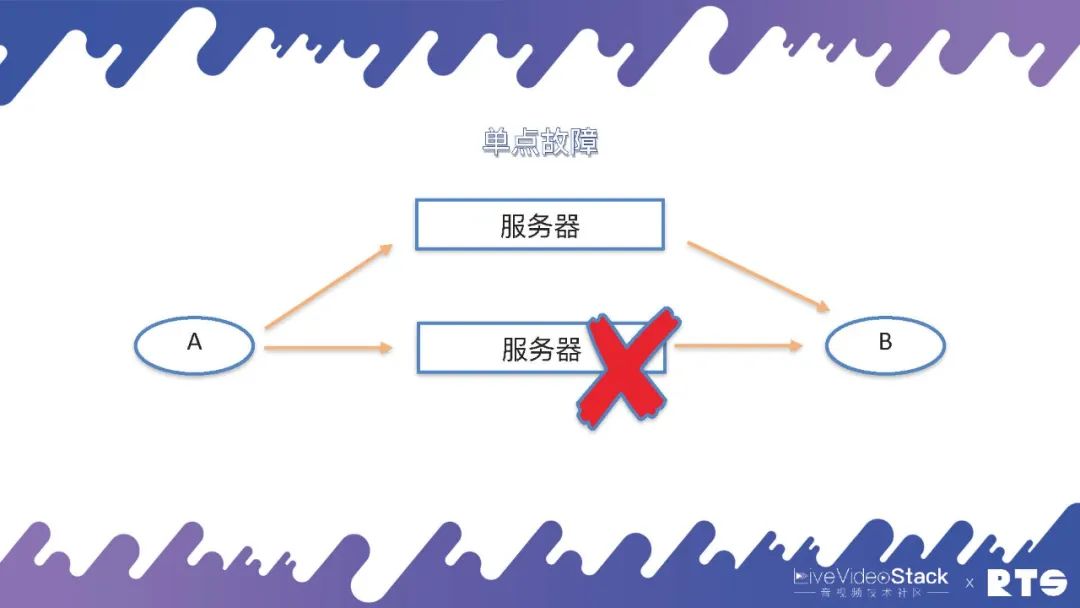
那要想解決這個單點故障,就需要另外的服務器通過迂回路由或是其它辦法來克服單點故障的問題。
02雙機HA
一般來說,克服這個單點故障的方法就是雙機HA(High Availability),即主備高可用。
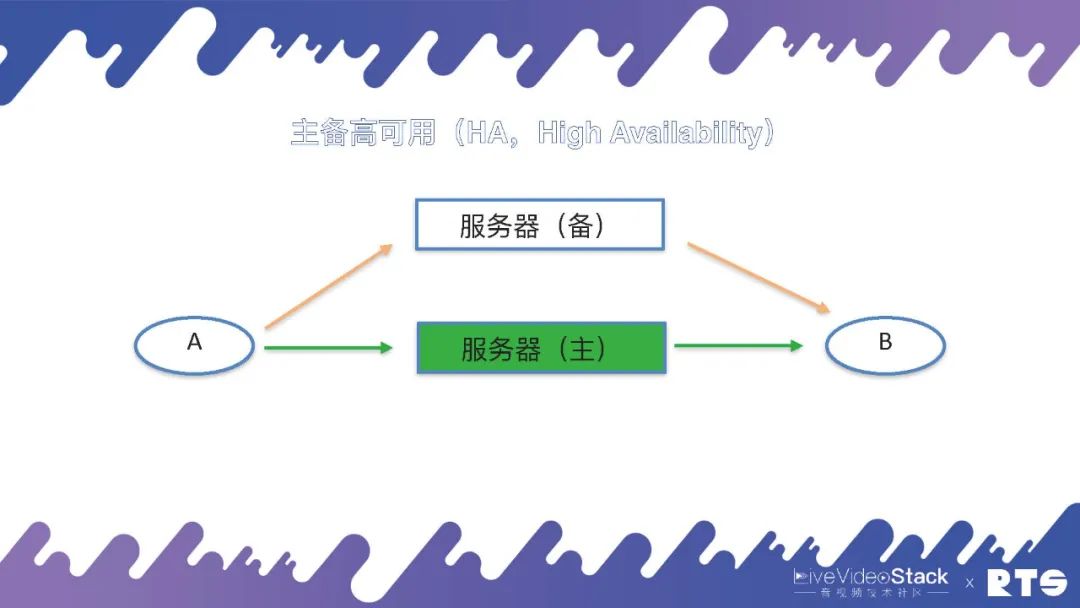
雙機HA的主要原理是:有一臺主機和一臺備機,假如主機出現問題斷連,備機可以接替成為主機繼續進行工作,如此不斷進行主備交換。主機與備機為同一IP地址,對于A和B來說可能感知的到或者根本感知不到主備機所進行的切換,因為通訊時A和B看到的僅僅只是IP地址,當任何一臺服務器切換到主機時,它就占有了對外服務的IP地址,這個IP地址我們就叫做虛擬的IP,也叫業務IP或浮動IP。本身每臺服務器底層還有一個IP,但對外提供服務的IP(即A和B看到的IP)其實是虛擬IP。
這樣當服務器發生切換的時候,A和B仍然是和原來的IP進行通話,他們可能會感覺到網絡的短暫卡頓,然后恢復正常,而感知不到服務器是否有進行切換,這就是主備高可用的原理。
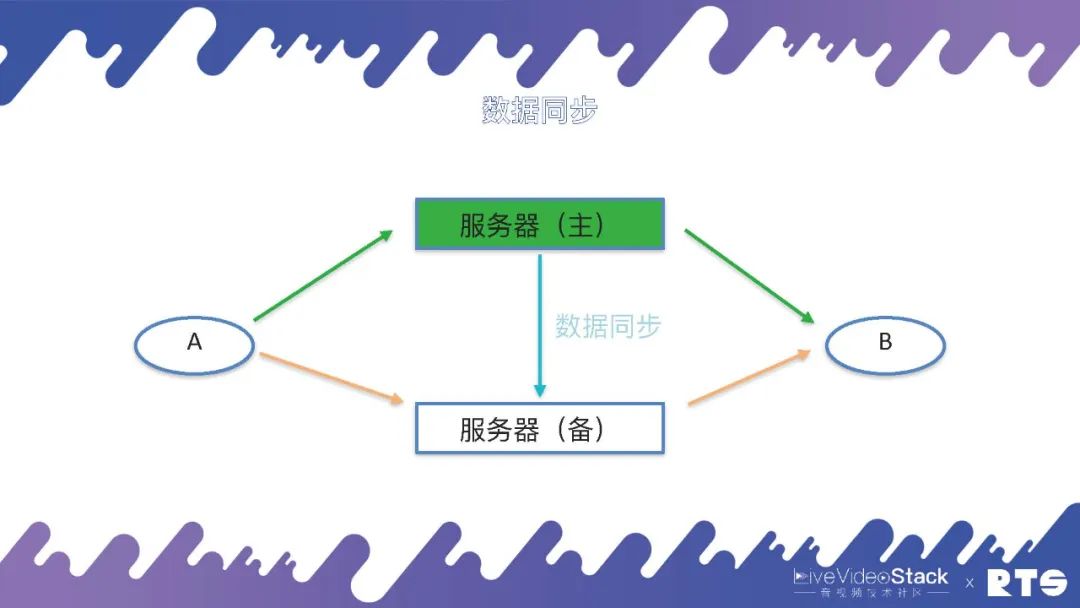
為了實現主備高可用,由于主服務器和備服務器之間有一些數據需要同步,所以就需要一種數據同步機制。
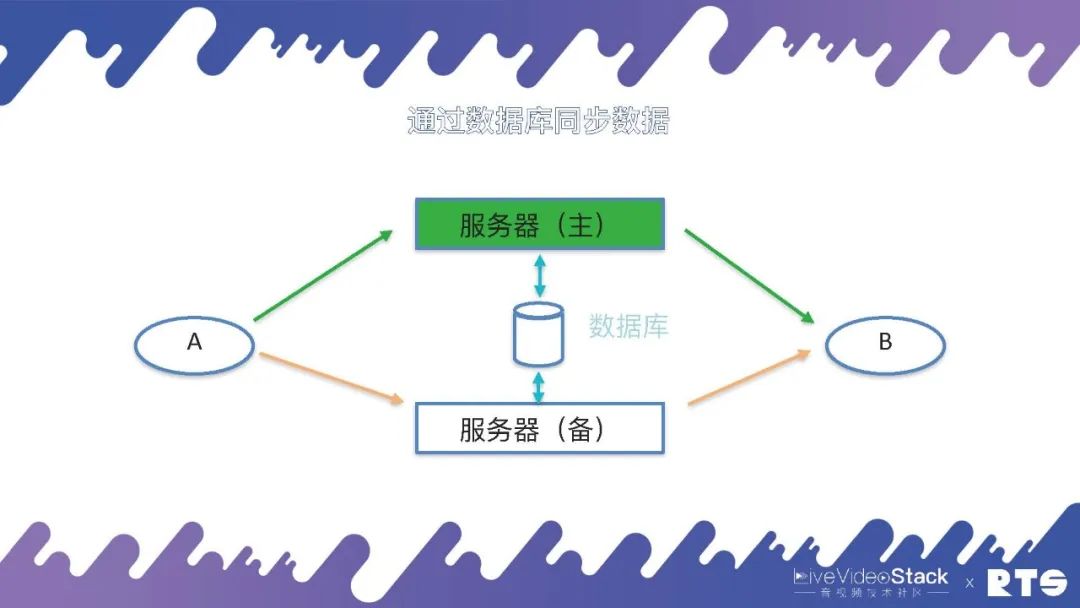
當然這個數據同步的機制有很多種,例如通過日志、消息隊列等等,在FreeSWITCH中主要是通過數據庫來同步這些數據。主服務器會實時將A和B(A和B可能有成千上萬個)通話的數據寫入到數據庫當中,備機可以在數據庫當中查詢數據,一旦發生主備切換,備機從數據庫當中取得數據,重新建立通話場景,A和B就可以繼續進行通話。
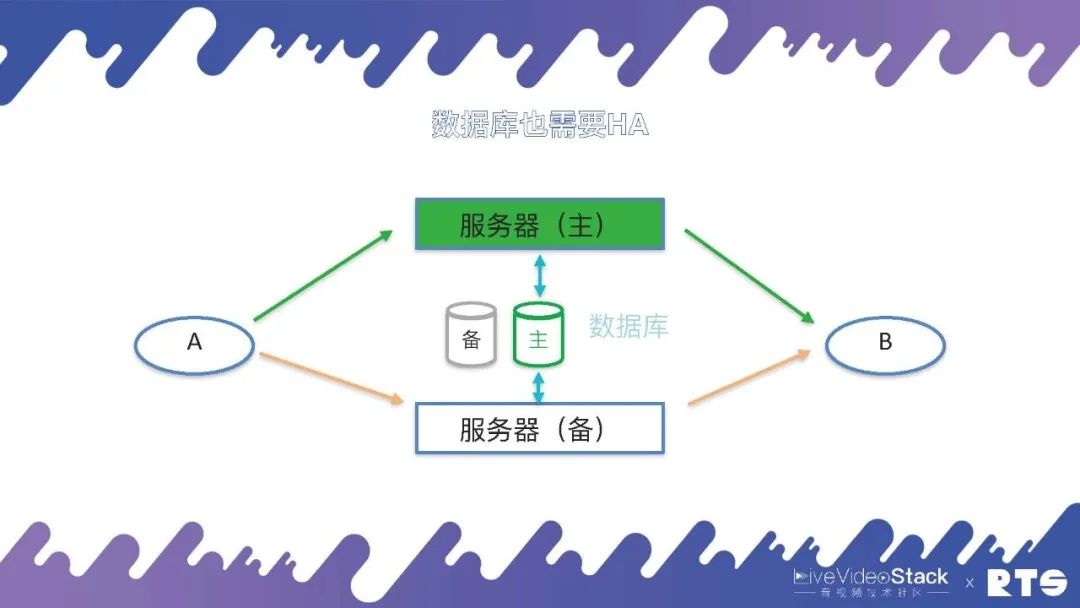
在這種情況下,數據庫也就成為了一個單點,為了解決這個問題,數據庫同樣需要主備高可用。
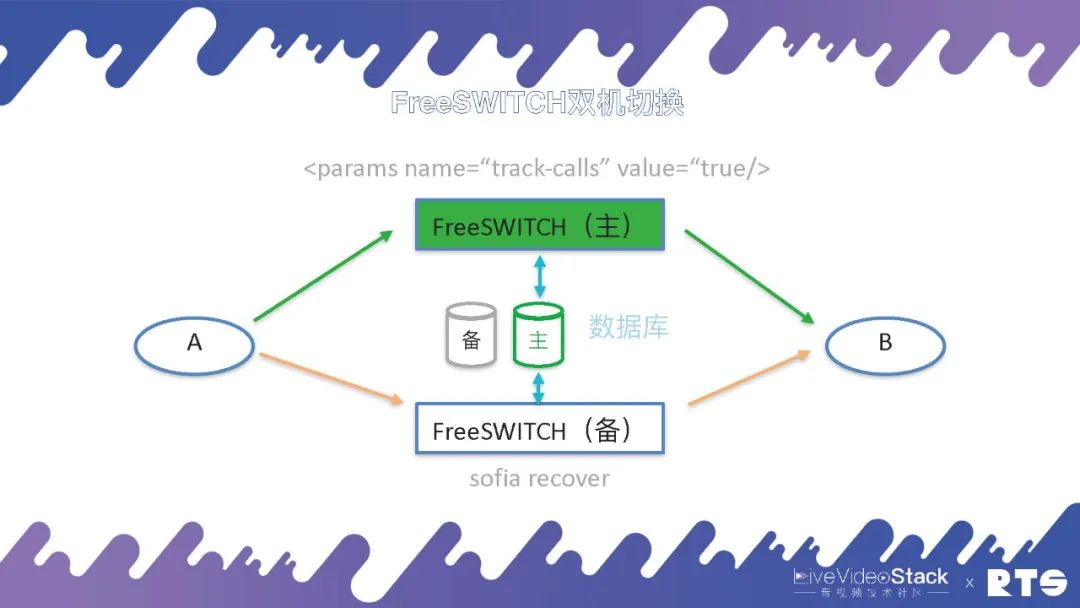
FreeSWITCH的主備切換原理:首先主機包含一個Param,參數為:
當備機發生切換的時候,備機會執行一個 sofia recover 命令,從數據庫中取得數據重建通話的場景,向A和B發送 reINVITE。前面我們說A和B感知不到,其實也能感知到,因為A和B收到了重新建連的邀請,繼續進行通話。一般這個通話過程大概在1-3秒內解決,A和B只是覺得會短暫的卡頓,不用掛斷重新呼叫。
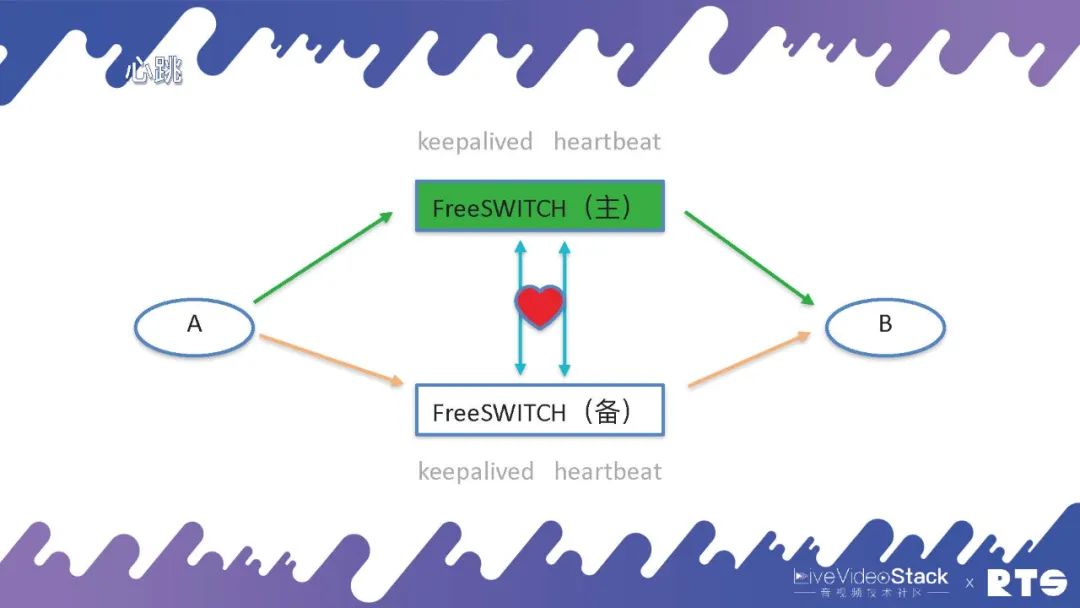
我們先排除數據庫的影響(默認數據庫是主備高可用的),來看FreeSWITCH的主備高可用。
為了能準確感知進行主服務器和備服務器之間的切換,需要有一個東西叫心跳(心跳線),一般心跳線在之前都是用串口線,因為心跳只是簡單的傳幾個字節的信息,對帶寬的要求不大。但現在在一些虛擬機中,不包含物理的串口,就只能用網線來實現。通過一個網線,不停的有心跳,備機可以借此感知主機的狀態,一旦產生主機崩潰、斷連,備機會接管IP。
當然這個情況下也可能會產生誤判,考慮到心跳線本身的斷開影響,我們可以通過兩根心跳線或雙網卡的方法避免出現這種誤判的情況。總之,我們需要更多的機制來保護系統,避免出現兩個服務器同時綁定同一個IP,同時寫入服務器導致服務器錯亂的情況產生。
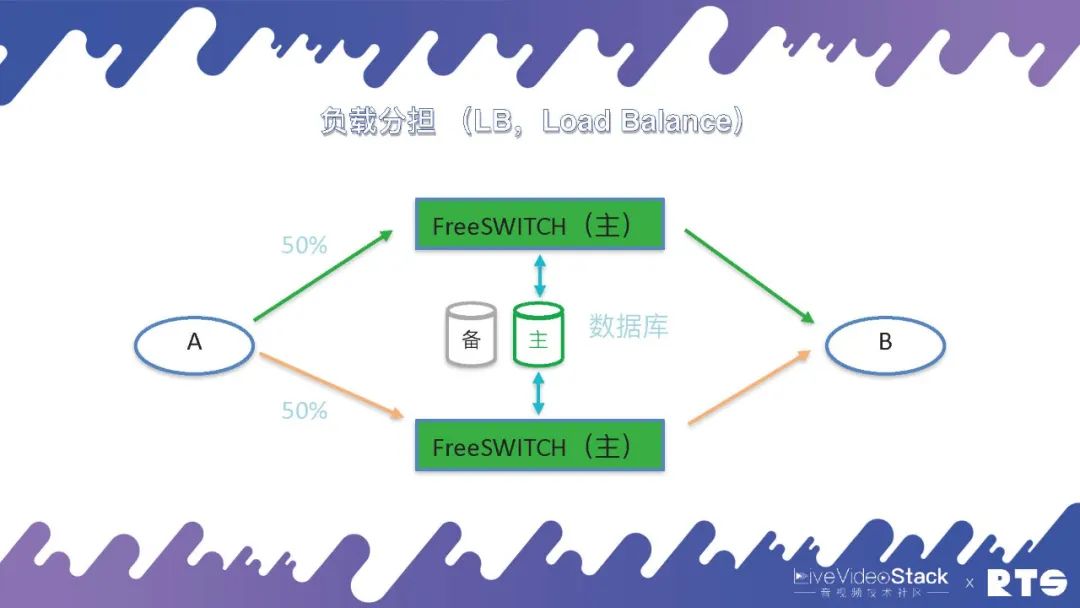
當然,這種情況下會有一些問題,兩臺機器作為一臺機器使用,可能會造成資源的浪費。還有一套方式是負載分擔(Load Balance),A和B之間有50%的話務分別放置于兩臺主機,兩臺主機可以同時達到滿負荷承載。但這種情況同樣存在一定問題,假設原本每臺可以承受一千路通話,兩臺配合總共可以承受兩千路通話,當其中一臺主機出現問題,另一臺在滿負載的情況下,實際上系統的吞吐量只能達到一千,就會發生擁塞發生問題。
所以說一般主備負載分擔的情況下,我們會保證兩臺FreeSWITCH主機每臺的話務量不要超過其設計容量的50%,這樣是比較安全的。當然,這樣算起來我們實際上還是有50%的浪費,我們也可以采取通信降級的策略,當一臺主機出現故障時,僅使用另外一臺主機,根據實際業務需求,保證部分通話連接的正常使用。
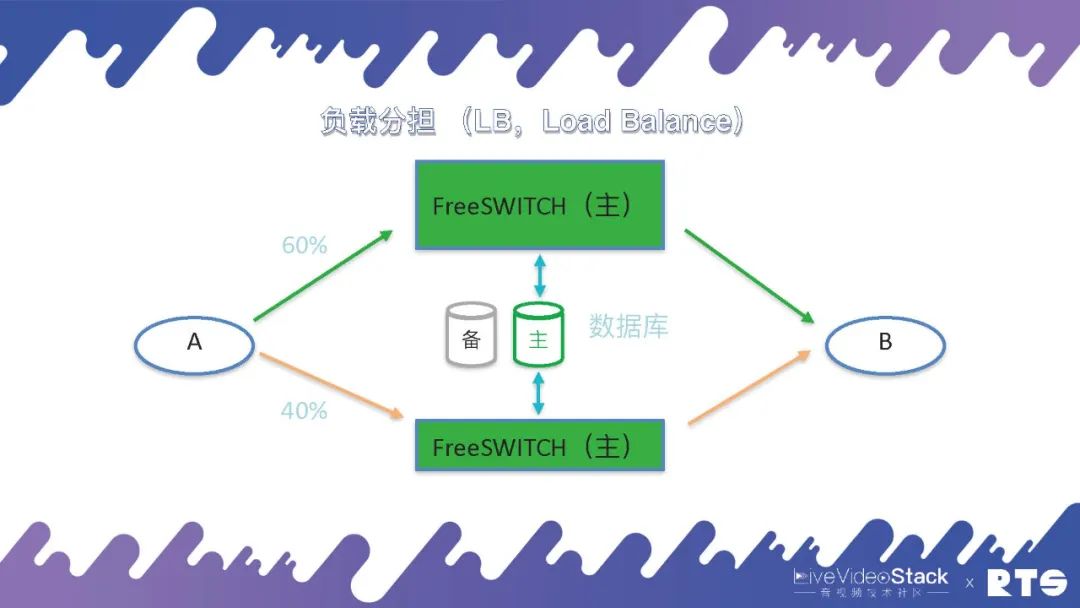
不過負載分擔對于A和B會有一定的要求,前面我們說到主備的方式,A和B都只能看到一臺服務器(實際上是兩臺服務器),是一個IP地址。但是在負載分擔的情況下,A和B都能看到兩臺機器,這就需要一定的邏輯(在A和B上做),需要能夠分發比如將50%的話務量分到一臺主機,剩余50%分到另外一臺主機。而且有時候兩臺主機的性能不一樣,可能一個是64核,另一個是32核,需要根據主機性能對話務量進行分配,比如一個60%,一個40%。這樣就會對A的要求比較高,需要能夠感知主機來進行負載的分發。
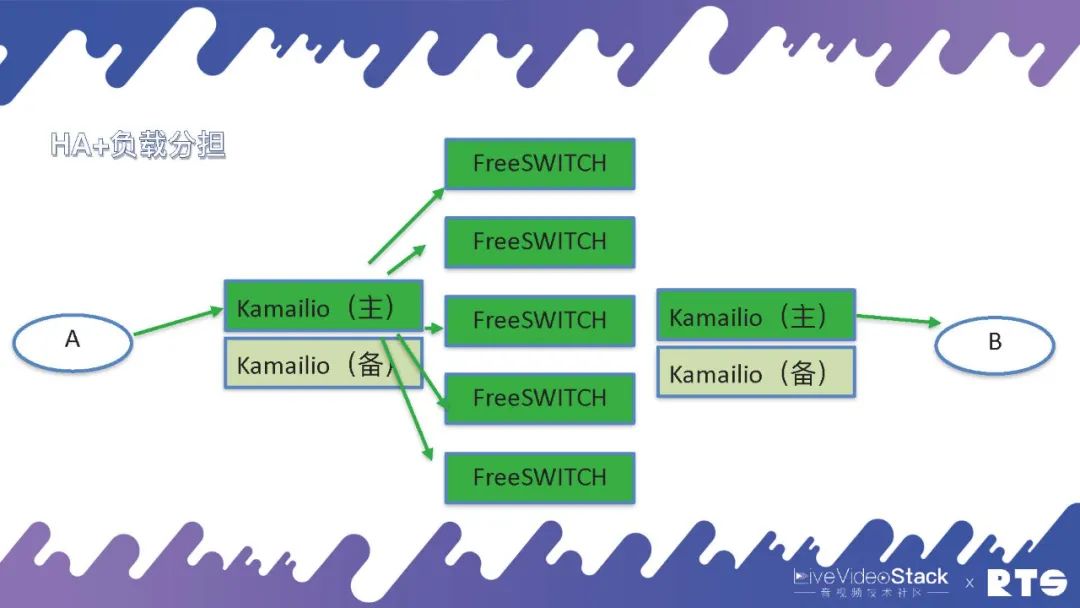
在實際的部署當中,我們一般都是采用這樣的結構(如圖所示)。FreeSWITCH作為媒體服務器,前面再放上代理服務器,一般是用Kamailio或者openSIPS做代理。Kamailio只代理SIP就是指處理通信的建立和分發,一臺Kamailio后端可以放很多的FreeSWITCH。因為FreeSWITCH要過媒體,要進行錄音、質檢、分析等等媒體的處理,所以FreeSWITCH的處理能力就不如Kamailio強。這樣前面放一個Kamailio,后端可以放很多FreeSWITCH進行通信。
當然Kamailio需要主備高可用,而Kamailio和FreeSWITCH之間是用Load Balance,這樣用HA+負載分擔的方式就完成了一種比較大的通信集群。而且由于A和B兩側的業務邏輯有可能會不一樣,比如說一側是中繼,一側是話務員是本次的系統電話,這時我們可以放兩個不同的Kamailio,管理起來會更方便一些。
當然我們也可以使用一個Kamailio,將A和B放在一側,但這樣的話腳本和邏輯的判斷上就會比較復雜。因為必須要判斷通話是由A還是B過來的,還是從FreeSWITCH過來的,需要判斷呼叫的方向,邏輯會相對比較復雜。
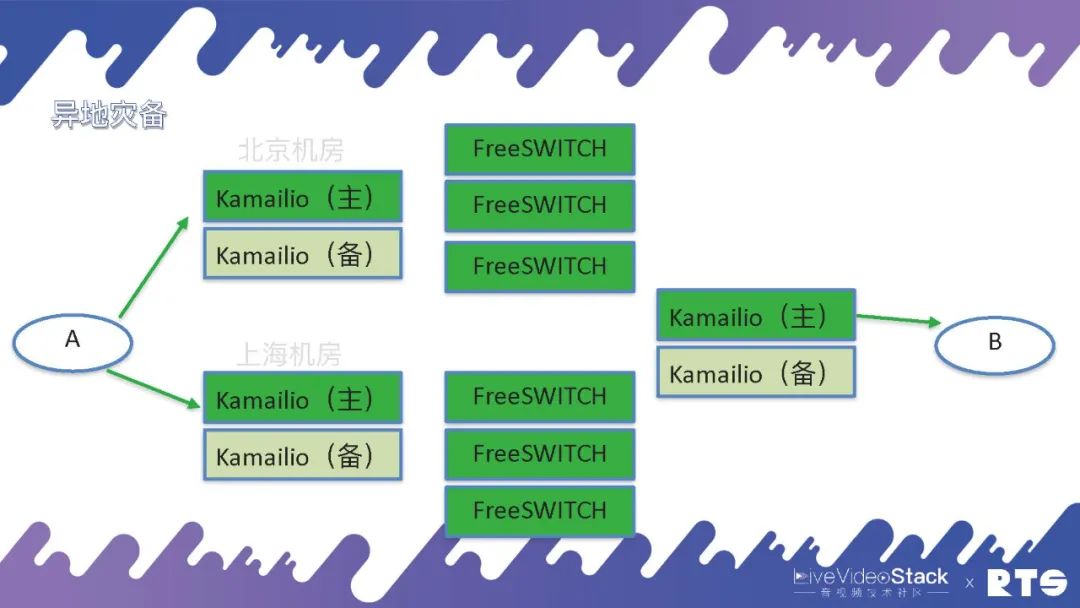
還有一種情況就是異地災備,什么是異地災備?舉個例子,我們可能有兩個機房分別在北京和上海,都用FreeSWITCH和主備高可用,這樣平常主要通過北京的機房,一旦出現問題可以通過迂回路由經由上海的機房進行通信。
但是異地災備同樣需要一些數據的同步,這就又對A提出了一定要求,因為A面對的是北京和上海兩個機房。所以說高可用是無窮無盡的,只要有需求只要改架構就需要相應的考慮,但萬變不離其宗,其實就是HA和負載均衡這兩種邏輯。當然具體地來說,A上可能靠DNS輪詢,也可以將北京或上海的地址直接寫進設備當中,自己執行策略根據情況來進行切換等等。
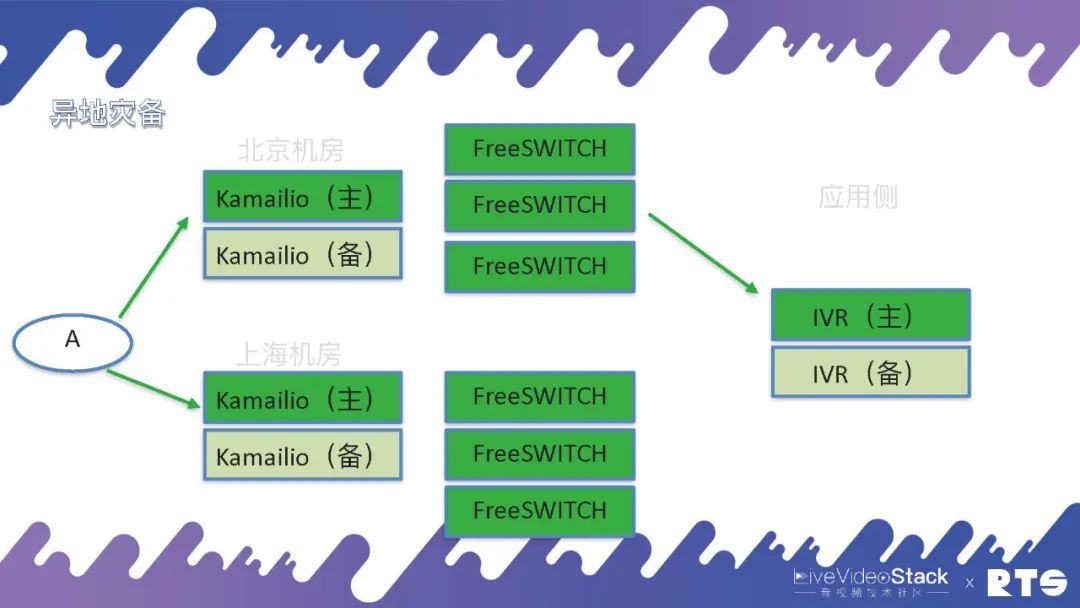
那么,我們來看B這一側。A和B進行通話,有可能會呼叫進來之后執行IVR有些應用,這些應用同樣需要主備高可用。比如有人打電話進來,Kamailio是負責信令的,FreeSWITCH負責媒體,但是具體的邏輯是由應用來負責的,需要由它來告訴FreeSWITCH應該什么時候處理媒體、什么時候錄音、放音等等,所以應用側同樣需要主備高可用。
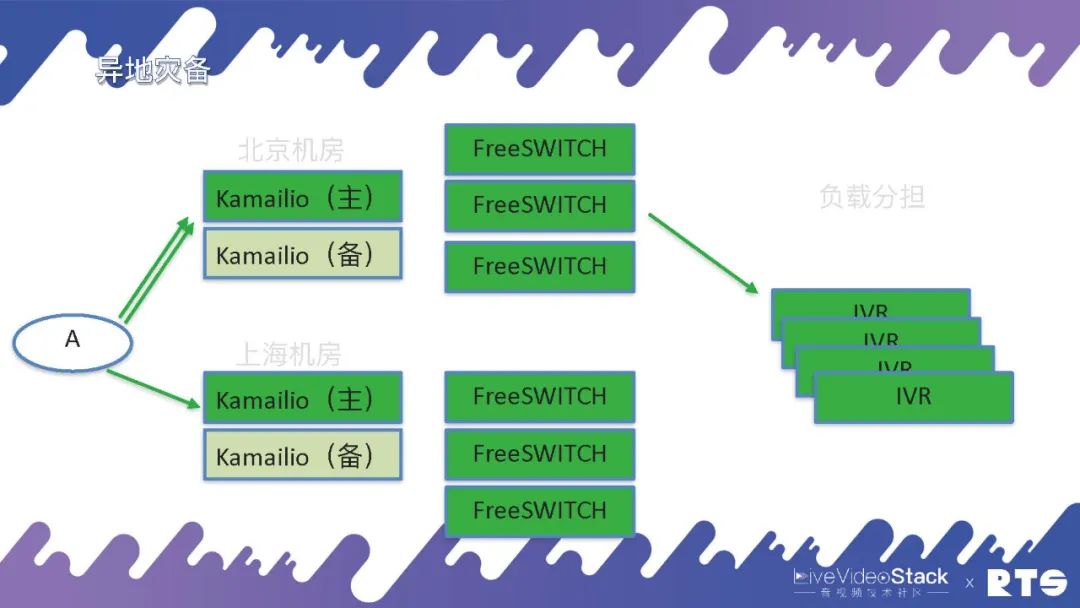
當然,一般的這種IVR我們認為它大體都是無狀態的,接入通話掛斷之后再接入一個新的通話同樣還是這個IVR,所以一般都會用負載分擔的方式,可以承擔多個IVR的業務。
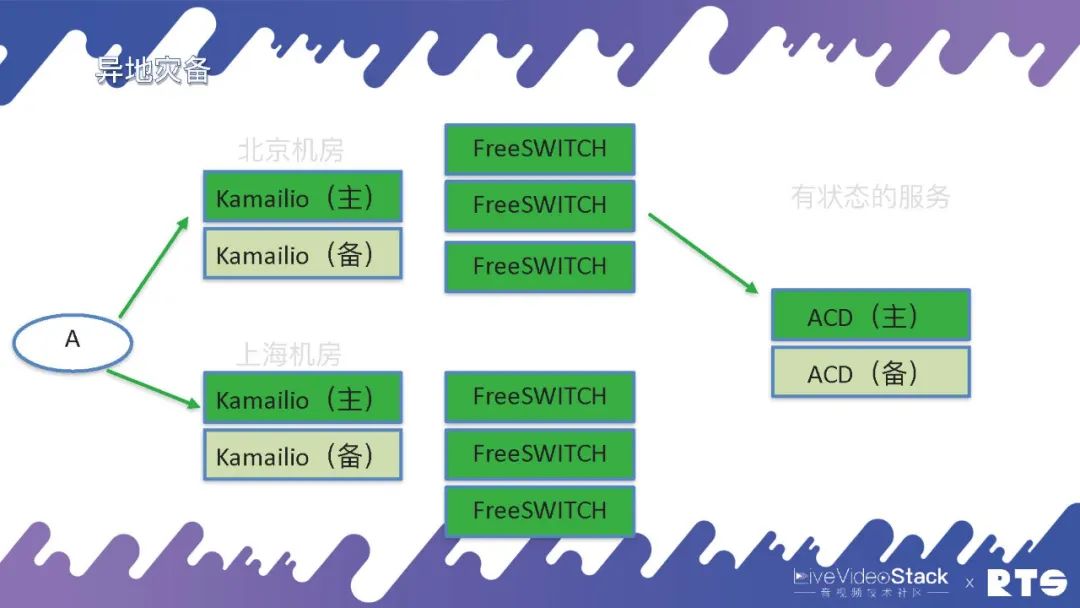
但是有一些服務它是有狀態的,比如說呼叫中心當中常用的ACD。ACD需要check坐席的狀態,以及隊列的狀態,有多少客戶在等待、有多少坐席在服務、哪個坐席正在跟客戶溝通、哪個坐席正處于空閑,它需要跟蹤這些狀態。一般來說對于這種有狀態的服務,還是要采用主備高可用的方式。當然,雙機HA同樣可能會出現兩臺機器同時發生問題的情況,這時候我們就擴展到 —— 三機。
03Raft
三臺機器的場景更為麻煩,由此我們引入了一個協議叫做Raft,還有一個叫做PaxOS,不過現在比較常用的還是Raft協議。

Raft其實是一個共識協議,它的主要作用是做Log。首先它是用一個分布式的系統,分布式系統主要是解決容錯的問題。那么怎么解決呢?就是同步日志。比如一臺機器上的日志,我要將這些日志副本同步到其它的服務器上去,當然我們說到的日志可能也是數據,數據庫數據或者通話的數據或者是狀態的數據等等。一般來說Raft都是奇數的,因為其遵循少數服從多數的原則,通過投票來進行選舉。
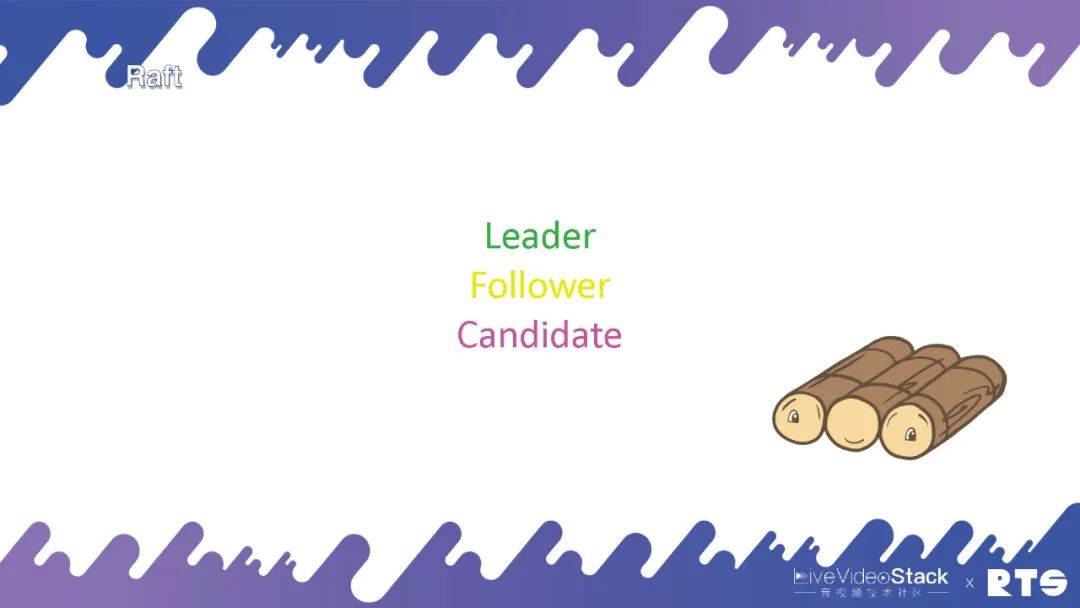
Raft中包含三個節點,Leader(領導)是一個主服務器,所有人會選舉選出一個Leader來,由Leader來決定什么時候修改數據。然后它會把這些數據同步給Follower(追隨者),所有的數據會從Leader上進行修改,之后會同步到Follower上。正常的情況下,集群內有Leader和Follower,數據就可以在服務器間進行同步。但又一種情況是作為Leader的主服務器掛掉了,其它所有的服務器就會變為Candidate(候選者),有機會被選舉成為新的Leader,通過這個機制可以保證有一臺服務器是可以保存這些數據的。
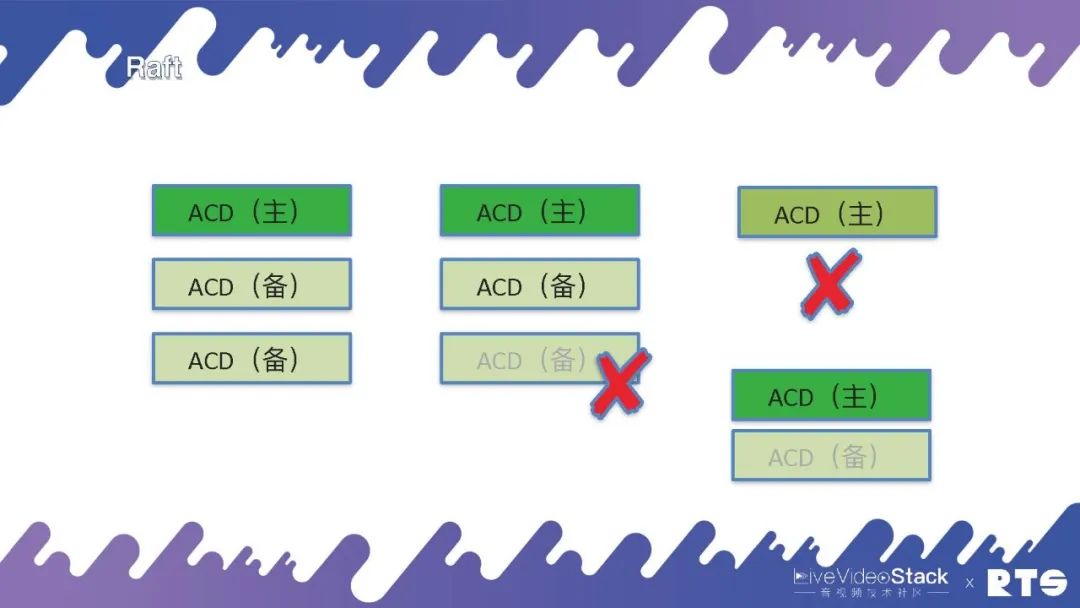
但是它雖然能保存數據卻不能對外提供服務,Raft集群規定其中有一臺主機負責寫數據,另外兩臺負責備份,只有集群當中有多數的主節點和備節點活著的時候,比如說3個死了1個,則還可以繼續對外提供服務。但是如果是死了兩個,就不能繼續對外提供服務了。
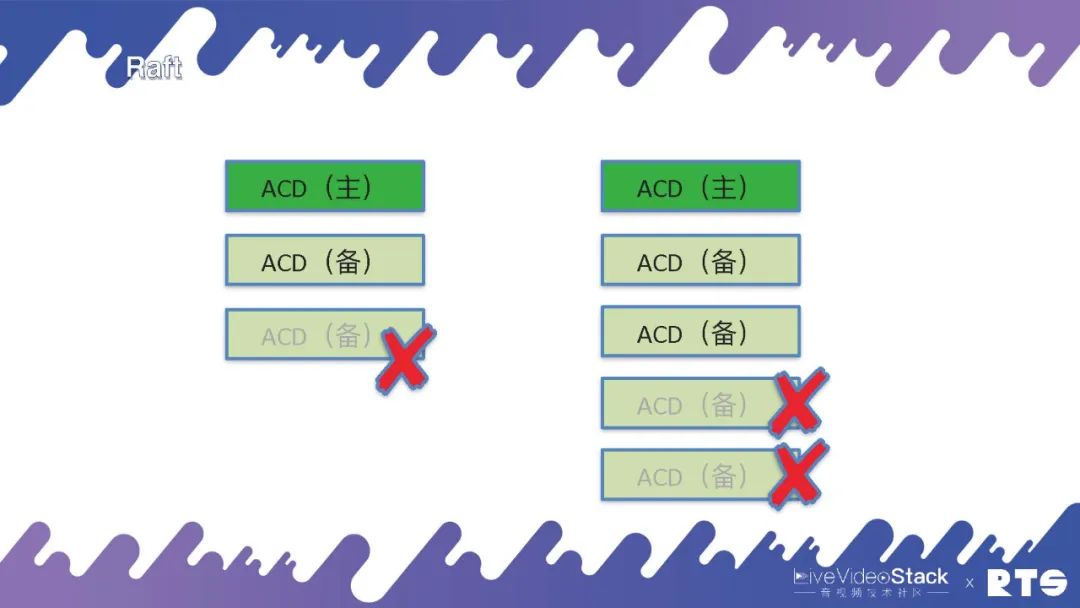
那么,這是為什么?如圖最右側我們來看,假設原來的主服務器與其它服務器斷開鏈接,此時它還是能正常進行服務。而另外的兩臺服務器會根據當前情況判斷,重新選舉出一臺作為主服務器。此時,整個集群當中就會同時出現兩臺主服務器產生沖突。所以一定要遵循少數服從多數的原則,只有當整個集群中有多數的節點活著的時候才能對外提供服務。
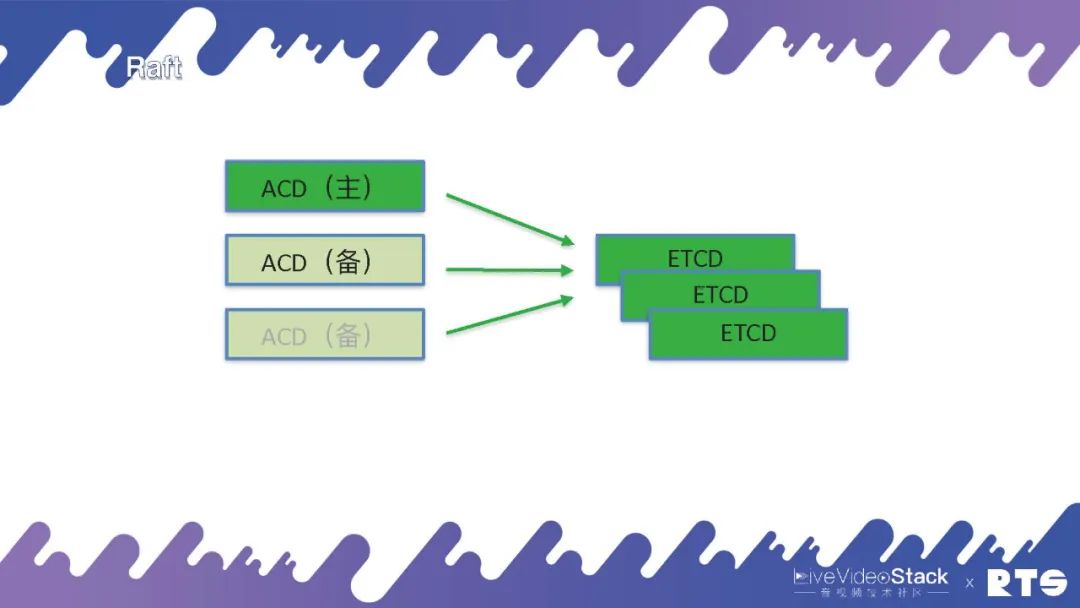
當然,如果我們說要把所有的ACD里面都要實現一個Raft是很難的。目前有一個應用叫做ETCD,我們可以直接將服務連接到ETCD上,它會告訴我們誰是主誰是備。但是這樣又帶來了一個問題,本來三臺機器就可以,我們還需要另外再裝三臺ETCD,這樣會帶來更大的開銷和浪費,多用了一倍的資源。
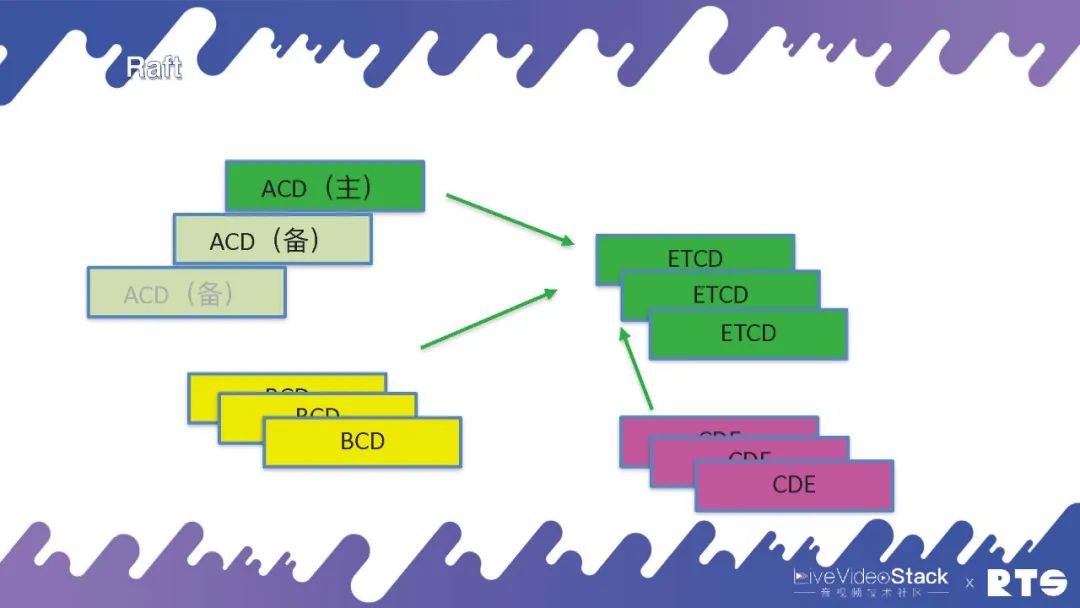
但是當我們的集群比較大的時候,比如除了ACD外我們還有其它服務如BCD、CDE等等。如果各種微服務的數量比較多,可以公用一個ETCD的話,相比較而言開銷也就沒那么大了。

簡單的總結一下:
雙機可以提?可靠性,但投?資源和獲得回報不成正?;
為了節省服務器,把不同的服務放到相同的物理服務器或虛擬機上,可能適得其反;
集群可以提?可靠性,但只有集群?夠?,資源才能有效利?;
雙機需要的服務器數量是偶數的,?少2臺;
分布式系統(集群)需要的服務器數量是奇數的,?少3臺。
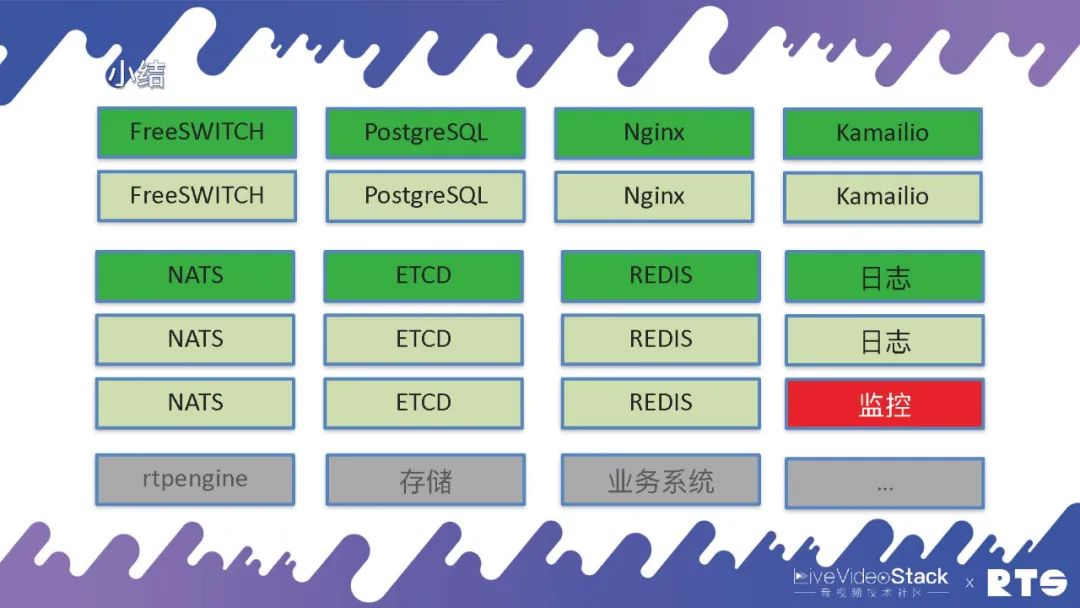
一般的來說,有一臺FreeSWITCH服務器就夠了,如果想雙機設備的話就需要兩臺服務器,如果需要數據庫的話就是四臺。有可能還會放Nginx代理HTTP,還有可能會放Kamailio來代理SIP。當然我們主要使用NATS,這是一個消息隊列。然后使用Etcd來做選主,有可能使用Redis來做緩存,還有可能做日志、監控等各種服務器。還有可能rtpengine、存儲、業務系統......
總之,要是想建立一個可靠的系統至少需要十幾臺服務器,它對外所能提供的服務能力也超不過一臺服務器的服務。所以如果集群規模比較小,那就沒有什么意義,投入天文數字但實際上整體的收益很小。如果想要集群規模做的足夠大,類似云服務,那么投入多少臺服務器其實都無所謂了,因為開銷是相對比較小了。當然,這些最終還是需要根據業務本身來做權衡。
04XSwitch實踐
接下來介紹一些XSwitch的具體實踐。
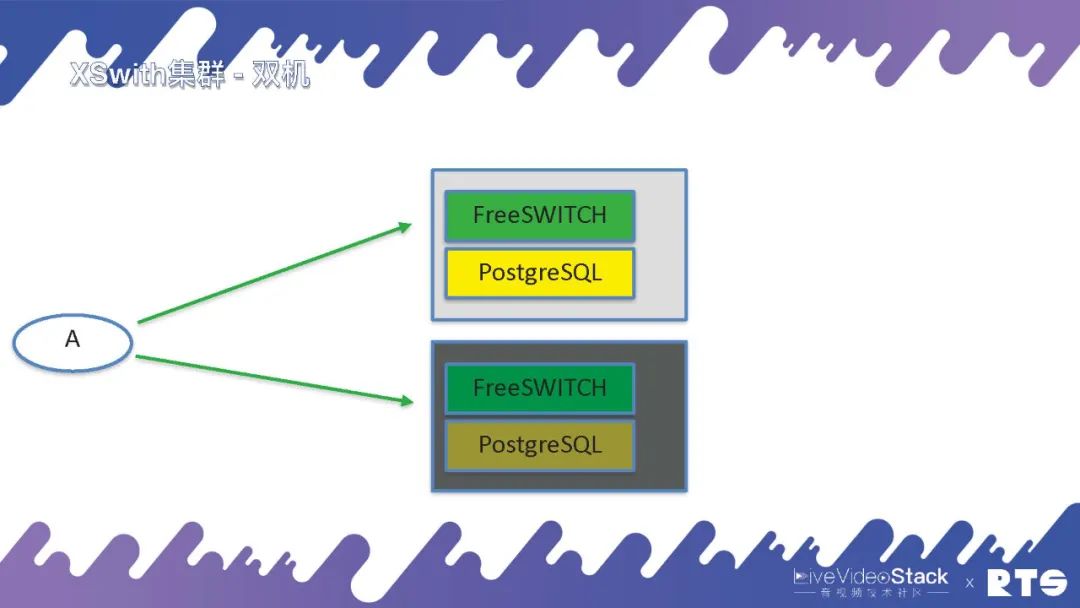
XSwitch即XSwitch集群,一般來說最小的配置就是雙機,主備高可用,FreeSWITCH和PostgreSQL放在一塊。
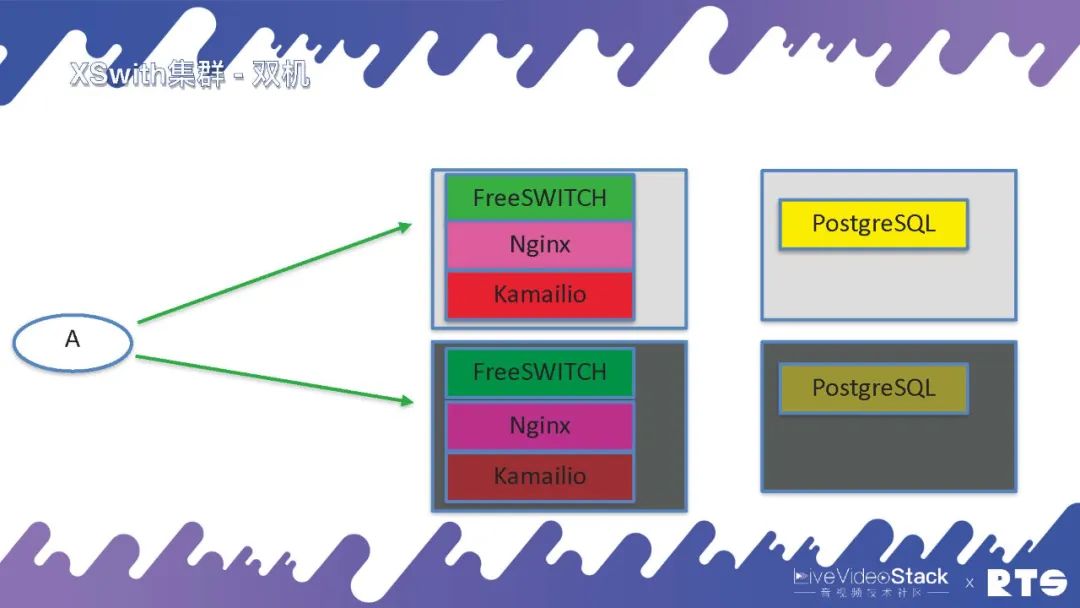
對于有一定預算的客戶,我們就建議他們將數據庫獨立出來,放在獨立的服務器上,總共4臺服務器。Nginx一般我們可以跟FreeSWITCH放在一起,然后有可能我們會放Kamailio。
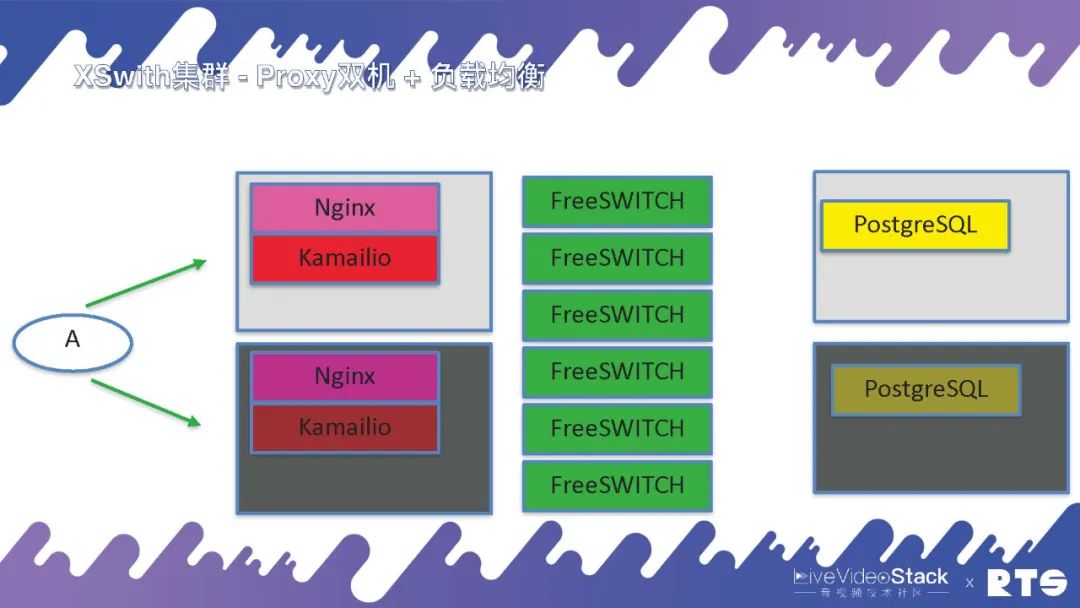
如果預算充足也可以將它們都獨立出來,這樣后面就可以放更多的FreeSWITCH。
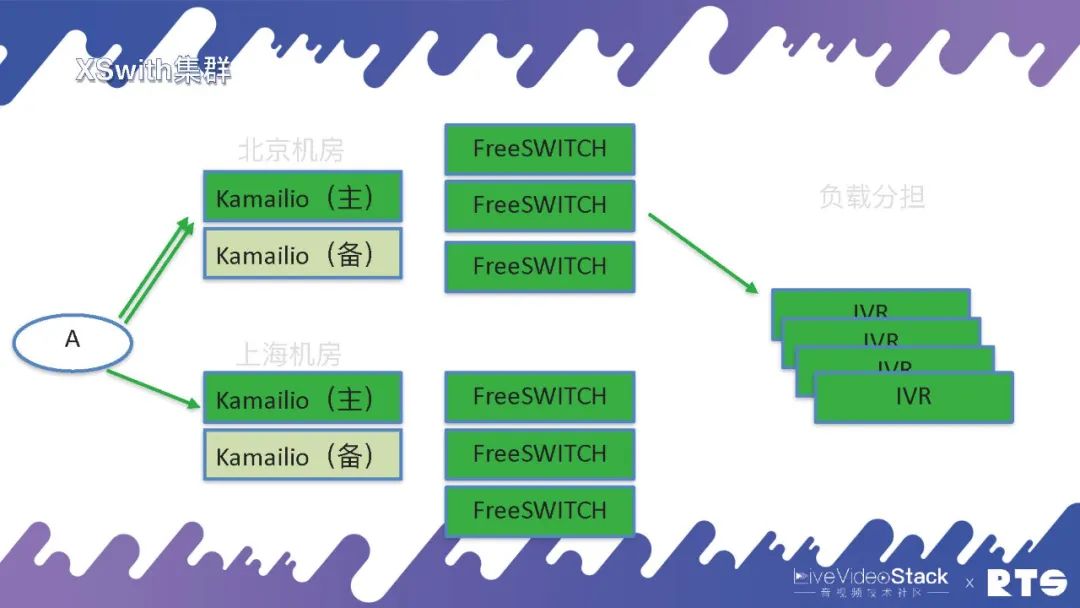
再就是異地的,負載分擔。
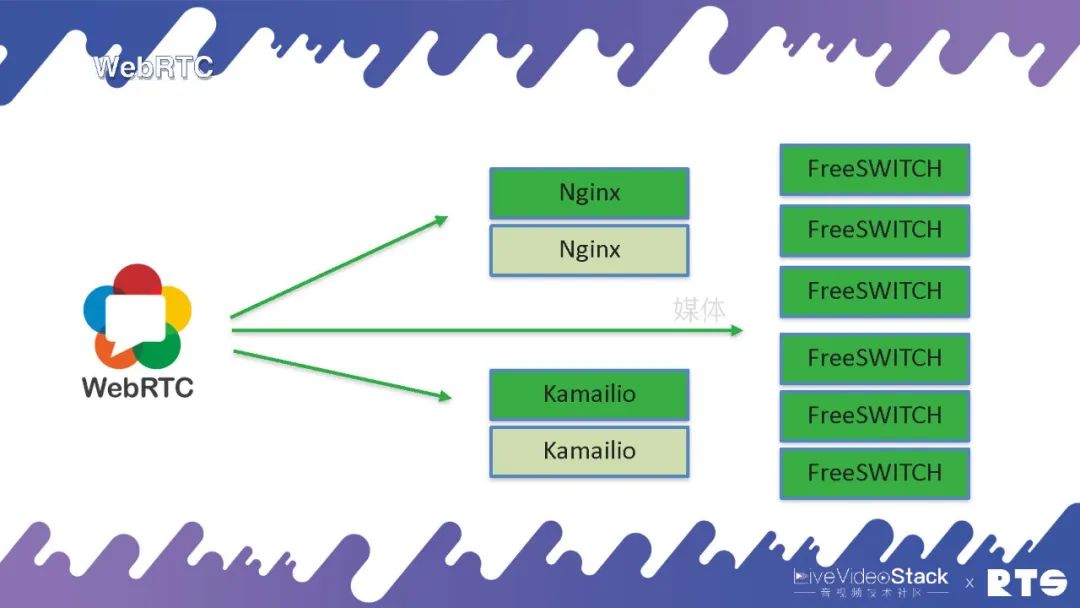
因為WebRTC只有媒體, 所以就是直接到FreeSWITCH,信令可以通過Nginx或者Kamailio實現,因為信令都是基于WebSocket來做的,這是WebRTC的高可用。當然,媒體前面我們提到有個rtpengine也可以做代理,可以把后臺的FreeSWITCH隱藏起來,這就是更復雜的一些應用了。
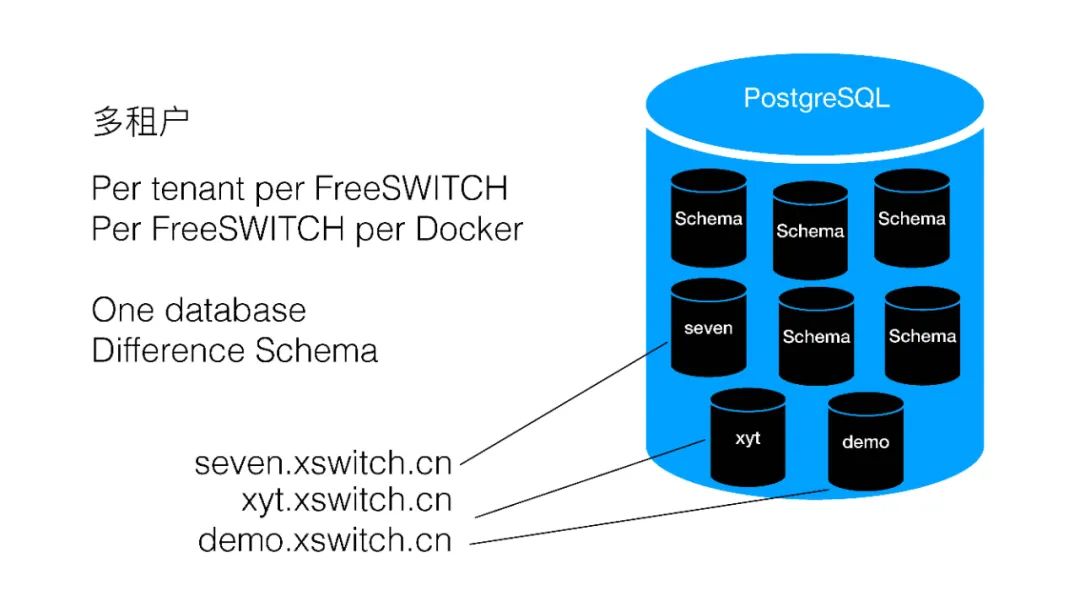
XSwitch如何實現多租戶呢?其實我們有好多種方式,一種就是Per tenant per FreeSWITCH,每個租戶給它一臺FreeSWITCH,每個FreeSWITCH一個Docker,使用同一個數據庫,我們用的是PostgreSQL,里面可以天然的分Schema,每個Schema都是彼此隔離的,這樣的話可以給每個租戶分一個Schema。
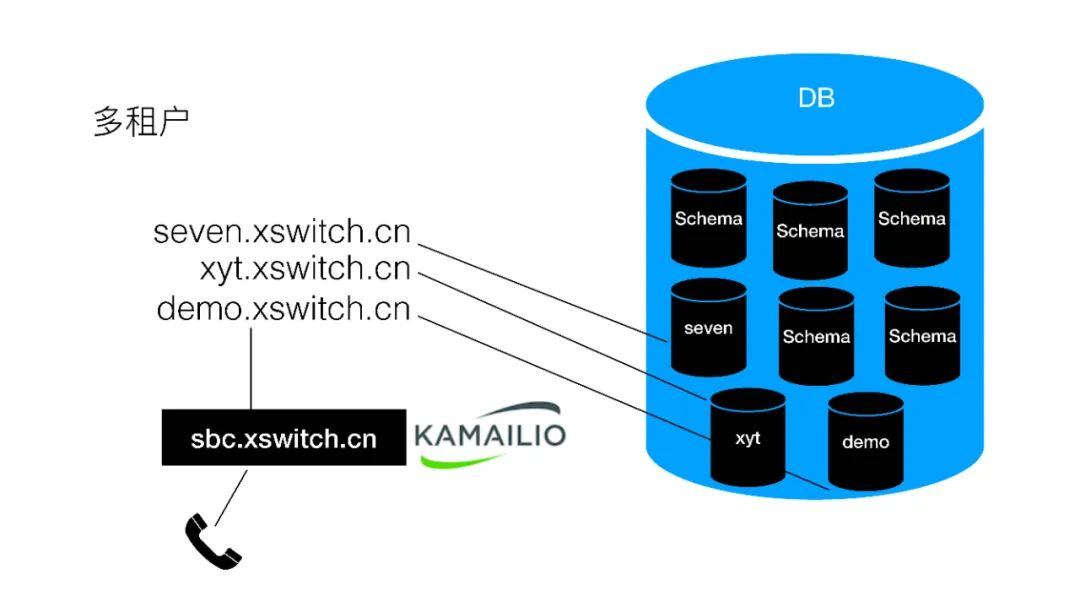
也就是每個租戶一個域名,每個租戶一個Docker,每個租戶一個Schema,數據庫是同一個。前面放一個sbc,用Kamailio來做信令的代理,當然sbc現在我們是單機部署的,以后也可以做HA。
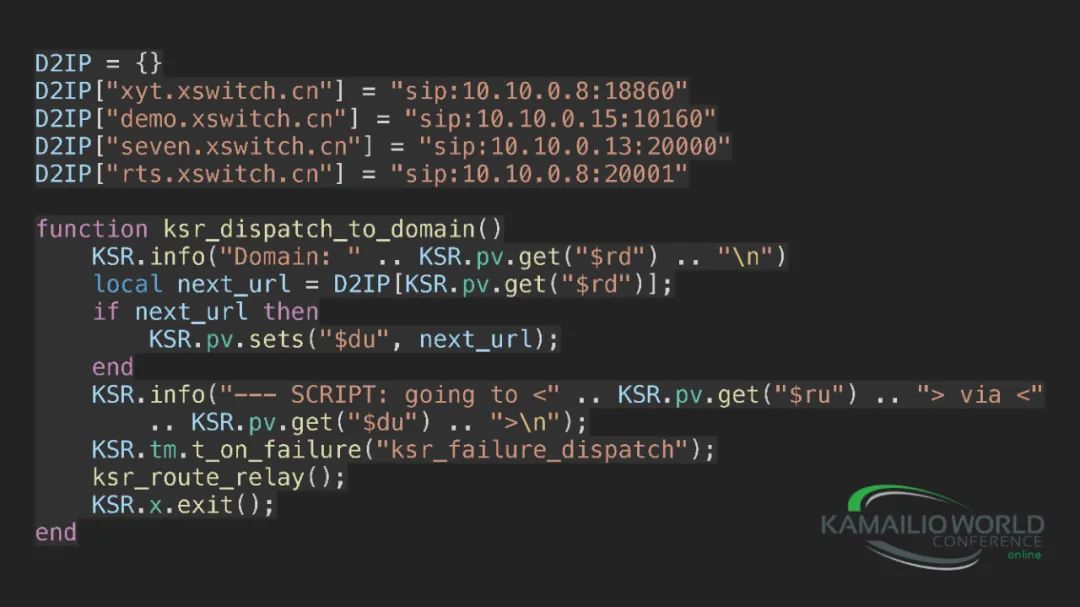
具體的代碼其實我們就寫了一個映射表,因為我們現在集群規模比較小,還沒有放數據庫,通過域名就可以直接查到對應的IP地址,來進行分發。我們使用的是Kamailio+Lua。
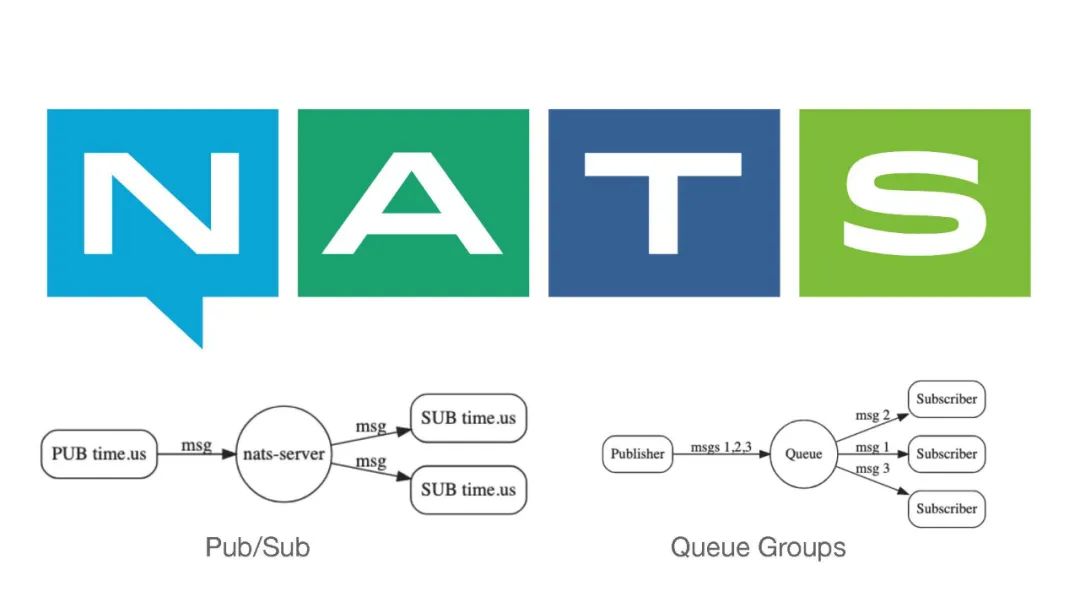
在應用側我們就使用了NATS。NATS是一個消息隊列,所以它具有消息隊列的一些基本特性,比如說Pub/Sub來進行推送,還有一個就是Queue Groups,可以通過一個隊列進行訂閱,這種情況下就可以做負載分擔。生產者生成了一條消息,消費者可以負載分擔的消費這些消息。
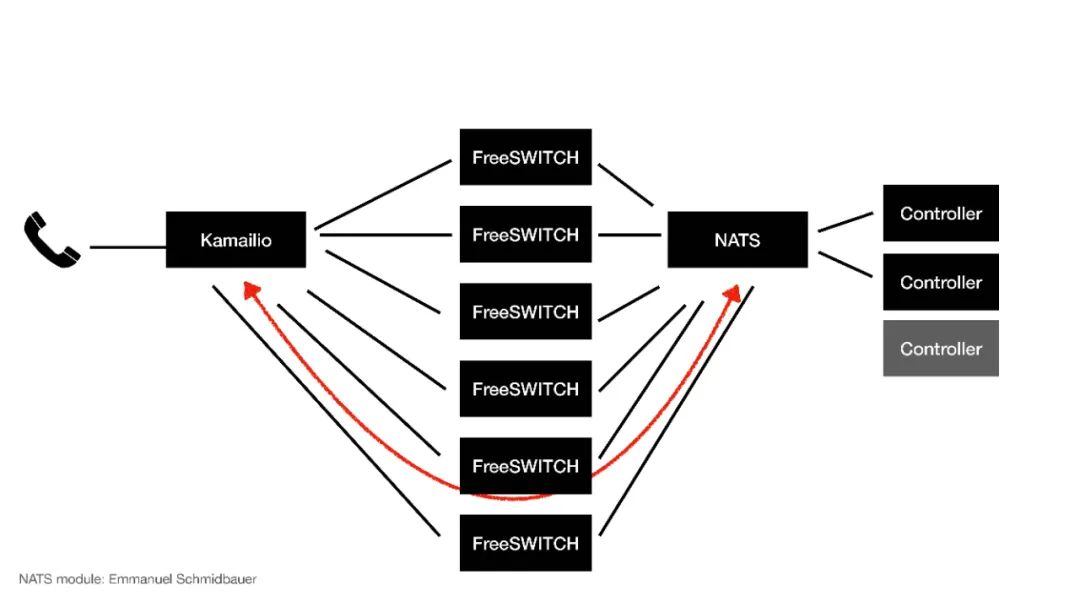
那么我們就用它來做集群的應用:來了一個電話到Kamailio進行分發,分發到不同的FreeSWITCH,通過NATS分配給不同的Controller,這個Controller就是應用側,應用側會控制通話的邏輯。
當來了一個電話到了FreeSWITCH以后,NATS會分給某一個Controller,這個時候Controller就跟某一臺FreeSWITCH建立了一個虛擬的對應關系,在這個電話的生存期間它就可以控制這路電話的通話行為和呼叫流程。
當然,這個Controller也可以額外增加,FreeSWITCH也可以。NATS也連接到了Kamailio,Kamailio也可以感知到NATS,這時候如果我們擴展、彈性伸縮,FreeSWITCH不夠用我們又加了幾臺,這個時候FreeSWITCH就會給NATS發一個消息,NATS會把這個消息發給Kamailio,Kamailio就感知到我現在有了6臺FreeSWITCH,它就會重新計算它的路由表,我們用的是dispatcher模塊,重載dispatcher模塊的數據,然后它就會把新的通話分發給新的FreeSWITCH,這樣就完成了一個擴容,這也就是彈性伸縮。
彈性伸縮的“伸”還是比較容易的,只需要往上加機器就行。“縮”才是比較困難的,有時候需要等所有的話務量都去掉之后才能進行。
當然,“縮”還有一個就是可能大家都認為的,比如其中一臺機器掛掉了,我重啟一下。其實重啟之后它就不是原來那臺機器了,我們這邊用的都是FreeSWITCH的UUID,重啟之后UUID會發生改變。雖然IP地址有可能變有可能不變,但我們認為它是變了,因為是一臺新的機器了。
所以說在這個集群里面,即使是重啟了以后,它也不是原來那臺機器了。我們在哲學里曾學過:“?不能兩次踏?同?條河流”就是這個意思。如果想要做集群,那就要把它做成是無狀態的最好,這樣才能大規模的分發和復用。
所以說使用的機制主要是Docker和K8S。當然,將FreeSWITCH放在K8S里面并不容易,首先我們先放到Docker里面,先完成容器化,然后再放到K8S里面。因為K8S它是一個網絡,優點就是不知道它在哪臺物理機上運行,想啟動就啟動,想關閉就關閉。但是FreeSWITCH、SIP,尤其是RTP,它們有一大堆的端口,就會比較麻煩。

那么,我們是怎么做的呢?我們使?Kamailio做Ingress,負責信令進來。Kamailio還是雙機,然后它分發給后端的FreeSWITCH,FreeSWITCH不夠用了就執行Scale Up,相反就Scale Down。
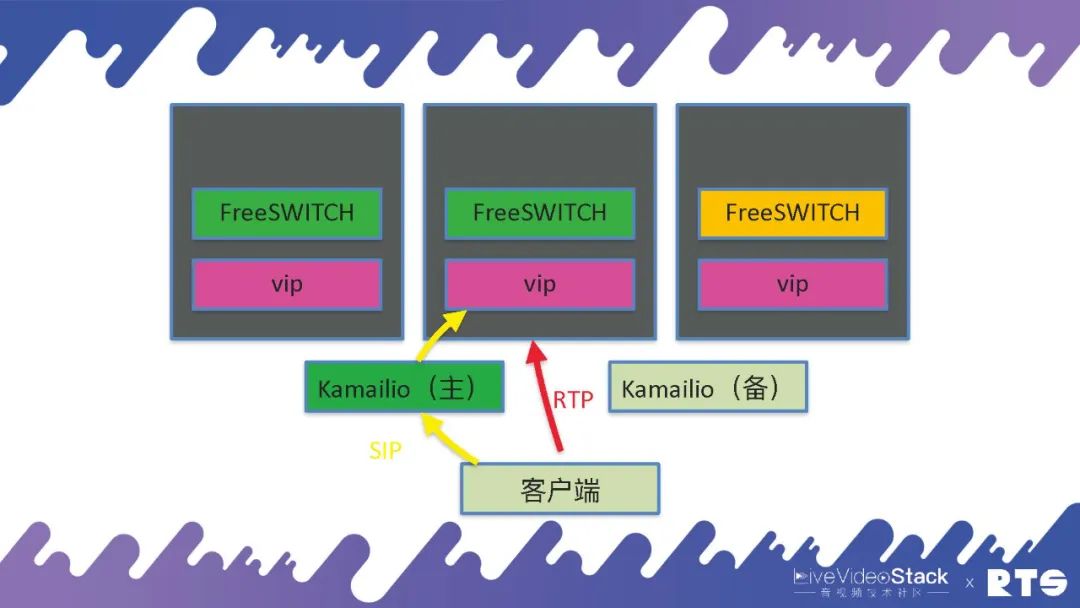
但是具體的我們使用了一個東西叫做VIP,這個VIP是我們自己寫的一個協議,因為現在的K8S主要是針對HTTP來優化的,對SIP類的應用就會比較麻煩。所以我們就自己寫了一個應用,在每臺物理機或者虛擬機上,都有一個VIP的服務。當FreeSWITCH啟動的時候,同樣每臺機器上也只啟動一個FreeSWITCH,它告訴VIP打開一對端口,然后VIP就把這些端口通過iptables打開,就可以正常分發了。萬一這臺機器死了之后,端口就是空著不用也無所謂,因為FreeSWITCH也死了,不會有服務往這上面發了。當機器重啟之后,端口仍舊還是使用這幾個端口段,所以也沒有問題。這種情況下RTP就是直接到FreeSWITCH,前端還是通過Kamailio進行分發SIP。

這種應用就是每個Node上只運??個FreeSWITCH,每個Node上運??個vip。當然,VIP這個東西叫做DaemonSet,每臺機器上只起一個VIP服務,這個服務也在集群當中。通過這種方式我們就可以動態的打開SIP和RTP的端口,這樣可以做彈性的伸縮。這是我們做的一些應用。

當然,如果一個Node 64核、128核,能不能運行多個FreeSWITCH?可以的,其實這樣就需要按端口段來分開,可以做成兩個Pod,一個占10000-20000,另一個占30000-50000。這樣的話通過這種方式,保證兩個FreeSWITCH同時啟動的時候互不影響,同樣管理也會更加復雜。
下面是在Kamailio中使用NATS的一些基本代碼:


05會議
下面還有一種就是會議。
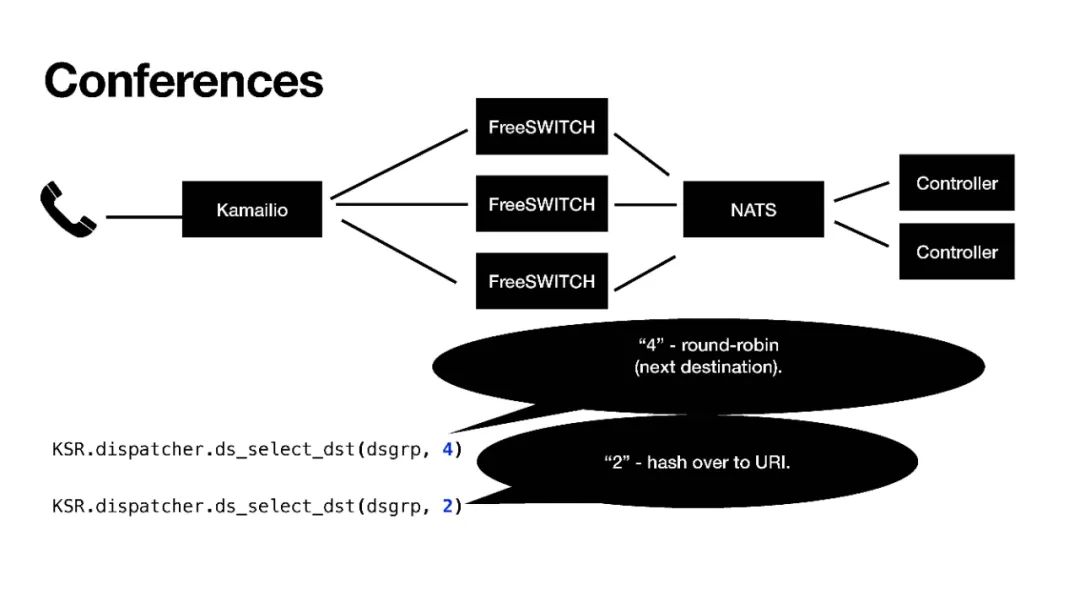
我們平常的負載分擔分發是盡量平均的分發到不同的FreeSWITCH,這是最好的分發策略。但是會議不能,會議需要把呼入同一個會議號的,都分發到同一臺FreeSWITCH上。這里我們用了Kamailio中一個“2”的策略,“hash over to URI”。

當然,實際使用的時候會議規模比較大,一臺FreeSWITCH不能滿足,我們需要放到多臺FreeSWITCH上,這個時候我們就用了“7”這個策略,“hash over the content of PVs string”。我們可以自己創建一個字符串,只要是計算出來不同的終端,它在一個組內,通過分組,只要計算出來字符串是相同的,就會分配到同一臺FreeSWITCH。
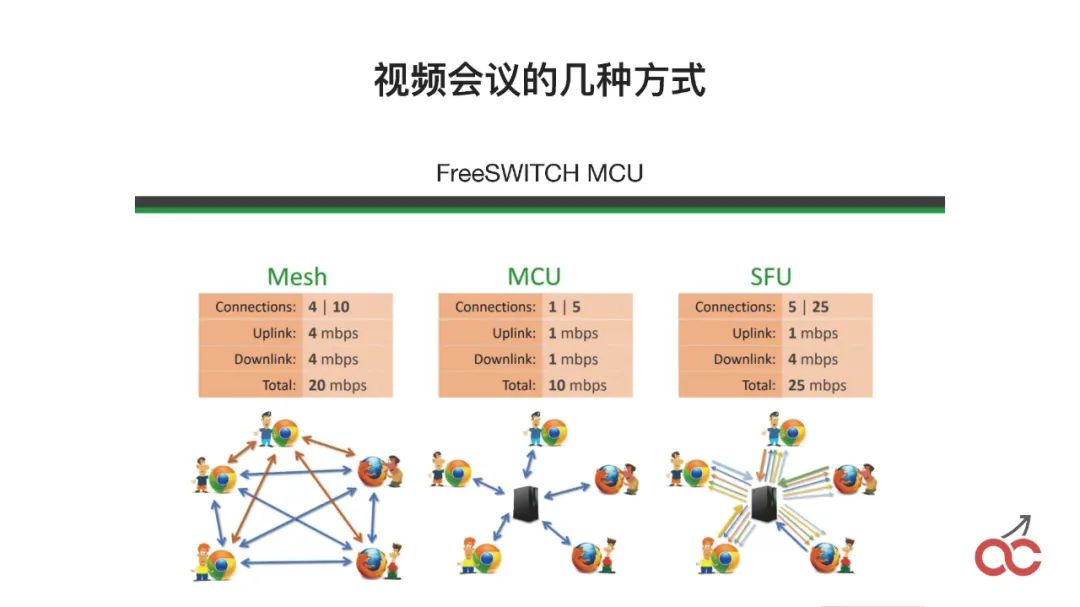
視頻會議有這么幾種方式:Mesh是無狀態的,MCU就是所有的東西都通過中間融屏,SFU是通過它進行分發,不融屏。
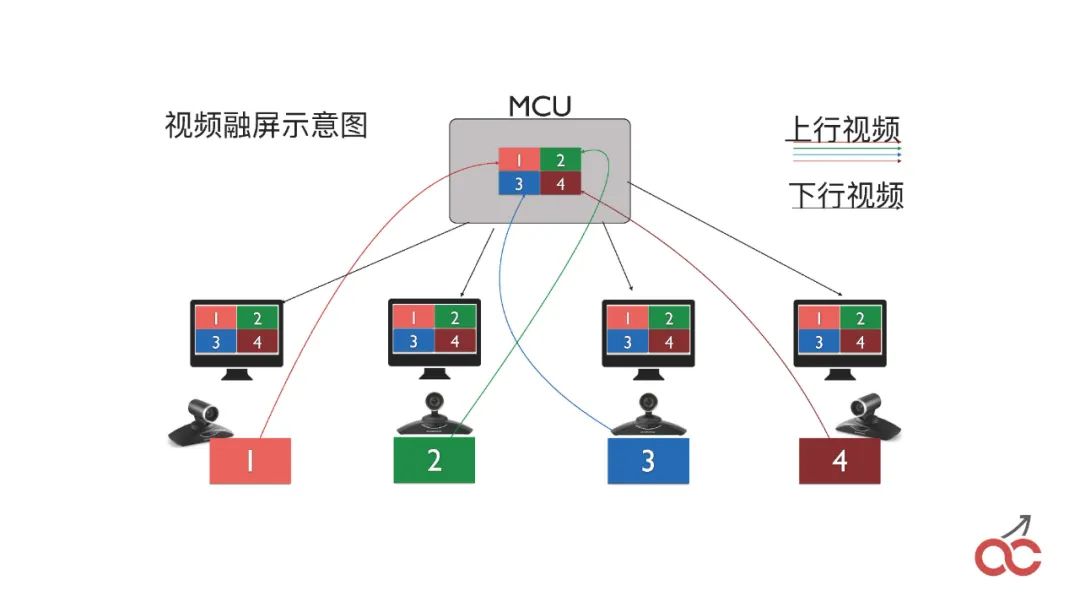
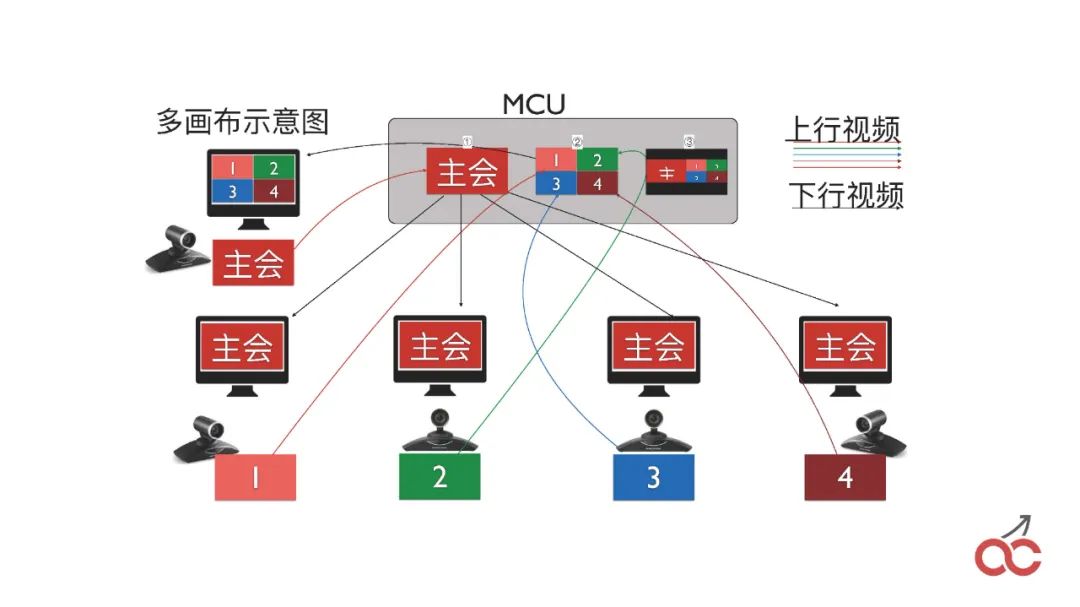
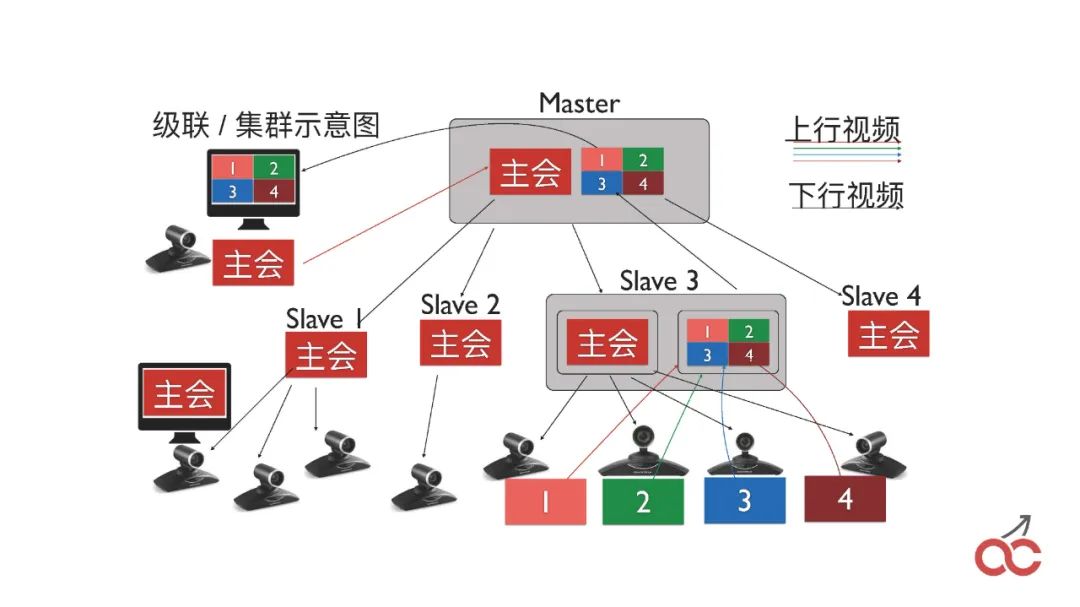
我們也會做會議的級聯,通過多個FreeSWITCH級聯來實現較大規模的會議。
級聯也會出現一個問題,叫做“看對眼”,就是出限類似無限循環的效果,如上圖中的樣子。

那么,我們是怎么做的?我們在會議當中,首先我們說怎么將兩個FreeSWITCH的會議串起來。
很簡單,就是在第一臺FreeSWITCH里面 conference 3000(會議號),然后呼叫另外一臺FreeSWITCH也呼3000,另外一臺FreeSWITCH收到呼叫以后,直接conference 3000 加入會議,這個時候就是把兩個會議進行串起來。

串起來之后,我們就可以設置兩個畫布,第一個是“video_initial_canvas”,表示我把我的圖像放在哪個canvas上;第二個是“video_initial_watching_canvas”,表示我看哪個canvas。

通過這種方式,我們也完成了MCU和SFU的互通。我們現在打通了Agora、TRTC以及MediaSoup之類的應用。
06日志
最后一個我想說的就是日志。

日志很簡單,都有一些現成的服務:
Homer是做SIP的日志的,它的實現原理就是FreeSWITCH或Kamailio插入一個Agent,會將收到的消息轉發給它,將SIP的圖畫出來;Loki就是存放日志的,我們會把所有的日志都發給它;另外還有Zabix、Grafana、Promuthus。

這里面關鍵的一點是,每天成千上萬路的通話并發,我們需要知道哪一路通話跟哪一路是相關的。所以說要有一個uuid,FreeSWITCH里面每一路通話都有一個uuid,這個UUID要跟call-id關聯起來。通過call-id就可以找到對應的uuid,通過uuid就可以找到另外一條腿的uuid。

上面是呼入,呼出的時候使用的是這個參數:outbound-use-uuid-as-callid。

如果FreeSWITCH對外發出一路呼叫,在SIP當中的Call-ID和內部的uuid是一致的,這樣就可以找到它們的對應關系,日志和SIP的對應關系。
這樣的話,A進來,通過A的Call-ID就可以找到uuid,通過B的uuid就可以找到對應的Call-ID。通過Other-Leg-Unique-ID,這個在事件里面會有,或者Channel-Call-UUID,都能找到到對方,找到A和B。
07總結

最后,簡單的總結一下。通信的集群我們要用到各種各樣的開源軟件,要有雙機、三機,彈性伸縮,包括?對?通話、呼叫中?及?視頻會議、?志監控等場景。最終還是萬變不離其宗,不管使用的是任何軟件,它們的基本原理是不變的。
審核編輯:劉清
-
RTC
+關注
關注
2文章
542瀏覽量
67028 -
MCU技術
+關注
關注
0文章
19瀏覽量
5827 -
SFUD
+關注
關注
0文章
5瀏覽量
1079
原文標題:FreeSWITCH高可用部署與云原生集群部署
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
云原生技術概述 云原生火爆成為升職加薪核心必備
Kubernetes Ingress 高可靠部署最佳實踐
Hadoop的集群環境部署說明
只需 6 步,你就可以搭建一個云原生操作系統原型
華為云中什么是云原生服務中心
什么是分布式云原生
K8S學習教程(二):在 PetaExpress KubeSphere容器平臺部署高可用 Redis 集群





 工商網監
工商網監
評論