 MAXQ競爭分析研究
MAXQ競爭分析研究
為了演示MAXQ微控制器的功能,我們采用了為競爭對手的微控制器編寫的基準代碼,并在MAXQ2000上運行。結果表明,MAXQ是目前最好的16位微控制器內核之一。
介紹
MAXQ獨特的轉換觸發架構使其成為16位微控制器市場中的佼佼者。MAXQ指令集具有單時鐘和指令周期運算,用于跳轉、調用、返回、環路控制和算術運算。因此,MAXQ使應用能夠在比其他微控制器更短的時間內處理更多的數據。因此,設計人員可以在其應用中添加更多功能,或者通過快速完成所需任務并在低功耗停止模式下花費更多時間來降低功耗。
為了演示MAXQ的競爭分析能力,我們采用了為展示MSP430而編寫的基準代碼,在MAXQ上運行,并監測MAXQ的性能。競爭對手的代碼最初使MAXQ函數相對較慢且效率低下。后來,當Rowley高度優化的MAXQ編譯器向市場發布時,我們重新運行了基準測試代碼。我們發現Rowley的編譯器更有效地使用了MAXQ架構特性,并且MAXQ的性能優于德州儀器(TI)MSP430和Atmel AVR。MAXQ在更少的時鐘周期內執行相同的代碼。此外,這種加速的性能并沒有因為額外的代碼大小而對用戶造成不利影響——MAXQ的代碼大小在競爭代碼大小的2%以內。
本應用筆記詳細介紹了我們對MAXQ、Atmel AVR和TI MSP430架構的研究。這項研究是透明的——沒有編譯器優化的技巧或專門的代碼來迫使一個微控制器比另一個微控制器表現得更好。模擬網站上提供了項目文件和源代碼,以便可以復制結果。
關于方法的注意事項
在本次研究的兩個編譯器IAR Embedded Workbench和Rowley CrossWorks中,我們使用Rowley的編譯器來生成MAXQ的基準數據,因為它充分利用了MAXQ功能。IAR 和 Rowley 編譯器結果均用于 MSP430 和 AVR 微控制器測試。
執行時間數據是使用IAR的嵌入式工作臺和Rowley的CrossWorks工具集附帶的模擬器收集的。計算的執行周期不包括啟動時間;計數從 main() 函數的入口點開始,以 main() 函數的 return 語句結束。
代碼大小以字節為單位,包括常量和代碼段。這是因為某些工具在 CODE 段中包含應用程序常量,這會使設備的代碼密度錯誤地顯示為高。組合 CODE 和 CONSTANT 段的大小可確保等效比較。
通常,我們將編譯器配置為對所有設備使用其最高代碼優化級別。這通常意味著在面向最小代碼大小時啟用所有優化,在面向最快代碼時啟用幾乎所有優化(因為某些編譯器優化會犧牲速度來換取代碼大小)。在某些情況下,高優化設置會導致問題 - 生成的代碼無法正確模擬,從未到達 return 語句。通常,當優化級別更改時,代碼開始工作。我們將指出何時需要降低優化級別。本應用筆記隨附的項目文件包含用于生成基準數據的優化設置。
TI 基準測試
該基準測試是德州儀器發布的一套測試,用于展示 MSP430。該套件包含 10 個單獨的基準測試:
8 位數學例程
8 位矩陣(陣列)訪問
8 位開關語句
16 位數學例程
16 位矩陣(陣列)訪問
16 位開關語句
32 位數學例程
浮點數學例程
有限脈沖響應算法
矩陣乘法
按照TI測試參數,MAXQ表現不佳。它生成的代碼比大多數其他微控制器更大、更慢。當然,TI 研究表明 MSP430 是比較中的贏家。然而,透明國際的方法存在缺陷,需要進一步分析。因此,我們研究了MAXQ在Rowley CrossWorks編譯器上的表現。
TI 結果
TI 研究提供了執行速度(以時鐘周期為單位)和代碼密度(以字節為單位)的結果,如表 1 和表 2 所示。請注意,某些器件名稱(直接取自TI應用筆記)不清楚。例如,8051 是指 12 時鐘、6 時鐘、4 時鐘甚至 1 時鐘 8051 架構嗎?
| 應用 | MSP430F135 | ATmega8 | 圖18F242 | 8051 | H8/300L | MC68HC11 | 最大Q20 | ARM7-TDMI (拇指) |
| 8 位數學 | 299 | 157 | 318 | 112 | 680 | 387 | 421 | 185 |
| 8 位矩陣 | 2899 | 5300 | 20045 | 17744 | 9098 | 15412 | 31691 | 2227 |
| 8 位交換機 | 50 | 131 | 109 | 84 | 388 | 214 | 58 | 146 |
| 16 位數學 | 343 | 319 | 625 | 426 | 802 | 508 | 815 | 259 |
| 16 位矩陣 | 5784 | 24426 | 27021 | 29468 | 15280 | 23164 | 60214 | 2998 |
| 16 位交換機 | 49 | 144 | 163 | 120 | 398 | 230 | 51 | 146 |
| 32 位數學 | 792 | 782 | 1818 | 2937 | 1756 | 1446 | 1034 | 115 |
| 浮點 | 1207 | 1601 | 1599 | 2487 | 2458 | 4664 | 1943 | 108 |
| 遠紅外濾波器 | 152193 | 164793 | 248655 | 206806 | 245588 | 567139 | 464558 | 43191 |
| 矩陣乘法 | 6633 | 16027 | 36190 | 9454 | 26750 | 26874 | 66534 | 2918 |
| 總數 | 170249 | 213680 | 336543 | 269638 | 303198 | 640038 | 627319 | 52293 |
| 應用 | MSP430F135 | ATmega8 | 圖18F242 | 8051 | H8/300L | MC68HC11 | 最大Q20 | ARM7-TDMI (拇指) |
| 8 位數學 | 172 | 116 | 386 | 141 | 354 | 285 | 352 | 660 |
| 8 位矩陣 | 118 | 364 | 676 | 615 | 356 | 380 | 378 | 408 |
| 8 位交換機 | 180 | 342 | 404 | 209 | 362 | 387 | 202 | 504 |
| 16 位數學 | 172 | 174 | 598 | 361 | 564 | 315 | 286 | 676 |
| 16 位矩陣 | 156 | 570 | 846 | 825 | 450 | 490 | 526 | 428 |
| 16 位交換機 | 178 | 388 | 572 | 326 | 404 | 405 | 188 | 504 |
| 32 位數學 | 250 | 316 | 960 | 723 | 876 | 962 | 338 | 620 |
| 浮點 | 662 | 1042 | 1778 | 1420 | 1450 | 1429 | 1596 | 1556 |
| 遠紅外濾波器 | 668 | 1292 | 2146 | 1915 | 1588 | 1470 | 1828 | 1420 |
| 矩陣乘法 | 252 | 510 | 936 | 345 | 462 | 499 | 494 | 432 |
| 總數 | 2808 | 5114 | 9302 | 6880 | 6866 | 6622 | 6188 | 7208 |
根據這些數據,MSP430 產生的代碼密度最高,比 Atmel AVR 微控制器小 45%。MSP430 似乎也表現最佳,但 32 位 ARM 處理器除外。這些結果還表明,MAXQ相對較慢且效率低下。
TI 基準研究的缺陷
透明國際制定基準的方式提出了一些問題。
第一個問題是TI在他們的研究中沒有使用任何優化。TI反對編譯器優化,以便將編譯器從考慮范圍中移除,并使微控制器自行執行。這個論點的問題在于工程師仍然使用編譯器來生成機器代碼。如果編譯器在未啟用優化時未利用微控制器的架構功能,則無法實際了解微控制器的性能。此外,基準測試只有在模擬實際應用程序時才有價值。工程師可能會在實際應用中優化尺寸或速度,因此這些應作為基準研究的一部分。
TI 基準測試研究中的第二個缺陷是他們只考慮了一個編譯器。誠然,當時 TI 無法使用 Rowley 編譯器。現在可用,Rowley 編譯器極大地更新了早期的 TI 結果。
馬克西姆的方法
如上所述,我們對 TI 基準測試的重新評估主要集中在 MSP430、Atmel AVR 和 MAXQ 架構上。我們考慮了IAR Embedded Workbench和Rowley CrossWorks工具集的執行和代碼大小數據。所有執行速度的結果均通過仿真得到。
本研究中的MAXQ器件是MAXQ2000微控制器。除了包括LCD控制器在內的一系列外設外,MAXQ2000還具有16個16位累加器和一個16 x 16硬件乘法加速器。在這項研究中,我們在所有三個被測器件上都啟用了硬件乘法器——我們假設如果數學計算(如FIR濾波器)的性能很重要,設計人員會選擇帶有乘法加速器的微控制器。
對于 MSP430 器件,我們以 MSP430F149 為目標,這與他們研究中針對的 TI 器件 (MSP430F135) 不同。我們之所以選擇F149,是因為它有一個硬件乘法單元,使得與MAXQ2000的比較更加公平。
之所以選擇ATmega8進行研究,是因為當前的IAR編譯器可以使用該微控制器的硬件乘法器生成代碼。IAR 編譯器無法對其他 AVR 設備(如 ATmega64 或 ATmega128)執行此操作。
從這兩個工具集中收集基準測試結果非常簡單。在 IAR 中,代碼大小數據位于映射文件(確保它是在“項目選項”→“鏈接器→列表”下生成的)。向下滾動到地圖文件的底部,將顯示以下三行:
184字節代碼存儲器 80字節數據存儲器
66字節CONST存儲器
如前所述,我們將 CODE 和 CONST 內存部分都計入總代碼大小,因為編譯器在放置常量程序數據的位置上有所不同。對于測試,比較代碼大小的唯一合法方法是包含常量大小。
若要在 IAR 中查找執行周期,請選擇模擬器作為調試工具并開始調試。在“查看→分析”下啟動代碼分析器。單擊“激活”按鈕和“自動刷新”按鈕(請參閱圖 1)。調試器應自動運行到 C 代碼的第一行。按 Run 鍵,(如果未設置斷點)IAR 調試器在程序退出時終止。查看代碼探查器,并在 main() 的“累積時間”下報告 周期數 - 這是在主例程和 main 調用的所有子例程中花費的周期數。
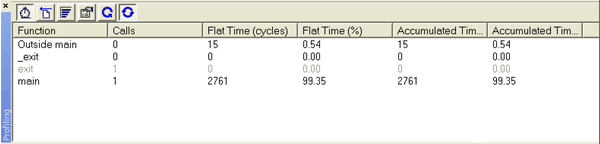
圖1.IAR 代碼探查器:累計時間(周期)是指在該例程及其調用的所有子例程中花費的周期數。
在 Rowley 工具集中查找生成的代碼大小也非常容易。生成項目時,項目資源管理器會隨項目一起列出代碼大小。圖 2 顯示,對于 MSP430F149,16 位數學基準測試代碼大小為 238 字節。
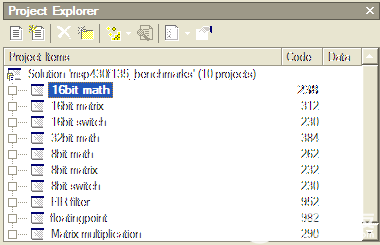
圖2.Rowley 項目資源管理器顯示每個項目的代碼大小詳細信息。
在 Rowley 工具中確定執行周期數并不像使用 IAR 那么容易 - Rowley 不會在程序結束時自動停止,也不會分離周期的花費位置。您必須在進入主程序時重置循環計數器。為此,請首先開始調試程序。當編譯器在 main 的入口點停止時,雙擊它來重置循環計數器。
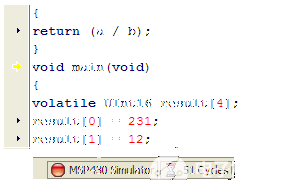
圖3.當 Rowley 模擬器在 main() 處停止時,雙擊它來重置循環計數器(帶有沙漏的圖片)。
接下來,在應用程序末尾設置斷點。(請注意,邊距中帶有藍色三角形的線條指示可以設置斷點的位置。運行到斷點并記錄報告的周期數。
使用羅利模擬器還有其他可能的并發癥。
根據優化的不同,您可能只能在程序集級別進行模擬,在這種情況下,很難找到應用程序的末尾。最好的方法是掃描代碼并在程序集代碼中找到下一個 RETURN 語句,在那里設置斷點,然后運行到該語句。
模擬器可能并不總是在主入口點停止。發生這種情況時,請嘗試按“重新啟動調試”按鈕。您可能還需要手動查找主入口點并在那里設置斷點。
編譯器設置
使用 IAR 工具集時,項目選項中的編譯器選項窗口配置為啟用所有優化的最高優化級別(請參閱圖 4)。若要在目標最小代碼和最快執行之間切換,請將所選單選按鈕從“大小”切換到“速度”。
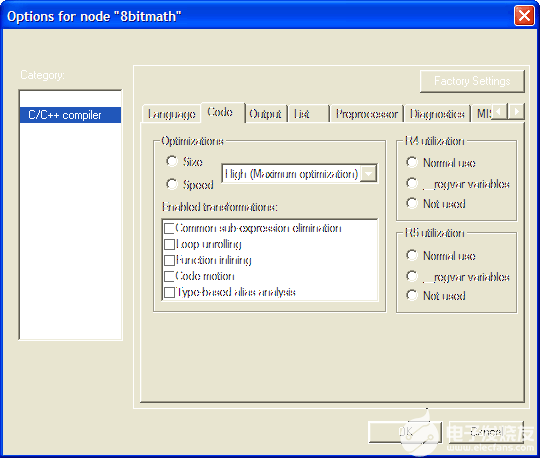
圖4.IAR 編譯器的選項:啟用所有優化。單選按鈕在優化速度和大小之間切換編譯器。
Rowley的CrossWorks允許用戶創建除了默認的調試和發布配置之外的構建配置。因此,本研究的基準項目還包括最快(見圖 5)和最小(圖 6)配置選項。最快配置刪除了以犧牲指令周期為代價來評估代碼大小的任何優化。
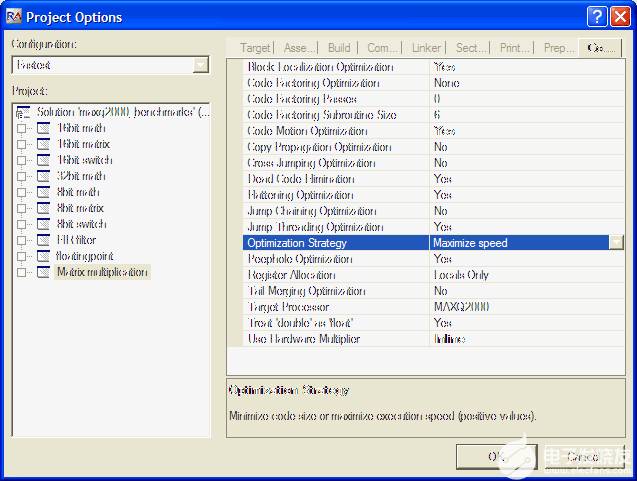
圖5.Rowley的CrossWorks中使用的項目選項可實現最快的配置。
最小配置的設置如圖 6 所示。啟用了以犧牲周期為代價的有利于代碼大小的選項,總體優化策略是最小化大小。
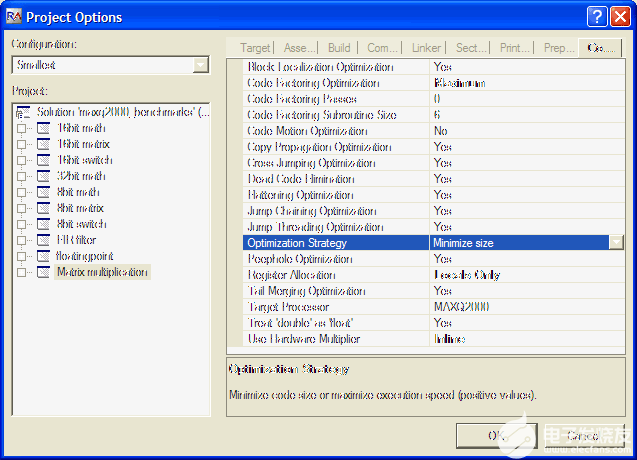
圖6.Rowley的CrossWorks中用于最小配置的項目選項。
Analog 運行的每個基準測試的項目和源文件可在 /en/product-category/ultra-low-power-microcontrollers.html 中找到。這些項目文件中的配置與用于基準測試的配置相同。Maxim網站上的其他第三方工具提供了IAR和Rowley工具試用版的鏈接,因此您可以輕松重現這些基準測試結果。
MAXQ基準測試結果
表3和表4顯示了MAXQ基準測試結果。執行速度再次以時鐘周期的形式給出,代碼大小以字節為單位給出。
| 應用 | MSP430F149 IAR | MSP430F149 羅利 | ATmega8 IAR | ATmega8 羅利 | MAXQ2000 羅利 | |||||
| 配置 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 |
| 8 位數學 | 243 | 243 | 276 | 272 | 110 | 110 | 279 | 278 | 278 | 245 |
| 8 位矩陣 | 1629 | 963 | 6243 | 2659 | 1508 | 1074 | 7348 | 3763 | 3461 | 2947 |
| 8 位交換機 | 31 | 31 | 24 | 24 | 84 | 36 | 45 | 45 | 39 | 39 |
| 16 位數學 | 219 | 219 | 250 | 250 | 275 | 266 | 348 | 330 | 194 | 191 |
| 16 位矩陣 | 1906 | 899 | 6755 | 3171 | 1147 | 697 | 5251 | 5250 | 3205 | 2691 |
| 16 位交換機 | 30 | 30 | 24 | 24 | 111 | 44 | 50 | 50 | 39 | 39 |
| 32 位數學 | 575 | 575 | 790 | 716 | 746 | 731 | 995 | 885 | 545 | 521 |
| 浮點 | 784 | 784 | 1097 | 921 | 1614 | 1565 | 1491 | 919 | 763 | 744 |
| 遠紅外濾波器 | 86042 | 82748 | 90812 | 82592 | 82779 | 82779 | 73598 | 66249 | 62280 | 59470 |
| 矩陣乘法 | 4254 | 2761 | 6036 | 5436 | 7799 | 2396 | 11081 | 9231 | 3704 | 3027 |
| 總數 | 95713 | 89253 | 112307 | 96065 | 96173 | 89698 | 100486 | 87000 | 74508 | 69914 |
圖 7 繪制了執行速度的數據圖表。僅顯示最快的結果。速度以執行周期來衡量 - 條越小意味著性能越好。
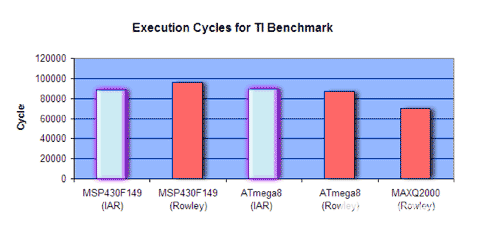
圖7.最快配置設置的執行速度結果。較小的MAXQ2000棒顯示出更好的性能。
| 應用 | MSP430F149 IAR | MSP430F149 羅利 | ATmega8 IAR | ATmega8 羅利 | MAXQ2000 羅利 | |||||
| 配置 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 |
| 8 位數學 | 192 | 192 | 258 | 262 | 98 | 98 | 212 | 212 | 248 | 284 |
| 8 位矩陣 | 152 | 180 | 240 | 232 | 318 | 304 | 220 | 250 | 202 | 222 |
| 8 位交換機 | 180 | 180 | 230 | 230 | 312 | 164 | 202 | 200 | 152 | 152 |
| 16 位數學 | 140 | 140 | 220 | 220 | 162 | 154 | 222 | 238 | 162 | 164 |
| 16 位矩陣 | 240 | 240 | 312 | 312 | 398 | 374 | 294 | 350 | 260 | 378 |
| 16 位交換機 | 178 | 178 | 230 | 230 | 346 | 178 | 212 | 240 | 152 | 152 |
| 32 位數學 | 236 | 236 | 284 | 388 | 306 | 296 | 380 | 460 | 274 | 324 |
| 浮點 | 1100 | 1100 | 966 | 1004 | 1026 | 1046 | 816 | 936 | 1018 | 1090 |
| 遠紅外濾波器 | 1178 | 1174 | 924 | 966 | 1258 | 1258 | 860 | 896 | 1024 | 1044 |
| 矩陣乘法 | 266 | 250 | 312 | 316 | 476 | 324 | 294 | 348 | 254 | 264 |
| 總數 | 3862 | 3870 | 4076 | 4160 | 4700 | 4196 | 3712 | 4130 | 3746 | 4074 |
下圖(圖 8)顯示了最小配置結果的代碼大小數據。代碼大小以字節數來衡量 - 條形越小意味著代碼密度越高。
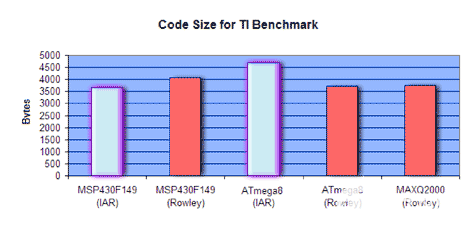
圖8.最小配置設置的代碼大小結果。MAXQ2000的條形越小,代碼密度越好。
| 微控制器 | 編譯器 | 版本 |
| 最大Q2000 | 羅利 | MAXQ 交叉工作,1.0 版,Build 2 |
| MSP430F149 | 羅利 | 適用于 MSP430 的 CrossWorks 版本,版本 1.3,內部版本 3 |
| MSP430F149 | IAR | IAR C/C++ 編譯器,適用于 MSP430,V3.30A/W32 (3.30.1.1) |
| ATmega8 | 羅利 | AVR 的 CrossWorks 版本,版本 1.1,內部版本 1 |
| ATmega8 | IAR | IAR C/C++ AVR 編譯器,4.10B/W32 (4.10.2.3) |
| 裝置 | 工具 | 配置 | 基準 | 問題 |
| ATmega8 | 羅利 | 最小 | 16 位矩陣 | 除非將代碼分解優化設置為 NONE,否則模擬不會終止。 |
| ATmega8 | IAR | 快 | 8 位矩陣、16 位矩陣 | 除非將優化級別設置為中而不是高,否則模擬不會終止。 |
| ATmega8 | IAR | 最小 | 遠紅外濾波器 | 即使在最低優化級別,仿真也不會終止。表3和表4中包含的數字適用于配置最快的FIR濾波器。 |
| ATmega8 | IAR | 雙 | 矩陣乘法 | 模擬不會在ATmega8,ATmega16或ATmega32目標上終止。該項目的目標是ATmega64。 |
分析和總結
在不同的編譯器和啟用優化的情況下,上述結果表明,即使運行 TI 特制的基準代碼,MSP430 也不是性能最佳的微控制器。
考慮到運行整個基準測試套件所需的總執行周期數,MAXQ2000的性能優于MSP430F149和ATmega8。MAXQ2000的周期為69,914次,而MSP430F149 (IAR)和ATmega8 (Rowley)的周期分別為89,253次和87,000次。在考慮基準代碼的總大小時,三個微控制器的最佳情況結果僅相差2%,因此代碼大小的任何差異都無關緊要。
由于代碼密度不是此基準測試的一個因素,因此我們將更深入地研究執行速度結果。總執行周期結果由FIR濾波器結果加權,其中MAXQ2000明顯優于競爭產品。MAXQ2000是數學基準測試中表現最好的,8位數學基準測試中除了ATmega8之外。MAXQ2000的性能最差的是8位和16位矩陣基準,它們將項目從一個多維數組復制到另一個多維陣列。
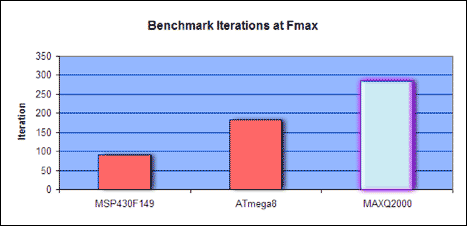
到目前為止,我們只考慮測試微控制器在時鐘周期方面的性能。我們沒有考慮設備的運行速度。為了進行絕對比較,我們使用每秒基準測試迭代次數,即整個 TI 基準測試套件在一秒鐘內可以運行的次數。表7顯示,當所有器件以相同的時鐘速度運行時,MAXQ2000比MSP28F430快149%,比ATmega24快8%。當器件以最大時鐘速率運行時,MAXQ2000比ATmega56快8%,比MSP218F430快149%。
| 裝置 | 周期 | F.max | 1MHz 時的迭代/秒 | F 處的迭代/秒.max |
| MSP430F149 | 89,253 | 8 | 11.20 | 89.60 |
| ATmega8 | 87,000 | 16 | 11.49 | 183.84 |
| 最大Q2000 | 69,914 | 20 | 14.30 | 286.00 |
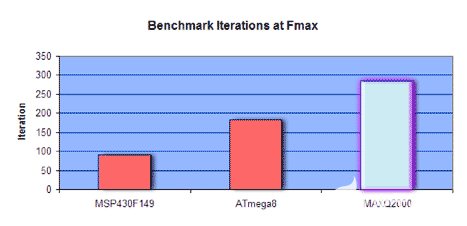
圖9.以最大時鐘速率運行時每秒的基準迭代次數。更高的MAXQ2000桿顯示出更好的性能。
我們應該如何總結Maxim基準研究的結果?至少,它與TI基準研究的結果相悖,后者表明MAXQ微控制器架構并不引人注目。這項更新的研究表明,MAXQ2000是一款代碼高效、快速的微控制器,對于任何受益于更高性能微控制器的新設計和重新設計,都應考慮使用MAXQ<>。
審核編輯:郭婷
-
微控制器
+關注
關注
48文章
7649瀏覽量
152107 -
控制器
+關注
關注
112文章
16445瀏覽量
179447 -
編譯器
+關注
關注
1文章
1642瀏覽量
49286
發布評論請先 登錄
相關推薦
繼電器結構原理分析研究
耦合電感式的Boost電路分析研究
Bluetooth跳頻網絡Piconet聞干擾分析研究
基于MATLAB的實時數據采集與分析研究
EMI抑制方法分析研究
基于多媒體社會事件的分析研究綜述







 工商網監
工商網監
評論