") 聊一聊現(xiàn)階段ChatGPT的缺點與局限
聊一聊現(xiàn)階段ChatGPT的缺點與局限
導語:常識性的問題,它將會具備優(yōu)勢,然而非常識性創(chuàng)作型的問題,它將有非常奇怪的表現(xiàn)。
先前被狂炒,所謂會改變世界的元宇宙被證偽,大量的投資以及熱錢現(xiàn)已從這個極其泡沫化的行業(yè)中撤出。
當時我就指出元宇宙這個行業(yè)純扯淡。
如今由于美聯(lián)儲加息縮表,許多行業(yè)越發(fā)艱難,許多VC也在尋求更多機會(忽悠)更多的韭菜入場,他們就能夠賺到預期的收益(后面韭菜高估值入坑的資本)。
如今我看ChatGPT 這個chat bot,也有類似的巨大問題。
通過這篇文章,我會總結現(xiàn)階段ChatGPT為何尚不足以成為一樣成熟的商用技術,以及這類技術現(xiàn)階段的限制以及缺陷,以及最后聊聊為何這項技術遠不如自媒體或是某些創(chuàng)投口中的“擁抱未來,改變世界”(擁抱韭菜,財富自由)。
許多VC或是甲方遠遠不如外界想象中專業(yè),他們更多的是思考,如何以更高的市場估值讓更大的商業(yè)巨頭接盤。
先聊聊ChatGPT的優(yōu)點。
首先微軟作為軟件行業(yè)的巨頭,一直在尋找切入移動端或是切入下一個互聯(lián)網更新?lián)Q代的賽道。
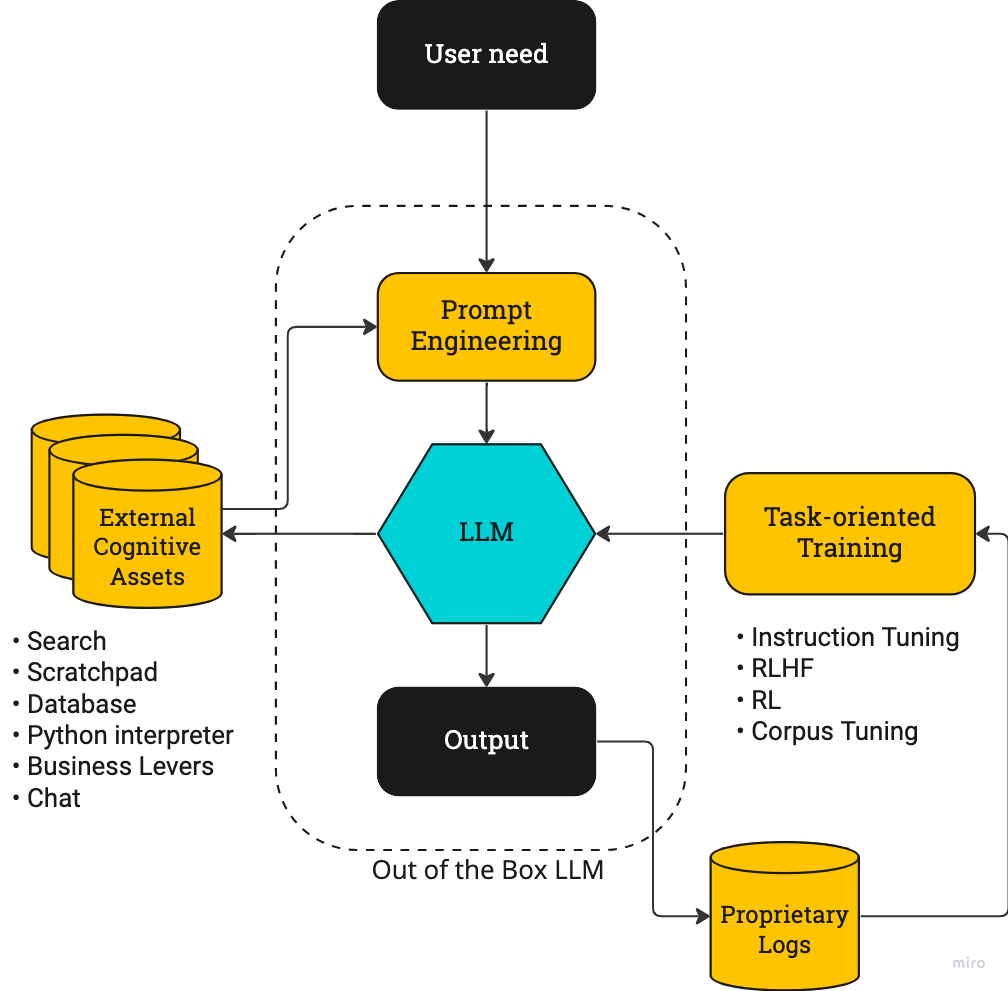
為何微軟愿意在這項自然語義模型(LLM-large language model based,需要大量的語義和參數(shù)作為基礎)砸下巨資,因為它無疑看到這個技術的巨大潛力。
1. 巨大的用戶粘性。
如果這項技術能克服現(xiàn)有缺陷并(弱AI)成形,那么潛在用戶極易對其形成巨大的依賴度。它非常可能成為下一代的搜索引擎,有機會改變用戶的搜索習慣。如今全球用戶通過一個巨大的搜索引擎接入互聯(lián)網,并決定自己下一步會“進入”哪一個網站。
人們或將和這樣的弱AI(智能助理)互動,并將許多的基礎繁雜工作(比如論文出處,寫作業(yè),或是找圖片,做表格等),交予這個能夠理解用戶訴求的人工智能進行處理。
2.高度的拓展性
在足夠巨大的樣本數(shù)訓練以及參數(shù)和標簽下,這樣的工具能夠實現(xiàn)自我學習。
能夠進一步對某些特定需求進行強化,比如說對于金融數(shù)據(jù)的分類整理,或是對于某些交易策略的代碼進行審計或是改bug之類的功能進行強化。
3. 巨大的效率提升
未來人工智能將成為類似搜索引擎,或是手機應用一樣無處不在的重要軟件基礎設施。這也意味著大量重復性的工作(文案,設計類等工作)將被語義模型所訓練的人工智能所替代。
這也意味著我們能夠專心轉向軟件端的框架搭建,創(chuàng)作者也能將旋律,歌詞,作畫等細枝末節(jié)或是其他的作業(yè)完全交給這樣的智能助理chatbot來一鍵式生成。
然而,現(xiàn)階段的ChatGPT更多是一個半完成品,它并不理解我們的需求,或者說這個AI本身并不理解何為”需求“。
更多是根據(jù)我們所輸入的變量和詞語進行反應,或是根據(jù)過去大量的訓練結果進行的回答。
它存在著以下缺點和限制:
1.現(xiàn)階段ChatGPT的本質更多是一個基于語義模型和預訓練的chat bot.
從GPT1到GPT3,AI的訓練數(shù)量甚至到了1750億參數(shù)量之多,這也意味著天價的AI訓練費用(1200萬美金)以及更加巨大的工作量(這也意味著訓練AI將是大量資本交火的主戰(zhàn)場。沒有這么龐大的算力和資本的支持,要開發(fā)這樣的AI簡直不可能。
這同樣也意味著現(xiàn)階段的AI技術仍然在一個成熟商業(yè)化之前的階段。
對于現(xiàn)階段的用戶而言,這個升級成Premium的費用20刀每月的費用更像是我們用戶付費公測參與訓練這個AI bot,然而它是否能創(chuàng)造高于這個費用的價值,現(xiàn)階段我表示懷疑。
2. 預訓練意味著過時的數(shù)據(jù),以及過去的參數(shù),這個AI并不主動吸收新的資訊。
現(xiàn)階段的AI更擅長回答一些非量化并且答案較為固定的一些常識類問題和簡單任務和請求。而且它所具備的參數(shù)和數(shù)據(jù)都是過去的數(shù)據(jù),這些數(shù)據(jù)難以被更新,意味著我們無法通過AI獲得新聞或是最新的數(shù)據(jù)。
或是一些主觀感受型的創(chuàng)作類題目:
比如寫一首押韻的詩歌,有著簡單動人旋律的曲子(大眾流行樂的創(chuàng)作難度遠遠小于你的想象力,作為古典音樂迷可以向你保證)
然而這個AI最具商業(yè)價值的地方,數(shù)據(jù)分析和歸納能力,現(xiàn)階段只是初級的。
其中一個原因在于,這個AI并沒有數(shù)據(jù)處理分析的能力,它僅僅具備的是多語言和語義的分析能力。
對于龐大的如醫(yī)療數(shù)據(jù),或是公共數(shù)據(jù),如果讓這個AI來參與復雜的數(shù)據(jù)整合和決策流程,現(xiàn)階段將是不可能的事。
3. ChatGPT并不具備“記憶功能”,這意味著你先前所詢問的一些問題,GPT無法記住,同時當你重復詢問同樣一個問題,你甚至會獲得截然不同的,甚至是隨機的答案,因為他不‘理解’你的問題。
換而言之,它并不回答你的問題,它只是‘生成答案’。當它回答了一個問題,它同樣也不記得,或是明白自己回答了什么,它只是按照大量的參數(shù)不斷生成你的語義對應的答案。
常識性的問題,它將會具備優(yōu)勢,然而非常識性創(chuàng)作型的問題,它將有非常奇怪的表現(xiàn)。
就像是過去我們玩CS一樣,當游戲程序出現(xiàn)bug,機器人有時候會在一些奇怪的場景里面spawn出來(生成)。
這些答案是大量參數(shù)訓練的結果,其本質是生成的答案。如果有一天我們要在決策領域容納AI作為參考依據(jù),那么這些強AI必須具備理解我們問題的能力。
4. ChatGPT現(xiàn)階段會生成,甚至是偽造許多的reference以及不存在的網址或者生成大量‘不負責任’或是極其隨機的回答。
隨著全球的用戶參與訓練,這也意味著有許多奇奇怪怪的東西將混進來,比如說種族主義的詞匯或者是一些奇怪的異國概念,當這些對話被作為參數(shù)參與訓練AI很可能得到完全無法理解或是預料的結果。
從這個角度來看,如何判斷一個AI究竟是強AI還是弱AI有一個簡單辦法,就是看這個AI會不會問用戶問題。
這才是CHAT的本質,如今的chat bot都是基于用戶的單回饋模型。也就是說用戶問,程序回答,然而真正的CHAT,聊天的過程應該是雙向的,意思是,這個過程也應該包含AI做出反應,甚至提問用戶的行為。
真正的深度的強AI包含了許多其他的參數(shù),比如說提問,情緒,語氣,性格等。
甚至有一天AI能夠理解印度或是東歐的英語口音,然后make fun of it,現(xiàn)階段的載體更多只是文字類的,未來GPT-4的時代,AI將可以對圖片,視頻,語音等不同載體做出反饋。
總的來說,語義模型,預訓練,這些深度學習在內的科技將會給人類帶來巨大轉變。現(xiàn)階段這些技術能夠讓我們讓AI更加像人,或是生成和人相似的行為模式。
在這點上GPT之所以更加像人的原因在于,作為AI,它并不追求答案的正確性,這個角度來看,甚至有些哲學性。
因為經過全球人口,大量交互訓練數(shù)據(jù)所獲得的一個AI,那么想必更像是全球當下的‘用戶畫像’。它將反應一些更加有趣的事實,那就是全球的用戶的意識形態(tài),傾向以及愛好等。
這也是GPT巨大商業(yè)價值的來源,它幾乎是免費的獲取這些用戶的興趣,愛好,以及所有用戶所對應的標簽。
用戶出于自愿將這些帶有個人隱私的數(shù)據(jù)源源不絕地提供給這些chatbot,從這個角度來說,它有機會顛覆tiktok或是FB。現(xiàn)階段它的商用價值更多限于訂閱制。
CHATGPT所提供的服務非常有限,甚至無法被稱為一種服務。作為訂閱方案,我訂閱了兩個月,它所提供的價值不明。但是感覺這筆錢更像是捐獻給OPEN AI基金會,用以改善這個技術。
因為人性,本來就是充滿偏見,或是謬誤的,人和機器的最大區(qū)別,在于變化性和適應性。機器是被創(chuàng)造于滿足一個特定的用途,人工智能是介于機器和人之間的產物。
作為一個‘犯錯’并學習不再犯錯的AI,和一個從不犯錯的AI對比,前者無疑更具備“人”的特征。
但有意思的是,與其說我們看到了一個“像人”的AI,倒不如說我們只是嘗試讓這個程序更像我們自己而已,我們只是通過這個程序反饋出了自己心中的渴望,困惑,以及更多的自己而已。
審核編輯 :李倩
-
AI
+關注
關注
87文章
31516瀏覽量
270333 -
人工智能
+關注
關注
1796文章
47667瀏覽量
240289 -
ChatGPT
+關注
關注
29文章
1568瀏覽量
8061
原文標題:聊一聊現(xiàn)階段ChatGPT的缺點與局限
文章出處:【微信號:alpworks,微信公眾號:阿爾法工場研究院】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
聊一聊-能量管理系統(tǒng)儲能電站
WDM技術的缺點和局限性
聊一聊頻偏和負載電容的計算方法

聊一聊5G路由器相比4G有哪些優(yōu)勢(5g科普)
簡單聊一聊彩色轉灰度的算法

聊一聊啥是“阻抗修正”去嵌入技術
聊一聊“阻抗修正”去嵌入
Simulink自動生成代碼現(xiàn)階段的學習筆記
聊一聊MCU和SoC的區(qū)別
聊一下常見的幾種無線遙控器及其可能使用的晶振頻率
聊一聊Transformer中的FFN
聊一聊|為什么充電樁檢測絕緣電阻呢?

聊一聊短路測試是怎么回事兒
聊一聊芯片的上電復位與掉電檢測





 工商網監(jiān)
工商網監(jiān)
評論