 利用JAVA向Mysql插入一億數量級數據
利用JAVA向Mysql插入一億數量級數據
利用JAVA向Mysql插入一億數量級數據—效率測評
這幾天研究mysql優化中查詢效率時,發現測試的數據太少(10萬級別),利用 EXPLAIN 比較不同的 SQL 語句,不能夠得到比較有效的測評數據,大多模棱兩可,不敢通過這些數據下定論。
所以通過隨機生成人的姓名、年齡、性別、電話、email、地址 ,向mysql數據庫大量插入數據,便于用大量的數據測試 SQL 語句優化效率。、在生成過程中發現使用不同的方法,效率天差萬別。
1、先上Mysql數據庫,隨機生成的人員數據圖。分別是ID、姓名、性別、年齡、Email、電話、住址。
下圖一共三千三百萬數據:
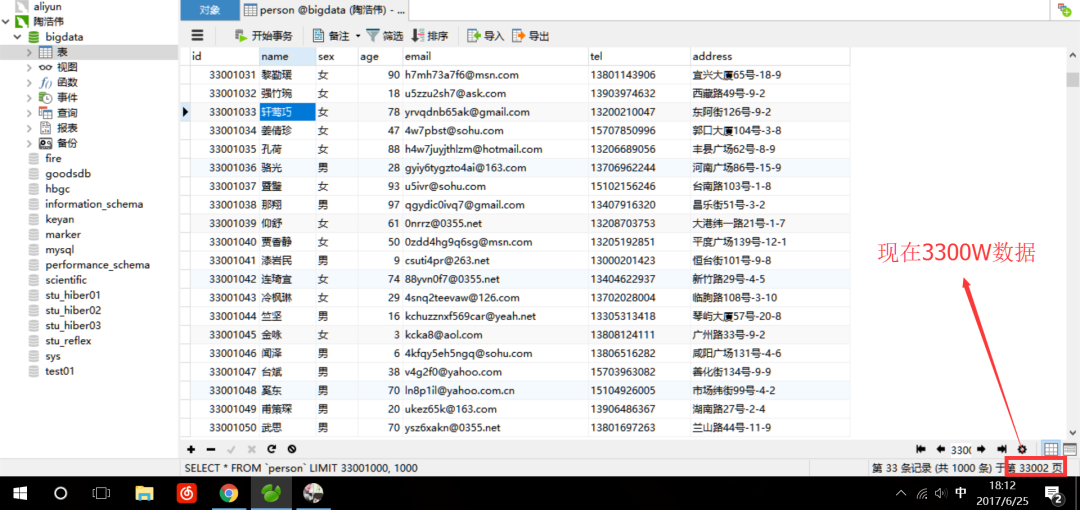
在數據量在億級別時,別點下面按鈕,會導致Navicat持續加載這億級別的數據,導致電腦死機。~覺著自己電腦配置不錯的可以去試試,可能會有驚喜
2、本次測評一共通過三種策略,五種情況,進行大批量數據插入測試
策略分別是:
Mybatis 輕量級框架插入(無事務)
采用JDBC直接處理(開啟事務、無事務)
采用JDBC批處理(開啟事務、無事務)
測試結果:
Mybatis輕量級插入 -> JDBC直接處理 -> JDBC 批處理。
JDBC 批處理,效率最高
第一種策略測試:
2.1 Mybatis 輕量級框架插入(無事務)
Mybatis是一個輕量級框架,它比hibernate輕便、效率高。
但是處理大批量的數據插入操作時,需要過程中實現一個ORM的轉換,本次測試存在實例,以及未開啟事務,導致mybatis效率很一般。
這里實驗內容是:
利用Spring框架生成mapper實例、創建人物實例對象
循環更改該實例對象屬性、并插入。
//代碼內無事務 privatelongbegin=33112001;//起始id privatelongend=begin+100000;//每次循環插入的數據量 privateStringurl="jdbc//localhost:3306/bigdata?useServerPrepStmts=false&rewriteBatchedStatements=true&useUnicode=true&characterEncoding=UTF-8"; privateStringuser="root"; privateStringpassword="0203"; @org.junit.Test publicvoidinsertBigData2() { //加載Spring,以及得到PersonMapper實例對象。這里創建的時間并不對最后結果產生很大的影響 ApplicationContextcontext=newClassPathXmlApplicationContext("applicationContext.xml"); PersonMapperpMapper=(PersonMapper)context.getBean("personMapper"); //創建一個人實例 Personperson=newPerson(); //計開始時間 longbTime=System.currentTimeMillis(); //開始循環,循環次數500W次。 for(inti=0;i<5000000;i++) ????????{ ????????????//為person賦值 ????????????person.setId(i); ????????????person.setName(RandomValue.getChineseName()); ????????????person.setSex(RandomValue.name_sex); ????????????person.setAge(RandomValue.getNum(1,?100)); ????????????person.setEmail(RandomValue.getEmail(4,15)); ????????????person.setTel(RandomValue.getTel()); ????????????person.setAddress(RandomValue.getRoad()); ????????????//執行插入語句 ????????????pMapper.insert(person); ????????????begin++; ????????} ????????//計結束時間 ????????long?eTime?=?System.currentTimeMillis(); ????????System.out.println("插入500W條數據耗時:"+(eTime-bTime)); ????}
本想測試插入五百萬條數據,但是實際運行過程中太慢,中途不得不終止程序。最后得到52W數據,大約耗時兩首歌的時間(7~9分鐘)。隨后,利用mybatis向mysql插入10000數據。
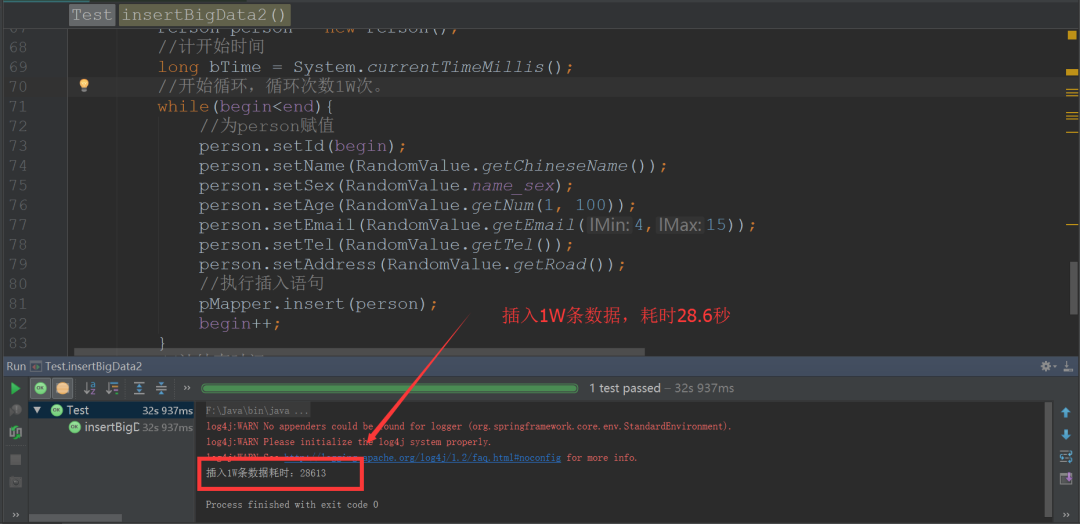
結果如下:
利用mybatis插入 一萬 條數據耗時:28613,即28.6秒
第二種策略測試:
2.2 采用JDBC直接處理(開啟事務、關閉事務)
采用JDBC直接處理的策略,這里的實驗內容分為開啟事務、未開啟事務是兩種,過程均如下:
利用PreparedStatment預編譯
循環,插入對應數據,并存入
事務對于插入數據有多大的影響呢? 看下面的實驗結果:
//該代碼為開啟事務
privatelongbegin=33112001;//起始id
privatelongend=begin+100000;//每次循環插入的數據量
privateStringurl="jdbc//localhost:3306/bigdata?useServerPrepStmts=false&rewriteBatchedStatements=true&useUnicode=true&characterEncoding=UTF-8";
privateStringuser="root";
privateStringpassword="0203";
@org.junit.Test
publicvoidinsertBigData3(){
//定義連接、statement對象
Connectionconn=null;
PreparedStatementpstm=null;
try{
//加載jdbc驅動
Class.forName("com.mysql.jdbc.Driver");
//連接mysql
conn=DriverManager.getConnection(url,user,password);
//將自動提交關閉
conn.setAutoCommit(false);
//編寫sql
Stringsql="INSERTINTOpersonVALUES(?,?,?,?,?,?,?)";
//預編譯sql
pstm=conn.prepareStatement(sql);
//開始總計時
longbTime1=System.currentTimeMillis();
//循環10次,每次一萬數據,一共10萬
for(inti=0;i<10;i++)?{
????????????????//開啟分段計時,計1W數據耗時
????????????????long?bTime?=?System.currentTimeMillis();
????????????????//開始循環
????????????????while?(begin?
1、我們首先利用上述代碼測試無事務狀態下,插入10W條數據需要耗時多少。
如圖:
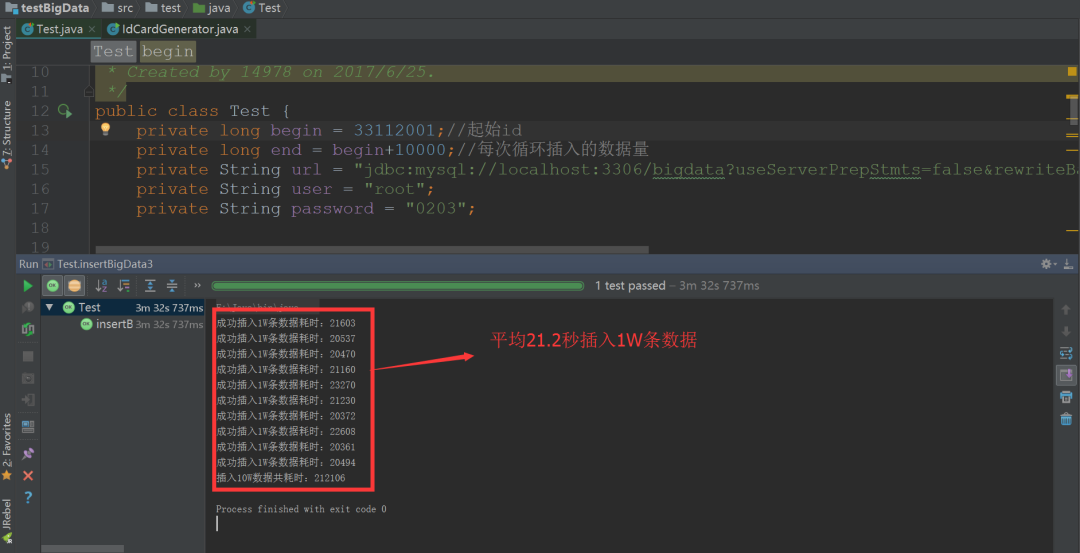
成功插入1W條數據耗時:21603
成功插入1W條數據耗時:20537
成功插入1W條數據耗時:20470
成功插入1W條數據耗時:21160
成功插入1W條數據耗時:23270
成功插入1W條數據耗時:21230
成功插入1W條數據耗時:20372
成功插入1W條數據耗時:22608
成功插入1W條數據耗時:20361
成功插入1W條數據耗時:20494
插入10W數據共耗時:212106
實驗結論如下:
在未開啟事務的情況下,平均每 21.2 秒插入 一萬 數據。
接著我們測試開啟事務后,插入十萬條數據耗時,如圖:
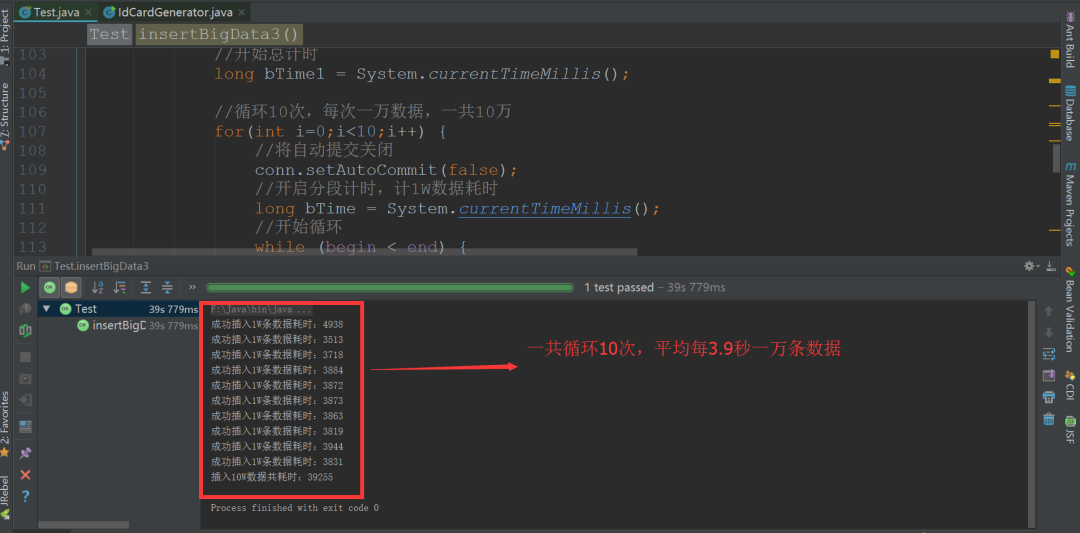
成功插入1W條數據耗時:4938
成功插入1W條數據耗時:3518
成功插入1W條數據耗時:3713
成功插入1W條數據耗時:3883
成功插入1W條數據耗時:3872
成功插入1W條數據耗時:3873
成功插入1W條數據耗時:3863
成功插入1W條數據耗時:3819
成功插入1W條數據耗時:3933
成功插入1W條數據耗時:3811
插入10W數據共耗時:39255
實驗結論如下:
開啟事務后,平均每 3.9 秒插入 一萬 數據
第三種策略測試:
2.3 采用JDBC批處理(開啟事務、無事務)
采用JDBC批處理時需要注意一下幾點:
1、在URL連接時需要開啟批處理、以及預編譯
Stringurl=“jdbc//localhost:3306/User?rewriteBatched
-Statements=true&useServerPrepStmts=false”;
2、PreparedStatement預處理sql語句必須放在循環體外
代碼如下:
privatelongbegin=33112001;//起始id
privatelongend=begin+100000;//每次循環插入的數據量
privateStringurl="jdbc//localhost:3306/bigdata?useServerPrepStmts=false&rewriteBatchedStatements=true&useUnicode=true&characterEncoding=UTF-8";
privateStringuser="root";
privateStringpassword="0203";
@org.junit.Test
publicvoidinsertBigData(){
//定義連接、statement對象
Connectionconn=null;
PreparedStatementpstm=null;
try{
//加載jdbc驅動
Class.forName("com.mysql.jdbc.Driver");
//連接mysql
conn=DriverManager.getConnection(url,user,password);
//將自動提交關閉
//conn.setAutoCommit(false);
//編寫sql
Stringsql="INSERTINTOpersonVALUES(?,?,?,?,?,?,?)";
//預編譯sql
pstm=conn.prepareStatement(sql);
//開始總計時
longbTime1=System.currentTimeMillis();
//循環10次,每次十萬數據,一共1000萬
for(inti=0;i<10;i++)?{
????????????//開啟分段計時,計1W數據耗時
????????????long?bTime?=?System.currentTimeMillis();
????????????//開始循環
????????????while?(begin?
首先開始測試
無事務,每次循環插入10W條數據,循環10次,一共100W條數據。
結果如下圖:
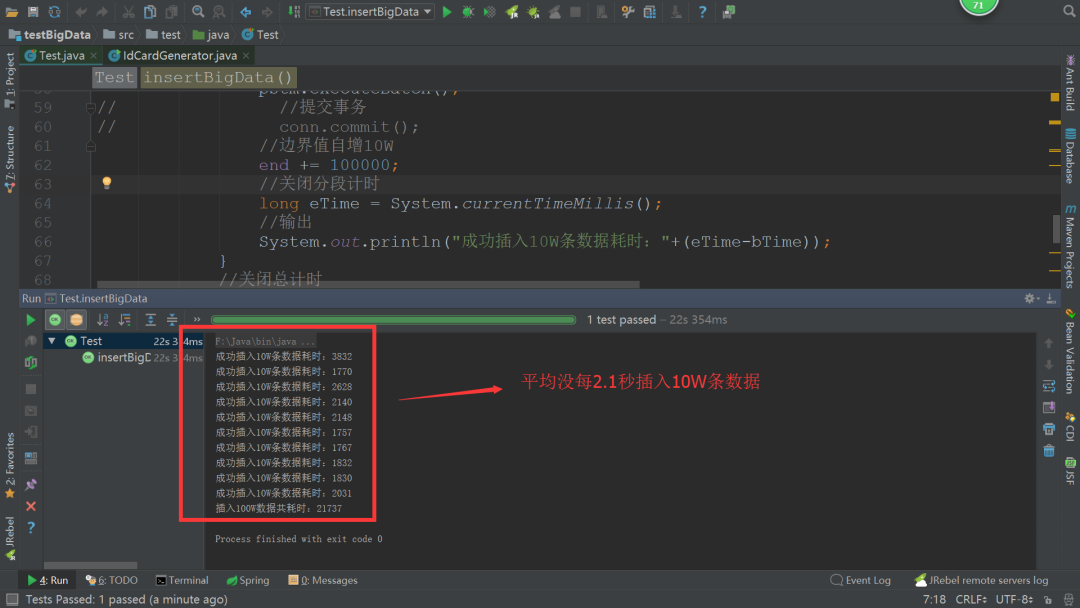
成功插入10W條數據耗時:3832
成功插入10W條數據耗時:1770
成功插入10W條數據耗時:2628
成功插入10W條數據耗時:2140
成功插入10W條數據耗時:2148
成功插入10W條數據耗時:1757
成功插入10W條數據耗時:1767
成功插入10W條數據耗時:1832
成功插入10W條數據耗時:1830
成功插入10W條數據耗時:2031
插入100W數據共耗時:21737
實驗結果:
使用JDBC批處理,未開啟事務下,平均每 2.1 秒插入 十萬 條數據
接著測試
開啟事務,每次循環插入10W條數據,循環10次,一共100W條數據。
結果如下圖:
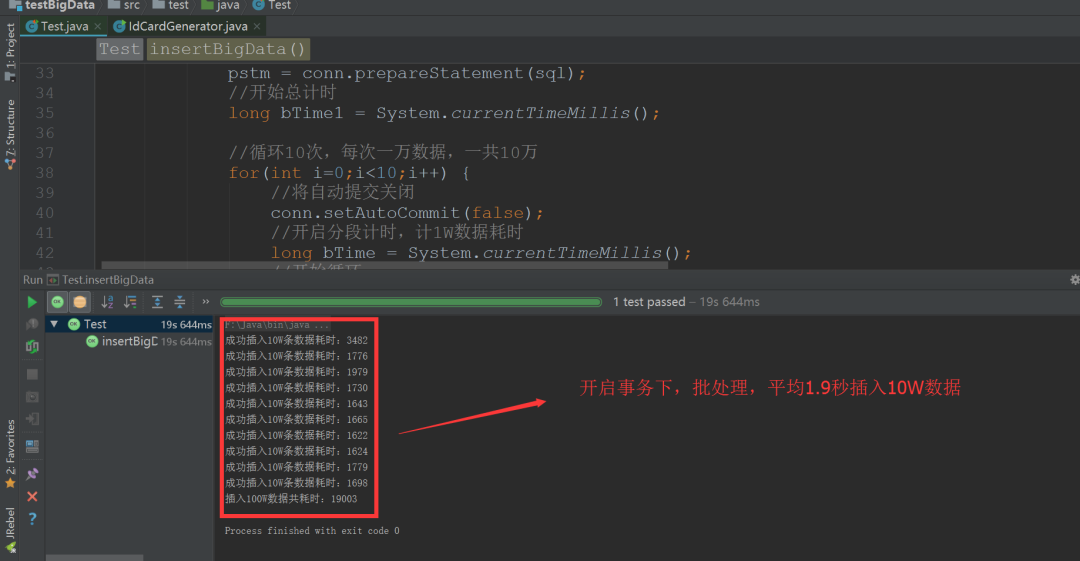
成功插入10W條數據耗時:3482
成功插入10W條數據耗時:1776
成功插入10W條數據耗時:1979
成功插入10W條數據耗時:1730
成功插入10W條數據耗時:1643
成功插入10W條數據耗時:1665
成功插入10W條數據耗時:1622
成功插入10W條數據耗時:1624
成功插入10W條數據耗時:1779
成功插入10W條數據耗時:1698
插入100W數據共耗時:19003
實驗結果:
使用JDBC批處理,開啟事務,平均每 1.9 秒插入 十萬 條數據
3 總結
能夠看到,在開啟事務下 JDBC直接處理 和 JDBC批處理 均耗時更短。
Mybatis 輕量級框架插入 , mybatis在我這次實驗被黑的可慘了,哈哈。實際開啟事務以后,差距不會這么大(差距10倍)。大家有興趣的可以接著去測試
JDBC直接處理,在本次實驗,開啟事務和關閉事務,耗時差距5倍左右,并且這個倍數會隨著數據量的增大而增大。因為在未開啟事務時,更新10000條數據,就得訪問數據庫10000次。導致每次操作都需要操作一次數據庫。
JDBC批處理,在本次實驗,開啟事務與關閉事務,耗時差距很微小(后面會增加測試,加大這個數值的差距)。但是能夠看到開啟事務以后,速度還是有提升。
結論:設計到大量單條數據的插入,使用JDBC批處理和事務混合速度最快
實測使用批處理+事務混合插入1億條數據耗時:174756毫秒
4 補充
JDBC批處理事務,開啟和關閉事務,測評插入20次,一次50W數據,一共一千萬數據耗時:
1、開啟事務(數據太長不全貼了)
插入1000W數據共耗時:197654
2、關閉事務(數據太長不全貼了)
插入1000W數據共耗時:200540
還是沒很大的差距~
借用:
分別是:
不用批處理,不用事務;
只用批處理,不用事務;
只用事務,不用批處理;
既用事務,也用批處理;(很明顯,這個最快,所以建議在處理大批量的數據時,同時使用批處理和事務)
審核編輯:劉清
-
JAVA
+關注
關注
19文章
2973瀏覽量
104872 -
SQL
+關注
關注
1文章
768瀏覽量
44177 -
JDBC
+關注
關注
0文章
25瀏覽量
13414 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9414
原文標題:1億條數據批量插入 MySQL,哪種方式最快?
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用JAVA向Mysql插入一億數量級數據—效率測評
使用tina測量opa227的輸入失調電壓和失調電流,結果數量級和手冊標準值差很多,為什么?
0基礎學Mysql:mysql入門視頻教程!
使用Matlab捕獲N9010A跟蹤數據縮放了幾個數量級
請問AD9361跳頻穩定時間是一個什么數量級?
開關電源的NTC阻值一般是什么數量級的?
如何實現處理器的速度跟外圍硬件設備的速度在一個數量級上呢
深度剖析OpenHarmony輕量級數據存儲
中國電子系統2天時間建設蘇州市疫情管控平臺 可同時支持10萬數量級企業及1000萬數量級員工的活動軌跡分析
MySQL數據庫:如何操作禁止重復插入數據






 工商網監
工商網監
評論