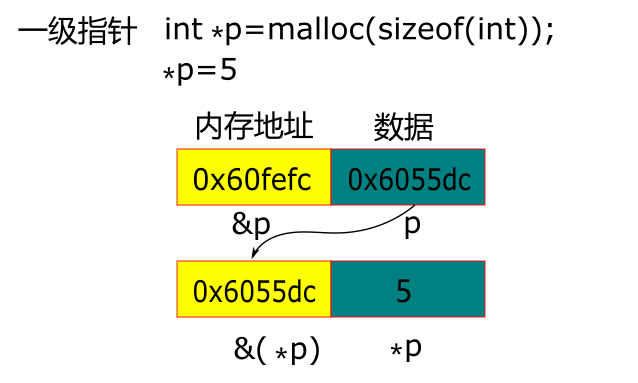
") 詳解C語(yǔ)言指針底層基本原理
詳解C語(yǔ)言指針底層基本原理
說(shuō)到指針,估計(jì)還是有很多小伙伴都還是云里霧里的,有點(diǎn)“知其然,而不知其所以然”。但是,不得不說(shuō),學(xué)了指針,C語(yǔ)言才能算是入門(mén)了。指針是C語(yǔ)言的「精華」,可以說(shuō),對(duì)對(duì)指針的掌握程度,「直接決定」了你C語(yǔ)言的編程能力。
在講指針之前,我們先來(lái)了解下變量在「內(nèi)存」中是如何存放的。
在程序中定義一個(gè)變量,那么在程序編譯的過(guò)程中,系統(tǒng)會(huì)根據(jù)你定義變量的類(lèi)型來(lái)分配「相應(yīng)尺寸」的內(nèi)存空間。那么如果要使用這個(gè)變量,只需要用變量名去訪問(wèn)即可。
通過(guò)變量名來(lái)訪問(wèn)變量,是一種「相對(duì)安全」的方式。因?yàn)橹挥心愣x了它,你才能夠訪問(wèn)相應(yīng)的變量。這就是對(duì)內(nèi)存的基本認(rèn)知。但是,如果光知道這一點(diǎn)的話,其實(shí)你還是不知道內(nèi)存是如何存放變量的,因?yàn)榈讓邮侨绾喂ぷ鞯模阋琅f不清楚。
那么如果要繼續(xù)深究的話,你就需要把變量在內(nèi)存中真正的樣子是什么搞清楚。內(nèi)存的最小索引單元是1字節(jié),那么你其實(shí)可以把內(nèi)存比作一個(gè)超級(jí)大的「字符型數(shù)組」。在上一節(jié)我們講過(guò),數(shù)組是有下標(biāo)的,我們是通過(guò)數(shù)組名和下標(biāo)來(lái)訪問(wèn)數(shù)組中的元素。那么內(nèi)存也是一樣,只不過(guò)我們給它起了個(gè)新名字:地址。每個(gè)地址可以存放「1字節(jié)」的數(shù)據(jù),所以如果我們需要定義一個(gè)整型變量,就需要占據(jù)4個(gè)內(nèi)存單元。
那么,看到這里你可能就明白了:其實(shí)在程序運(yùn)行的過(guò)程中,完全不需要變量名的參與。變量名只是方便我們進(jìn)行代碼的編寫(xiě)和閱讀,只有程序員和編譯器知道這個(gè)東西的存在。而編譯器還知道具體的變量名對(duì)應(yīng)的「內(nèi)存地址」,這個(gè)是我們不知道的,因此編譯器就像一個(gè)橋梁。當(dāng)讀取某一個(gè)變量的時(shí)候,編譯器就會(huì)找到變量名所對(duì)應(yīng)的地址,讀取對(duì)應(yīng)的值。
初識(shí)指針和指針變量
那么我們現(xiàn)在就來(lái)切入正題,指針是個(gè)什么東西呢?
所謂指針,就是內(nèi)存地址(下文簡(jiǎn)稱(chēng)地址)。C語(yǔ)言中設(shè)立了專(zhuān)門(mén)的「指針變量」來(lái)存儲(chǔ)指針,和「普通變量」不一樣的是,指針變量存儲(chǔ)的是「地址」。
定義指針
指針變量也有類(lèi)型,實(shí)際上取決于地址指向的值的類(lèi)型。那么如何定義指針變量呢:
很簡(jiǎn)單:類(lèi)型名* 指針變量名
char*pa;//定義一個(gè)字符變量的指針,名稱(chēng)為pa
int*pb;//定義一個(gè)整型變量的指針,名稱(chēng)為pb
float*pc;//定義一個(gè)浮點(diǎn)型變量的指針,名稱(chēng)為pc
注意,指針變量一定要和指向的變量的類(lèi)型一樣,不然類(lèi)型不同可能在內(nèi)存中所占的位置不同,如果定義錯(cuò)了就可能導(dǎo)致出錯(cuò)。
取地址運(yùn)算符和取值運(yùn)算符
獲取某個(gè)變量的地址,使用取地址運(yùn)算符&,如:
char*pa=&a;
int*pb=&f;
如果反過(guò)來(lái),你要訪問(wèn)指針變量指向的數(shù)據(jù),那么你就要使用取值運(yùn)算符*,如:
printf("%c,%d ",*pa,*pb);
這里你可能發(fā)現(xiàn),定義指針的時(shí)候也使用了*,這里屬于符號(hào)的「重用」,也就是說(shuō)這種符號(hào)在不同的地方就有不同的用意:在定義的時(shí)候表示「定義一個(gè)指針變量」,在其他的時(shí)候則用來(lái)「獲取指針變量指向的變量的值」。
直接通過(guò)變量名來(lái)訪問(wèn)變量的值稱(chēng)之為直接訪問(wèn),通過(guò)指針這樣的形式訪問(wèn)稱(chēng)之為間接訪問(wèn),因此取值運(yùn)算符有時(shí)候也成為「間接運(yùn)算符」。
比如:
//Example01
//代碼來(lái)源于網(wǎng)絡(luò),非個(gè)人原創(chuàng)
#include
intmain(void)
{
chara='f';
intf=123;
char*pa=&a;
int*pf=&f;
printf("a=%c ",*pa);
printf("f=%d ",*pf);
*pa='c';
*pf+=1;
printf("now,a=%c ",*pa);
printf("now,f=%d ",*pf);
printf("sizeofpa=%d ",sizeof(pa));
printf("sizeofpf=%d ",sizeof(pf));
printf("theaddrofais:%p ",pa);
printf("theaddroffis:%p ",pf);
return0;
}
程序?qū)崿F(xiàn)如下:
//Consequence 01
a = f
f = 123
now, a = c
now, f = 124
sizeof pa = 4
sizeof pf = 4
the addr of a is: 00EFF97F
the addr of f is: 00EFF970
避免訪問(wèn)未初始化的指針
voidf()
{
int*a;
*a=10;
}
像這樣的代碼是十分危險(xiǎn)的。因?yàn)橹羔榓到底指向哪里,我們不知道。就和訪問(wèn)未初始化的普通變量一樣,會(huì)返回一個(gè)「隨機(jī)值」。
但是如果是在指針里面,那么就有可能覆蓋到「其他的內(nèi)存區(qū)域」,甚至可能是系統(tǒng)正在使用的「關(guān)鍵區(qū)域」,十分危險(xiǎn)。不過(guò)這種情況,系統(tǒng)一般會(huì)駁回程序的運(yùn)行,此時(shí)程序會(huì)被「中止」并「報(bào)錯(cuò)」。
要是萬(wàn)一中獎(jiǎng)的話,覆蓋到一個(gè)合法的地址,那么接下來(lái)的賦值就會(huì)導(dǎo)致一些有用的數(shù)據(jù)被「莫名其妙地修改」,這樣的bug是十分不好排查的,因此使用指針的時(shí)候一定要注意初始化。
指針和數(shù)組
有些讀者可能會(huì)有些奇怪,指針和數(shù)組又有什么關(guān)系?這倆貨明明八竿子打不著井水不犯河水。別著急,接著往下看,你的觀點(diǎn)有可能會(huì)改變。
數(shù)組的地址
我們剛剛說(shuō)了,指針實(shí)際上就是變量在「內(nèi)存中的地址」,那么如果有細(xì)心的小伙伴就可能會(huì)想到,像數(shù)組這樣的一大摞變量的集合,它的地址是啥呢?
我們知道,從標(biāo)準(zhǔn)輸入流中讀取一個(gè)值到變量中,用的是scanf函數(shù),一般貌似在后面都要加上&,這個(gè)其實(shí)就是我們剛剛說(shuō)的「取地址運(yùn)算符」。如果你存儲(chǔ)的位置是指針變量的話,那就不需要。
//Example02
intmain(void)
{
inta;
int*p=&a;
printf("請(qǐng)輸入一個(gè)整數(shù):");
scanf("%d",&a);//此處需要&
printf("a=%d ",a);
printf("請(qǐng)?jiān)佥斎胍粋€(gè)整數(shù):");
scanf("%d",p);//此處不需要&
printf("a=%d ",a);
return0;
}
程序運(yùn)行如下:
//Consequence 02
請(qǐng)輸入一個(gè)整數(shù):1
a = 1
請(qǐng)?jiān)佥斎胍粋€(gè)整數(shù):2
a = 2
在普通變量讀取的時(shí)候,程序需要知道這個(gè)變量在內(nèi)存中的地址,因此需要&來(lái)取地址完成這個(gè)任務(wù)。而對(duì)于指針變量來(lái)說(shuō),本身就是「另外一個(gè)」普通變量的「地址信息」,因此直接給出指針的值就可以了。
試想一下,我們?cè)谑褂胹canf函數(shù)的時(shí)候,是不是也有不需要使用&的時(shí)候?就是在讀取「字符串」的時(shí)候:
//Example03
#include
intmain(void)
{
charurl[100];
url[99]='?';
printf("請(qǐng)輸入TechZone的域名:");
scanf("%s",url);//此處也不用&
printf("你輸入的域名是:%s ",url);
return0;
}
程序執(zhí)行如下:
//Consequence 03
請(qǐng)輸入TechZone的域名:www.techzone.ltd
你輸入的域名是:www.techzone.ltd
因此很好推理:數(shù)組名其實(shí)就是一個(gè)「地址信息」,實(shí)際上就是數(shù)組「第一個(gè)元素的地址」。
咱們?cè)囋嚢训谝粋€(gè)元素的地址和數(shù)組的地址做個(gè)對(duì)比就知道了:
//Example03V2
#include
intmain(void)
{
charurl[100];
printf("請(qǐng)輸入TechZone的域名:");
url[99]='?';
scanf("%s",url);
printf("你輸入的域名是:%s ",url);
printf("url的地址為:%p ",url);
printf("url[0]的地址為:%p ",&url[0]);
if(url==&url[0])
{
printf("兩者一致!");
}
else
{
printf("兩者不一致!");
}
return0;
}
程序運(yùn)行結(jié)果為:
//Comsequense 03 V2
請(qǐng)輸入TechZone的域名:www.techzone.ltd
你輸入的域名是:www.techzone.ltd
url的地址為:0063F804
url[0]的地址為:0063F804
兩者一致!
這么看,應(yīng)該是實(shí)錘了。那么數(shù)組后面的元素也就是依次往后放置,有興趣的也可以自己寫(xiě)代碼嘗試把它們輸出看看。
指向數(shù)組的指針
剛剛我們驗(yàn)證了數(shù)組的地址就是數(shù)組第一個(gè)元素的地址。那么指向數(shù)組的指針自然也就有兩種定義的方法:
...
char*p;
//方法1
p=a;
//方法2
p=&a[0];
指針的運(yùn)算
當(dāng)指針指向數(shù)組元素的時(shí)候,可以對(duì)指針變量進(jìn)行「加減」運(yùn)算,+n表示指向p指針?biāo)赶虻脑氐?strong>「下n個(gè)元素」,-n表示指向p指針?biāo)赶虻脑氐?strong>「上n個(gè)元素」。并不是將地址加1。
如:
//Example04
#include
intmain(void)
{
inta[]={1,2,3,4,5};
int*p=a;
printf("*p=%d,*(p+1)=%d,*(p+2)=%d ",*p,*(p+1),*(p+2));
printf("*p->%p,*(p+1)->%p,*(p+2)->%p ",p,p+1,p+2);
return0;
}
執(zhí)行結(jié)果如下:
//Consequence 04
*p = 1, *(p+1) = 2, *(p+2) = 3
*p -> 00AFF838, *(p+1) -> 00AFF83C, *(p+2) -> 00AFF840
有的小伙伴可能會(huì)想,編譯器是怎么知道訪問(wèn)下一個(gè)元素而不是地址直接加1呢?
其實(shí)就在我們定義指針變量的時(shí)候,就已經(jīng)告訴編譯器了。如果我們定義的是整型數(shù)組的指針,那么指針加1,實(shí)際上就是加上一個(gè)sizeof(int)的距離。相對(duì)于標(biāo)準(zhǔn)的下標(biāo)訪問(wèn),使用指針來(lái)間接訪問(wèn)數(shù)組元素的方法叫做指針?lè)ā?/p>
其實(shí)使用指針?lè)▉?lái)訪問(wèn)數(shù)組的元素,不一定需要定義一個(gè)指向數(shù)組的單獨(dú)的指針變量,因?yàn)閿?shù)組名自身就是指向數(shù)組「第一個(gè)元素」的指針,因此指針?lè)梢灾苯幼饔糜跀?shù)組名:
...
printf("p->%p,p+1->%p,p+2->%p ",a,a+1,a+2);
printf("a=%d,a+1=%d,a+2=%d",*a,*(a+1),*(a+2));
...
執(zhí)行結(jié)果如下:
p->00AFF838,p+1->00AFF83C,p+2->00AFF840
b=1,b+1=2,b+2=3
現(xiàn)在你是不是感覺(jué),數(shù)組和指針有點(diǎn)像了呢?不過(guò)筆者先提醒,數(shù)組和指針雖然非常像,但是絕對(duì)「不是」一種東西。
甚至你還可以直接用指針來(lái)定義字符串,然后用下標(biāo)法來(lái)讀取每一個(gè)元素:
//Example05
//代碼來(lái)源于網(wǎng)絡(luò)
#include
#include
intmain(void)
{
char*str="IloveTechZone!";
inti,length;
length=strlen(str);
for(i=0;i
{
printf("%c",str[i]);
}
printf(" ");
return0;
}
程序運(yùn)行如下:
//Consequence 05
I love TechZone!
在剛剛的代碼里面,我們定義了一個(gè)「字符指針」變量,并且初始化成指向一個(gè)字符串。后來(lái)的操作,不僅在它身上可以使用「字符串處理函數(shù)」,還可以用「下標(biāo)法」訪問(wèn)字符串中的每一個(gè)字符。
當(dāng)然,循環(huán)部分這樣寫(xiě)也是沒(méi)毛病的:
...
for(i=0,i
{
printf("%c",*(str+i));
}
這就相當(dāng)于利用了指針?lè)▉?lái)讀取。
指針和數(shù)組的區(qū)別
剛剛說(shuō)了許多指針和數(shù)組相互替換的例子,可能有的小伙伴又開(kāi)始說(shuō):“這倆貨不就是一個(gè)東西嗎?”
隨著你對(duì)指針和數(shù)組越來(lái)越了解,你會(huì)發(fā)現(xiàn),C語(yǔ)言的創(chuàng)始人不會(huì)這么無(wú)聊去創(chuàng)建兩種一樣的東西,還叫上不同的名字。指針和數(shù)組終究是「不一樣」的。
比如筆者之前看過(guò)的一個(gè)例子:
//Example06
//代碼來(lái)源于網(wǎng)絡(luò)
#include
intmain(void)
{
charstr[]="IloveTechZone!";
intcount=0;
while(*str++!='?')
{
count++;
}
printf("總共有%d個(gè)字符。 ",count);
return0;
}
當(dāng)編譯器報(bào)錯(cuò)的時(shí)候,你可能會(huì)開(kāi)始懷疑你學(xué)了假的C語(yǔ)言語(yǔ)法:
//Error in Example 06
錯(cuò)誤(活動(dòng))E0137表達(dá)式必須是可修改的左值
錯(cuò)誤C2105“++”需要左值
我們知道,*str++ != ‘?’是一個(gè)復(fù)合表達(dá)式,那么就要遵循「運(yùn)算符優(yōu)先級(jí)」來(lái)看。具體可以回顧《C語(yǔ)言運(yùn)算符優(yōu)先級(jí)及ASCII對(duì)照表》。
str++比*str的優(yōu)先級(jí)「更高」,但是自增運(yùn)算符要在「下一條語(yǔ)句」的時(shí)候才能生效。所以這個(gè)語(yǔ)句的理解就是,先取出str所指向的值,判斷是否為?,若是,則跳出循環(huán),然后str指向下一個(gè)字符的位置。
看上去貌似沒(méi)啥毛病,但是,看看編譯器告訴我們的東西:表達(dá)式必須是可修改的左值
++的操作對(duì)象是str,那么str到底是不是「左值」呢?
如果是左值的話,那么就必須滿足左值的條件。
?
擁有用于識(shí)別和定位一個(gè)存儲(chǔ)位置的標(biāo)識(shí)符
存儲(chǔ)值可修改
?
第一點(diǎn),數(shù)組名str是可以滿足的,因?yàn)閿?shù)組名實(shí)際上就是定位數(shù)組第一個(gè)元素的位置。但是第二點(diǎn)就不滿足了,數(shù)組名實(shí)際上是一個(gè)地址,地址是「不可以」修改的,它是一個(gè)常量。如果非要利用上面的思路來(lái)實(shí)現(xiàn)的話,可以將代碼改成這樣:
//Example06V2
//代碼來(lái)源于網(wǎng)絡(luò)
#include
intmain(void)
{
charstr[]="IloveTechZone!";
char*target=str;
intcount=0;
while(*target++!='?')
{
count++;
}
printf("總共有%d個(gè)字符。 ",count);
return0;
}
這樣就可以正常執(zhí)行了:
//Consequence 06 V2
總共有16個(gè)字符。
這樣我們就可以得出:數(shù)組名只是一個(gè)「地址」,而指針是一個(gè)「左值」。
指針數(shù)組?數(shù)組指針?
看下面的例子,你能分辨出哪個(gè)是指針數(shù)組,哪個(gè)是數(shù)組指針嗎?
int*p1[5];
int(*p2)[5];
單個(gè)的我們都可以判斷,但是組合起來(lái)就有些難度了。
答案:
int*p1[5];//指針數(shù)組
int(*p2)[5];//數(shù)組指針
我們挨個(gè)來(lái)分析。
指針數(shù)組
數(shù)組下標(biāo)[]的優(yōu)先級(jí)是最高的,因此p1是一個(gè)有5個(gè)元素的「數(shù)組」。那么這個(gè)數(shù)組的類(lèi)型是什么呢?答案就是int*,是「指向整型變量的指針」。因此這是一個(gè)「指針數(shù)組」。
那么這樣的數(shù)組應(yīng)該怎么樣去初始化呢?
你可以定義5個(gè)變量,然后挨個(gè)取地址來(lái)初始化。
不過(guò)這樣太繁瑣了,但是,并不是說(shuō)指針數(shù)組就沒(méi)什么用。
比如:
//Example07
#include
intmain(void)
{
char*p1[5]={
"人生苦短,我用Python。",
"PHP是世界上最好的語(yǔ)言!",
"Onemorething...",
"一個(gè)好的程序員應(yīng)該是那種過(guò)單行線都要往兩邊看的人。",
"C語(yǔ)言很容易讓你犯錯(cuò)誤;C++看起來(lái)好一些,但當(dāng)你用它時(shí),你會(huì)發(fā)現(xiàn)會(huì)死的更慘。"
};
inti;
for(i=0;i
{
printf("%s ",p1[i]);
}
return0;
}
結(jié)果如下:
//Consequence 07
人生苦短,我用Python。
PHP是世界上最好的語(yǔ)言!
One more thing...
一個(gè)好的程序員應(yīng)該是那種過(guò)單行線都要往兩邊看的人。
C語(yǔ)言很容易讓你犯錯(cuò)誤;C++看起來(lái)好一些,但當(dāng)你用它時(shí),你會(huì)發(fā)現(xiàn)會(huì)死的更慘。
這樣是不是比二維數(shù)組來(lái)的更加直接更加通俗呢?
數(shù)組指針
()和[]在優(yōu)先級(jí)里面屬于「同級(jí)」,那么就按照「先后順序」進(jìn)行。
int(*p2)將p2定義為「指針」, 后面跟隨著一個(gè)5個(gè)元素的「數(shù)組」,p2就指向這個(gè)數(shù)組。因此,數(shù)組指針是一個(gè)「指針」,它指向的是一個(gè)數(shù)組。
但是,如果想對(duì)數(shù)組指針初始化的時(shí)候,千萬(wàn)要小心,比如:
//Example08
#include
intmain(void)
{
int(*p2)[5]={1,2,3,4,5};
inti;
for(i=0;i
{
printf("%d ",*(p2+i));
}
return0;
}
Visual Studio 2019報(bào)出以下的錯(cuò)誤:
//Error and Warning in Example 08
錯(cuò)誤(活動(dòng))E0146初始值設(shè)定項(xiàng)值太多
錯(cuò)誤C2440“初始化”: 無(wú)法從“initializer list”轉(zhuǎn)換為“int (*)[5]”
警告C4477“printf”: 格式字符串“%d”需要類(lèi)型“int”的參數(shù),但可變參數(shù) 1 擁有了類(lèi)型“int *”
這其實(shí)是一個(gè)非常典型的錯(cuò)誤使用指針的案例,編譯器提示說(shuō)這里有一個(gè)「整數(shù)」賦值給「指針變量」的問(wèn)題,因?yàn)閜2歸根結(jié)底還是指針,所以應(yīng)該給它傳遞一個(gè)「地址」才行,更改一下:
//Example08V2
#include
intmain(void)
{
inttemp[5]={1,2,3,4,5};
int(*p2)[5]=temp;
inti;
for(i=0;i
{
printf("%d ",*(p2+i));
}
return0;
} //Error and Warning in Example 08 V2
錯(cuò)誤(活動(dòng))E0144"int *" 類(lèi)型的值不能用于初始化 "int (*)[5]" 類(lèi)型的實(shí)體
錯(cuò)誤C2440“初始化”: 無(wú)法從“int [5]”轉(zhuǎn)換為“int (*)[5]”
警告C4477“printf”: 格式字符串“%d”需要類(lèi)型“int”的參數(shù),但可變參數(shù) 1 擁有了類(lèi)型“int *”
可是怎么還是有問(wèn)題呢?
我們回顧一下,指針是如何指向數(shù)組的。
inttemp[5]={1,2,3,4,5};
int*p=temp;
我們?cè)疽詾椋羔榩是指向數(shù)組的指針,但是實(shí)際上「并不是」。仔細(xì)想想就會(huì)發(fā)現(xiàn),這個(gè)指針實(shí)際上是指向的數(shù)組的「第一個(gè)元素」,而不是指向數(shù)組。因?yàn)閿?shù)組里面的元素在內(nèi)存中都是挨著個(gè)兒存放的,因此只需要知道第一個(gè)元素的地址,就可以訪問(wèn)到后面的所有元素。
但是,這么來(lái)看的話,指針p指向的就是一個(gè)「整型變量」的指針,并不是指向「數(shù)組」的指針。而剛剛我們用的數(shù)組指針,才是指向數(shù)組的指針。因此,應(yīng)該將「數(shù)組的地址」傳遞給數(shù)組指針,而不是將第一個(gè)元素的地址傳入,盡管它們值相同,但是「含義」確實(shí)不一樣:
//Example08V3
//Example08V2
#include
intmain(void)
{
inttemp[5]={1,2,3,4,5};
int(*p2)[5]=&temp;//此處取地址
inti;
for(i=0;i
{
printf("%d ",*(*p2+i));
}
return0;
}
程序運(yùn)行如下:
//Consequence 08
1
2
3
4
5
指針和二維數(shù)組
在上一節(jié)《C語(yǔ)言之?dāng)?shù)組》我們講過(guò)「二維數(shù)組」的概念,并且我們也知道,C語(yǔ)言的二維數(shù)組其實(shí)在內(nèi)存中也是「線性存放」的。
假設(shè)我們定義了:int array[4][5]
array
array作為數(shù)組的名稱(chēng),顯然應(yīng)該表示的是數(shù)組的「首地址」。由于二維數(shù)組實(shí)際上就是一維數(shù)組的「線性拓展」,因此array應(yīng)該就是指的指向包含5個(gè)元素的數(shù)組的指針。
如果你用sizeof()去測(cè)試array和array+1的話,就可以測(cè)試出來(lái)這樣的結(jié)論。
*(array+1)
首先從剛剛的問(wèn)題我們可以得出,array+1同樣也是指的指向包含5個(gè)元素的數(shù)組的指針,因此*(array+1)就是相當(dāng)于array[1],而這剛好相當(dāng)于array[1][0]的數(shù)組名。因此*(array+1)就是指第二行子數(shù)組的第一個(gè)元素的地址。
*(*(array+1)+2)
有了剛剛的結(jié)論,我們就不難推理出,這個(gè)實(shí)際上就是array[1][2]。是不是感覺(jué)非常簡(jiǎn)單呢?
總結(jié)一下,就是下面的這些結(jié)論,記住就好,理解那當(dāng)然更好:
*(array+i)==array[i]
*(*(array+i)+j)==array[i][j]
*(*(*(array+i)+j)+k)==array[i][j][k]
...
數(shù)組指針和二維數(shù)組
我們?cè)谏弦还?jié)里面講過(guò),在初始化二維數(shù)組的時(shí)候是可以偷懶的:
intarray[][3]={
{1,2,3},
{4,5,6}
};
剛剛我們又說(shuō)過(guò),定義一個(gè)數(shù)組指針是這樣的:
int(*p)[3];
那么組合起來(lái)是什么意思呢?
int(*p)[3]=array;
通過(guò)剛剛的說(shuō)明,我們可以知道,array是指向一個(gè)3個(gè)元素的數(shù)組的「指針」,所以這里完全可以將array的值賦值給p。
其實(shí)C語(yǔ)言的指針?lè)浅l`活,同樣的代碼用不同的角度去解讀,就可以有不同的應(yīng)用。
那么如何使用指針來(lái)訪問(wèn)二維數(shù)組呢?沒(méi)錯(cuò),就是使用「數(shù)組指針」:
//Example09
#include
intmain(void)
{
intarray[3][4]={
{0,1,2,3},
{4,5,6,7},
{8,9,10,11}
};
int(*p)[4];
inti,j;
p=array;
for(i=0,i
{
for(j=0,j
{
printf("%2d",*(*(p+i)+j));
}
printf(" ");
}
return0;
}
運(yùn)行結(jié)果:
//Consequence 09
0 1 2 3
4 5 6 7
8 9 10 11
void指針
void實(shí)際上是無(wú)類(lèi)型的意思。如果你嘗試用它來(lái)定義一個(gè)變量,編譯器肯定會(huì)「報(bào)錯(cuò)」,因?yàn)椴煌?lèi)型所占用的內(nèi)存有可能「不一樣」。但是如果定義的是一個(gè)指針,那就沒(méi)問(wèn)題。void類(lèi)型中指針可以指向「任何一個(gè)類(lèi)型」的數(shù)據(jù),也就是說(shuō),任何類(lèi)型的指針都可以賦值給void指針。
將任何類(lèi)型的指針轉(zhuǎn)換為void是沒(méi)有問(wèn)題的。但是如果你要反過(guò)來(lái),那就需要「強(qiáng)制類(lèi)型轉(zhuǎn)換」。此外,不要對(duì)void指針「直接解引用」,因?yàn)榫幾g器其實(shí)并不知道void指針會(huì)存放什么樣的類(lèi)型。
//Example10
#include
intmain(void)
{
intnum=1024;
int*pi=#
char*ps="TechZone";
void*pv;
pv=pi;
printf("pi:%p,pv:%p ",pi,pv);
printf("*pv:%d ",*pv);
pv=ps;
printf("ps:%p,pv:%p ",ps,pv);
printf("*pv:%s ",*pv);
}
這樣會(huì)報(bào)錯(cuò):
//Error in Example 10
錯(cuò)誤C2100非法的間接尋址
錯(cuò)誤C2100非法的間接尋址
如果一定要這么做,那么可以用「強(qiáng)制類(lèi)型轉(zhuǎn)換」:
//Example10V2
#include
intmain(void)
{
intnum=1024;
int*pi=#
char*ps="TechZone";
void*pv;
pv=pi;
printf("pi:%p,pv:%p ",pi,pv);
printf("*pv:%d ",*(int*)pv);
pv=ps;
printf("ps:%p,pv:%p ",ps,pv);
printf("*pv:%s ",pv);
}
當(dāng)然,使用void指針一定要小心,由于void指針幾乎可以「通吃」所有類(lèi)型,所以間接使得不同類(lèi)型的指針轉(zhuǎn)換變得合法,如果代碼中存在不合理的轉(zhuǎn)換,編譯器也不會(huì)報(bào)錯(cuò)。
因此,void指針能不用則不用,后面講函數(shù)的時(shí)候,還可以解鎖更多新的玩法。
NULL指針
在C語(yǔ)言中,如果一個(gè)指針不指向任何數(shù)據(jù),那么就稱(chēng)之為「空指針」,用「NULL」來(lái)表示。NULL其實(shí)是一個(gè)宏定義:
#defineNULL((void*)0)
在大部分的操作系統(tǒng)中,地址0通常是一個(gè)「不被使用」的地址,所以如果一個(gè)指針指向NULL,就意味著不指向任何東西。為什么一個(gè)指針要指向NULL呢?
其實(shí)這反而是一種比較指的推薦的「編程風(fēng)格」——當(dāng)你暫時(shí)還不知道該指向哪兒的時(shí)候,就讓它指向NULL,以后不會(huì)有太多的麻煩,比如:
//Example11
#include
intmain(void)
{
int*p1;
int*p2=NULL;
printf("%d ",*p1);
printf("%d ",*p2);
return0;
}
第一個(gè)指針未被初始化。在有的編譯器里面,這樣未初始化的變量就會(huì)被賦予「隨機(jī)值」。這樣指針被稱(chēng)為「迷途指針」,「野指針」或者「懸空指針」。如果后面的代碼對(duì)這類(lèi)指針解引用,而這個(gè)地址又剛好是合法的話,那么就會(huì)產(chǎn)生莫名其妙的結(jié)果,甚至導(dǎo)致程序的崩潰。因此養(yǎng)成良好的習(xí)慣,在暫時(shí)不清楚的情況下使用NULL,可以節(jié)省大量的后期調(diào)試的時(shí)間。
指向指針的指針
開(kāi)始套娃了。其實(shí)只要你理解了指針的概念,也就沒(méi)什么大不了的。
//Example12
#include
intmain(void)
{
intnum=1;
int*p=#
int**pp=&p;
printf("num:%d ",num);
printf("*p:%d ",*p);
printf("**p:%d ",**pp);
printf("&p:%p,pp:%p ",&p,pp);
printf("&num:%p,p:%p,*pp:%p ",&num,p,*pp);
return0;
}
程序結(jié)果如下:
//Consequence 12
num: 1
*p: 1
**p: 1
&p: 004FF960, pp: 004FF960
&num: 004FF96C, p: 004FF96C, *pp: 004FF96C
當(dāng)然你也可以無(wú)限地套娃,一直指下去。不過(guò)這樣會(huì)讓代碼可讀性變得「很差」,過(guò)段時(shí)間可能你自己都看不懂你寫(xiě)的代碼了。
指針數(shù)組和指向指針的指針
那么,指向指針的指針有什么用呢?
它可不是為了去創(chuàng)造混亂代碼,在一個(gè)經(jīng)典的實(shí)例里面,就可以體會(huì)到它的用處:
char*Books[]={
"《C專(zhuān)家編程》",
"《C和指針》",
"《C的陷阱與缺陷》",
"《CPrimerPlus》",
"《Python基礎(chǔ)教程(第三版)》"
};
然后我們需要將這些書(shū)進(jìn)行分類(lèi)。我們發(fā)現(xiàn),其中有一本是寫(xiě)Python的,其他都是C語(yǔ)言的。這時(shí)候指向指針的指針就派上用場(chǎng)了。首先,我們剛剛定義了一個(gè)指針數(shù)組,也就是說(shuō),里面的所有元素的類(lèi)型「都是指針」,而數(shù)組名卻又可以用指針的形式來(lái)「訪問(wèn)」,因此就可以使用「指向指針的指針」來(lái)指向指針數(shù)組:
...
char**Python;
char**CLang[4];
Python=&Books[5];
CLang[0]=&Books[0];
CLang[1]=&Books[1];
CLang[2]=&Books[2];
CLang[3]=&Books[3];
...
因?yàn)樽址娜〉刂分祵?shí)際上就是其「首地址」,也就是一個(gè)「指向字符指針的指針」,所以可以這樣賦值。
這樣,我們就利用指向指針的指針完成了對(duì)書(shū)籍的分類(lèi),這樣既避免了浪費(fèi)多余的內(nèi)存,而且當(dāng)其中的書(shū)名要修改,只需要改一次即可,代碼的靈活性和安全性都得到了提升。
常量和指針
常量,在我們目前的認(rèn)知里面,應(yīng)該是這樣的:
520, 'a'
或者是這樣的:
#defineMAX1000
#defineB'b'
常量和變量最大的區(qū)別,就是前者「不能夠被修改」,后者可以。那么在C語(yǔ)言中,可以將變量變成像具有常量一樣的特性,利用const即可。
constintmax=1000;
constchara='a';
在const關(guān)鍵字的作用下,變量就會(huì)「失去」本來(lái)具有的可修改的特性,變成“只讀”的屬性。
指向常量的指針
強(qiáng)大的指針當(dāng)然也是可以指向被const修飾過(guò)的變量,但這就意味著「不能通過(guò)」指針來(lái)修改它所引用的值。總結(jié)一下,就是以下4點(diǎn):
指針可以修改為指向不同的變量
指針可以修改為指向不同的常量
可以通過(guò)解引用來(lái)讀取指針指向的數(shù)據(jù)
不可以通過(guò)解引用來(lái)修改指針指向的數(shù)據(jù)
常量指針
指向非常量的常量指針
指針本身作為一種「變量」,也是可以修改的。因此,指針也是可以被const修飾的,只不過(guò)位置稍稍「發(fā)生了點(diǎn)變化」:
...
int*constp=#
...
這樣的指針有如下的特性:
指針自身不能夠被修改
指針指向的值可以被修改
指向常量的常量指針
在定義普通變量的時(shí)候也用const修飾,就得到了這樣的指針。不過(guò)由于限制太多,一般很少用到:
...
intnum=100;
constintcnum=200;
constint*constp=&cnum;
...
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3055瀏覽量
74327 -
C語(yǔ)言
+關(guān)注
關(guān)注
180文章
7614瀏覽量
137703 -
數(shù)組
+關(guān)注
關(guān)注
1文章
417瀏覽量
26027 -
運(yùn)算符
+關(guān)注
關(guān)注
0文章
172瀏覽量
11107 -
指針變量
+關(guān)注
關(guān)注
0文章
17瀏覽量
7243
原文標(biāo)題:詳解 C 語(yǔ)言指針底層基本原理
文章出處:【微信號(hào):嵌入式開(kāi)發(fā)愛(ài)好者,微信公眾號(hào):嵌入式開(kāi)發(fā)愛(ài)好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
擴(kuò)頻通信的基本原理
C語(yǔ)言指針詳解
C指針詳解
C語(yǔ)言指針電子教程
C語(yǔ)言指針函數(shù)和函數(shù)指針詳細(xì)介紹

c語(yǔ)言指針用法詳解:如何使用指針變量做函數(shù)參數(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論