 Stable Diffusion:一種新型的深度學習AIGC模型
Stable Diffusion:一種新型的深度學習AIGC模型
潛在擴散模型 | AIGC|Diffusion Model
圖片感知壓縮 | GAN |Stable Diffusion
隨著生成型AI技術的能力提升,越來越多的注意力放在了通過AI模型提升研發效率上。業內比較火的AI模型有很多,比如畫圖神器Midjourney、用途多樣的Stable Diffusion,以及OpenAI此前剛剛迭代的DALL-E 2。
對于研發團隊而言,盡管Midjourney功能強大且不需要本地安裝,但它對于硬件性能的要求較高,甚至同一個指令每次得到的結果都不盡相同。相對而言,Stable Diffusion因具備功能多、開源、運行速度快,且能耗低內存占用小成為更理想的選擇。
AIGC和ChatGPT4技術的爆燃和狂飆,讓文字生成、音頻生成、圖像生成、視頻生成、策略生成、GAMEAI、虛擬人等生成領域得到了極大的提升。不僅可以提高創作質量,還能降低成本,增加效率。同時,對GPU和算力的需求也越來越高,因此GPU服務器廠商開始涌向該賽道,為這一領域提供更好的支持。
本文將重點從Stable Diffusion如何安裝、Stable Diffusion工作原理及Diffusion model與GAN相比的優劣勢為大家展開詳細介紹。

Stable Diffusion如何安裝
Stable Diffusion是一個非常有用的工具,可以幫助用戶快速、準確地生成想要的場景及圖片。它的安裝也非常簡單,只需要按照上述步驟進行即可。如果您需要快速生成圖片及場景,Stable Diffusion是一個值得嘗試的工具。
一、環境準備
1、硬件方面
1)顯存
4G起步,4G顯存支持生成512*512大小圖片,超過這個大小將卡爆失敗。這里小編建議使用RTX 3090。
2)硬盤
10G起步,模型基本都在5G以上,有個30G硬盤不為過吧?現在硬盤容量應該不是個問題。

2、軟件方面
1)Git
https://git-scm.com/download/win
2)Python
https://www.python.org/downloads/
3)Nvidia CUDA
https://developer.download.nvidia.cn/compute/cuda/11.7.1/local_installers/cuda_11.7.1_516.94_windows.exe
版本11.7.1,搭配Nvidia驅動516.94,可使用最新版。
4)stable-diffusion-webui
https://github.com/AUTOMATIC1111/stable-diffusion-webui
核心部件當然用最新版本~~但注意上面三個的版本的兼容性。
5)中文語言包
https://github.com/VinsonLaro/stable-diffusion-webui-chinese
下載chinese-all-0306.json 和 chinese-english-0306.json文件
6)擴展(可選)
https://github.com/Mikubill/sd-webui-controlnet
下載整個sd-webui-controlnet壓縮包
https://huggingface.co/Hetaneko/Controlnet-models/tree/main/controlnet_safetensors
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
https://huggingface.co/TencentARC/T2I-Adapter/tree/main
試用時先下載第一個鏈接中的control_openpose.safetensors 或 第二個鏈接中的control_sd15_openpose.pth文件
7)模型
https://huggingface.co/models
https://civitai.com
可以網上去找推薦的一些模型,一般后綴名為ckpt、pt、pth、safetensors ,有時也會附帶VAE(.vae.pt)或配置文件(.yaml)。
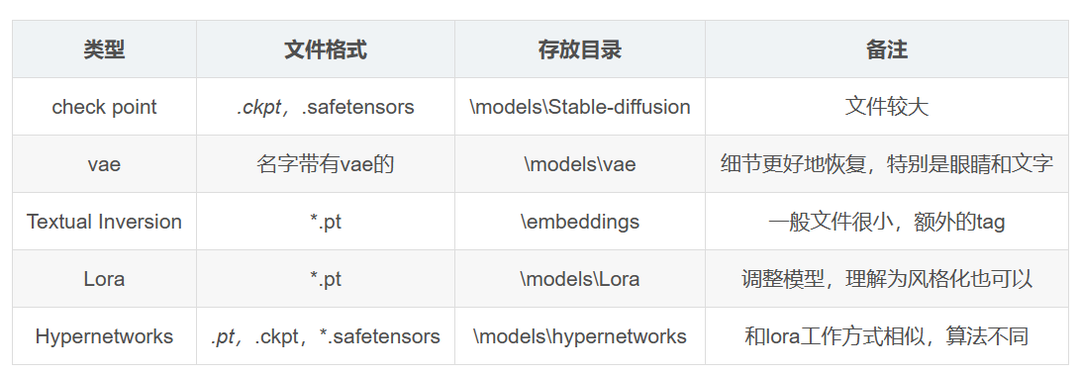
二、安裝流程
1)安裝Git
就正常安裝,無問題。
2)安裝Python
建議安裝在非program files、非C盤目錄,以防出現目錄權限問題。
注意安裝時勾選Add Python to PATH,這樣可以在安裝時自動加入windows環境變量PATH所需的Python路徑。
3)安裝Nvidia CUDA
正常安裝,無問題。
4)安裝stable-diffusion-webui
國內需要用到代理和鏡像,請按照下面的步驟操作:
a) 編輯根目錄下launch.py文件
將https://github.com替換為https://ghproxy.com/https://github.com,即使用Ghproxy代理,加速國內Git。
b) 執行根目錄下webui.bat文件
根目錄下將生成tmp和venv目錄。
c) 編輯venv目錄下pyvenv.cfg文件
將include-system-site-packages = false改為include-system-site-packages = true。
d) 配置python庫管理器pip
方便起見,在venvScripts下打開cmd后執行如下命令:

xformer會安裝到venvLibsite-packages中,安裝失敗可以用pip install -U xformers命試試。
e) 安裝語言包
將文件chinese-all-0306.json 和 chinese-english-0306.json放到目錄localizations目錄中。運行webui后進行配置,操作方法見下。
f) 安裝擴展(可選)
將sd-webui-controlnet解壓縮到extensions目錄中。將control_sd15_openpose.pth文件復制到/extensions/sd-webui-controlnet/models目錄中。不同的擴展可能還需要安裝對應的系統,比如controlnet要正常使用則還需要安裝ffmpeg等。
g) 安裝模型
下載的各種模型放在modelsStable-diffusion目錄中即可。
h) 再次執行根目錄下webui.bat文件
用瀏覽器打開webui.bat所提供的網址即可運行。

其中提供了網址:http://127.0.0.1:7860。
打開該網址后在Settings -> User interface -> Localization (requires restart)設置語言,在菜單中選擇chinese-all-0220(前提是已經在目錄中放入了對應語言包,見上),點擊Apply Settings確定,并且點擊Reload UI重啟界面后即可。
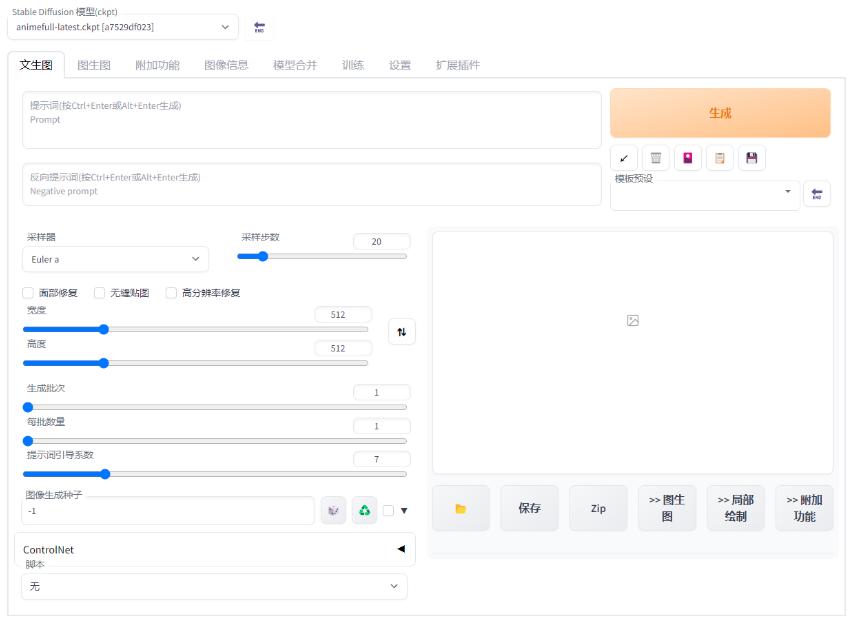
Stable Diffusion背后的原理
Latent Diffusion Models(潛在擴散模型)的整體框架如下圖所示。首先需要訓練一個自編碼模型,這樣就可以利用編碼器對圖片進行壓縮,然后在潛在表示空間上進行擴散操作,最后再用解碼器恢復到原始像素空間。這種方法被稱為感知壓縮(Perceptual Compression)。個人認為這種將高維特征壓縮到低維,然后在低維空間上進行操作的方法具有普適性,可以很容易地推廣到文本、音頻、視頻等領域。
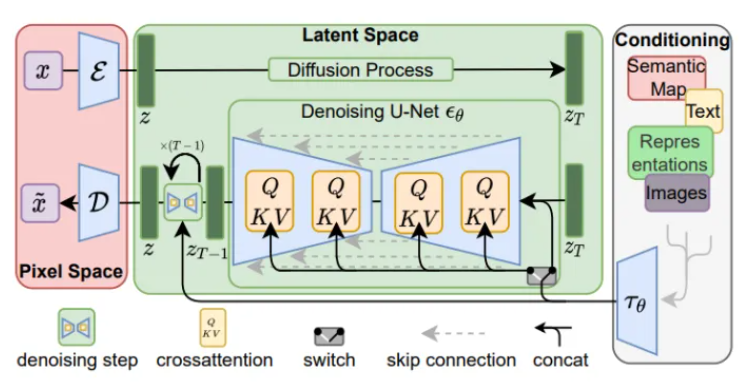
在潛在表示空間上進行diffusion操作的主要過程和標準的擴散模型沒有太大的區別,所使用的擴散模型的具體實現為time-conditional UNet。但是,論文為擴散操作引入了條件機制(Conditioning Mechanisms),通過cross-attention的方式來實現多模態訓練,使得條件圖片生成任務也可以實現。
下面我們針對感知壓縮、擴散模型、條件機制的具體細節進行展開。
一、圖片感知壓縮(Perceptual Image Compression)
感知壓縮本質上是一個tradeoff。之前的許多擴散模型沒有使用這種技術也可以進行,但是原有的非感知壓縮的擴散模型存在一個很大的問題,即在像素空間上訓練模型時,如果希望生成高分辨率的圖像,則訓練空間也是高維的。感知壓縮通過使用自編碼模型,忽略高頻信息,只保留重要的基礎特征,從而大幅降低訓練和采樣階段的計算復雜度,使文圖生成等任務能夠在消費級GPU上在10秒內生成圖片,降低了落地門檻。
感知壓縮利用預訓練的自編碼模型,學習到一個在感知上等同于圖像空間的潛在表示空間。這種方法的優勢在于,只需要訓練一個通用的自編碼模型,就可以用于不同的擴散模型的訓練,在不同的任務上使用。
因此,基于感知壓縮的擴散模型的訓練本質上是一個兩階段訓練的過程,第一階段需要訓練一個自編碼器,第二階段才需要訓練擴散模型本身。在第一階段訓練自編碼器時,為了避免潛在表示空間出現高度的異化,作者使用了兩種正則化方法,一種是KL-reg,另一種是VQ-reg,因此在官方發布的一階段預訓練模型中,會看到KL和VQ兩種實現。在Stable Diffusion中主要采用AutoencoderKL這種實現。
二、潛在擴散模型(Latent Diffusion Models)
首先簡要介紹一下普通的擴散模型(DM),擴散模型可以解釋為一個時序去噪自編碼器(equally weighted sequence of denoising autoencoders)
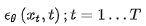
,其目標是根據輸入
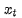
去預測一個對應去噪后的變體,或者說預測噪音,其中
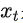
是輸入
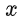
的噪音版本。相應的目標函數可以寫成如下形式:
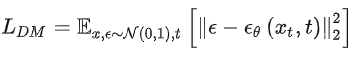
。其中
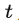
從
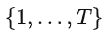
中均勻采樣獲得。
而在潛在擴散模型中,引入了預訓練的感知壓縮模型,它包括一個編碼器
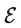
和一個解碼器
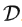
。這樣就可以利用在訓練時就可以利用編碼器得到
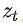
,從而讓模型在潛在表示空間中學習,相應的目標函數可以寫成如下形式:
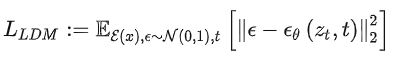
三、條件機制
除了無條件圖片生成外,我們也可以進行條件圖片生成,這主要是通過拓展得到一個條件時序去噪自編碼器(conditional denoising autoencoder)
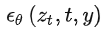
來實現的,這樣一來我們就可通過
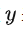
來控制圖片合成的過程。具體來說,論文通過在UNet主干網絡上增加cross-attention機制來實現
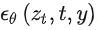
。為了能夠從多個不同的模態預處理
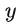
,論文引入了一個領域專用編碼器(domain specific encoder)
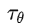
,它用來將
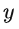
映射為一個中間表示
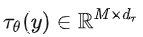
,這樣我們就可以很方便的引入各種形態的條件(文本、類別、layout等等)。最終模型就可以通過一個cross-attention層映射將控制信息融入到UNet的中間層,cross-attention層的實現如下:
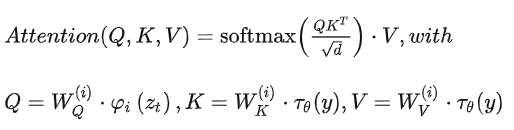
其中
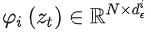
是UNet的一個中間表征。相應的目標函數可以寫成如下形式:
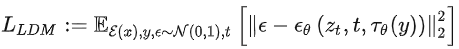
四、效率與效果的權衡
分析不同下采樣因子f∈{1,2,4,8,16,32}(簡稱LDM-f,其中LDM-1對應基于像素的DMs)的效果。為了獲得可比較的測試結果,固定在一個NVIDIA A100上進行了實驗,并使用相同數量的步驟和參數訓練模型。實驗結果表明,LDM-{1,2}這樣的小下采樣因子訓練緩慢,因為它將大部分感知壓縮留給擴散模型。而f值過大,則導致在相對較少的訓練步驟后保真度停滯不前,原因在于第一階段壓縮過多,導致信息丟失,從而限制了可達到的質量。LDM-{4-16}在效率和感知結果之間取得了較好的平衡。與基于像素的LDM-1相比,LDM-{4-8}實現了更低的FID得分,同時顯著提高了樣本吞吐量。對于像ImageNet這樣的復雜數據集,需要降低壓縮率以避免降低質量。總之,LDM-4和-8提供了較高質量的合成結果。
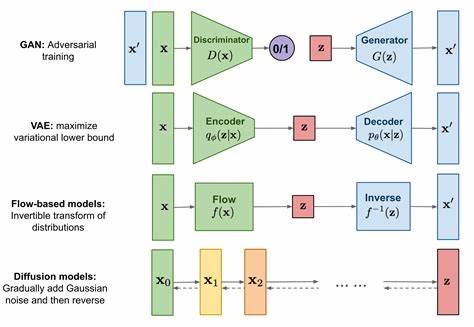
Diffusion model與GAN相比的優劣勢
一、優點
Diffusion Model相比于GAN,明顯的優點是避免了麻煩的對抗學習。此外,還有幾個不太明顯的好處:首先,Diffusion Model可以“完美”用latent去表示圖片,因為我們可以用一個ODE從latent變到圖片,同一個ODE反過來就可以從圖片變到latent。而GAN很難找到真實圖片對應什么latent,所以可能會不太好修改非GAN生成的圖片。其次,Diffusion Model可以用來做“基于色塊的編輯”(SDEdit),而GAN沒有這樣的性質,所以效果會差很多。再次,由于Diffusion Model和score之間的聯系,它可以用來做inverse problem solver的learned prior,例如我有一個清晰圖片的生成模型,看到一個模糊圖片,可以用生成模型作為先驗讓圖片更清晰。最后,Diffusion Model可以求model likelihood,而這個GAN就很難辦。Diffusion Model最近的流行一部分也可能是因為GAN卷不太動了。雖然嚴格意義上說,Diffusion Model最早出自Jascha Sohl-Dickstein在ICML 2015就發表的文章,和GAN的NeurIPS 2014也差不了多少;不過DCGAN/WGAN這種讓GAN沃克的工作在2015-17就出了,而Diffusion Model在大家眼中做沃克基本上在NeurIPS 2020,所以最近看上去更火也正常。
二、不足之處
Diffusion model相比于GAN也存在一些缺陷。首先,無法直接修改潛在空間的維度,這意味著無法像StyleGAN中使用AdaIN對圖像風格進行操作。其次,由于沒有判別器,如果監督條件是“我想要網絡輸出的東西看起來像某個物體,但我不確定具體是什么”,就會比較困難。而GAN可以輕松地實現這一點,例如生成長頸鹿的圖像。此外,由于需要迭代,生成速度比較慢,但在單純的圖像生成方面已經得到了解決。目前在條件圖像生成方面的研究還不夠充分,但可以嘗試將Diffusion model應用于這一領域。
審核編輯黃宇
-
AI
+關注
關注
87文章
31520瀏覽量
270335 -
ChatGPT
+關注
關注
29文章
1568瀏覽量
8061 -
AIGC
+關注
關注
1文章
367瀏覽量
1606
發布評論請先 登錄
相關推薦
#新年新氣象,大家新年快樂!#AIGC入門及鴻蒙入門
AIGC入門及鴻蒙入門

AIGC系統中多個模型的切換調用方案探索
AIGC是什么及其應用 AIGC的定義和工作原理

一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
韓國科研團隊發布新型AI圖像生成模型KOALA,大幅優化硬件需求
Stability AI試圖通過新的圖像生成人工智能模型保持領先地位






 工商網監
工商網監
評論