 清華&美團提出稀疏Pairwise損失函數!ReID任務超已有損失函數!
清華&美團提出稀疏Pairwise損失函數!ReID任務超已有損失函數!
ReID任務的目的是從海量圖像中檢索出與給定query相同ID的實例。
Pairwise損失函數在ReID 任務中發揮著關鍵作用。現有方法都是基于密集采樣機制,即將每個實例都作為錨點(anchor)采樣其正樣本和負樣本構成三元組。這種機制不可避免地會引入一些幾乎沒有視覺相似性的正對,從而影響訓練效果。為了解決這個問題,我們提出了一種新穎的損失范式,稱為稀疏Pairwise (SP) 損失,在ReID任務中針對mini-batch的每一類篩選出少數合適的樣本對來構造損失函數(如圖1所示)。基于所提出的損失框架,我們進一步提出了一種自適應正挖掘策略,可以動態地適應不同類別內部的變化。大量實驗表明,SP 損失及其自適應變體AdaSP 損失在多個ReID數據集上均優于其他成對損失方法,并取得了state-of-the-art性能。
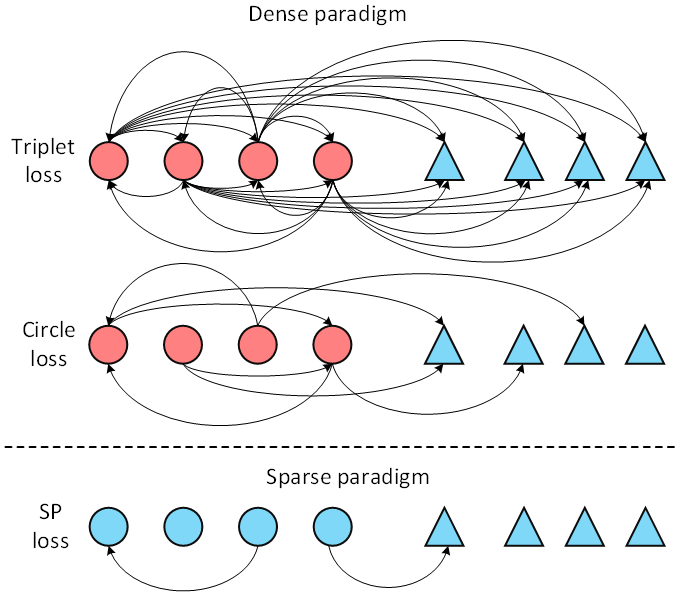
圖1. Sparse pairwise損失與Dense pairwise損失之間的差異

Adaptive Sparse Pairwise Loss for Object Re-Identification
論文地址:https://arxiv.org/abs/2303.18247
Github地址(已開源):
https://github.com/Astaxanthin/AdaSP
研究動機:
ReID任務中的由于光照變化、視角改變和遮擋等原因會造成同一類中不同實例的視覺相似度很低(如圖2所示),因此由視覺相似度很低的實例(我們稱之為harmful positive pair)構成的正樣本對會對特征表示的學習過程帶來不利的影響,從而使訓練收斂至局部極小點。現有的方法都是以每個樣本作為錨(anchor)密集采樣正樣本對來構造度量損失函數,不可避免的會引入大量壞對影響訓練結果。基于此,我們提出了稀疏Pairwise損失函數以降低對壞對的采樣概率,從而減輕壞對在訓練過程的不利影響。
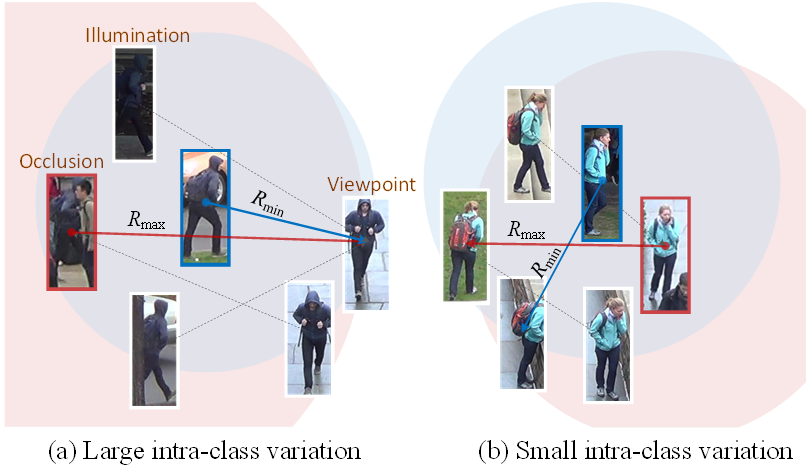
圖2. 行人ReID數據集上不同級別的類內差異
方法介紹:我們提出的稀疏Pairwise損失函數(命名為SP loss)針對每一類僅采樣一個正樣本對和一個負樣本對。其中負樣本對為該類別與其他所有類別間最難的負樣本對,而正樣本對為所有樣本的hard positive pair集合中的最不難positive pair(least-hard mining):
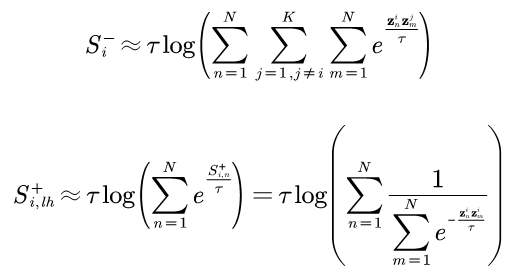
從幾何角度看,以最難positive pair的距離作為半徑的超球面是能夠覆蓋所有類內樣本的最大球,而以hard positive pair集合中最不難positive pair的距離作為半徑的超球面是能夠副高所有類內樣本的最小球,如圖3所示。利用最小球能夠有效的避免過于難的harmful positive pair對于訓練過程的影響,我們從理論上證明了針對一個mini-batch,我們的方法采樣得到的正樣本對中harmful positive pair的期望占比小于Triplet-BH和Circle等密集采樣方法。
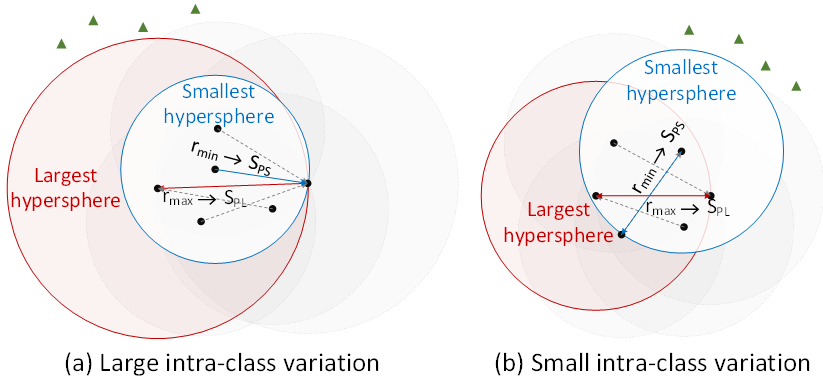
圖3. 不同級別類內差異差異下的最大和最小覆蓋球。
為了適應不同類別可能具有不同的類內差異,我們在SP loss的基礎上增加了自適應策略構成AdaSP loss:
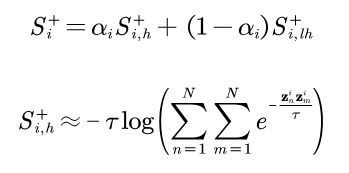

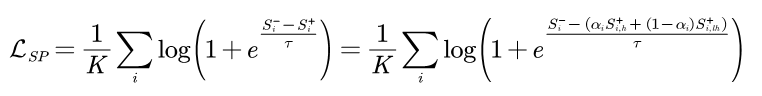
該loss通過動態調整構造loss所用到的正樣本對相似度以適應不同的類內差異。
實驗結果:
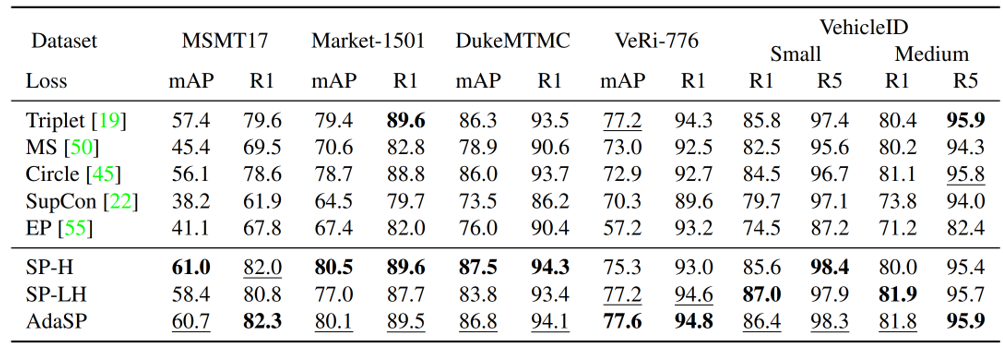
我們在多個行人ReID數據集(包括MSMT17,Market1501,DukeMTMC,CUHK03)和車輛ReID數據集(包括VeRi-776,VehicleID,VERIWild)上驗證了AdaSP loss的有效性。實驗結果顯示AdaSP loss在單獨使用時超過Triplet-BH,Circle,MS,Supcon,EP等已有度量損失函數,如表1所示;AdaSP loss在不同骨干網絡(包括ResNet-50/101/152,ResNet-IBN,MGN,ViT,DeiT)上的ReID性能均優于Triplet-BH;此外,AdaSP loss結合分類損失函數在ReID任務上達到了State-of-the-art的性能。
表1. 在不同數據集上不同度量損失函數的性能比較
具體細節可以參考原文。
審核編輯 :李倩
-
函數
+關注
關注
3文章
4346瀏覽量
62973 -
數據集
+關注
關注
4文章
1209瀏覽量
24834 -
REID
+關注
關注
1文章
18瀏覽量
10873
原文標題:CVPR 2023 | 清華&美團提出稀疏Pairwise損失函數!ReID任務超已有損失函數!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
對象檢測邊界框損失函數–從IOU到ProbIOU介紹
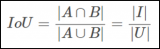
keras常用的損失函數Losses與評價函數Metrics介紹
神經網絡中的損失函數層和Optimizers圖文解讀
機器學習經典損失函數比較
機器學習實用指南:訓練和損失函數
三種常見的損失函數和兩種常用的激活函數介紹和可視化
深度學習的19種損失函數你了解嗎?帶你詳細了解
計算機視覺的損失函數是什么?
損失函數的簡要介紹
機器學習和深度學習中分類與回歸常用的幾種損失函數
表示學習中7大損失函數的發展歷程及設計思路
詳細分析14種可用于時間序列預測的損失函數
語義分割25種損失函數綜述和展望






 工商網監
工商網監
評論