") 算法時(shí)空復(fù)雜度分析實(shí)用指南1
算法時(shí)空復(fù)雜度分析實(shí)用指南1
我以前的文章主要都是講解算法的原理和解題的思維,對(duì)時(shí)間復(fù)雜度和空間復(fù)雜度的分析經(jīng)常一筆帶過(guò),主要是基于以下兩個(gè)原因:
1、對(duì)于偏小白的讀者,希望你集中精力理解算法原理。如果加入太多偏數(shù)學(xué)的內(nèi)容,很容易把人勸退。
2、正確理解常用算法底層原理,是進(jìn)行復(fù)雜度的分析的前提。尤其是遞歸相關(guān)的算法,只有你從樹的角度進(jìn)行思考和分析,才能正確分析其復(fù)雜度。
鑒于現(xiàn)在歷史文章已經(jīng)涵蓋了所有常見算法的核心原理,所以我專門寫一篇時(shí)空復(fù)雜度的分析指南,授人以魚不如授人以漁,教給你一套通用的方法分析任何算法的時(shí)空復(fù)雜度。
本文會(huì)篇幅較長(zhǎng),會(huì)涵蓋如下幾點(diǎn):
1、Big O 表示法的幾個(gè)基本特點(diǎn)。
2、非遞歸算法中的時(shí)間復(fù)雜度分析。
3、數(shù)據(jù)結(jié)構(gòu) API 的效率衡量方法(攤還分析)。
4、遞歸算法的時(shí)間/空間復(fù)雜度的分析方法,這部分是重點(diǎn),我會(huì)用動(dòng)態(tài)規(guī)劃和回溯算法舉例。
廢話不多說(shuō)了,接下來(lái)一個(gè)個(gè)看。
Big O 表示法
首先看一下 Big O 記號(hào)的數(shù)學(xué)定義:
O(g(n))= {f(n): 存在正常量c和n_0,使得對(duì)所有n ≥ n_0,有0 ≤ f(n) ≤ c*g(n)}
我們常用的這個(gè)符號(hào)O其實(shí)代表一個(gè)函數(shù)的集合,比如O(n^2)代表著一個(gè)由g(n) = n^2派生出來(lái)的一個(gè)函數(shù)集合;我們說(shuō)一個(gè)算法的時(shí)間復(fù)雜度為O(n^2),意思就是描述該算法的復(fù)雜度的函數(shù)屬于這個(gè)函數(shù)集合之中。
理論上,你看明白這個(gè)抽象的數(shù)學(xué)定義,就可以解答你關(guān)于 Big O 表示法的一切疑問(wèn)了 。
但考慮到大部分人看到數(shù)學(xué)定義就頭暈,我給你列舉兩個(gè)復(fù)雜度分析中會(huì)用到的特性,記住這兩個(gè)就夠用了。
1、只保留增長(zhǎng)速率最快的項(xiàng),其他的項(xiàng)可以省略 。
首先,乘法和加法中的常數(shù)因子都可以忽略不計(jì),比如下面的例子:
O(2N + 100) = O(N)
O(2^(N+1)) = O(2 * 2^N) = O(2^N)
O(M + 3N + 99) = O(M + N)
當(dāng)然,不要見到常數(shù)就消,有的常數(shù)消不得:
O(2^(2N)) = O(4^N)
除了常數(shù)因子,增長(zhǎng)速率慢的項(xiàng)在增長(zhǎng)速率快的項(xiàng)面前也可以忽略不計(jì):
O(N^3 + 999 * N^2 + 999 * N) = O(N^3)
O((N + 1) * 2^N) = O(N * 2^N + 2^N) = O(N * 2^N)
以上列舉的都是最簡(jiǎn)單常見的例子,這些例子都可以被 Big O 記號(hào)的定義正確解釋。如果你遇到更復(fù)雜的復(fù)雜度場(chǎng)景,也可以根據(jù)定義來(lái)判斷自己的復(fù)雜度表達(dá)式是否正確。
2、Big O 記號(hào)表示復(fù)雜度的「上界」 。
換句話說(shuō),只要你給出的是一個(gè)上界,用 Big O 記號(hào)表示就都是正確的。
比如如下代碼:
for (int i = 0; i < N; i++) {
print("hello world");
}
如果說(shuō)這是一個(gè)算法,那么顯然它的時(shí)間復(fù)雜度是O(N)。但如果你非要說(shuō)它的時(shí)間復(fù)雜度是O(N^2),嚴(yán)格意義上講是可以的,因?yàn)?code>O記號(hào)表示一個(gè)上界嘛,這個(gè)算法的時(shí)間復(fù)雜度確實(shí)不會(huì)超過(guò)N^2這個(gè)上界呀,雖然這個(gè)上界不夠「緊」,但符合定義,所以沒(méi)毛病。
上述例子太簡(jiǎn)單,非要擴(kuò)大它的時(shí)間復(fù)雜度上界顯得沒(méi)什么意義。但有些算法的復(fù)雜度會(huì)和算法的輸入數(shù)據(jù)有關(guān),沒(méi)辦法提前給出一個(gè)特別精確的時(shí)間復(fù)雜度,那么在這種情況下,用 Big O 記號(hào)擴(kuò)大時(shí)間復(fù)雜度的上界就變得有意義了。
比如前文 動(dòng)態(tài)規(guī)劃核心框架中講到的湊零錢問(wèn)題的暴力遞歸解法,核心代碼框架如下:
// 定義:要湊出金額 n,至少要 dp(coins, n) 個(gè)硬幣
int dp(int[] coins, int amount) {
// base case
if (amount <= 0) return;
// 狀態(tài)轉(zhuǎn)移
for (int coin : coins) {
dp(coins, amount - coin);
}
}
當(dāng)amount = 11, coins = [1,2,5]時(shí),算法的遞歸樹就長(zhǎng)這樣:
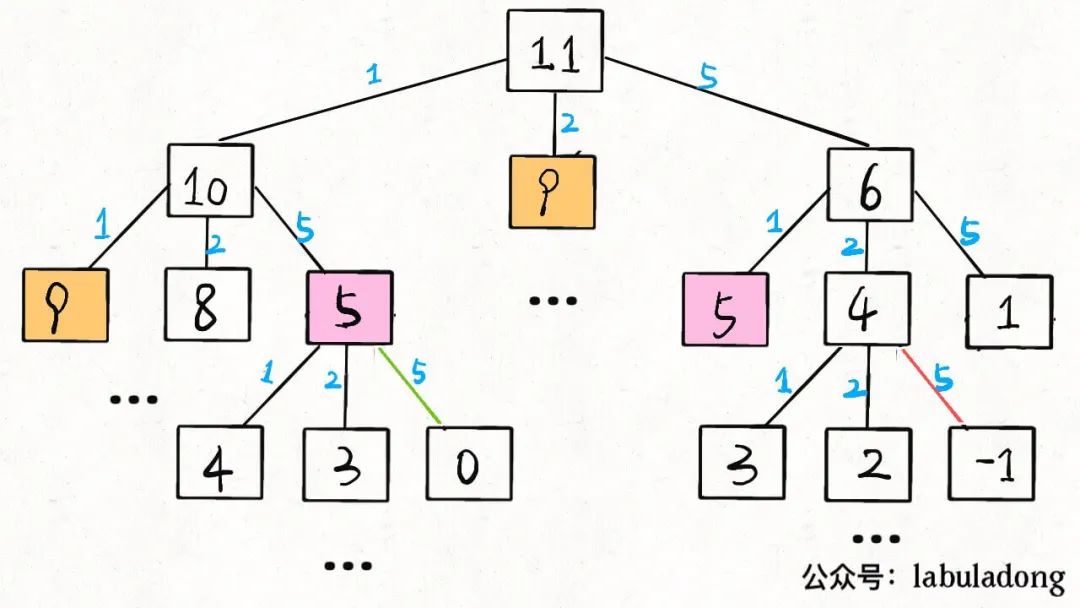
后文會(huì)具體講遞歸算法的時(shí)間復(fù)雜度計(jì)算方法,現(xiàn)在我們先求一下這棵遞歸樹上的節(jié)點(diǎn)個(gè)數(shù)吧。
假設(shè)金額amount的值為N,coins列表中元素個(gè)數(shù)為K,那么這棵遞歸樹就是一棵K叉樹。但這棵樹的生長(zhǎng)和coins列表中的硬幣面額有直接的關(guān)系,所以這棵樹的形狀會(huì)很不規(guī)則,導(dǎo)致我們很難精確地求出樹上節(jié)點(diǎn)的總數(shù)。
對(duì)于這種情況,比較簡(jiǎn)單的處理方式就是按最壞情況做近似處理:
這棵樹的高度有多高?不知道,那就按最壞情況來(lái)處理,假設(shè)全都是面額為 1 的硬幣,這種情況下樹高為N。
這棵樹的結(jié)構(gòu)是什么樣的?不知道,那就按最壞情況來(lái)處理,假設(shè)它是一棵滿K叉樹好了。
那么,這棵樹上共有多少節(jié)點(diǎn)?都按最壞情況來(lái)處理,高度為N的一棵滿K叉樹,其節(jié)點(diǎn)總數(shù)為K^N - 1,用 Big O 表示就是O(K^N)。
當(dāng)然,我們知道這棵樹上的節(jié)點(diǎn)數(shù)其實(shí)沒(méi)有這么多,但用O(K^N)表示一個(gè)上界是沒(méi)問(wèn)題的。
所以,有時(shí)候你自己估算出來(lái)的時(shí)間復(fù)雜度和別人估算的復(fù)雜度不同,并不一定代表誰(shuí)算錯(cuò)了,可能你倆都是對(duì)的,只是是估算的精度不同 ,一般來(lái)說(shuō)只要數(shù)量級(jí)(線性/指數(shù)級(jí)/對(duì)數(shù)級(jí)/平方級(jí)等)能對(duì)上就沒(méi)問(wèn)題。
在算法領(lǐng)域,除了用 Big O 表示漸進(jìn)上界,還有漸進(jìn)下界、漸進(jìn)緊確界等邊界的表示方法,有興趣的讀者可以自行搜索。不過(guò)從實(shí)用的角度看,以上對(duì) Big O 記號(hào)表示法的講解就夠用了。
非遞歸算法分析
非遞歸算法的空間復(fù)雜度一般很容易計(jì)算,你看它有沒(méi)有申請(qǐng)數(shù)組之類的存儲(chǔ)空間就行了,所以我主要說(shuō)下時(shí)間復(fù)雜度的分析。
非遞歸算法中嵌套循環(huán)很常見,大部分場(chǎng)景下,只需把每一層的復(fù)雜度相乘就是總的時(shí)間復(fù)雜度:
// 復(fù)雜度 O(N*W)
for (int i = 1; i <= N; i++) {
for (int w = 1; w <= W; w++) {
dp[i][w] = ...;
}
}
// 1 + 2 + ... + n = n/2 + (n^2)/2
// 用 Big O 表示化簡(jiǎn)為 O(n^2)
for (int i = 0; i < n; i++) {
for (int j = i; j >= 0; j--) {
dp[i][j] = ...;
}
}
但有時(shí)候只看嵌套循環(huán)的層數(shù)并不準(zhǔn)確,還得看算法 具體在做什么 ,比如前文一文秒殺所有 nSum 問(wèn)題) 中就有這樣一段代碼:
// 左右雙指針
int lo = 0, hi = nums.length;
while (lo < hi) {
int sum = nums[lo] + nums[hi];
int left = nums[lo], right = nums[hi];
if (sum < target) {
while (lo < hi && nums[lo] == left) lo++;
} else if (sum > target) {
while (lo < hi && nums[hi] == right) hi--;
} else {
while (lo < hi && nums[lo] == left) lo++;
while (lo < hi && nums[hi] == right) hi--;
}
}
這段代碼看起來(lái)很復(fù)雜,大 while 循環(huán)里面套了好多小 while 循環(huán),感覺(jué)這段代碼的時(shí)間復(fù)雜度應(yīng)該是O(N^2)(N代表nums的長(zhǎng)度)?
其實(shí),你只需要搞清楚代碼到底在干什么,就能輕松計(jì)算出正確的復(fù)雜度了 。
這段代碼就是個(gè)左右雙指針嘛,lo是左邊的指針,hi是右邊的指針,這兩個(gè)指針相向而行,相遇時(shí)外層 while 結(jié)束。
甭管多復(fù)雜的邏輯,你看lo指針一直在往右走(lo++),hi指針一直在往左走(hi--),它倆有沒(méi)有回退過(guò)?沒(méi)有。
所以這段算法的邏輯就是lo和hi不斷相向而行,相遇時(shí)算法結(jié)束,那么它的時(shí)間復(fù)雜度就是線性的O(N)。
類似的,你看前文 滑動(dòng)窗口算法核心框架給出的滑動(dòng)窗口算法模板:
/* 滑動(dòng)窗口算法框架 */
void slidingWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
// 雙指針,維護(hù) [left, right) 為窗口
int left = 0, right = 0;
while (right < s.size()) {
// 增大窗口
right++;
// 判斷左側(cè)窗口是否要收縮
while (window needs shrink) {
// 縮小窗口
left++;
}
}
}
乍一看也是個(gè)嵌套循環(huán),但仔細(xì)觀察,發(fā)現(xiàn)這也是個(gè)雙指針技巧,left和right指針從 0 開始,一直向右移,直到移動(dòng)到s的末尾結(jié)束外層 while 循環(huán),沒(méi)有回退過(guò)。
那么該算法做的事情就是把left和right兩個(gè)指針從 0 移動(dòng)到N(N代表字符串s的長(zhǎng)度),所以滑動(dòng)窗口算法的時(shí)間復(fù)雜度為線性的O(N)。
數(shù)據(jù)結(jié)構(gòu)分析
因?yàn)閿?shù)據(jù)結(jié)構(gòu)會(huì)用來(lái)存儲(chǔ)數(shù)據(jù),其 API 的執(zhí)行效率可能受到其中存儲(chǔ)的數(shù)據(jù)的影響,所以衡量數(shù)據(jù)結(jié)構(gòu) API 效率的方法和衡量普通算法函數(shù)效率的方法是有一些區(qū)別的。
就拿我們常見的數(shù)據(jù)結(jié)構(gòu)舉例,比如很多語(yǔ)言都提供動(dòng)態(tài)數(shù)組,可以自動(dòng)進(jìn)行擴(kuò)容和縮容。在它的尾部添加元素的時(shí)間復(fù)雜度是O(1)。但當(dāng)?shù)讓訑?shù)組擴(kuò)容時(shí)會(huì)分配新內(nèi)存并把原來(lái)的數(shù)據(jù)搬移到新數(shù)組中,這個(gè)時(shí)間復(fù)雜度就是O(N)了,那我們能說(shuō)在數(shù)組尾部添加元素的時(shí)間復(fù)雜度就是O(N)嗎?
再比如哈希表也會(huì)在負(fù)載因子達(dá)到某個(gè)閾值時(shí)進(jìn)行擴(kuò)容和 rehash,時(shí)間復(fù)雜度也會(huì)達(dá)到O(N),那么我們?yōu)槭裁催€說(shuō)哈希表對(duì)單個(gè)鍵值對(duì)的存取效率是O(1)呢?
答案就是, 如果想衡量數(shù)據(jù)結(jié)構(gòu)類中的某個(gè)方法的時(shí)間復(fù)雜度,不能簡(jiǎn)單地看最壞時(shí)間復(fù)雜度,而應(yīng)該看攤還(平均)時(shí)間復(fù)雜度 。
比如說(shuō)前文 [特殊數(shù)據(jù)結(jié)構(gòu):?jiǎn)握{(diào)隊(duì)列實(shí)現(xiàn)的單調(diào)隊(duì)列類:
/* 單調(diào)隊(duì)列的實(shí)現(xiàn) */
class MonotonicQueue {
LinkedList
標(biāo)準(zhǔn)的隊(duì)列實(shí)現(xiàn)中,push和pop方法的時(shí)間復(fù)雜度應(yīng)該都是O(1),但這個(gè)MonotonicQueue類的push方法包含一個(gè)循環(huán),其復(fù)雜度取決于參數(shù)e,最好情況下是O(1),而最壞情況下復(fù)雜度應(yīng)該是O(N),N為隊(duì)列中的元素個(gè)數(shù)。
對(duì)于這種情況,我們用平均時(shí)間復(fù)雜度來(lái)衡量push方法的效率比較合理。雖然它包含循環(huán),但它的平均時(shí)間復(fù)雜度依然為O(1)。
-
算法
+關(guān)注
關(guān)注
23文章
4630瀏覽量
93359 -
API
+關(guān)注
關(guān)注
2文章
1511瀏覽量
62400 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4346瀏覽量
62977 -
數(shù)據(jù)結(jié)構(gòu)
+關(guān)注
關(guān)注
3文章
573瀏覽量
40232
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于紋理復(fù)雜度的快速幀內(nèi)預(yù)測(cè)算法
時(shí)間復(fù)雜度是指什么
各種排序算法的時(shí)間空間復(fù)雜度、穩(wěn)定性
一種低復(fù)雜度的MIMO-OFDM信道估計(jì)閾值算法
LDPC碼低復(fù)雜度譯碼算法研究

基于復(fù)雜度分析的改進(jìn)A_算法飛行器航跡規(guī)劃_叢林虎
圖像復(fù)雜度對(duì)信息隱藏性能影響分析
如何求遞歸算法的時(shí)間復(fù)雜度
如何求遞歸算法的時(shí)間復(fù)雜度
常見機(jī)器學(xué)習(xí)算法的計(jì)算復(fù)雜度
算法時(shí)空復(fù)雜度分析實(shí)用指南2
算法時(shí)空復(fù)雜度分析實(shí)用指南(上)
算法時(shí)空復(fù)雜度分析實(shí)用指南(下)
如何計(jì)算時(shí)間復(fù)雜度





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論