") 大算力未來,HBM、Chiplet和CPO等技術打破性能瓶頸
大算力未來,HBM、Chiplet和CPO等技術打破性能瓶頸
在“AI算力產(chǎn)業(yè)鏈梳理:技術迭代突破瓶頸,AIGC場景驅動算力需求提升”報告中,詳細闡述了大語言模型涉及對高性能硬件(如 GPU、TPU)、大規(guī)模高質量數(shù)據(jù)集的需求以及軟件算法的提高等多方面要求。
1.HBM 技術:高吞吐高帶寬,AI 帶動需求激增
HBM(High Bandwidth Memory)意為高帶寬存儲器,是一種硬件存儲介質,是高性能 GPU 的核心組件。HBM 具有高吞吐高帶寬的特性,受到工業(yè)界和學術界的關注。它單顆粒的帶寬可以達到 256 GB/s,遠超過 DDR4 和 GDDR6。DDR4 是 CPU 和硬件處理單元的常用外掛存儲設備,但是它的吞吐能力不足以滿足當今計算需求,特別是在 AI 計算、區(qū)塊鏈和數(shù)字貨幣挖礦等大數(shù)據(jù)處理訪存需求極高的領域。GDDR6 也比不上 HBM,它單顆粒的帶寬只有 64 GB/s,是HBM 的 1/4。而 DDR4 3200 需要至少 8 顆粒才能提供 25.6 GB/s 的帶寬,是 HBM 的 1/10。
HBM 使用多根數(shù)據(jù)線實現(xiàn)高帶寬,完美解決傳統(tǒng)存儲效率低的問題。HBM 的核心原理和普通的 DDR、GDDR 完全一樣,但是 HBM 使用多根數(shù)據(jù)線實現(xiàn)了高帶寬。HBM/HBM2 使用 1024 根數(shù)據(jù)線傳輸數(shù)據(jù),作為對比,GDDR 是 32 根,DDR 是 64 根。HBM 需要使用額外的硅聯(lián)通層,通過晶片堆疊技術與處理器連接。這么多的連接線保持高傳輸頻率會帶來高功耗。因此 HBM 的數(shù)據(jù)傳輸頻率相對很低,HBM2 也只有 2 Gbps,作為對比,GDDR6 是 16 Gbps,DDR4 3200 是3.2 Gbps。這些特點導致了 HBM 技術高成本,容量不可擴,高延遲等缺點。
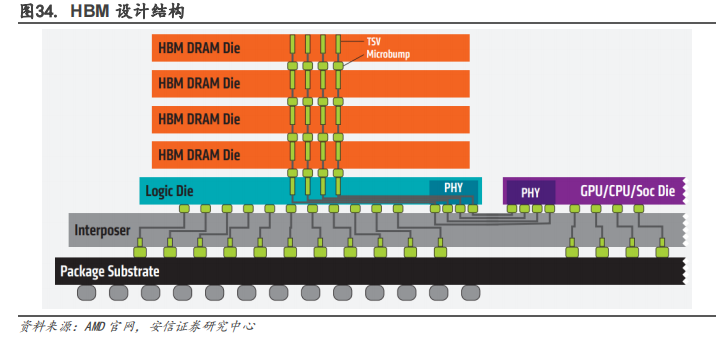
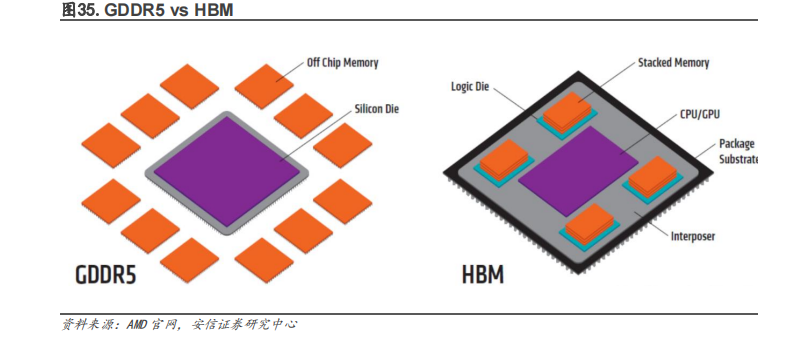
HBM 可以被廣泛的應用到汽車高帶寬存儲器,GPU 顯存芯片,部分 CPU 的內存芯片,邊緣 AI加速卡,Chiplets 等硬件中。在高端 GPU 芯片產(chǎn)品中,比如 NVDIA 面向數(shù)據(jù)中心的 A100 等加速卡中就使用了 HBM;部分 CPU 的內存芯片,如目前富岳中的 A64FX 等 HPC 芯片中也有應用到。車輛在快速移動時,攝像頭、傳感器會捕獲大量的數(shù)據(jù),為了更快速的處理數(shù)據(jù),HBM是最合適的選擇。Chiplets 在設計過程中沒有降低對內存的需求,隨著異構計算(尤其是小芯片)的發(fā)展,芯片會加速對高帶寬內存的需求,無論是 HBM、GDDR6 還是 LPDDR6。
HBM 緩解帶寬瓶頸,是 AI 時代不可或缺的關鍵技術。AI 處理器架構的探討從學術界開始,當時的模型簡單,算力低,后來模型加深,算力需求增加,帶寬瓶頸出現(xiàn),也就是 IO 問題。這個問題可以通過增大片內緩存、優(yōu)化調度模型等方法解決。但是隨著 AI 大模型和云端 AI處理的發(fā)展,計算單元劇增,IO 問題更嚴重了。要解決這個問題需要付出很高的代價(比如增加 DDR 接口通道數(shù)量、片內緩存容量、多芯片互聯(lián)),這便是 HBM 出現(xiàn)的意義。HBM 用晶堆疊技術和硅聯(lián)通層把處理器和存儲器連接起來,把 AI/深度學習完全放到片上,提高集成度,降低功耗,不受芯片引腳數(shù)量的限制。HBM 在一定程度上解決了 IO 瓶頸。未來人工智能的數(shù)據(jù)量、計算量會越來越大,超過現(xiàn)有的 DDR/GDDR 帶寬瓶頸,HBM 可能會是唯一的解決方案。
巨頭領跑,各大存儲公司都已在 HBM 領域參與角逐。SK 海力士、三星、美光等存儲巨頭在HBM 領域展開了升級競賽,國內佰維存儲等公司持續(xù)關注 HBM 領域。SK 海力士早在 2021 年10 月就開發(fā)出全球首款 HBM3,2022 年 6 月量產(chǎn)了 HBM3 DRAM 芯片,并將供貨英偉達,持續(xù)鞏固其市場領先地位。三星也在積極跟進,在 2022 年技術發(fā)布會上發(fā)布的內存技術發(fā)展路線圖中,HBM3 技術已經(jīng)量產(chǎn)。
2、Chiplet技術:全產(chǎn)業(yè)鏈升級降本增效,國內外大廠前瞻布局
Chiplet 即根據(jù)計算單元或功能單元將 SOC 進行分解,分別選擇合適制程工藝制造。隨著處理器的核越來越多,芯片復雜度增加、設計周期越來越長,SoC 芯片驗證的時間、成本也急劇增加,特別是高端處理芯片、大芯片。當前集成電路工藝在物理、化學很多方面都達到了極限,大芯片快要接近制造瓶頸,傳統(tǒng)的 SoC 已經(jīng)很難繼續(xù)被采納。Chiplet,俗稱小芯片、芯粒,是將一塊原本復雜的 SoC 芯片,從設計的時候就按照不同的計算單元或功能單元進行分解,然后每個單元分別選擇最合適的半導體制程工藝進行制造,再通過先進封裝技術將各自單元彼此互聯(lián)。Chiplet 是一種類似搭樂高積木的方法,能將采用不同制造商、不同制程工藝的各種功能芯片進行組裝,從而實現(xiàn)更高良率、更低成本。
Chiplet 可以從多個維度降低成本,延續(xù)摩爾定律的“經(jīng)濟效益”。隨著半導體工藝制程推進,晶體管尺寸越來越逼近物理極限,所耗費的時間及成本越來越高,同時所能夠帶來的“經(jīng)濟效益”的也越來越有限。Chiplet 技術可從三個不同的維度來降低成本:
(1)可大幅度提高大型芯片的良率:芯片的良率與芯片面積有關,Chiplet 設計將大芯片分成小模塊可以有效改善良率,降低因不良率導致的成本增加。
(2)可降低設計的復雜度和設計成本:Chiplet 通過在芯片設計階段就將 Soc 按照不同功能模塊分解成可重復云涌的小芯粒,是一種新形式的 IP 復用,可大幅度降低設計復雜度和成本累次增加。
(3)可降低芯片制造的成本:在 Soc 中的一些主要邏輯計算單元是依賴于先進工藝制程來提升性能,但其他部分對制程的要求并不高,一些成熟制程即可滿足需求。將Soc進行Chiplet化后對于不同的芯粒可選擇對應合適的工藝制程進行分開制造,極大降低芯片的制造成本。
Chiplet 為全產(chǎn)業(yè)鏈提供了升級機會。在后摩爾時代,Chiplet 可以開啟一個新的芯片生態(tài)。2022年 3 月,Chiplet的高速互聯(lián)標準——UCIe(UniversalChiplet Interconnect Express,通用芯粒互聯(lián)技術)正式推出,旨在芯片封裝層面確立互聯(lián)互通的統(tǒng)一標準,打造一個開放性的 Chiplet 生態(tài)系統(tǒng)。巨頭們合力搭建起了統(tǒng)一的 Chiplet 互聯(lián)標準,將加速推動開放的Chiplet 平臺發(fā)展,并橫跨 x86、Arm、RISC-V 等架構和指令集。Chiplet 的影響力也從設計端走到芯片制造與封裝環(huán)節(jié)。在芯片小型化的設計過程中,需要添加更多 I/O 與其他芯片芯片接口,裸片尺寸必須要保持較大的空白空間。而且,要想保證 Chiplet 的信號傳輸質量就需要發(fā)展高密度、大寬帶布線的先進封裝技術。另外,Chiplet 也影響到從 EDA 廠商、晶圓制造和封裝公司、芯粒 IP 供應商、Chiplet 產(chǎn)品及系統(tǒng)設計公司到 Fabless 設計廠商的產(chǎn)業(yè)鏈各個環(huán)節(jié)的參與者。
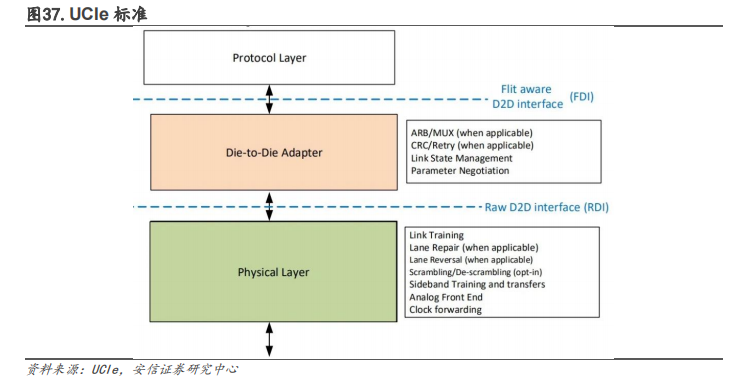
(1)最先受到影響的是芯片 IP 設計企業(yè),Chiplet 本質就是不同的 IP 芯片化,國內類似 IP 商均有望參與其中,比如華為海思有 IP 甚至指令集開發(fā)實力的公司,推出基于 RISC-V 內核的處理器(玄鐵 910)阿里平頭哥半導體公司,獨立的第三方 IP 廠商,如芯動科技、芯原股份、芯耀輝、銳成芯微、芯來等眾多 IP 公司等。
(2)Chiplet 需要 EDA 工具從架構探索、芯片設計、物理及封裝實現(xiàn)等提供全面支持,為國內 EDA 企業(yè)發(fā)展帶來了突破口。芯和半導體已全面支持 2.5D Interposer、3DIC 和 Chiplet 設計。
(3)Chiplet 也推動了先進封裝技術的發(fā)展。根據(jù)長電科技公告,在封測技術領域取得新的突破。4nm 芯片作為先進硅節(jié)點技術,是導入 Chiplet 封裝的一部分通富微電提供晶圓級及基板級封裝兩種解決方案,其中晶圓級 TSV 技術是 Chiplet 技術路徑的一個重要部分。

國外芯片廠率先發(fā)力,通過 Chiplet 實現(xiàn)收益。AMD 的 EPYC 率先采用了 Chiplet 結構,實現(xiàn)了在服務器 CPU 市場上的翻身。隨后,Ryzen 產(chǎn)品上重用了 EYPC Rome 的 CCD,這樣的 chiplet設計極好的降低了總研發(fā)費用。2023 年 1 月,Intel 發(fā)布了采用了 Chiplet 技術的第四代至強可擴展處理器 Sapphire Rapids 以及英特爾數(shù)據(jù)中心 GPU Max 系列等。Sapphire Rapids是 Intel 首個基于 Chiplet 設計的處理器,被稱為“算力神器”。Xilinx 的 2011 Virtex-72000T 是 4 個裸片的 Chiplet 設計。Xilinx 也是業(yè)界唯一的同構和異構的 3D IC。
3、CPO 技術:提升數(shù)據(jù)中心及云計算效率,應用領域廣泛
CPO(Co-packaged,共封裝光學技術)是高速電信號能夠高質量的在交換芯片和光引擎之間傳輸。在 5G 時代,計算、傳輸、存儲的帶寬要求越來越高,同時硅光技術也越來越成熟,因此板上和板間的光互連成為了一種必要的方式。隨著通道數(shù)大幅增加,需要專用集成電路(ASIC)來控制多個光收發(fā)模塊。傳統(tǒng)的連接方式是 Pluggable(可插拔),即光引擎是可插拔的光模塊,通過光纖和 SerDes 通道與網(wǎng)絡交換芯片(AISC)連接。之后發(fā)展出了 NPO(Near-packaged,近封裝光學),一種將光引擎和交換芯片分別裝配在同一塊 PCB 基板上的方式。而CPO 是一種將交換芯片和光引擎共同裝配在同一個 Socketed(插槽)上的方式,形成芯片和模組的共封裝,從而降低網(wǎng)絡設備的功耗和散熱問題。NPO 是 CPO 的過渡階段,相對容易實現(xiàn),而 CPO 是最終解決方案。
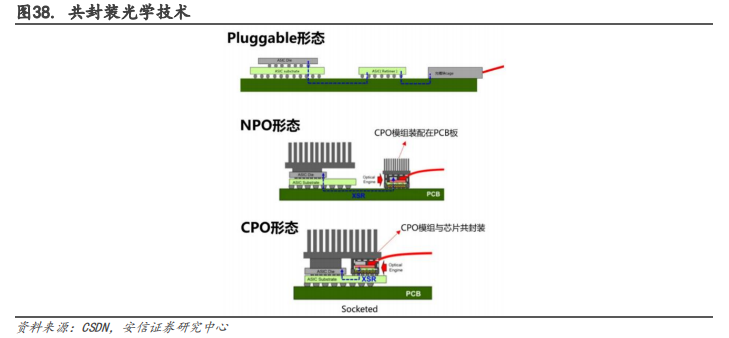
隨著大數(shù)據(jù)及 AI 的發(fā)展,數(shù)據(jù)中心的需求激增,CPO 有著廣泛的應用前景。在數(shù)據(jù)中心領域,CPO 技術可以實現(xiàn)更高的數(shù)據(jù)密度和更快的數(shù)據(jù)傳輸速度,還可以減少系統(tǒng)的功耗和空間占用,降低數(shù)據(jù)中心的能源消耗和維護成本,能夠應用于高速網(wǎng)絡交換、服務器互聯(lián)和分布式存儲等領域,例如,F(xiàn)acebook 在其自研的數(shù)據(jù)中心網(wǎng)絡 Fabric Aggregator 中采用了CPO 技術,提高了網(wǎng)絡的速度和質量。在云計算領域,CPO 技術可以實現(xiàn)高速云計算和大規(guī)模數(shù)據(jù)處理。例如微軟在其云計算平臺 Azure 中采用了 CPO 技術,實現(xiàn)更高的數(shù)據(jù)密度和更快的數(shù)據(jù)傳輸速度,提高云計算的效率和性能。
在 5G 通信領域,CPO 技術可以實現(xiàn)更快的無線數(shù)據(jù)傳輸和更穩(wěn)定的網(wǎng)絡連接。例如華為在其 5G 通信系統(tǒng)中采用了 CPO 技術,將收發(fā)器和芯片封裝在同一個封裝體中,從而實現(xiàn)了高速、高密度、低功耗的通信。除此之外,5G/6G 用戶的增加,人工智能、機器學習 (ML)、物聯(lián)網(wǎng) (IoT) 和虛擬現(xiàn)實流量的延遲敏感型流量激增,對光收發(fā)器的數(shù)據(jù)速率要求將快速增長;AI、ML、VR 和 AR 對數(shù)據(jù)中心的帶寬要求巨大,并且對低延遲有極高的要求,未來 CPO 的市場規(guī)模將持續(xù)高速擴大。
審核編輯 :李倩
-
存儲器
+關注
關注
38文章
7528瀏覽量
164347 -
gpu
+關注
關注
28文章
4777瀏覽量
129360 -
chiplet
+關注
關注
6文章
434瀏覽量
12632
原文標題:大算力未來,HBM、Chiplet和CPO等技術打破性能瓶頸
文章出處:【微信號:架構師技術聯(lián)盟,微信公眾號:架構師技術聯(lián)盟】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
FPGA上的HBM性能實測結果分析
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
如何打破技術瓶頸?
北極雄芯開發(fā)的首款基于Chiplet異構集成的智能處理芯片“啟明930”
IBM全新AI芯片設計登上Nature,解決GPU的算力瓶頸
基于憶阻器存算一體芯片的研究進展
基于憶阻器存算一體芯片研究進展、總結與展望
奇異摩爾:Chiplet如何助力高性能計算突破算力瓶頸
大算力模型,HBM、Chiplet和CPO等技術打破技術瓶頸
一文詳解CPO光模塊技術

chiplet和cpo有什么區(qū)別?
大算力芯片里的HBM,你了解多少?
HBM:突破AI算力內存瓶頸,技術迭代引領高性能存儲新紀元

解鎖Chiplet潛力:封裝技術是關鍵






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論