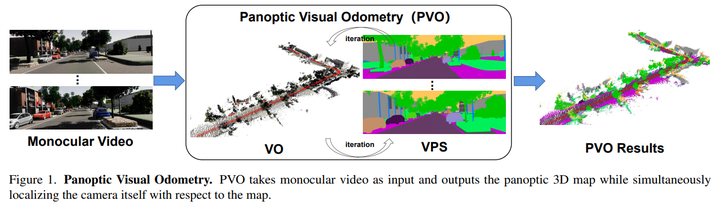
 介紹一種新的全景視覺里程計框架PVO
介紹一種新的全景視覺里程計框架PVO
論文提出了PVO,這是一種新的全景視覺里程計框架,用于實現場景運動、幾何和全景分割信息的更全面建模。提出的PVO在統一的視圖中對視覺里程計(VO)和視頻全景分割(VPS)進行建模,這使得這兩項任務互惠互利。具體來說,在圖像全景分割的指導下,在VO模塊中引入了全景更新模塊。
該全景增強VO模塊可以通過全景感知動態mask來減輕動態目標在相機姿態估計中的影響。另一方面,VO增強型VPS模塊還利用從VO模塊獲得的相機姿態、深度和光流等幾何信息,將當前幀的全景分割結果融合到相鄰幀,從而提高了分割精度,這兩個模塊通過反復迭代優化相互促進。大量實驗表明,PVO在視覺里程計和視頻全景分割任務中都優于最先進的方法。
領域背景
了解場景的運動、幾何和全景分割在計算機視覺和機器人技術中發揮著至關重要的作用,其應用范圍從自動駕駛到增強現實,本文朝著解決這個問題邁出了一步,以實現單目視頻場景的更全面建模!已經提出了兩項任務來解決這個問題,即視覺里程計(VO)和視頻全景分割(VPS)。特別地,VO[9,11,38]將單目視頻作為輸入,并在靜態場景假設下估計相機姿態。為了處理場景中的動態對象,一些動態SLAM系統使用實例分割網絡進行分割,并明確過濾出某些類別的目標,這些目標可能是動態的,例如行人或車輛。
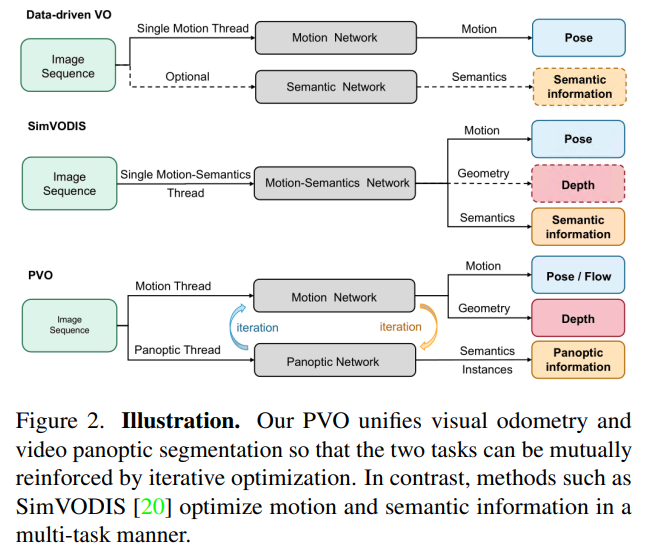
然而,這種方法忽略了這樣一個事實,即潛在的動態目標實際上可能在場景中是靜止的,例如停放的車輛。相比之下,VPS專注于在給定一些初始全景分割結果的情況下,跨視頻幀跟蹤場景中的單個實例。當前的VPS方法沒有明確區分目標實例是否在移動,盡管現有的方法廣泛地獨立地解決了這兩個任務,但值得注意的是,場景中的動態目標會使這兩項任務都具有挑戰性。認識到兩個任務之間的這種相關性,一些方法試圖同時處理這兩個任務,并以多任務的方式訓練運動語義網絡,如圖2所示。然而,這些方法中使用的損失函數可能相互矛盾,從而導致性能下降。
本文提出了一種新的全景視覺里程計(PVO)框架,該框架使用統一的視圖將這兩項任務緊密耦合,以對場景進行全面建模。VPS可以利用全景分割信息調整VO的權重(每個實例的像素的權重應該相互關聯),VO可以將視頻全景分割的跟蹤和融合從2D轉換為3D。受開創性的期望最大化算法的啟發,遞歸迭代優化策略可以使這兩項任務互惠互利。
PVO由三個模塊組成,一個圖像全景分割模塊、一個全景增強型VO模塊和一個VO增強型VPS模塊。全景分割模塊獲取單個圖像并輸出圖像全景分割結果,然后被饋送到全景增強VO模塊中作為初始化。注意,盡管本文選擇PanopticFPN,但任何分割模型都可以用于全景分割模塊。在全景增強VO模塊,提出了一個全景更新模塊來過濾動態目標的干擾,從而提高了動態場景中姿態估計的準確性。在VO增強的VPS模塊中,引入了一種在線融合機制,根據估計的姿態、深度和光流,將當前幀的多分辨率特征與相鄰幀對齊,這種在線融合機制可以有效地解決多目標遮擋的問題。實驗表明,遞歸迭代優化策略提高了VO和VPS的性能。本文的主要貢獻概括為四個方面:
1.本文提出了一種新的全景視覺里程計(PVO)框架,該框架可以將VO和VPS任務統一起來,對場景進行全面建模;
2.引入全景更新模塊,并將其納入全景增強VO模塊,以改進姿態估計;
3.在VOEnhanced VPS模塊中提出了一種在線融合機制,有助于改進視頻全景分割;
4.大量實驗表明,提出的具有遞歸迭代優化的PVO在視覺里程計和視頻全景分割任務中都優于最先進的方法;
1)視頻全景分割
視頻全景分割旨在生成一致的全景分割,并跟蹤視頻幀中所有像素的實例。作為一項先驅工作,VPSNet定義了這項新任務,并提出了一種基于實例級跟蹤的方法。SiamTrack通過提出pixel-tube匹配損失和對比度損失來擴展VPSNet,以提高實例嵌入的判別能力。VIPDeplab通過引入額外的深度信息,提供了一個深度感知VPS網絡。而STEP提出對視頻全景分割的每個像素進行分割和跟蹤,HybridTracker提出從兩個角度跟蹤實例:特征空間和空間位置。與現有方法不同,本文引入了一種VO增強的VPS模塊,該模塊利用VO估計的相機姿態、深度和光流來跟蹤和融合從當前幀到相鄰幀的信息,并可以處理遮擋。
2)SLAM和視覺里程計
SLAM同時進行定位和地圖構建,視覺里程計作為SLAM的前端,專注于姿態估計。現代SLAM系統大致分為兩類,基于幾何的方法和基于學習的方法。由于基于監督學習的方法具有良好的性能,基于無監督學習的VO方法受到了廣泛的關注,但它們的性能不如有監督的方法。一些無監督方法利用多任務學習和深度和光流等輔助任務來提高性能。
最近,TartanVO提出建立一個可推廣基于學習的VO,并在具有挑戰性的SLAM數據集TartanAir上測試該系統。DROID-SLAM提出使用bundle adjustment層迭代更新相機姿態和像素深度,并展示了卓越的性能。DeFlowSLAM進一步提出了dual-flow表示和自監督方法,以提高SLAM系統在動態場景中的性能。為了應對動態場景的挑戰,動態SLAM系統通常利用語義信息作為約束但它們主要作用于stereo、RGBD或LiDAR序列。相反,本文引入了全景更新模塊,并在DROID-SLAM上構建了全景增強型VO,可以用于單目視頻。這樣的組合可以更好地理解場景幾何和語義,從而對場景中的動態對象更加魯棒。與其它多任務端到端模型不同,本文的PVO具有循環迭代優化策略,可以防止任務相互干擾。
本文提出的方法
給定一個單目視頻,PVO的目標是同時定位和全景3D映射。圖3描述了PVO模型的框架,它由三個主要模塊組成:圖像全景分割模塊、全景增強VO模塊和VO增強VPS模塊。VO模塊旨在估計攝像機的姿態、深度和光流,而VPS模塊輸出相應的視頻全景分割,最后兩個模塊以反復互動的方式相互促進!
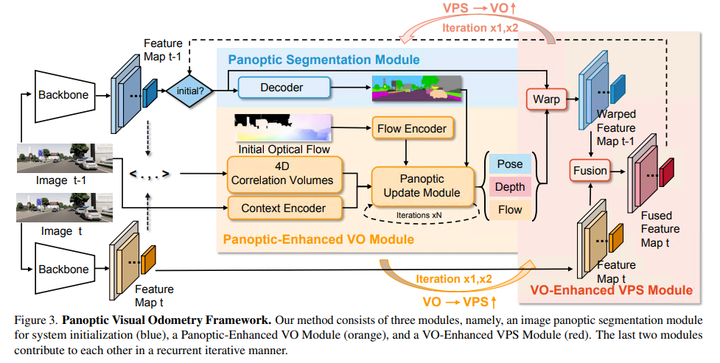
1)圖像全景分割
圖像全景分割以單個圖像為輸入,輸出圖像的全景分割結果,將語義分割和實例分割相結合,對圖像的實例進行綜合建模。輸出結果用于初始化視頻全景分割,然后輸入全景增強VO模塊。在本文的實驗中,如果沒有特別指出,使用廣泛使用的圖像全景分割網絡PanopticFPN。PanopticFPN建立在具有權重θ_e的ResNetf_{θ_e}的主干上,并提取圖像的多尺度特征I_t:

它使用具有權重θ_d的解碼器g_{θ_d}輸出全景分割結果,該解碼器由語義分割和實例分割組成,每個像素p的全景分割結果為:
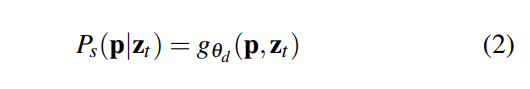
被饋送到解碼器中的多尺度特征隨著時間的推移而更新。一開始,編碼器生成的多尺度特征被直接輸入解碼器(圖3藍色部分)。在隨后的時間步長中,這些多尺度特征在被饋送到解碼器之前用在線特征融合模塊進行更新。
2)全景增強 VO 模塊
在視覺里程計中,動態場景無處不在,過濾掉動態目標的干擾至關重要。DROID-SLAM的前端以單目視頻{{I_t}}^N_{t=0}為輸入,并優化相機姿態{G_t}^N_{t=0}∈SE(3)和反深度d_t∈R^{H×W}+,通過迭代優化光流delta r{ij}∈R^{HW2}。它不考慮大多數背景是靜態的,前景目標可能是動態的,并且每個目標的像素權重應該是相關的。全景增強VO模塊(見圖4)是通過結合全景分割的信息,幫助獲得更好的置信度估計(見圖7),因此,全景增強VO可以獲得更精確的相機姿勢。接下來,將簡要回顧DROID-SLAM的類似部分(特征提取和相關性),并重點介紹全景更新模塊的復雜設計。
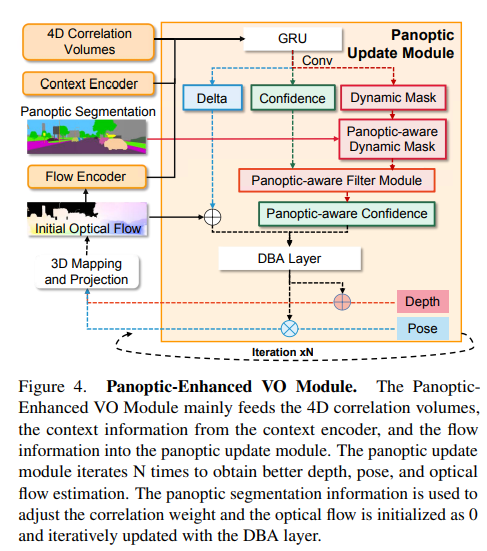

特征提取:與DROID-SLAM類似,全景增強VO模塊借用了RAFT的關鍵組件來提取特征。本文使用兩個獨立的網絡(一個特征編碼器和一個上下文編碼器) 提取每個圖像的多尺度特征,其中利用特征編碼器的特征構建成對圖像的4D相關volumes,并將上下文編碼器的特征注入全景更新模塊。特征編碼器的結構類似于全景分割網絡的主干,并且它們可以使用共享編碼器。
相關金字塔和查找表:與DROIDSLAM類似,本文采用幀圖(V,E)來指示幀之間的共同可見性。例如,邊(i,j)∈E表示保持重疊區域的兩個圖像I_i和I_j,并且可以通過這兩個圖像的特征向量之間的點積來構建4D相關volumes:
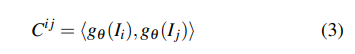
遵循平均池化層以獲得金字塔相關性,本文使用DROID-SLAM中定義的相同查找運算符來使用雙線性插值對金字塔相關volumes值進行索引,這些相關特征被串聯,從而產生最終的特征向量。Panoptic增強型VO模塊繼承了DROID-SLAM的前端VO模塊,利用全景分割信息來調整VO的權重。將通過將初始光流饋送到流編碼器而獲得的flow信息和從兩幀建立的4D相關volumes以及上下文編碼器獲取的特征作為中間變量饋送到GRU,然后三個卷積層輸出動態掩碼M_{d_{ij}},相關置信度map w_{ij}和稠密光流delta r_{ij}。給定初始化的全景分割,可以將動態掩碼調整為全景感知動態掩碼,為了便于理解,保持符號不變。置信度和全景感知動態掩碼通過全景感知濾波器模塊以獲得全景感知置信度:
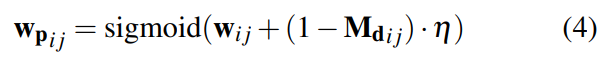
深度和動態的殘差掩碼被添加到當前深度和動態掩碼,分別為:
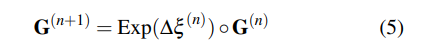
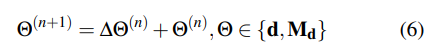
Correspondence:首先在每次迭代中使用當前的姿態和深度估計來搜索對應關系。參考DROID-SLAM,對于幀i中的每個像素坐標pi,幀圖中每個邊(i,j)∈E的稠密對應域pij可以計算如下:
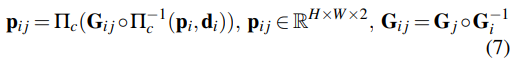
DBA層:使用DROID-SLAM中定義的密集束調整層(DBA)來map stream revisions,以更新當前估計的逐像素深度和姿態,成本函數可以定義如下:
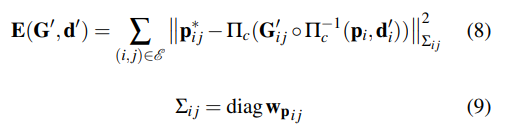
3)VO增強型VPS模塊
視頻全景分割旨在獲得每幀的全景分割結果,并保持幀間分割的一致性。為了提高分割精度和跟蹤精度,FuseTrack等一些方法試圖利用光流信息對特征進行融合,并根據特征的相似性進行跟蹤。這些方法僅來自可能遇到遮擋或劇烈運動的2D視角。我們生活在一個3D世界中,可以使用額外的深度信息來更好地建模場景。本文的VO增強型VPS模塊正是基于這一理解,能夠更好地解決上述問題。
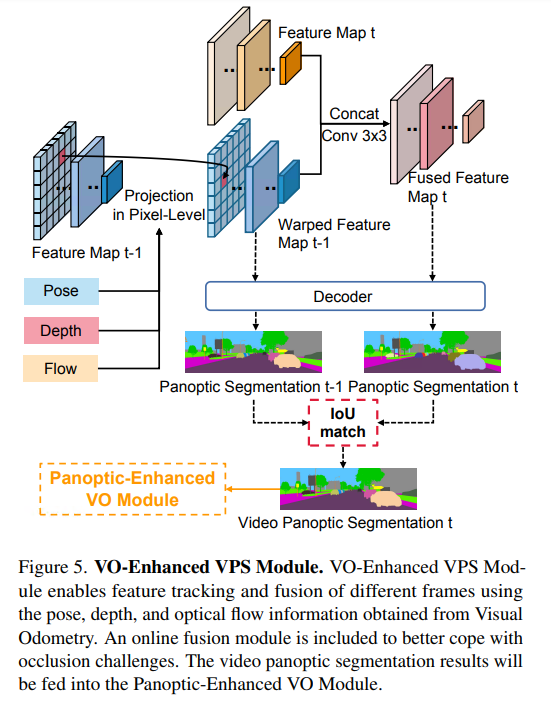
圖5顯示了VO增強型VPS模塊,該模塊通過使用從視覺里程計獲得的深度、姿態和光流信息,將前一幀t?1的特征wrap到當前幀t,從而獲得wrap的特征。在線融合模塊將融合當前幀t的特征和wrap的特征,以獲得融合的特征。為了保持視頻分割的一致性,首先將wrap的特征t?1(包含幾何運動信息)和融合的特征圖t輸入解碼器,分別獲得全景分割t?1和t,然后使用簡單的IoU匹配模塊來獲得一致的全景分割,該結果將被輸入Panoptic增強型VO模塊。
4)遞歸迭代優化
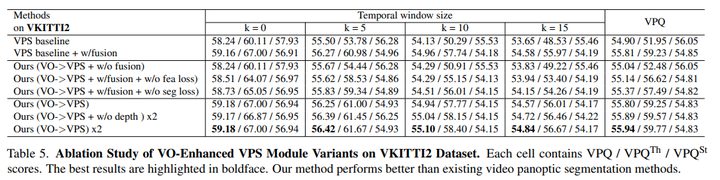
受EM算法的啟發,可以以遞歸迭代的方式優化所提出的全景增強VO模塊和VO增強VPS模塊,直到收斂。在實驗上,循環通常只需要兩次迭代就可以收斂,表5和表6表明,反復迭代優化可以提高VPS和VO模塊的性能。
5)實施細則
PVO由PyTorch實現,由三個主要模塊組成:圖像全景分割、全景增強VO模塊和VO增強VPS模塊。本文使用三個階段來訓練網絡,在KITTI數據集上訓練圖像全景分割作為初始化。在PanopticFCN之后,訓練過程中采用了多尺度縮放策略。在兩個GeForce RTX 3090 GPU上以1e-4的初始速率優化網絡,其中每個小批量有八個圖像,SGD優化器的使用具有1e-4的重量衰減和0.9的動量。
全景增強VO模塊的訓練遵循DROIDSLAM,只是它額外提供了地面實況全景分割結果。在訓練VO增強視頻全景分割模塊時,使用GT深度、光流和姿態信息作為幾何先驗來對齊特征,并固定訓練的單圖像全景分割的主干,然后僅訓練融合模塊。該網絡在一個GeForce RTX 3090 GPU上以1e-5的初始學習率進行了優化,其中每個批次有八個圖像。當融合網絡基本收斂時,添加了一個分割一致性損失函數來進一步完善VPS模塊!
實驗結果
1)視覺里程計
本文在三個具有動態場景的數據集上進行實驗:Virtual KITTI、KITTI和TUM RGBD動態序列,使用絕對軌跡誤差(ATE)進行評估。對于視頻全景分割,在cityscape和VIPER數據集上使用視頻全景質量(VPQ)度量。本文進一步對Virtual KITTI進行消融研究,以分析本文的框架設計。最后,展示了PVO在視頻編輯方面的適用性,如補充材料中的第B節所示。
VKITTI2
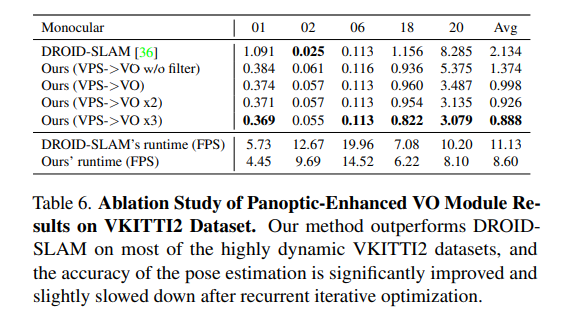
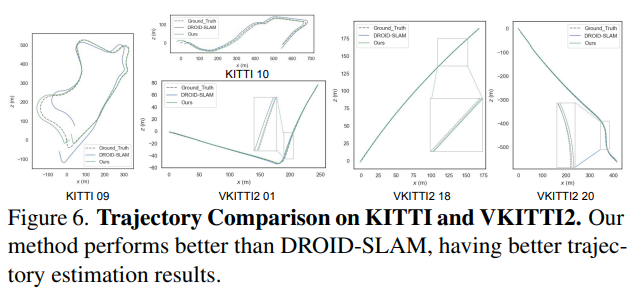
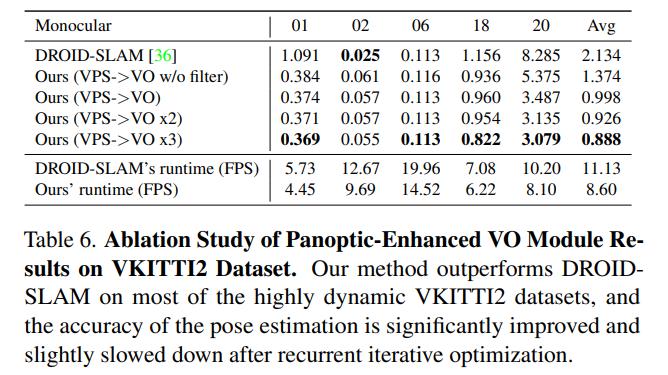
虛擬KITTI數據集[3]由從KITTI跟蹤基準克隆的5個序列組成,為每個序列提供RGB、深度、類分割、實例分割、相機姿態、flow和場景flow數據。如表6和圖6所示,在大多數序列中,本文的PVO以很大的優勢優于DROID SLAM,并在序列02中實現了有競爭力的性能。
KITTI
KITTI是一個捕捉真實世界交通場景的數據集,從農村地區的高速公路到擁有大量靜態和動態對象的城市街道。本文將在VKITTI2[3]數據集上訓練的PVO模型應用于KITTI序列。如圖6所示,PVO的姿態估計誤差僅為DROID-SLAM的一半,這證明了PVO具有良好的泛化能力。表1顯示了KITTI和VKITTI數據集上的完整SLAM比較結果,其中PVO在大多數情況下都大大優于DROID-SLAM和DynaSLAM,DynaSLAM在VKITTI2 02、06和18序列中屬于災難性系統故障。

TUM-RGBD
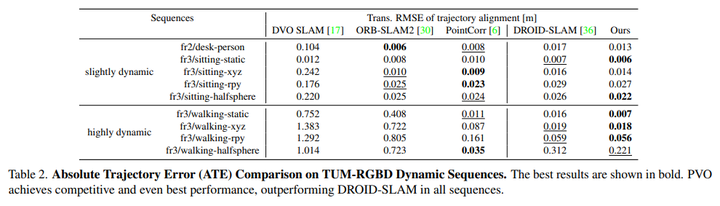
TUM RGBD是一個用手持相機捕捉室內場景的數據集,本文選擇TUM RGBD數據集的動態序列來顯示本文的方法的有效性。將PVO與DROIDSLAM以及三種最先進的動態RGB-D SLAM系統進行了比較,即DVO-SLAM、ORB-SLAM2和PointCorr。請注意,PVO和DROID-SLAM僅使用單目RGB視頻。表2表明PVO在所有場景中都優于DROID-SLAM,與傳統的RGB-D SLAM系統相比,本文的方法在大多數場景中也表現得更好。
2)視頻全景分割
將PVO與三種基于實例的視頻全景分割方法進行了比較,即VPSNetTrack、VPSNetFuseTrack和SiamTrack。在圖像全景分割模型UPSNet的基礎上,VPSNetTrack還添加了MaskTrack head,以形成視頻全景分割模型。基于VPSNet Track的VPSNet FuseTrack額外注入了時間特征聚合和融合,而SiamTrack利用pixel-tubel 匹配損失和對比度損耗對VPSNet Track進行微調,性能略有提高,比較VPSNet FuseTrack主要是因為SiamTrack的代碼不可用。
Cityscape:本文在VPS中采用了Cityscape的公共訓練/val/test分割,其中每個視頻包含30個連續幀,每五幀有相應的GT注釋。表3表明,使用PanopticFCN的方法在val數據集上優于最先進的方法,實現了比VPSNet Track高+1.6%VPQ。與VPSNetFuseTrack相比,本文的方法略有改進,可以保持一致的視頻分割,如補充材料中的圖A4所示。原因是由于內存有限,論文的VO模塊只能獲得1/8分辨率的光流和深度。
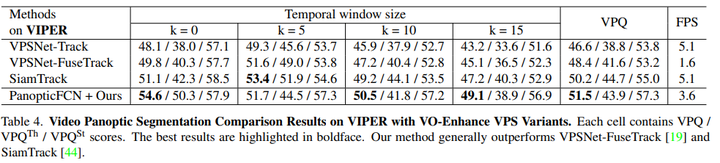
VIPER:VIPER維護了大量高質量的全景視頻注釋,這是另一個視頻全景分割基準。遵循VPS[19],并采用其公共train/val拆分。使用從日常場景中選擇的10個視頻,每個視頻的前60幀用于評估。表4表明,與VPSNet FuseTrack相比,PanopticFCN方法在VIPER數據集上獲得了更高的分數(+3.1VPQ)。
3)消融實驗
VPS增強型VO模塊:在全景增強型VO模塊中,使用DROID-SLAM作為基線,(VPS->VO)意味著增加了全景信息先驗以增強VO基線,(VPS->VO x2)意味著可以迭代優化VO模塊兩次。(VPS->VO x3)意味著對VO模塊進行3次反復迭代優化,表6和圖7顯示,在大多數高度動態的VKITTI2數據集上,全景信息可以幫助提高DROID-SLAM的準確性,遞歸迭代優化可以進一步改善結果。
VO增強型VPS模塊:為了評估VO是否有助于VPS,首先使用PanopticFPN來獲得每個幀的全景分割結果,然后使用來自RAFT的光流信息進行幀間跟蹤,這被設置為VPS基線。(VPS基線+w/fusion)意味著額外地將特征與流量估計相融合。(VO->VPS+w/o融合)意味著在基線之上使用額外的深度、姿勢和其他信息,(VO->VPS)意味著我們額外融合了該功能。
VO增強型VPS模塊中的在線融合:為了驗證所提出的特征對齊損失(fea損失)和分割一致性損失(seg損失)的有效性,方法如下:(VO->VPS+w/fusion+w/o fealoss)意味著在沒有特征對齊損失的情況下訓練在線融合模塊,(VO->VPS+w/fusion+w/o-seg loss)意味著在沒有Segmentation Consistent loss的情況下訓練在線融合模塊,表5展示了這兩種損失函數的有效性!
一些結論
論文提出了一種新的全景視覺里程計方法,該方法在統一的視圖中對VO和VPS進行建模,使這兩項任務能夠相互促進。全景更新模塊可以幫助改進姿態估計,而在線融合模塊有助于改進全景分割。大量實驗表明,本文的PVO在這兩項任務中都優于最先進的方法。局限性主要是PVO建立在DROID-SLAM和全景分割的基礎上,這使得網絡很重,需要大量內存。盡管PVO可以在動態場景中穩健地執行,但它忽略了當攝像機返回到之前的位置時環路閉合的問題,探索一種低成本、高效的閉環SLAM系統是未來的工作。
審核編輯:劉清
-
攝像機
+關注
關注
3文章
1618瀏覽量
60317 -
Droid
+關注
關注
0文章
2瀏覽量
6427 -
SLAM
+關注
關注
23文章
426瀏覽量
31929 -
vps
+關注
關注
1文章
111瀏覽量
12050
原文標題:CVPR 2023 | PVO:全景視覺里程計(VO和全景分割雙SOTA)!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
成像式亮度色度計產品原理及應用介紹

AI開發框架集成介紹
用于任意排列多相機的通用視覺里程計系統
一種面向飛行試驗的數據融合框架

基于視覺語言模型的導航框架VLMnav
投入式水位計是什么?投入式水位計怎么安裝


一種完全分布式的點線協同視覺慣性導航系統
全景聲解碼器

rup是一種什么模型
一種高效的KV緩存壓縮框架--GEAR

視覺慣性里程計(VIO)在運動估計中的優勢及應用

介紹一種OpenAtom OpenHarmony輕量系統適配方案






 工商網監
工商網監
評論