") 一顆Jericho3-AI芯片,用來替代InfiniBand?
一顆Jericho3-AI芯片,用來替代InfiniBand?
多樣性不僅是生活的調(diào)味品,也是推動(dòng)創(chuàng)新和降低風(fēng)險(xiǎn)的方式。這就是為什么我們看到交換機(jī)架構(gòu)不斷發(fā)展以驅(qū)動(dòng)特定類型的 AI 工作負(fù)載,就像我們在過去兩年半的時(shí)間里看到的 HPC 模擬和建模工作負(fù)載一樣。
Hyperion Research:SC22 HPC Market Update(2022.11)
Hyperion Research:ISC22 Market Update(2022.5)
Intersect360全球HPC-AI市場報(bào)告(2022—2026)
Intersect360 AMD CPU和GPU調(diào)研白皮書
在橫向擴(kuò)展人工智能訓(xùn)練的早期——也就是從 2010 年到現(xiàn)在——InfiniBand 是 HPC 模擬和建模的首選低延遲網(wǎng)絡(luò)之一,它崛起成為主要的網(wǎng)絡(luò)互連,將擠滿了 GPU 的節(jié)點(diǎn)粘合在一起。但許多 AI 初創(chuàng)公司,如 Cerebras Systems、SambaNova Systems、GraphCore 和英特爾的 Gaudi 都有自己的互連,谷歌也是如此,其光開關(guān)是其 TPUv4 矩陣數(shù)學(xué)巨頭的核心。如果你想大方一點(diǎn),你可以說 Cray(現(xiàn)在是惠普企業(yè)的一部分)創(chuàng)建的以太網(wǎng)的 Slingshot 變體也是一種自定義互連,可以(并且將會(huì))以百億億次級運(yùn)行 AI 工作負(fù)載。
在推動(dòng)人工智能革命的超大規(guī)模和云構(gòu)建巨頭中,博通在交換和路由半導(dǎo)體領(lǐng)域占據(jù)主導(dǎo)市場份額,它希望在人工智能網(wǎng)絡(luò)行動(dòng)中分得一杯羹。因此,該公司采用“Jericho”系列交換機(jī)和路由 ASIC 及其深度數(shù)據(jù)包緩沖區(qū),并專門重新設(shè)計(jì)它們以承擔(dān) AI 工作負(fù)載,最初的 Jericho3-AI 交換機(jī)芯片是該設(shè)計(jì)的第一個(gè)實(shí)例。通過這種設(shè)計(jì),Broadcom 已經(jīng)將 InfiniBand 牢牢地放在了自己的視線之內(nèi),而且絕對是在爭取它。
這意味著,除其他外,Broadcom 將讓 Arista Networks 和云構(gòu)建者和超大規(guī)模應(yīng)用者使用的白盒交換機(jī)制造商集體在其主場 AI 領(lǐng)域與 Nvidia 競爭,其中包括強(qiáng)大的 AI 軟件堆棧、GPU 以及即將推出的 CPU 和 GPU內(nèi)存互連以及Nvidia 從三年前完成的 69 億美元收購中獲得的InfiniBand 網(wǎng)絡(luò)硬件和軟件。
借助 Jericho3-AI 芯片,Broadcom 正在重新設(shè)計(jì)深度緩沖 Jericho 芯片系列,這些芯片通常被超大規(guī)模用戶和云構(gòu)建者用來執(zhí)行路由和交換功能,并為它們提供通常用于集體操作的性能。AI 和 HPC 使它們在 AI 工作負(fù)載方面與 InfiniBand 具有絕對競爭力,并賦予它們標(biāo)準(zhǔn)以太網(wǎng) ASIC 所不具備的功能,包括在各種規(guī)模的數(shù)據(jù)中心中常用的“Trident”和“Tomahawk”系列中的功能。
Jericho3-AI 芯片使用相同的“Peregrine”系列 SerDes 信號電路,該電路在2022 年 8 月發(fā)布的“Tomahawk5”葉/主干以太網(wǎng)交換機(jī) ASIC中首次亮相。Broadcom Trident 和 Tomahawk 交換機(jī)產(chǎn)品線的產(chǎn)品線經(jīng)理 Peter Del Vecchio 向我們介紹了 Jericho3-AI,他說 Tomahawk5 ASIC 于今年 3 月開始批量出貨,這意味著我們應(yīng)該很快就會(huì)看到它出現(xiàn)在交換機(jī)中。
Tomahawk5 在某些方面是比 Jericho3-AI 更強(qiáng)大的設(shè)備,但它具有更適度的緩沖區(qū),并且專為在這些超大規(guī)模和云構(gòu)建者的 Clos 網(wǎng)絡(luò)中完成的架頂和葉交換而設(shè)計(jì)。Tomahawk5 采用臺灣半導(dǎo)體制造公司的 5 納米工藝實(shí)現(xiàn),其中 512 個(gè) Peregrine SerDes 以 100 Gb/秒的速度運(yùn)行(通過信號的 PAM-4 調(diào)制啟用)包裹在數(shù)據(jù)包處理引擎和適度的緩沖區(qū)周圍以創(chuàng)建一個(gè)設(shè)備總帶寬為 51.2 Tb/秒。Jericho3-AI 芯片也采用 TSMC 的 5 納米工藝蝕刻,具有 304 個(gè)相同的 SerDes,其中 144 個(gè)分配給下行鏈路,其中 160 個(gè)延伸到網(wǎng)絡(luò)中更高層的 Ramon 3 結(jié)構(gòu)元素,充當(dāng)leaf 和spine開關(guān)。像這樣:
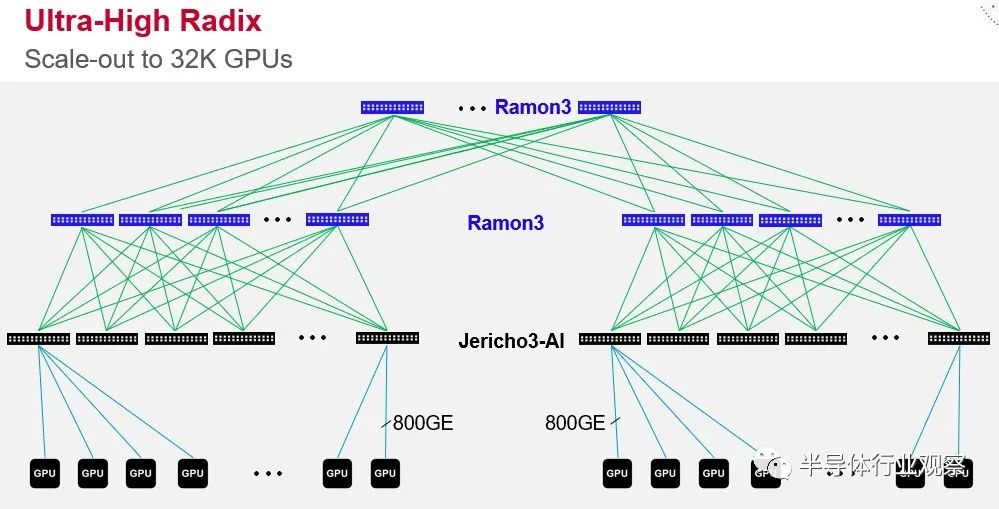
您會(huì)注意到圖中的交換機(jī)端口直接鏈接到 GPU,這不是錯(cuò)誤。越來越多的架構(gòu)將這樣做。為什么要通過服務(wù)器總線來鏈接 GPU?重要的是,Ramon 3 結(jié)構(gòu)元素(本質(zhì)上是spine互連)和 Jericho3-AI leaf或架頂式交換機(jī)的規(guī)模允許超過 32,000 個(gè) GPU 在 Clos 拓?fù)渲墟溄拥揭粋€(gè)龐大的 AI 訓(xùn)練系統(tǒng)中,以 800 Gb/秒的速度運(yùn)行的端口。不可否認(rèn),今天沒有服務(wù)器的端口運(yùn)行速度超過 200 Gb/秒或 400 Gb/秒,因?yàn)檫m配卡還沒有以這些本機(jī)速度運(yùn)行。在 2025 年時(shí)間框架內(nèi) PCI-Express 6.0 插槽在服務(wù)器中可用之前,這可能不會(huì)發(fā)生。
現(xiàn)在,當(dāng)微軟為自己和它在 AI 框架中的合作伙伴 OpenAI 運(yùn)行 GPT 訓(xùn)練時(shí),它使用標(biāo)準(zhǔn)的 HGX GPU 系統(tǒng)板綁定到服務(wù)器主機(jī)節(jié)點(diǎn),并通過一個(gè) 400 Gb/秒的 ConnectX CX7 網(wǎng)絡(luò)接口相互鏈接,用于八 GPU 系統(tǒng)中的每個(gè) GPU。微軟 Azure 在 InfiniBand 網(wǎng)絡(luò)上使用胖樹(fat tree)拓?fù)洌拖裨S多 HPC 商店所做的那樣,并且還使用消息傳遞接口 (MPI) 協(xié)議來調(diào)度數(shù)據(jù)和計(jì)算,跨 4,000 個(gè) GPU 鏈接到一個(gè)集群,以運(yùn)行 GPT 和其他框架。作為單例。微軟將根據(jù)需要增加它,如果 Jericho3-AI 芯片為人工智能工作負(fù)載提供更好的性能和經(jīng)濟(jì)性,那么微軟架構(gòu)中的任何內(nèi)容都不會(huì)阻止它遷移到基于 Broadcom Dune StrataDNX 系列的結(jié)構(gòu),其中 Jericho3 -AI和Ramon 3是一部分。
同上所有其他云和超大規(guī)模。
這是關(guān)于 Tomahawk5 和 Jericho3-A1 的巧妙之處,因?yàn)樗鼈兪褂昧?Peregrine SerDes。按照這些 SerDes 的設(shè)計(jì)方式,它們可以使用所謂的線性驅(qū)動(dòng)光學(xué)器件直接驅(qū)動(dòng)光學(xué)器件,這意味著 SerDes 可以直接與光學(xué)器件中的跨阻放大器對話,而無需在其前面安裝數(shù)字信號處理器。此外,Peregrine SerDes 可以將信號向下推送到 4 米直連銅 (DAC) 電纜——是 IEEE 規(guī)范電纜長度的兩倍——無需重定時(shí)器或中繼器。盡管此選項(xiàng)尚未商業(yè)化,但如果 Broadcom 的客戶希望進(jìn)一步降低熱量、每比特成本和延遲,則可以使用 Peregrine SerDes 來驅(qū)動(dòng)共同封裝的光學(xué)器件。

從技術(shù)上講,Jericho3-AI 芯片的額定速度為 14.4 Tb/秒,因?yàn)橹挥?144 個(gè) SerDes 驅(qū)動(dòng)下行鏈路,其余 160 個(gè) SerDes,即 16 Tb/秒,不計(jì)入設(shè)備的官方吞吐量。芯片上可能有更多的物理SerDes,這是一個(gè)單片器件,不是由chiplet組成的,目的是在5納米器件上的反良率被屏蔽后,增加有效SerDes的數(shù)量。(這在當(dāng)今所有復(fù)雜的半導(dǎo)體設(shè)備設(shè)計(jì)和制造中都很常見。)如果我們有 Jericho3-AI 的die照片,我們肯定會(huì)知道。。 . 。
Jericho3-AI 芯片專門設(shè)計(jì)用于在分布式模型中的每個(gè)計(jì)算步驟結(jié)束時(shí)執(zhí)行集體操作(尤其是 all-to-all 或 all reduce 操作)時(shí)幫助處理網(wǎng)絡(luò)上的復(fù)雜流。這些功能在大型語言模型和推薦系統(tǒng)中至關(guān)重要,它們具有非常不同的特征并且需要稍微不同的硬件(這就是為什么“Hopper”GPU 需要緊密耦合的“Grace”CPU 用于未來專注于推薦系統(tǒng)的 Nvidia 系統(tǒng)) 。
Meta Platforms 基礎(chǔ)設(shè)施副總裁 Alexis Bjorlin在去年 10 月的開放計(jì)算項(xiàng)目峰會(huì)上的主題演講中談到了其“Grand Teton”AI 系統(tǒng)和配套“Grand Canyon”存儲(chǔ)陣列的設(shè)計(jì),而我們并不知道她分享了下圖涉及四種不同的機(jī)器學(xué)習(xí)模型,這些模型是Meta Platforms 使用的深度學(xué)習(xí)推薦模型 (DLRM) 推薦系統(tǒng)的一部分,該系統(tǒng)于 2019 年 7 月開源:
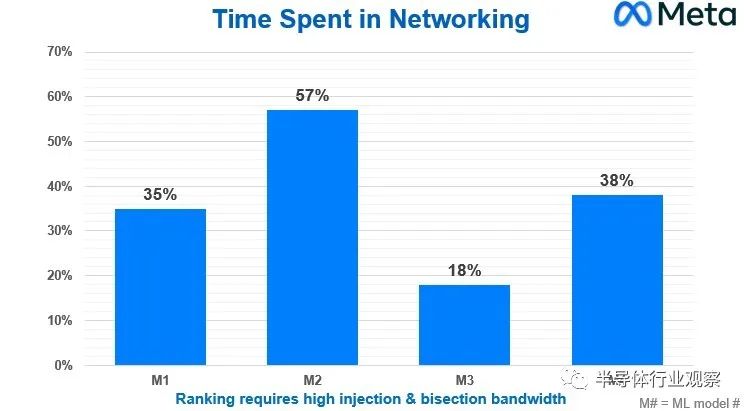
此圖表顯示的是在下一個(gè)計(jì)算步驟開始之前等待集體操作在網(wǎng)絡(luò)上運(yùn)行所浪費(fèi)的 CPU 時(shí)間百分比。它是掛鐘時(shí)間減去計(jì)算時(shí)間除以掛鐘時(shí)間,得到網(wǎng)絡(luò)時(shí)間。
現(xiàn)在,這些龐大的 AI 集群中的單個(gè)節(jié)點(diǎn)成本可能為 400,000 到 500,000 美元,根據(jù)模型的不同,有 18%、35%、38% 或 57% 的時(shí)間都在那里,這確實(shí)是一個(gè)非常昂貴的提議。 通過針對 AI 工作負(fù)載優(yōu)化的網(wǎng)絡(luò),集體操作的網(wǎng)絡(luò)效率的任何變化都意味著 CPU-GPU 硬件投資不會(huì)按比例浪費(fèi)。
為了解 Jericho3-AI 如何與 InfiniBand 競爭,Broadcom 與其中一家超大規(guī)模廠商合作,更換了連接 GPU 加速計(jì)算節(jié)點(diǎn)的 200 Gb/秒 InfiniBand 交換機(jī),并將該 InfiniBand 交換機(jī)替換為以太網(wǎng)交換機(jī)。這兩款交換機(jī)都運(yùn)行 Nvidia 集體通信庫 (NCCL),這是一種由 Nvidia 創(chuàng)建的集體操作網(wǎng)絡(luò)軟件驅(qū)動(dòng)程序,旨在為密集的 GPU 分組提供比在 CPU 內(nèi)核或插槽上運(yùn)行普通 MPI 更好的集體操作性能。NCCL 是拓?fù)涓兄模@意味著它知道計(jì)算節(jié)點(diǎn)內(nèi)的快速和fat NVLink 管道與跨節(jié)點(diǎn)的 InfiniBand 或以太網(wǎng)管道之間的區(qū)別。這些不是非此即彼的命題,NCCL 和 MPI 經(jīng)常一起使用。
以下是在支持 InfiniBand 或以太網(wǎng)協(xié)議的 ConnectX-6 SmartNIC 上具有多達(dá) 16 個(gè) 200 Gb/秒端口的服務(wù)器與基于 Nvidia 的 Quantum 2 ASIC 或 Broadcom 的 Jericho3-AI ASIC 的交換機(jī)之間的性能差異:
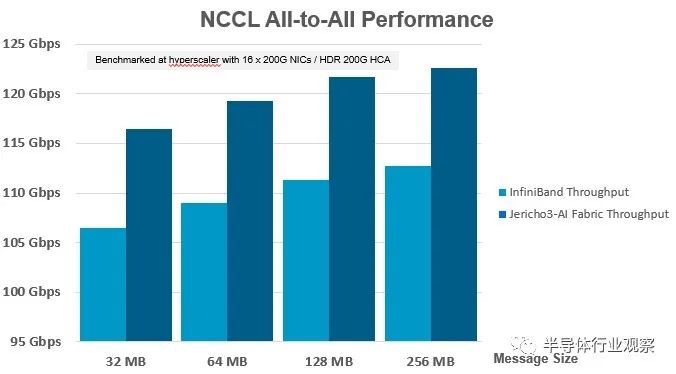
您必須仔細(xì)觀察 Y 軸,因?yàn)閮蓚€(gè)交換機(jī)的整體集體操作性能不是從 0 Gb/秒到 125 Gb/秒,而是從 95 Gb/秒到 125 Gb/秒,這意味著此圖表中的性能增量在視覺上比實(shí)際大。結(jié)果是,幾乎無論消息大小如何,Jericho3-AI 芯片提供的吞吐量比運(yùn)行相同 AI 訓(xùn)練工作負(fù)載的 InfiniBand 交換機(jī)高出約 10%。
現(xiàn)在,如果您查看 Meta Platforms 提供的圖表,10% 是一個(gè)大問題。任何能提高網(wǎng)絡(luò)有效加速的東西都會(huì)縮短集體操作的掛鐘時(shí)間。Del Vecchio 告訴The Next Platform,Jericho3-AI switch 的性能提速對于所有 reduce 集體操作也有大約 10%(但我們沒有這方面的圖表)。這意味著完成 AI 訓(xùn)練運(yùn)行的時(shí)間也將縮短,如果時(shí)間就是金錢——通常是在涉及 AI 和 HPC 工作負(fù)載時(shí)——那么可以同時(shí)訓(xùn)練更多模型。再加上節(jié)能和更長的 DAC,Broadcom 將在 AI 培訓(xùn)方面擁有令人信服的價(jià)值主張,以與 InfiniBand 競爭。
Broadcom 如何為 InfiniBand 帶來熱度?Jericho3-AI 芯片有一些功能名稱看起來非常奇特,但歸根結(jié)底是更好的負(fù)載平衡和擁塞控制,可以減少網(wǎng)絡(luò)爭用并改善網(wǎng)絡(luò)延遲,坦率地說,這比降低延遲更重要在交換機(jī)內(nèi)部端口到端口的跳躍上,與基于 ASIC(如 Tridents 和 Tomahawks)的傳統(tǒng)數(shù)據(jù)中心級以太網(wǎng)交換機(jī)及其來自 Cisco Systems 的競爭產(chǎn)品相比,InfiniBand 具有巨大的優(yōu)勢——大約 3 到 4 倍或更多(那是我們說的,不是 Broadcom。但這是真的。)
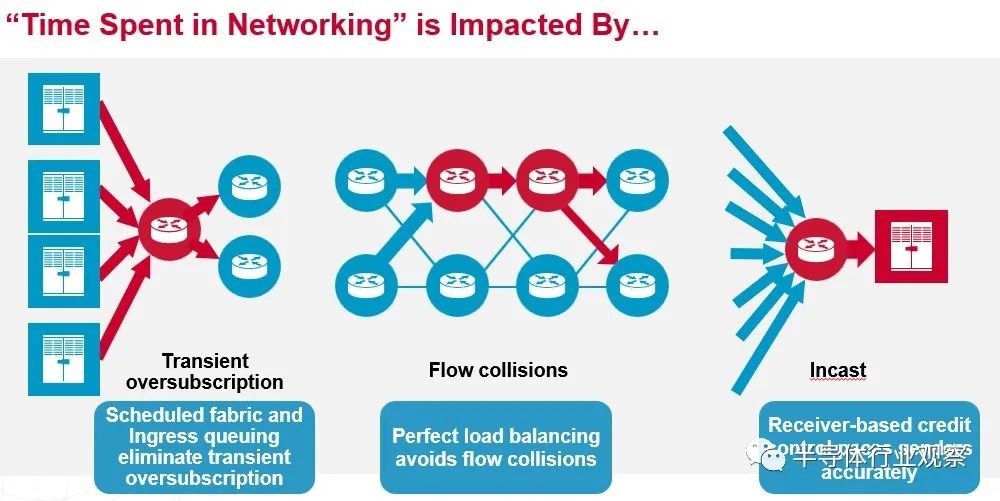
Jericho3-AI 芯片的兩個(gè)重要特性就是 Broadcom 夸張地稱之為完美的負(fù)載平衡和無擁塞操作。這是一張從概念上顯示它們?nèi)绾螀f(xié)同工作的圖片:
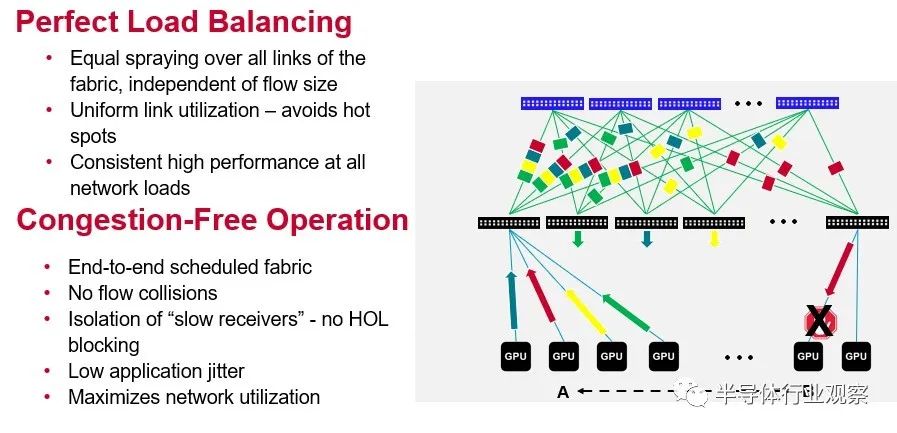
我們高度懷疑任何負(fù)載平衡是否“完美”或網(wǎng)絡(luò)操作是否可以“無擁塞”,但顯然,根據(jù) Broadcom 展示的結(jié)果,Jericho3-AI 在 AI 訓(xùn)練工作負(fù)載方面將比 Tomahawk 做得更好或 Trident ASIC 可以并且基于這組有限的性能數(shù)據(jù),應(yīng)該讓 InfiniBand 與 AI 訓(xùn)練資金競爭。
我們的問題是:Jericho3-AI 芯片是否會(huì)像 InfiniBand 那樣幫助處理傳統(tǒng)的 HPC 模擬和建模工作負(fù)載?
“這取決于 HPC 的類型,”Del Vecchio 說。“但如果吞吐量對應(yīng)用程序很重要,那當(dāng)然是肯定的。HPC 應(yīng)用程序也將獲得這些好處,您最終將獲得無擁塞操作、非常好的負(fù)載平衡以及更有效地利用鏈接。與 HPC 相比,AI 更傾向于關(guān)注整個(gè)網(wǎng)絡(luò)的原始吞吐量,后者才是最重要的端到端延遲。HPC 有很多非常短的消息,因此消息速率非常關(guān)鍵。所以有一些不同。但關(guān)鍵是要確保負(fù)載平衡,如果沒有擁塞——這些將同樣適用于 AI 和 HPC。”
Jericho3-AI 開關(guān)芯片現(xiàn)在正在出樣,預(yù)計(jì)會(huì)像 Tomahawk5 那樣有相對較快的提升。
審核編輯 :李倩
-
芯片
+關(guān)注
關(guān)注
456文章
51192瀏覽量
427324 -
gpu
+關(guān)注
關(guān)注
28文章
4777瀏覽量
129362 -
網(wǎng)絡(luò)硬件
+關(guān)注
關(guān)注
0文章
10瀏覽量
6202
原文標(biāo)題:一顆Jericho3-AI芯片,用來替代InfiniBand?
文章出處:【微信號:AI_Architect,微信公眾號:智能計(jì)算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
用一顆TXB0104可以進(jìn)行串口電壓轉(zhuǎn)換嗎?

用一顆5G的204B接口DA芯片,DA芯片的輸入時(shí)鐘大小和輸入數(shù)據(jù)的速率是怎么樣的關(guān)系?
一顆射頻開關(guān)的獨(dú)白
請問AIC3254能不能替代C5502+AIC32B?
兩顆TAS5711,一顆作2.0輸出,一顆作PBTL輸出,共用一個(gè)I2S_DATA時(shí)發(fā)現(xiàn)失真增大,為什么?
InfiniBand網(wǎng)絡(luò)內(nèi)計(jì)算的關(guān)鍵技術(shù)和應(yīng)用
OPA197如果使用多階,用一顆跟隨器提供基準(zhǔn)電壓是否可行?
鈺泰ETA300X主動(dòng)均衡芯片,一顆可以劫富濟(jì)貧的芯片
HT7017 是一顆帶 UART 通訊接口的高精度單相多功能計(jì)量芯片

一顆改變了世界的芯片






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論