") 從不均勻性角度淺析AB實驗
從不均勻性角度淺析AB實驗
本篇的目的是從三個不均勻性的角度,對 AB 實驗進行一個認知的普及,最終著重講述 AB 實驗的一個普遍的問題,即實驗準確度問題。
一、AB 實驗場景
在首頁中,我們是用紅色基調(diào)還是綠色基調(diào),是采用門店小列表外 + 商品 feed(左圖),還是采用門店大列表囊括商品 feed(右圖),哪種更吸引用戶瀏覽下單呢,簡單來處理讓 50% 的用戶看到左圖效果,讓 50% 的用戶看到右圖效果,最終通過點擊量,單量等指標進行比對得出結(jié)論,這是典型的 AB 實驗場景


二、AB 實驗的定義
A/B 實驗就是針對想迭代的產(chǎn)品功能,提供兩種不同的備選解決方案,然后讓一部分用戶使用方案 A,另一部分用戶使用方案 B,最終通過實驗數(shù)據(jù)對比來確定最優(yōu)方案。 從定義里我們就可以看出來,最直觀的一個概念,就是用戶的分流,此時就涉及到分流人數(shù)是否均勻的問題,即人數(shù)比例的均勻性。
三、AB 中的三個不均勻
1、人數(shù)比例的不均勻
目前 AB 實驗的分流核心算法是通過的哈希算法,假設(shè)我們按用戶名做為分流因子,使用 murmurhash 算法,以 100 桶制為例,確定一個人的位置的算法就是
//將用戶名通過hash算法計算出一個整數(shù) int hashNum = MurmurHash3.murmurhash3_x86_32(useName) //整數(shù)值對100取模 int bucket = hashNum % 100;當我們定義一個實驗兩個策略的人數(shù)均為 50% 時,那么 bucket 為 0-49 的用戶由 AB 系統(tǒng)標記為 A, 業(yè)務(wù)系統(tǒng)根據(jù) A 標記,使得用戶使用方案 A bucket 為 50-99 的用戶由 AB 系統(tǒng)標記為 B, 業(yè)務(wù)系統(tǒng)根據(jù) B 標記,使得用戶使用方案 B。 可是我們都知道哈希算法并不是絕對均勻的,當 100 人時,基本上不會出現(xiàn)有 50 個人走 A,50 個人走 B,但是 1 萬個人的時候,兩部分流量可能就接近了 1:1,10 萬人的時候可能更接近 1:1。 之前有位運營的同學問過,為什么不能用一種很均勻的算法,比如第一個人來了,放入 A,第二個人來了放入 B,第三個人來了放入 A,第四個人來了放入 B....,這樣一天 1W 個人來,5000 個取 A 策略,5000 個取 B 策略。 假設(shè)我們真的這么做了,第一天是 OK 的,第二天進 A 只來了 4000 人,這樣還是不均勻的,如果你第二天仍然按第一天的規(guī)則重新分配,這樣會有一部分人亂了策略,不符合我們固定人群走固定策略的實驗?zāi)康摹?所以說這個不均勻是無解的,HASH 算法是目前最理想的解決方案,前提是你需要一定的流量,流量越大,分流相對就比較準確。
2、人群素質(zhì)的不均勻
我們假設(shè)流量足夠大,人數(shù)比例很均勻了,但是還有個問題就是人群素質(zhì)的均勻問題。這里的素質(zhì)包括消費能力,活躍度,年齡等各種人群因素。 假設(shè)現(xiàn)在我們的活動統(tǒng)一采用的 A 策略(現(xiàn)狀),我們想驗證一下 B 策略(新策略)會不會帶來客單價的提升,就直接做了 AB 實驗,還按 1:1 比例來分流,發(fā)現(xiàn)使用 A 方案的人群客單價是 100,使用客單價 B 的人群是 96,此時我們能認為原有 A 方案優(yōu)于 B 方案嗎?其實是不能的,怎樣確定這種人群素質(zhì)的差異呢,可以采用 AA 實驗,就是兩部分人都走 A,進行分開統(tǒng)計,可能會發(fā)現(xiàn),位于 0-49 桶的人群本身客單價就是 100,而位于 50-99 桶的人群可能只有 94,這么看來 B 方案是能提升客單價的,因為位于 50-99 桶的人群本身指標就差一些。 當然 AA 不是必須的,可能你有整體的客單價指標,上了 B 策略后發(fā)現(xiàn)整體提升了,這種情況相當于灰度驗證了,但實際情況是比較復(fù)雜的,整體指標你是不清楚的(因為這里的整體可能只是你取的業(yè)務(wù)中的一部分流量)。 所以解決素質(zhì)不均勻的手段就是采用 AA 提前確定差異性,再在這個差異性基礎(chǔ)上看差異的變化。
3、實驗間影響的不均勻
這個不均勻性是最復(fù)雜的,一般做實驗我們走兩種極端: 第一種是完全不復(fù)用人群,每個實驗人群都是獨立的,這樣的話效果比較準確,但是弊端是,當所有流量都被用去后,不能有新實驗開始,必須等待有結(jié)束的實驗后才能繼續(xù)做。 第二種,所有實驗都用全部流量,此時我們認為實驗雖然互相之間有影響,但是這種影響是正交的,量大的時候應(yīng)該是均勻的,如下圖所示,P 實驗的兩個策略人群,到 Q 實驗時,對 Q 的兩個策略影響是均勻的。
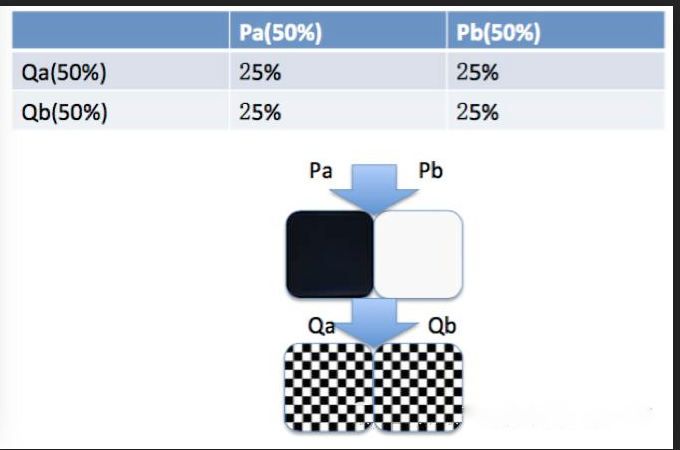
這種可以滿足無限個實驗,想做多少實驗都可以,但弊端是,實驗太多,必然有影響不均勻的,且我們無法消除這種不均勻。 所以我們想能不能結(jié)合以上兩種情況來處理呢,結(jié)合 google 的 Overlapping Experiment Infrastructure 文章我們設(shè)計出分層的實驗管理模型
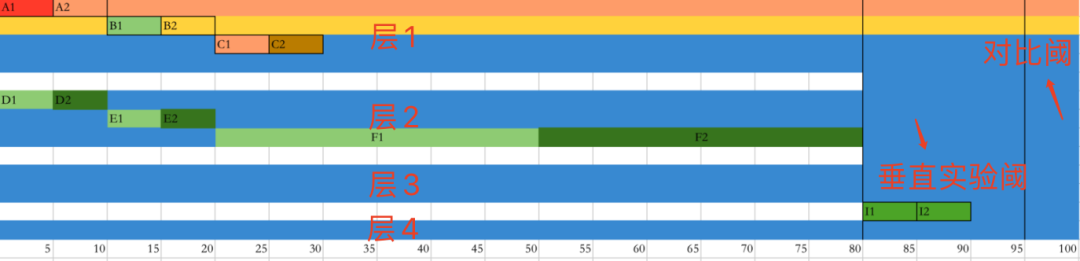
首先我們將總流量分成兩部分,正交域,垂直域(含對比區(qū)) 我們假設(shè)如圖取 80% 的流量用做正交閾,20% 用作垂直域,垂直域中有 5% 用做對比區(qū)。 上圖正交域下 4 個層,層內(nèi)實驗流量互斥,層間實驗流量正交,我們將可能會互相影響的實驗放到同一層內(nèi)進行流量互斥,而影響不大的實驗可以放到不同層內(nèi)。 垂直域中的實驗流量只能互斥,且不與任何實驗正交,可以理解用最純正的流量做實驗,可以 I1 和 I2 兩個策略間對比,也可以 I1 或 I2 和對比域(現(xiàn)狀)比對。 那此時有一個很重要的問題需要解決,我們怎么確定哪些實驗互相影響較大,需要放到同一層下。 有一些簡單標準,比如入口不一樣,目標不一樣等等,這種可以放到不同層,我們可以忽略正交不均勻的問題,反之就不行。 比如活動頁劵對單量提升度的實驗和會員頁面入會效果的實驗,就可以放到不同層。 而首頁上滿減活動實驗對客單價提升的實驗和同樣首頁買贈活動對客單價提升的實驗,最好是不共用用戶,放到同層比較合適。 但對于很多實驗是不太容易通過簡單規(guī)則來確定的,需要大數(shù)據(jù)的同學和產(chǎn)品,甚至研發(fā)來共同決定實驗放到哪些層和哪些實驗互斥,這確實在實際的運作中是最難的點。 總之采用這種策略,可以復(fù)用流量的同時還可以降低不必要的互相影響,比較綜合考慮了流量和準確度問題。
四、總結(jié)
現(xiàn)在我們對以上問題進行總結(jié),從問題到解決方案上來認識 ab 實驗 1、人群做不到絕對的均勻,只能通過 HASH 算法,結(jié)合一定的流量來解決。 2、通過 AA 實驗,來提前確定人群素質(zhì)的不均勻。最終的實驗數(shù)據(jù)結(jié)合 AA 實驗數(shù)據(jù)來確定最終效果。 3、設(shè)計出正交垂直域,正交閾內(nèi)多個層,每個層內(nèi)放可能相互影響的實驗,層內(nèi)互斥,層間正交,保留垂直域,為要求精準的實驗留出流量,來解決實驗間相互影響的問題。 本篇從核心分流與實驗間相互影響角度講解 ab 實驗,希望能引起大家在做實驗前能有更多的思考,來更準確的驗證自己想要的效果,希望大家有興趣的可以留言討論。
審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4630瀏覽量
93355 -
模型
+關(guān)注
關(guān)注
1文章
3308瀏覽量
49223
原文標題:從不均勻性角度淺析AB實驗
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論